文章目录
- 语法分析器的功能
- 自上而下分析面临的问题
- LL(1)分析法
- 左递归的消除
- 直接左递归
- 非直接左递归
- 消除左递归的算法
- 消除回溯、提左因子
- FIRST
- 提左因子
- FOLLOW集
- LL(1)的分析条件
- LL(1)文法
- 构造FIRST和FOLLOW集合
- 构造每个文法符号的FIRST集合
- 构造FOLLOW集合
- 递归下降分析程序
- 递归下降分析程序
- 文法的另一种表示方法和转换图
- 预测分析程序
- 预测分析程序的工作过程
- 预测分析表的构造
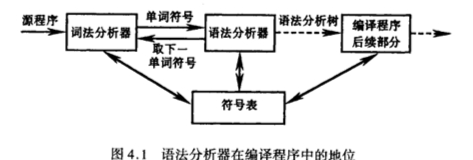
语法分析器的功能
语法分析器是编译过程的核心部分。任务是在词法分析识别出的单词符号串的基础上,分析并判定程序的语法结构是否符合语法规则。
自上而下分析面临的问题
- 左递归: p − > p α ∣ β {p}->{p}{\alpha}|{\beta} p−>pα∣β:会使程序陷入死循环,导致不可实现
- 回溯:试探法就是穷举所有可能,一旦遇到不匹配就进行回溯,尝试下一种可能,这种方法只在理论上有意义,由于回溯穷举时间开销巨大所以不太具有实践意义。
LL(1)分析法
左递归的消除
直接左递归
直接左递归的形式:
p
−
>
p
α
∣
β
{p}->{p\alpha}|{\beta}
p−>pα∣β
β
{\beta}
β不以
p
{p}
p开头
这个推导:
p
=
>
p
α
=
>
p
α
α
=
>
.
.
.
=
>
β
α
.
.
.
.
α
{p => p\alpha => p\alpha\alpha => ... => \beta\alpha....\alpha}
p=>pα=>pαα=>...=>βα....α
从这个推到我们可以看出
p
{p}
p推出的串是以
β
{\beta}
β后面跟着若干个
α
{\alpha}
α组成的串
这样我没对这个串做等价变换:
p
−
>
β
p
′
{p->\beta p'}
p−>βp′
p
′
−
>
α
p
′
∣
ϵ
{p'->\alpha p'|\epsilon}
p′−>αp′∣ϵ
我们可以验证这个文法是不是和上面左递归形式的文法等价,我们对这个文法做推导看看会推导出哪些串
p
=
>
β
p
′
=
>
β
α
p
′
=
>
.
.
.
=
>
β
α
.
.
.
α
{p => \beta p' => \beta \alpha p' => ... => \beta \alpha ...\alpha}
p=>βp′=>βαp′=>...=>βα...α
我们得到的串同样是以
β
{\beta}
β开头后面接跟着若干个
α
{\alpha}
α的串
我们对上面的结论进行推广:
对于P的全部产生式是
P
−
>
P
α
1
∣
P
α
2
∣
.
.
.
∣
P
α
m
∣
β
1
∣
β
2
∣
.
.
.
∣
β
n
,
其中每个
α
都不以
ϵ
开头
,
每个
β
都不以
P
开头
{P -> P\alpha_1|P\alpha_2|...|P\alpha_m|\beta_1|\beta_2|...|\beta_n},其中每个{\alpha}都不以{\epsilon}开头,每个\beta都不以P开头
P−>Pα1∣Pα2∣...∣Pαm∣β1∣β2∣...∣βn,其中每个α都不以ϵ开头,每个β都不以P开头
我们直接进行右递归改造:
P
−
>
β
1
P
’
∣
β
2
P
’
∥
.
.
.
∣
b
e
t
a
n
P
’
{P -> \beta_1P’|\beta_2P’\|...|beta_nP’}
P−>β1P’∣β2P’∥...∣betanP’
P
’
−
>
α
1
P
’
∣
α
2
P
’
∣
.
.
.
