论文连接:https://www.sciencedirect.com/science/article/abs/pii/S1524070320300151
机构:
a英国卡迪夫大学计算机科学与信息学院
b中国科学院大学北京
c中国科学院计算技术研究所北京
d深圳大数据研究院,深圳518172
代码链接:可恶啊!暂时没有扒拉到只能看看其他组员的了!
摘要
牙齿三维模型的自动分割是正畸CAD系统的一个重要步骤。三维牙齿分割是一项网格实例分割任务。由于三维牙齿模型表面复杂的几何特征常常导致牙齿边界检测失败,传统的网格分割方法难以实现自动准确的分割。我们提出了一个解决这个问题的新方法。我们将三维牙齿模型同构映射到二维谐波参数空间,并将其转换成图像。这使得我们可以使用CNN学习高度鲁棒的图像分割模型来实现3D牙齿模型的自动准确分割。最后,我们将图像分割掩码映射回三维牙齿模型,并使用改进的模糊聚类和切割算法对分割结果进行细化。该方法已应用于正畸CAD系统中,在实际应用中取得了良好的效果。
背景
根据牙齿几何的先验知识,在牙齿边界处存在明显的负曲率特征。基于曲率的方法[1-6]通常检测这些负曲率特征并将表面划分为不同的部分。然而,牙齿和牙龈表面也存在负曲率特性,会形成噪音,造成严重干扰。此外,对于光滑的网格,负曲率特征不够明显,容易导致分割错误。
然而,由于网格数据格式与典型神经网络的输入格式有很大不同,因此不能直接输入到标准cnn中进行训练。为此,一些研究人员提出了[10]方法,将网格编码为图像,从而将卷积神经网络应用于处理基于网格的数据的任务。
以及在网格上标注不方便。
本文提出了一种在谐波参数空间中进行三维牙齿模型分割的算法。网格表面参数化[12]是将网格表面映射到参数空间的过程,目的是为了构造从原始网格到参数空间的同构映射,同时最小化映射过程中的畸变。我们首先将三维牙齿网格同构映射到二维(2D)谐波参数空间作为二维网格,然后对二维网格进行采样以形成类似图像的结构(即矩阵)。将曲率等网格特征编码为像素值,生成数据量小、计算速度快的256 ×1024图像。然后将图像输入到基于图像的CNN中训练鲁棒图像分割模型。由于大规模的3D模型训练集难以获得,我们的方法只需要少量的3D训练模型数据来生成几何图像,这些图像紧凑地捕获了规则域中的几何特征,使得用有限的3D牙齿数据训练CNN成为可能。我们使用交叉验证来评估我们方法的有效性。
由于图像分割的结果在边界处可能会有一定的偏差,并且二维网格与图像之间的投影和反向投影不是双射的(由于多个顶点映射到同一像素上),因此网格分割的边界不够精确。因此,我们采用并改进了模糊聚类和切割(FCC)方法[13]来解决这一问题。
FCC:是一种基于网络流算法[14]的网格分割方法。它可以在给定的模糊区域内检测出凹二面角最小的路径,从而将模糊区域划分为两部分,分割边界与几何特征对齐。我们改进了FCC方法,使分割边界更加精确和平滑,并考虑了边界区域中更密集的网格三角剖分。
贡献
1)提出了一种基于谐波参数空间的牙模型分割方法,该方法能够实现牙模型的自动准确分割,在正畸CAD系统中得到了很好的应用;
