写屏障
上面使用记忆集解决了缩减GC Roots扫描范围的问题,现在又抛出来一个新的问题,卡表元素如何维护的呢?,例如它们何时变脏、谁来把它们变脏等。
何时变脏这个问题应该很明确的,原则上应该发生在引用类型字段赋值的那一刻。
但问题是如何变脏,即如何在对象赋值的那一刻去更新维护卡表呢?
假如是解释执行的字节码,那相对好处理,虚拟机负责每条字节码指令的执行,有充分的介入空间;但在编译执行的场景中呢?经过即时编译后的代码已经是纯粹的机器指令流了,这就必须找到一个在机器码层面的手段,把维护卡表的动作放到每一个赋值操作之中。
在HotSpot虚拟机里是通过写屏障(Write Barrier)技术维护卡表状态的。写屏障可以看作在虚拟机层面对“引用类型字段赋值”这个动作的AOP切面,在引用对象赋值时会产生一个环形(Around)通知,供程序执行额外的动作,也就是说赋值的前后都在写屏障的覆盖范畴内。在赋值前的部分的写屏障叫作写前屏障(Pre-Write Barrier),在赋值后的则叫作写后屏障(Post-Write Barrier)。HotSpot虚拟机的许多收集器中都有使用到写屏障,但直至G1收集器出现之前,其他收集器都只用到了写后屏障。
当时看到这里,还是不明白怎么对即时编译后的代码(已经是纯粹的机器指令流)应用写屏障(机器码指令流都已经生成好了)。
原来应用写屏障后,对即时编译后的代码所生成的指令流,已经包含所有赋值操作相应的更新卡表逻辑的指令了。
另外,一旦收集器在写屏障中增加了更新卡表操作,无论更新的是不是老年代对新生代对象的引用,每次只要对引用进行更新,就会产生额外的开销,不过这个开销与Minor GC时扫描整个老年代的代价相比还是低得多的。
除了写屏障的开销外,卡表在高并发场景下(基本是必然的)还面临着“伪共享”(False Sharing)问题。伪共享是处理并发底层细节时一种经常需要考虑的问题,现代中央处理器的缓存系统中是以缓存行(Cache Line)为单位存储的,当多线程修改互相独立的变量时,如果这些变量恰好共享同一个缓存行,就会彼此影响(写回、无效化或者同步)而导致性能降低,这就是伪共享问题。
尽管上面解释了一番,u1s1,我当时看到这里还是懵的,因为在此之前我还不知道什么是伪共享。不知道在座的各位有没有跟我一样的…/手动捂脸
如何理解伪共享?
了解过MySQL 的索引结构以及MySQL 内存的应该都知道,查询磁盘时、或者更新内存时也是已页为单位。比如你查询一个主键id 去查库。如果内存中没有,就会去查磁盘。那么在查询磁盘过程中(脑部B+ 树的数据结构),由上往下遍历树索引的的过程中,是一个节点一个节点(一页一页)的加载到内存中的。
为什么以页为单位?我认为是因为空间局部性或者经验法则吧,临近的数据在将来被访问的可能性大。
再回到计算机的缓存,当 CPU 把内存的数据载入 cache 时,会把临近的共 64 Byte 的数据一同放入同一个缓存行,可以理解是以缓存行(Cache Line)为单位存储的。
那这样会存在什么问题?看一下下面这个Java 多线程程序的例子:
public class FalseSharingDemo {
// 前提知识:
// 1. Java对象的相邻成员变量大概率也会加载到同一缓存行中
// 2. 做一个循环计数, 会把计数变量放到缓存里,就不用每次循环都往内存存取数据了
private static class Pair {
// 所以在一个缓存行中,如果有一个线程在读取a时,会顺带把b带出
volatile long a;// 一个缓存行64 字节,a属性 8个字节
volatile long b;
}
private static void testPointer(Pair pair) throws InterruptedException {
long start = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 100000000; i++) {
pair.a++;
}
}, "对 Pair 对象中的变量 a 进行 ++ 操作");