∣
α
m
P
′
{P’->\alpha_1P’|\alpha_2P’|...|\alpha_mP'}
P’−>α1P’∣α2P’∣...∣αmP′
例子:
E − > E + T ∣ T {E->E+T|T} E−>E+T∣T
T − > T ∗ F ∣ F {T->T*F|F} T−>T∗F∣F
F − > ( E ) ∣ i {F->(E)|i} F−>(E)∣i
对于第一个式子有直接左递归我们进行消除,首先第一个式子最终的推导串是以 T {T} T开头后面若干个{+T}我们进行等价变换: E − > T E ′ {E->TE'} E−>TE′ E ′ − > + T E ′ ∣ ϵ {E'->+TE'|\epsilon} E′−>+TE′∣ϵ
对于第二个式子也是直接左递归的我们也需要进行消除,首先第二个式子最终推导出的串的形式下以 F {F} F开头后面若干个*F,我们根据这个进行等价变换
T − > F T ′ {T->FT'} T−>FT′
T ′ ∗ F T ′ ∣ ϵ {T'*FT'|\epsilon} T′∗FT′∣ϵ
最后一个式子没有直接左递归不用进行处理
非直接左递归
文法
G
(
S
)
文法G(S)
文法G(S)
S
−
>
Q
c
∣
c
{S -> Qc|c}
S−>Qc∣c
Q
−
>
R
b
∣
b
{Q -> Rb|b}
Q−>Rb∣b
R
−
>
S
a
∣
a
{R -> Sa|a}
R−>Sa∣a
形式上这个文法并没有直接左递归,但是实际上这个文法是左递归的,进行如下推导就可以看出
S
=
>
Q
c
=
>
R
b
c
=
>
S
a
b
c
{S => Qc => Rbc => Sabc}
S=>Qc=>Rbc=>Sabc
经过推导我们发现S实际上是左递归的
我们从上面的文法可以看出S是由Q定义的,Q是由R定义的,R是由S定义的,那么我们可以得到下图
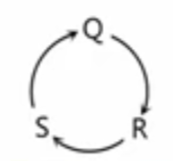
S
−
>
Q
c
∣
c
{S -> Qc|c}
S−>Qc∣c
Q
−
>
R
b
∣
b
{Q -> Rb|b}
Q−>Rb∣b
R
−
>
S
a
∣
a
{R -> Sa|a}
R−>Sa∣a
我们将Q中的R替换掉
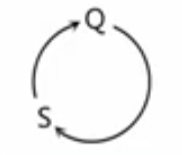
S
−
>
Q
c
∣
c
{S -> Qc|c}
S−>Qc∣c
Q
−
>
S
a
b
∣
a
b
∣
b
{Q -> Sab|ab|b}
Q−>Sab∣ab∣b
R
−
>
S
a
∣
a
{R -> Sa|a}
R−>Sa∣a
再将S中的Q替换掉
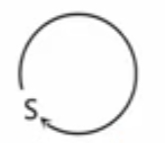
S
−
>
S
a
b
c
∣
a
b
c
∣
b
c
∣
c
{S ->Sabc|abc|bc|c}
S−>Sabc∣abc∣bc∣c
Q
−
>
S
a
b
∣
a
b
∣
b
{Q -> Sab|ab|b}
Q−>Sab∣ab∣b
R
−
>
S
a
∣
a
{R -> Sa|a}
R−>Sa∣a
消除左递归的算法
1.把文法G的所有非终结符按任意一种顺序排列成
P
1
P
2
,
.
.
.
,
P
n
{P_1 P_2, ... ,P_n}
P1P2,...,Pn按此顺序执行
2.
F
O
R
i
:
=
1
T
O
n
D
O
FOR\quad i:=1\quad TO\quad n\quad DO
FORi:=1TOnDO
B
E
G
I
N
BEGIN
BEGIN
F
O
R
j
:
=
1
T
O
i
−
1
D
O
\quad \quad FOR \quad j:=1 \quad TO \quad i-1\quad DO
FORj:=1TOi−1DO
$ \quad \quad 把形如P_i->P_j \gamma 的规则改写成,P_i-> \delta_1 \gamma|\delta_2 \gamma|…|\delta_k \gamma (其中P_j -> \delta_1|\delta_2|…|\delta_k是关于P_j的所有规则) $
消除回溯、提左因子
FIRST
为了消除回溯,我们首先需要引入两个概念一个是FIRST集一个是FOLLW集
FIRST:
零G是一个不含左递归的文法,对G的所有非终结符的每一个候选
α
\alpha
α定义它的终结首符集
F
I
R
S
T
(
α
)
FIRST(\alpha)
FIRST(α)

那么当要求A匹配输入串时,A就能根据它所面临的第一个输入符号a,准确地指派某一个候选前去。这个候选就是那个首符集含
a
a
a的
α
\alpha
α
提左因子
很多文法都存在不满足所有候选式的终结首符集不两两相交的。我们采用提取公共左因子的办法
假设关于A的规则是:
A
→
δ
β
1
∣
δ
β
2
∣
.
