系列文章
Hazelcast系列(一):初识hazelcast
Hazelcast系列(二):hazelcast集成(嵌入式)
Hazelcast系列(三):hazelcast集成(服务器/客户端)
Hazelcast系列(四):hazelcast管理中心
Hazelcast系列(五):Auto-Detection发现机制
Hazelcast系列(六):Multicast发现机制
Hazelcast系列(七):TCP-IP发现机制
Hazelcast系列(八):数据结构
Hazelcast系列(九):Map(一)加载和存储
目录
前言
加载和存储
加载
存储
应用
环境
实战
测试
测试加载
测试存储
其他
前言
Hazelcast的数据结构众多,这里就以 Map 为例,探讨一下 Hazelcast 数据结构操作相关的东西。
Hazelcast 针对数据结构的东西还是蛮多,这里咱们拆分为多个节点来阐述。
Hazelcast系列(十):Map(一)主要探讨 Map 加载、存储以及配置
Hazelcast系列(十):Map(二)主要探讨 Map 监听器、拦截器以及谓词
Hazelcast系列(九):Map(三)主要探讨 Map 备份、过期和驱逐以及内存格式
正式开始前,还是对 Map 做一个大概的描述。
Hazelcast Map( IMap) 扩展了接口java.util.concurrent.ConcurrentMap ,因此 java.util.Map,它是Java地图的分布式实现。可以使用众所周知的 get 和 put 方法执行诸如从 Hazelcast Map读取和写入 Hazelcast Map等操作。
当前 Hazelcast版本:5.1.7,Hazelcast模式:嵌入式。
加载和存储
在某些情况下,可能希望从关系数据库中加载数据和存储数据在关系数据库中。
Hazelcast 最常见的实现之一是作为外部存储系统(例如关系数据库)的前端缓存。Hazelcast 提供了一种方法,可以自动将数据加载到内存映射中,以实现更快的应用程序访问,并自动将更新写回外部存储以保持系统同步。
访问内存中数据的应用程序使用获取、放置或执行查询。当使用外部数据存储时,Hazelcast 集群成员独立于应用程序从该外部数据存储检索数据或向该外部数据存储写入数据。
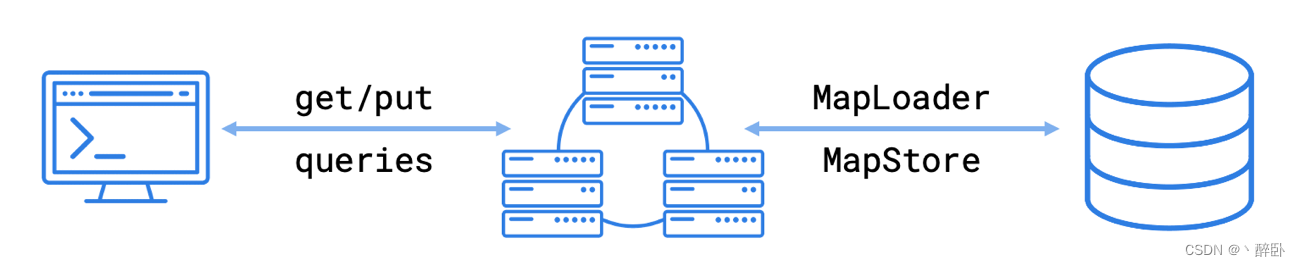
Hazelcast 提供了两个接口用于加载和存储:
MapLoader: 加载数据,当应用程序从地图请求值时,将调用该接口方法。如果内存中不存在请求的值,MapLoader.load() 方法会尝试从数据存储中加载它。一旦加载到内存中,映射数据就会一直保留,直到它被更改、movd 或逐出
MapStore:存储数据,继承了 MapLoader,所以该接口有 MapLoader 的全部功能,此外,该接口方法将对内存中映射数据的更新复制到数据存储
加载
通读持久性
实现 MapLoader 时,如果内存中不存在所请求的数据,map.get() 则会触发该方法,然后 load() 检索请求的数据,将其添加到 Hazelcast 内存中,这种自动加载称为通读持久性。
Map初始化
通读持久性将从外部数据存储中检索所请求的映射数据,但按请求检索每个单独的数据效率很低。相反,使用 MapLoader.loadAllKeys() 方法来预先填充内存中的映射效率很高。使用时,每个 Hazelcast 集群成员都会连接到数据库以检索其拥有的地图部分,这种并行处理是从数据存储中检索数据的最快方法。
Map 初始化方式有两种:EAGER 和 LAZY 。
EAGER:第一次创建或获取地图时会调用 MapLoader.loadAllKeys() 方法。所有集群成员都连接到数据库并加载其所有本地活动分区。这是一个阻塞操作;在所有集群成员加载其分区之前,应用程序将无法读取或写入映射。
LAZY:获取或创建地图后,当您首次使用的 IMap 操作之一访问地图时,会触发 MapLoader.loadAllKeys() 方法。LAZY 是默认模式。
加载过程
1. 初始化根据 initial-mode 属性的值开始。如果设置为 EAGER,则一旦创建映射(即调用时map.get() ),就会在所有分区上开始初始化。如果设置为 LAZY,则当某个操作或其他操作尝试从映射中读取时,将加载数据。
2. 接下来,MapLoader.loadAllKeys() 以获取其中一名成员的所有 Key。
3. 该集群成员将密钥批量分发给集群中其他成员。
4. 每个成员通过调用 MapLoader.loadAll(keys) 自己的密钥来加载其所有密钥的值。
5. 每个成员通过调用将其拥有的数据放入映射中 IMap.putTransient(key,value)
存储
直写持久性
直写持久性对映射和外部数据存储执行同步更新。实施后,map.put(key,value) 调用会按顺序触发以下操作:
1. 调用 MapStore.store(key,value) 这会将数据入外部数据存储。
2. 将数据写入内存中的主map
3. backup-count 如果已配置(即如果属性大于 0),则将数据写入备份map
后写持久性
后写持久性对外部数据存储执行异步更新。触发后,map.put(key,value) 调用会按顺序触发以下操作:
1. 将数据写入内存中的主map。
2. 将数据写入备份map(如果已配置)。
3. 将数据标记为“脏数据”,这时数据尚未写入外部存储。
4. 经过一段时间后,即 write-delay-seconds 时间后,调用 MapStore.storeAll 将数据写入外部存储
应用
环境
Pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.16</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.hazelcast</groupId>
<artifactId>HazelCastSpringBootDemo1</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>HazelCastSpringBootDemo1</name>