2)我们设计了一种CNN的图像分割方案,并通过数据增强生成一个独特的数据集,用于CNN的训练和测试。该模型对新的牙齿几何图像具有较强的鲁棒性和良好的泛化性能。
2)改进了模糊聚类和切割(FCC)方法,使其能够更准确地检测凹形分割边界,使分割边界更平滑
相关工作
一般网格分割 General mesh segmentation
三维网格分割是计算机图形学的一个重要组成部分。它根据一些合理的规则将网格分成不同的部分。常用的方法可分为两类:基于区域的方法和基于边界的方法。基于区域的方法是根据网格的几何信息将相似的区域聚集在一起。著名的基于区域的研究包括K-means[16,17]、聚类[18]、层次分解[13]、原始拟合[19]、网格[20]、随机漫步[21]。基于边界的方法检测网格的几何特征边界,将网格划分为不同的部分。这些方法包括随机切割[22]、模糊聚类切割(FCC)[13]、核心提取[23]、形状直径函数[24]、活动轮廓或剪切[25,26]、稀疏和低秩表示[27]。然而,这些方法过于依赖于网格的几何信息,一旦网格过于复杂,往往会失败。
由于网格可以有显著的变化,用全自动的方法将网格分割成所需的部分是具有挑战性的。另一方面,人工分割是劳动密集型和耗时的。因此基于草图(sketch-based)的半自动方法变得流行起来。它们为用户提供简单且用户友好的界面,以添加他们的建议作为起点或优化约束。例如,Ji等人提出了一种改进的区域增长分割算法。Fan等人采用了一种高效的基于局部图切的优化算法,获得了满意的结果。研究[30-33]将谐波场理论与基于草图的分割相结合,理论基础扎实,效果良好。Khan等人提出了一种立体交互分割方法来提高重划分质量。在他们的方法中,首先使用基于在线交互[35]的现有交互方法初始化网格分割,以捕获井盖的尖锐特征。然后使用顶点和边缘的局部操作来改进分割。然而,基于草图的方法需要在用户输入和自动计算之间达到平衡。
自普林斯顿分割基准[36]等三维网格数据库发布以来,数据驱动的网格分割方法应运而生。监督学习和半监督学习方法的目的都是学习一个模型,使用标记的训练集将网格分割成有意义的部分;最近的一些作品包括[37-40]。
牙网格分割 Dental mesh segmentation
已经提出了许多分割方法来分离牙齿模型。根据输入格式,我们将现有的方法分为两类:基于三维网格的方法和基于二维图像的方法。
三维:可进一步分为基于曲率的方法和基于谐波场的方法两类。基于曲率的方法占多数。Yuan等人[3]分析了三维牙齿模型的区域,并根据表面的最小曲率对其进行了分类。Zhao等人[41]提出了一种基于三角形网格曲率值的交互式分割方法。[4]设计的系统需要用户通过直观的滑块一次性设置一定的曲率阈值。其他基于蛇的活动轮廓法[5]、快速推进分水岭法[6]、形态骨架提取法[1]等都与曲率信息有一定的关系。基于谐波的方法是少数。邹等[42],廖等[43],李等[44]将谐波应用于齿面分割它只需要有限数量的表面点。节省了用户的时间,达到了合理的效果。