Thread t2 = new Thread(() -> {
for (int i = 0; i < 100000000; i++) {
// 由于 b 和 a 在同一个缓存行,会导致线程t2 在读取缓存行会失效。需要重新在内存中重新加载进缓存。
pair.b++;
}
},"对 Pair 对象中的变量 b 进行 ++ 操作");
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("两个线程并发时的总耗时:" + (System.currentTimeMillis() - start);
}
public static void main(String[] args) throws InterruptedException {
// 测试肉眼可见的并发伪共享问题
testPointer(new Pair());
}
}
运行结果:
两个线程并发时的总耗时:2085
稍微调整下代码:
private static class Pair {
volatile long a;
// 新增的属性
long p1, p2, p3, p4, p5, p6, p7;
volatile long b;
}
再次运行,运行结果如下:
两个线程并发时的总耗时:279
可以发现,修改前后,程序的运行时间基本相差10 倍。
为什么会这样?回到程序中注释中寻找答案。修改前缓存行如何?修改后缓存行如何变化?口头分析
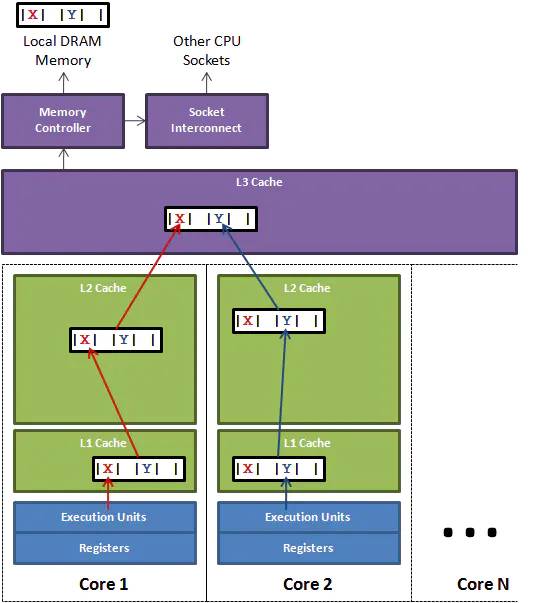
所以我理解伪共享就是:当多线程修改互相独立的变量时,如果这些变量恰好共享同一个缓存行,就会彼此影响而导致性能降低。(比如上面例子线程t1所在的core1在写回缓存时会把t2 线程core 2的缓存失效,那么在线程t2 得直接写回内存了了。那么下一次t2需要在读取的时候,需要在内存中在读进处理器2的缓存。)(结果就是导致基本每一次读都需要重新读进缓存。)
天下没有免费的午餐,技术在解决一个问题的同时,往往甚至必然会带来另外一个问题。就比如引入缓存,提高了读取性能,但同时带来了并发三个特性之一的可见性问题,又比如为了提高命中率,以缓存行为最小单位,同时也带来了并发时的伪共享问题,反而被拖慢了(引入多线程带来上下文切换开销以及原子性问题。,编译优化带来并发的有序性问题)。所以在采用一项技术的同时,一定要清楚它带来的问题是什么,以及如何规避。
那一般如何解决这个问题:
-
如上,我们可以使用数据填充的方式来避免,即单个数据填充满一个CacheLine。这本质是一种空间换时间的做法
-
Java 8 中已经提供了官方的解决方案,Java 8 中新增了一个注解:
@sun.misc.Contended。加上这个注解的类会自动补齐缓存行,需要注意的是此注解默认是无效的,需要在 jvm 启动时设置-XX:-RestrictContended才会生效。(ConcurrentHashMap存在这个注解的应用)
有了伪共享的基础,我们再回来看卡表在高并发场景下(基本是必然的)如何解决“伪共享”(False Sharing)问题?
假设处理器的缓存行大小为64字节,由于一个卡表元素占1个字节,64个卡表元素将共享同一个缓存行。这64个卡表元素对应的卡页总的内存为32KB(64×512字节),也就是说如果不同线程更新的对象正好处于这32KB的内存区域内,就会导致更新卡表时正好写入同一个缓存行而影响性能。
为了避免伪共享问题,一种简单的解决方案是采用条件的写屏障,先检查卡表标记,只有当该卡表元素未被标记过时才将其标记为变脏。
在JDK 7之后,HotSpot虚拟机增加了一个新的参数-XX:+UseCondCardMark,用来决定是否开启卡表更新的条件判断。开启会增加一次额外判断的开销,但能够避免伪共享问题,两者各有性能损耗,是否打开要根据应用实际运行情况来进行测试权衡。
参考文章:
https://blog.csdn.net/AZHELL/article/details/73740048
https://zhuanlan.zhihu.com/p/187593289