<description>HazelCastSpringBootDemo1</description>
<properties>
<java.version>8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.31</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
服务器
两台,当前是两个项目在两个不同的端口启动
实战
- 配置 hazelcast.yml
hazelcast:
cluster-name: hazelcast-cluster
instance-name: hzInstance_local
network:
port:
auto-increment: true
port-count: 100
port: 5701
outbound-ports:
- 0
join:
auto-detection:
enabled: false
multicast:
enabled: false
multicast-group: 224.2.2.3
multicast-port: 54327
tcp-ip:
enabled: true
member-list:
- 192.168.119.1
interfaces:
enabled: true
interfaces:
- 192.168.*.*
map:
mapcache:
backup-count: 1
async-backup-count: 1
map-store:
enabled: true
initial-mode: LAZY
class-name: com.hazelcast.hazelcastspringbootdemo1.config.HazelcastMapDataLoader
write-delay-seconds: 2
write-batch-size: 1000
write-coalescing: true
map之前的都是集群配置,这里不再赘述
说明:map.mapcache 生成一个名称为mapcache的map
map.mapcache.backup-count 同步备份数量,默认为1,最大为6
map.mapcache.async-backup-count 异步备份数量,默认为0
map.mapcache.map-store.enabled 启用此MapStore配置
map.mapcache.map-store.initial-mode 加载模式,默认为LAZY
map.mapcache.map-store.class-name 实现MapLoader/MapStore配置类
map.mapcache.map-store.write-delay-seconds 延迟写入毫秒数,为0为直写,否则为后写
map.mapcache.map-store.write-batch-size 批处理大小,后写模式下生效,最小为2
map.mapcache.map-store.write-coalescing 合并键更新操作,后写模式下生效,只保留最后一次更新
注意:1. Hazelcast 有一个默认名称为 default 的 Map,没额外需求可直接使用默认的,并配置
2. Hazelcast.map 下可以有多个map配置
- 配置MapStore
/**
* Hazelcast缓存map加载配置类
*/
public class HazelcastMapDataLoader implements MapStore<Long, StudentPo> {
@Override
public void store(Long no, StudentPo resumePo) {
SpringUtils.getBean(StudentMapper.class).insert(resumePo);
}
@Override
public void storeAll(Map<Long, StudentPo> map) {
if (Objects.nonNull(map) && map.isEmpty()) {
return;
}
//TODO 可批量插
StudentMapper studentMapper = SpringUtils.getBean(StudentMapper.class);
map.values().stream().forEach(item -> {
studentMapper.insert(item);
});
}
@Override
public void delete(Long no) {
LambdaQueryWrapper<StudentPo> queryWrapper = Wrappers.<StudentPo>lambdaQuery()
.eq(StudentPo::getNo, no);
StudentMapper studentMapper = SpringUtils.getBean(StudentMapper.class);
studentMapper.delete(queryWrapper);
}
@Override
public void deleteAll(Collection<Long> collection) {
LambdaQueryWrapper<StudentPo> queryWrapper = Wrappers.<StudentPo>lambdaQuery()
.in(StudentPo::getNo, collection);
StudentMapper studentMapper = SpringUtils.getBean(StudentMapper.class);
studentMapper.delete(queryWrapper);
}
@Override
public StudentPo load(Long no) {
LambdaQueryWrapper<StudentPo> queryWrapper = Wrappers.<StudentPo>lambdaQuery()
.eq(StudentPo::getNo, no);