二维:基于投影图像的有效分割算法。Yamany和El-Bialy[2]将曲率和表面法线信息编码成二维图像,并设计了一种图像分割工具来提取高/低曲率的结构。类似地,Toshiaki等人提出了一种从激光扫描仪捕获的3D数字化图像中自动分割牙齿的方法。Grzegorzek等人提出了一种基于二维模型轮廓检索算法的三维牙列表面多阶段分割方法。Wongwaen et al.[47]将3D全景图像转换为二维空间,找到切点对单个牙齿进行分割,然后将二维图像转换回三维空间进行剩余操作。Xu等人。[11]使用了与[10]相似的一组特征,将网格的每个面编码为20 ×30图像。然后将这些图像输入到CNN中训练分割模型,最后使用网格分割细化算法对分割边界进行细化,取得了满意的结果。然而,该方法需要一个大的标记网格数据集进行训练。
方法
我们的方法以牙齿网格作为输入,目的是获得牙齿网格的每个顶点的标签。
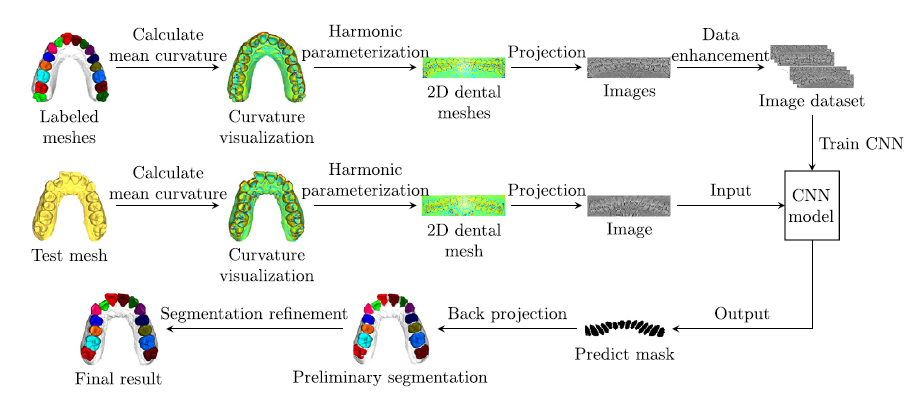
输入原始的齿网,经过一系列的处理,最终得到齿网各顶点的分割标签。
上图为对标记的齿网格进行谐波参数化、投影、数据增强等操作获得图像训练集的过程。
中图为通过类似操作从待分割网格中获取牙齿图像并输入CNN模型的过程。
下图为CNN网络输出的图像分割掩码,反向投影到机器上。
网格参数化 Mesh parameterization
(这块暂时不是很懂要是有写错翻错的地方欢迎指正,好图形学的方法!图形学直接攻击我!)
网格参数化的目的是寻找三维网格上的点到参数空间的一对一映射映射,在保持参数空间上的拓扑信息与原网格同构的同时,最小化某个几何度量的畸变。我们的牙齿网格是一个非封闭的零属三维表面,只有一个边界。在几何上,它与平面圆盘拓扑同构。假设曲面𝑀与平面空间中点(u, v)的相依关系(𝐷,v)的参数表达式为:
![]()
凸表示方法[48]是一种常用的曲面参数化方法,它将一个多边形边界𝜕D固定在平面D上,并将曲面M的边界𝜕M线性映射到𝜕D。然后用能量最小化法确定平面D内顶点的坐标(u, v)。我们的牙齿模型是通过扫描仪获得的,然后人工处理去除除了牙龈和牙齿以外的所有东西。(可恶,好大的工作量!)因此,得到的模型在空间上的整体形状类似于拱形,各模型的边界相似,如图2所示。
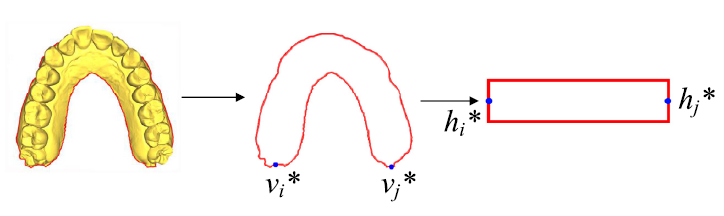
曲面参数化的目的是获得牙齿模型的几何图像,因此我们使用矩形作为平面D的边界,这样可以最小化图像冗余。此外,考虑到牙齿模型的特点和整体形状,我们将矩形的纵横比设置为4:1。为了将原始网格的边界𝜕M映射到矩形边界𝜕D,我们首先计算原始网格边界上具有最大测地线距离(geodesic distance)的两个顶点(𝑣∗,𝑣∗𝑗)。式中𝐷i𝑠_𝑔𝑒𝑜(𝑣i,𝑣𝑗)为v i与v j之间的测地线距离。然后,我们将(𝑣∗i,𝑣∗𝑗)固定到矩形的两个短边的中点为(h∗i,h∗𝑗),并将原始边界上的剩余顶点映射到矩形边界。图2为三维曲面边界𝜕M到平面边界𝜕D的映射过程。
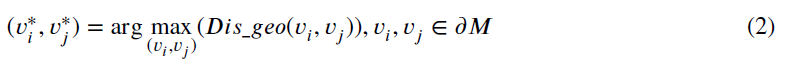
利用能量最小化法确定平面域D内顶点的坐标,只需要求解线性方程组,效率高,关键在于能量权值的选择。[12]提出了一种基于谐波映射的网格参数化方法。其能量功能设置如下。
