目录
一、资源限制:
1. 资源限制的两种规范:
2. Pod 和 容器 的资源请求和限制:
3. CPU 资源单位:
4. 内存资源单位 :
5. 资源限制示例:
二、健康检查:探针(Probe)
1. 探针的三种规则:
2. 探针健康检查机制的优势:
3. Probe支持三种检查方法:
每次探测都将获得以下三种结果之一:
3. 探针探测参数:
4. 示例:
4.1 livenessProbe(exec):
4.2 livenessProbe(httpGet方式):
4.3 tcpSocket方式:
三、启动、退出动作:
一、资源限制:
当定义 Pod 时可以选择性地为每个容器设定所需要的资源数量。 最常见的可设定资源是 CPU 和内存大小,以及其他类型的资源。
1. 资源限制的两种规范:
- requests :用于设置预留资源,指定了 request 资源时,调度器就使用该信息来决定将 Pod 调度到哪个节点上。 设置Pod容器创建时需要预留的资源量
- limits: 用于限制运行时容器的最大占用资源,当容器占用资源超过limits时会被终止,并进行重启 设置Pod容器能够使用的最大资源量
如果给容器设置了内存的 limit 值,但未设置内存的 request 值,Kubernetes 会自动为其设置与内存 limit 相匹配的 request 值。 类似的,如果给容器设置了 CPU 的 limit 值但未设置 CPU 的 request 值,则 Kubernetes 自动为其设置 CPU 的 request 值 并使之与 CPU 的 limit 值匹配。
2. Pod 和 容器 的资源请求和限制:
spec.containers[].resources.requests.cpu //定义创建容器时预分配的CPU资源
spec.containers[].resources.requests.memory //定义创建容器时预分配的内存资源
spec.containers[].resources.limits.cpu //定义 cpu 的资源上限
spec.containers[].resources.limits.memory //定义内存的资源上限
3. CPU 资源单位:
- CPU 资源的 request 和 limit 以 cpu 为单位。Kubernetes 中的一个 cpu 相当于1个 vCPU(1个超线程)。
- Kubernetes 也支持带小数 CPU 的请求。spec.containers[].resources.requests.cpu 为 0.5 的容器能够获得一个 cpu 的一半 CPU 资源(类似于Cgroup对CPU资源的时间分片)。表达式 0.1 等价于表达式 100m(毫核),表示每 1000 毫秒内容器可以使用的 CPU 时间总量为 0.1*1000 毫秒。
- Kubernetes 不允许设置精度小于 1m 的 CPU 资源。
4. 内存资源单位 :
内存的 request 和 limit 以字节为单位。可以以整数表示,或者以10为底数的指数的单位(E、P、T、G、M、K)来表示, 或者以2为底数的指数的单位(Ei、Pi、Ti、Gi、Mi、Ki)来表示。
如:1KB=10^3=1000,1MB=10^6=1000000=1000KB,1GB=10^9=1000000000=1000MB
1KiB=2^10=1024,1MiB=2^20=1048576=1024KiB
- PS:在买硬盘的时候,操作系统报的数量要比产品标出或商家号称的小一些,主要原因是标出的是以 MB、GB为单位的,1GB 就是1,000,000,000Byte,而操作系统是以2进制为处理单位的,因此检查硬盘容量时是以MiB、GiB为单位,1GiB=2^30=1,073,741,824,相比较而言,1GiB要比1GB多出1,073,741,824-1,000,000,000=73,741,824Byte,所以检测实际结果要比标出的少一些。
5. 资源限制示例:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: nginx01
name: nginx01
spec:
containers:
- image: nginx
name: nginx01
ports:
- containerPort: 80
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
- name: db
image: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: "abc123"
resources:
requests:
memory: "512Mi"
cpu: "0.5"
limits:
memory: "1Gi"
cpu: "1"
kubectl describe pod nginx01 #查看pod资源
kubectl describe node node01 #查看node资源