StudentMapper studentMapper = SpringUtils.getBean(StudentMapper.class);
return studentMapper.selectOne(queryWrapper);
}
@Override
public Map<Long, StudentPo> loadAll(Collection<Long> collection) {
LambdaQueryWrapper<StudentPo> queryWrapper = Wrappers.<StudentPo>lambdaQuery()
.in(StudentPo::getNo, collection);
StudentMapper studentMapper = SpringUtils.getBean(StudentMapper.class);
List<StudentPo> resultPoList = studentMapper.selectList(queryWrapper);
return resultPoList.parallelStream().collect(Collectors.toMap(StudentPo::getNo, Function.identity()));
}
@Override
public Iterable<Long> loadAllKeys() {
//TODO 可自定义sql查
StudentMapper studentMapper = SpringUtils.getBean(StudentMapper.class);
List<StudentPo> resultPoList = studentMapper.selectList(new QueryWrapper<>());
return resultPoList.parallelStream().map(StudentPo::getNo).collect(Collectors.toList());
}
}
说明:1. 这里类必须要实现MapLoader/MapStore
2. 这里配合 Mybatis-Plus 操作数据库,通过 SpringUtils 获取 Mapper Bean 调用
3. 这里操作的 key 必须唯一并且一致
- 下面就是一些项目相关类和配置,可跳过,项目相关Po
@Data
@TableName("student")
public class StudentPo implements Serializable {
@TableId(type = IdType.AUTO)
private Long id;
@TableField
private Long no;
@TableField
private String name;
@TableField
private String sex;
@TableField
private Integer score;
}- 项目相关常量
public interface HazelcastConstants {
String HAZECAST_MAP_CACHE = "mapcache";
}
- 项目相关Controller
@RestController
@RequestMapping("/student")
public class StudentController {
@Autowired
private HazelcastInstance hazelcastInstance;
private ConcurrentMap<Long, StudentPo> retrieveMap() {
return hazelcastInstance.getMap(HazelcastConstants.HAZECAST_MAP_CACHE);
}
@PostMapping("/one")
public String addOne(@RequestBody StudentPo studentPo) {
retrieveMap().put(studentPo.getNo(), studentPo);
return "插入成功";
}
@GetMapping("/one/{no}")
public StudentPo getOne(@PathVariable Long no) {
return retrieveMap().get(no);
}
}- 项目相关Mapper
public interface StudentMapper extends BaseMapper<StudentPo> {
}
- 项目相关yml
server:
port: 8084
servlet:
context-path: /hazelcast
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.119.141:3307/demo
username: root
password: 123456
测试
同一份代码复制两份进行测试,开启不同的端口
测试加载
- 分别启动 Node1 和 Node2,登录 management-center 查看当前状态
- 当前管理中心有两个成员,但是没有对应的 map ,为啥?因为是 LAZY 模式。接下来,发起一个 GET 请求 localhost:8083/hazelcast/student/one/3,然后再查看管理中心相应值

- 获取到了数据库中的所有数据,并且已经放在不同的节点不同的分区里面,图上面还有 获取次数 和 命中次数,测试成功
测试存储
- 发起一个 POST 请求 localhost:8083/hazelcast/student/one,查看管理中心

- 数据总数 和 Puts 都已经增加,此外,也可查看对应的数据,测试成功
其他
- Hazelcast 的加载和存储就是缓存一致性的一种解决方式之一
- hazelcast 的 mapStore,其所有方法中操作的 key 必须一致
- MapLoader.loadAllKeys() 方法的实现返回一个 null 值,则不会加载任何内容
- 放在缓存中的类必须实现序列化,此外,如果需要优化,序列化可选择,可自定义序列化器