其中hi是平面上的顶点D对应于原始网格的顶点v M, e i, j是顶点的边缘与M v i和j和弹簧常数𝜅i, j计算如下:每个边缘e i, j,让L i, j表示其长度来衡量在原始网格,和为每一个面临f i, j, k,让区域i, j, k表示它的面积,再以M。每条内沿ei,j与两个面(𝑓,𝑗,𝑘1)和(𝑓,𝑗,𝑘2)相关联。
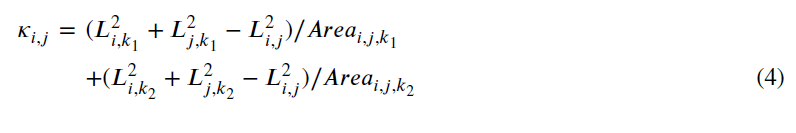
为了最大限度地减少Energe harm,我们求解这个稀疏线性方程组给出了平面D的每个内部顶点的坐标。
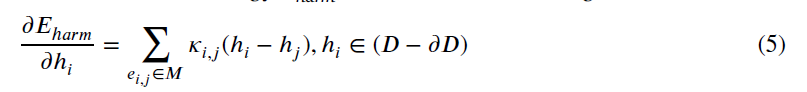
相邻牙齿之间的几何结构相当复杂,这个区域的顶点非常密集,每个三角形的面积都很小。所使用的谐波参数化保证了一对一的映射。然而,一旦离散成几何图像,多个三角形可能被映射到相同的像素。这往往只影响一小部分像素(通常是1或2个)。此外,我们的方法还有最后的分割和再细化步骤。这一步在原始模型上进行处理,以消除这种重叠对最终分割结果的影响。
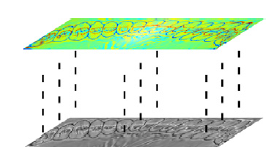
平面网格和图像的数据格式有很大的不同。我们将平面网格上的每个面投影到图像对应位置的像素上,并将曲率编码为像素强度值,生成宽高比为4:1的图像。然后我们计算离散网格的平均曲率,并根据Eq.(6)将曲率映射到[0,255]:

其中Cur (i)是顶点vi的平均曲率。由于网格数据具有亚像素级精度,因此增加图像分辨率可以保留更多细节。理论上,当图像分辨率足够高时,可以保证每个表面的信息被保留,但在实践中图像的维数不能太高。齿网格面数约为20万个,因此我们将平面齿网格投影到256张×1024图像上,达到了效率和精度的良好平衡。
图像分割 Image segmentation
将三维牙网格映射到谐波参数空间可以有效地避免平面牙网格上的顶点和面重叠,保证了映射的同构性。图像中的每个牙齿都是相互独立的,因此可以得到每个牙齿的完整分割mask。
与语义分割不同,实例分割需要区分一个类中的多个实体。然而,这些实例的特征非常相似,它们之间几乎没有区别。我们的牙齿几何图像将原始网格的曲率特征编码为像素。相邻的牙齿极为相似,但每颗牙齿与其他牙齿或牙龈的内界面具有明显且相对完整的负曲率特征。
我们参考U-Net的结构,设计了一个牙齿图像分割网络模型。使用的损失函数是交叉熵损失。
相邻牙齿的mask容易被错误连接,导致分割失败,因此我们做了以下两方面的改进:
1)缩小每颗牙齿的分割掩模范围,使分割掩模的边界在ground truth牙齿边界内,相当于扩大了相邻牙齿之间的边界,增强了每颗牙齿之间的独立性。
2)在齿边界处增加训练权值,我们的损失函数为:

其中,pi为预测值,p^为ground truth,i为整个图像的像素集,B为图像中的边界像素集,𝜌为边界权值。我们的统计数据显示,边界面积的平均比例约为5%,因此我们设置𝜌为 20来平衡这两项。
图像分割掩码和边界权值图如图3所示。

大规模的三维牙齿模型数据集很难获得,因此我们使用少量的三维牙齿模型生成几何图像,然后通过数据增强对几何图像进行鲁棒性训练。(增大四十倍!)