特殊容器,资源限制不能太低,例如mysql 内存不能低于512,否则会报OOM
二、健康检查:探针(Probe)
yaml文件配置中与image同
1. 探针的三种规则:
- livenessProbe :判断容器是否正在运行。如果探测失败,则kubelet会杀死容器,并且容器将根据 restartPolicy 来设置 Pod 状态。 如果容器不提供存活探针,则默认状态为Success。
- readinessProbe :判断容器是否准备好接受请求。如果探测失败,端点控制器将从与 Pod 匹配的所有 service endpoints 中剔除删除该Pod的IP地址。 初始延迟之前的就绪状态默认为Failure。如果容器不提供就绪探针,则默认状态为Success。
- startupProbe(这个1.17版本增加的):判断容器内的应用程序是否已启动,主要针对于不能确定具体启动时间的应用。如果配置了 startupProbe 探测,则在 startupProbe 状态为 Success 之前,其他所有探针都处于无效状态,直到它成功后其他探针才起作用。 如果 startupProbe 失败,kubelet 将杀死容器,容器将根据 restartPolicy 来重启。如果容器没有配置 startupProbe, 则默认状态为 Success。
#注:以上规则可以同时定义。在readinessProbe检测成功之前,Pod的running状态是不会变成ready状态的。
2. 探针健康检查机制的优势:
- 精确控制健康状态: 探针允许你以更细粒度的方式定义容器的健康状态。通过定义自定义的检查逻辑,你可以确保容器的健康状态与你的应用程序的实际需求相匹配。
- 动态调整: 探针的配置允许你动态地调整健康检查的频率、超时和失败阈值等参数。这使得你可以根据应用程序的特性和环境的变化来优化健康检查的性能和准确性。
- 更好的故障处理: 使用探针可以帮助 Kubernetes 更快速、可靠地检测到容器的故障。这对于自动缩放、滚动升级和故障转移等场景非常重要,因为它能够更迅速地发现并替换不健康的容器。
- 避免不必要的流量: 控制器(如 Deployment)默认会在 Pod 启动后立即将其标记为 "就绪"。如果没有 readinessProbe,可能会导致流量被引导到尚未完全启动或初始化的容器。通过设置 readinessProbe,你可以确保只有在容器真正就绪时才将其加入服务负载均衡。
总的来说,使用探针提供了更大的灵活性和控制,使你能够根据应用程序的需求和特性进行定制,从而提高容器的可靠性和性能。
3. Probe支持三种检查方法:
- exec :在容器内执行指定命令。如果命令退出时返回码为0则认为诊断成功。
- tcpSocket :对指定端口上的容器的IP地址进行TCP检查(三次握手)。如果端口打开,则诊断被认为是成功的。
- httpGet :对指定的端口和uri路径上的容器的IP地址执行HTTPGet请求。如果响应的状态码大于等于200且小于400,则诊断被认为是成功的
每次探测都将获得以下三种结果之一:
- 成功(Success):表示容器通过了检测。
- 失败(Failure):表示容器未通过检测。
- 未知(Unknown):表示检测没有正常进行。
3. 探针探测参数:
- initialDelaySeconds:指定容器启动后延迟探测的秒数
- periodSeconds:指定每次探测间隔的秒数
- failureThreshold:探测连续失败判断整体探测失败的次数
- timeoutSeconds:指定探测超时等待的秒数
4. 示例:
4.1 livenessProbe(exec):
apiVersion: v1
kind: Pod
metadata:
name: wzw01
spec:
containers:
- image: busybox
name: busybox01
ports:
- containerPort: 80
args:
- /bin/sh
- -c
- touch /tmp/test.txt; sleep 30; rm -rf /tmp/test.txt; sleep 60;
livenessProbe:
exec:
command:
- /bin/sh
- cat
- /tmp/test.txt
failureThreshold: 1 连续探测失败一次则下线容器
initialDelaySeconds: 5 第一次探测的开始时间
periodSeconds: 5 每次探测的间隔时间
4.2 livenessProbe(httpGet方式):
apiVersion: v1
kind: Pod
metadata:
name: wzw02
spec:
containers:
- image: nginx
name: wzw-nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
livenessProbe:
httpGet:
port: 80
path: /wzw.html #/index.html
failureThreshold: 2
initialDelaySeconds: 5
periodSeconds: 5


4.3 tcpSocket方式:
apiVersion: v1
kind: Pod
metadata:
name: wzw02
spec:
containers:
- image: nginx
name: wzw-nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
readinessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 20
periodSeconds: 5
这个例子同时使用 readinessProbe 和 livenessProbe 探测。kubelet 会在容器启动 5 秒后发送第一个 readinessProbe 探测。这会尝试连接 nginx 容器的 80 端口。如果探测成功,kubelet 将继续每隔 5 秒运行一次检测。除了 readinessProbe 探测,这个配置包括了一个 livenessProbe 探测。kubelet 会在容器启动 20 秒后进行第一次 livenessProbe 探测。就像 readinessProbe 探测一样,会尝试连接 nginx 容器的 80 端口。如果 livenessProbe 探测失败,这个容器会被重新启动。

readinessProbe探测失败,无法进入READY状态

三、启动、退出动作:
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: soscscs/myapp:v1
lifecycle: #此为关键字段
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler >> /var/log/nginx/message"]
preStop:
exec:
command: ["/bin/sh", "-c", "echo Hello from the poststop handler >> /var/log/nginx/message"]
volumeMounts:
- name: message-log
mountPath: /var/log/nginx/
readOnly: false
initContainers:
- name: init-myservice
image: soscscs/myapp:v1
command: ["/bin/sh", "-c", "echo 'Hello initContainers' >> /var/log/nginx/message"]
volumeMounts:
- name: message-log
mountPath: /var/log/nginx/
readOnly: false
volumes:
- name: message-log
hostPath:
path: /data/volumes/nginx/log/
type: DirectoryOrCreatekubectl get pods -o wide #在node02节点
kubectl exec -it lifecycle-demo -- cat /var/log/nginx/message
##进入pod查看文件
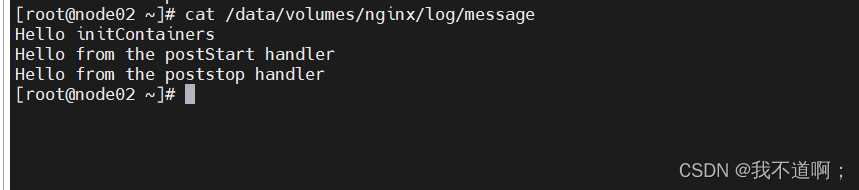
cat /data/volumes/nginx/log/message
由上可知,init Container先执行,然后当一个主容器启动后,Kubernetes 将立即发送 postStart 事件。

- 删除 pod 后,再在 node02 节点上查看
kubectl delete pod lifecycle-demo
cat /data/volumes/nginx/log/message 由此可知,当在容器被终结之前, Kubernetes 将发送一个 preStop 事件。