方法:旋转rotation,翻转flip,平移translation,正弦扰动Sinusoidal disturbance
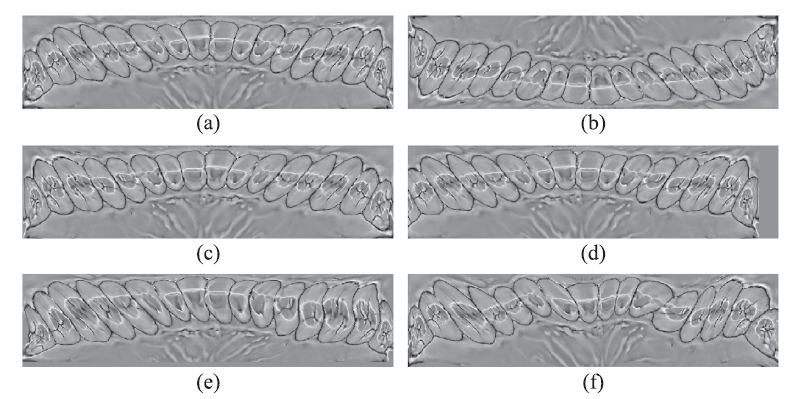
(a)为原始图像,(b)为180°旋转后的图像,(c)为水平变形后的图像,(d)为𝑣(0,- 50)平移后的图像,(e)为水平扰动后的图像,(f)为垂直扰动后的图像。
不同的牙网重建可能产生精度有很大差异的牙齿模型,这将导致估计曲线这些网格的曲率可能不同,因此响应图像的对比度会有很大差异。因此,我们对每张图像应用全局对比度归一化[49]来消除对比度差异带来的分割误差。
分割细化 Segmentation refinement
对图像进行分割后,得到mask。将mask反投影到原始网格中,得到n个牙齿的表面𝑀i,i= 1,2、…、𝑛,初步分割完成。假设每个齿的地面真值曲面为𝜕°,分割细化的目的是寻找地面真值分割边界𝜕°。𝑀对初步分割的结果进行分析。

如图5所示,在初步分割结果中,各个齿面边界𝜕M i一般都在地真齿边界𝜕²内,因此我们将表面m1向外延伸,形成一个表面𝑀’s,该表面预计包含地面真齿边界。则模糊区域为:
![]()
[13]提出了一种基于最大流量算法[50]的网格分割方法FCC,该方法能在给定的模糊区域内找到凹二面角最小的分割边界并将模糊区域划分为两部分。该方法首先构造一个无向图𝐺= < V,E> ,其中V为M - fi中的顶点集,E为M - fi中的边集。在集合V中增加两个虚拟节点s和t,分别代表源点和汇聚点。在E中添加边,将s连接到边界𝜕M i上的每个顶点,将t连接到边界𝜕𝑀’上的每个顶点。
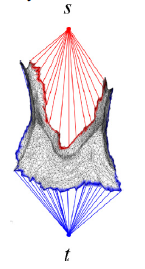
使用maximum-flow算法对网格进行分割,最重要的是如何设置每个边的容量Cap (i, j)。通常,相互接触的两个物体在结合面具有凹二面体和负曲率特征。通过检测这些特征,可以找到最合理的分割边界。[13]利用凹二面体特征,根据式(10)设置每条边的容量。
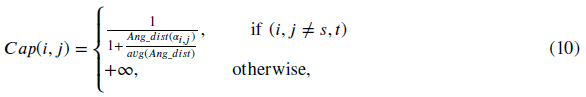
![]()
𝜂是 0到1之间的系数。凸角使用一个小的正值(通常为0.1),凹角使用𝜂= 1,因为凹边对分割更重要。
通过实验发现,结果并不理想。分割边界粗糙,甚至明显偏离地真齿边界𝜕^𝑀i这是因为三角形网格使用许多三角形补丁来近似3D物体表面,并且具有显著负曲率特征的区域的顶点和边缘往往比其他平坦区域密集得多。虽然这部分区域的每条边的权值较小,但由于大量边的积累,路径权值可能较大,因此权值最小的路径可能偏离地真齿边界𝜕^𝑀i。
因此我们的改进根据式(12)计算每条边的容量,其中边的长度也考虑在内:

lij是边的长度e1j。Cur (i, j)定义如下:
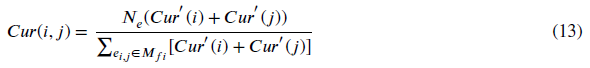
其中,Cur‘(i)与Eq.(6)相同,ne为M - fi中的边数。由式(12)可知,容量Cap our (i,j)是曲率项Cur (i,j)和边长项‖i,j‖2的乘积。曲率项用于检测负曲率特征,边长项限制了到达顶点和边缘密集区域的最短路径,消除了密集区域边缘数量过多带来的负面影响。经过以上改进,我们得到了更加精确和平滑的分割边界。
实验
硬件&数据集
好久没见这么低的配置了!
为了验证我们方法的有效性,我们制作了一个包含100个牙齿模型的数据集,并在专业牙医的帮助下完成了手工标记。这些模型来自几个不同的商业3D扫描仪设计,以测试我们的方法的普遍性。使用两种不同的扫描仪获取了120个牙模型的数据,两种扫描仪获得的牙模型三角形数分别为3万~ 9万个,20万~ 50万个。
评估指标
1) Accuracy
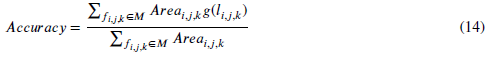
2)Directional Cut Discrepancy (DCD)
使用定向切割误差来计算分割边界的平均误差
好冷门的评估标准🤔
图像分割
unet baseline (这个地方可改进)
5折交叉验证
一般100 epoch之后就会过拟合,所以我们只训练100个epoch
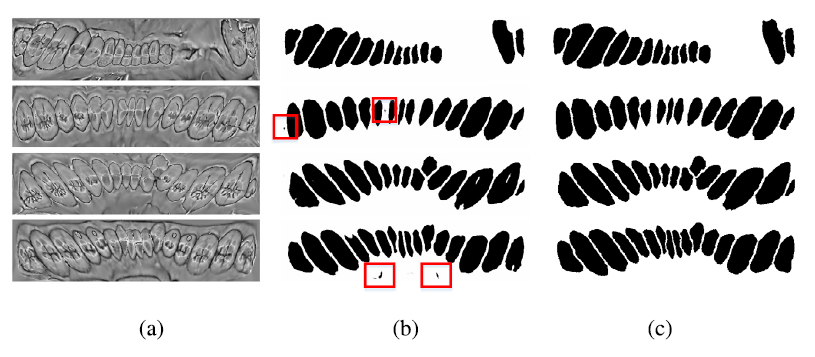
p7显示部分原始图像,预测面具和地面真相。红色框突出显示了预测掩码中不准确的部分,这将影响后续的分割。我们检测每个黑色区域的面积,并将面积小于阈值的区域作为噪声处理
实际上,每个牙网最多只有16颗牙齿。我们计算每个黑色区域的面积,并计算最大的16个区域的平均值,并将阈值设置为平均值的十分之一。(!这个去噪方法学到了!)
分割增强
在交叉验证过程中,对每个测试样例进行牙齿模型在几何图像域的分割。然后将图像分割掩模投影回牙网,得到初步分割结果。初步结果可以通过细分细化进一步改进,这是我们流水线的最后一步。对FCC算法进行了改进,并通过实验对改进前后的分割结果进行了比较。
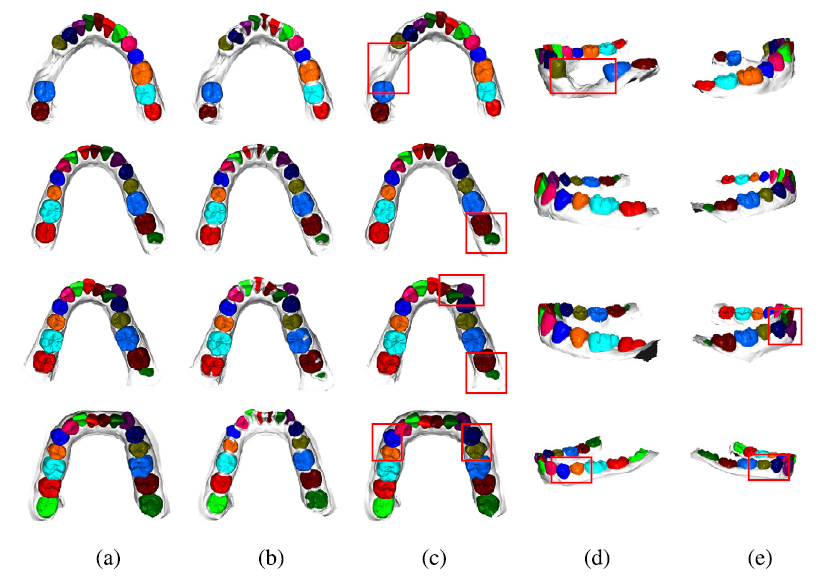
图8为部分模型的分割结果。红框表示复杂的区域,我们的方法仍然表现良好。(a)事实。(b)初步分割。(c)最后结果。(d)&(e)最终结果的其它角度。我们使用以下两种方法对结果进行综合分析。一是计算正确标记的面面积的百分比[10],表示为:
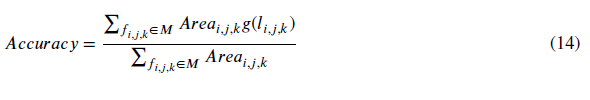
其中,区域i,j,k与式(4)相同,其中,i,j,k为面f i,j,k的预测标签。如果预测正确,G (i,j,k)为1,否则为0。由于我们的输出是网格顶点的标签,我们将顶点标签转换为面标签。在网格中,面f i,j,k的三个顶点(vi, v j, v k)有标签(i,j,k)。如果在这三个顶点标签中有两个或两个以上的标签是相同的,则标记i,j,k (f i,j,k)被分配为具有大多数数字的顶点标签。20张牙网的平均分割准确率达到98.87%。另一种方法是使用定向切割误差(DCD)[36]来计算分割边界的平均误差。大多数型号的DCD小于0.1 mm,所有型号的平均DCD为0.0458 mm。
实验结果
Fig9. 比较我们的分割改进方法和FCC的分割精度。
fig10. 比较我们的分割细化方法和FCC使用DCD措施

fig11. (a),(b)是FCC,(c)(d)是我们的
从图9和图10的结果可以看出,分割精度和边界误差与模型的面数有关。红框内的结果显示了精度较低、误差较大的结果。可以看出,分割精度高、边界误差小的模型往往具有更多的面。一般来说,模型的顶点和面越多,模型重建的质量越高。在两个物体的边界处,顶点和面密度比平面物体高,负曲率特征更明显。由于部分3D扫描设备的精度较低,负曲率特征不够明显,导致分割效果略差。

未来工作
我们的方法还有一些局限性。首先,为了满足网格参数化的输入条件,该方法要求齿形模型为非封闭的零属三维曲面,且只有一个边界。因此,在进行牙齿分割之前,需要进行繁琐的预处理操作。其次,神经网络预测的分割掩码误差不能太大,否则即使经过分割再细化步骤也难以找到准确的边界。如果预测的分割掩码中的噪声区域(图7红框部分)过大,将导致去噪过程失败。如果相邻牙齿的预测口罩相互连接,会导致这些牙齿被标记为一颗牙齿。因此,我们未来的工作是设计一个细化的子网来处理掩码边界的预测和去除噪声区域。第三,最终的分割精度仍然很大程度上依赖于最大流量算法。由于部分模型质量不高,最终得到的分割边界仍然粗糙,误差较大,因此我们计划在分割细化步骤中加入边界平滑条件,寻找更准确、更光滑的边界。最后,我们只有一个有限的数据集,只有120个牙齿模型。虽然我们设计了交叉验证和比较实验来证明我们的方法的可靠性,但有必要扩大数据集以使我们的方法更加可靠。

![[文件读取]coldfusion 文件读取 (CVE-2010-2861)](https://img-blog.csdnimg.cn/566c75cf4e22491383b185b8b33717f5.png)