.
.
∣
δ
β
n
∣
γ
1
∣
γ
2
∣
.
.
.
∣
γ
m
,
(
其中
,
每个
γ
不以
δ
开头
)
{A\rightarrow \delta \beta_1 | \delta \beta_2 | ... |\delta \beta_n| \gamma_1 | \gamma_2| ... | \gamma_m} \quad ,(其中,每个 \gamma 不以 \delta 开头)
A→δβ1∣δβ2∣...∣δβn∣γ1∣γ2∣...∣γm,(其中,每个γ不以δ开头)
那么可以把这些规则改写成
A
→
δ
A
′
∣
γ
1
∣
γ
2
∣
.
.
.
∣
γ
m
{A \rightarrow \delta A' | \gamma_1 | \gamma_2| ... | \gamma_m}
A→δA′∣γ1∣γ2∣...∣γm
A
′
→
β
1
∣
β
2
∣
.
.
.
∣
β
n
{A' \rightarrow \beta_1 | \beta_2 | ... | \beta_n}
A′→β1∣β2∣...∣βn
经过上面反复提取左因子,我们一定可以将一个非终结符的所有候选式的FIRST集两两不相交
FOLLOW集
消除左递归后的文法
E
→
T
E
′
{E \rightarrow TE'}
E→TE′
E
′
→
+
T
E
′
∣
ϵ
{E' \rightarrow +TE'|\epsilon}
E′→+TE′∣ϵ
T
→
F
T
′
{T \rightarrow FT'}
T→FT′
T
′
→
∗
F
T
′
∣
ϵ
{T' \rightarrow * FT'|\epsilon}
T′→∗FT′∣ϵ
F
→
(
E
)
∣
i
{F \rightarrow (E)|i}
F→(E)∣i
我们对$ i + i $进行至上而下的语法分析
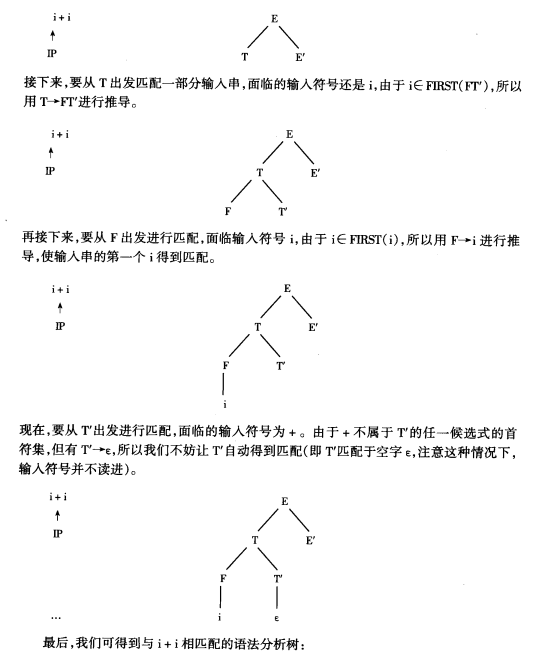
当我们进行到这个地方的时候我们发现
T
′
有两个候选式
T
′
→
∗
F
T
′
∣
ϵ
,但是
∗
不能和
+
匹配,另一个候选式是
ϵ
,
这时我们不能选择
∗
F
T
′
去扩展,只能选择
ϵ
T'有两个候选式{T' \rightarrow * FT'|\epsilon},但是 * 不能和 + 匹配,另一个候选式是{\epsilon} ,这时我们不能选择 * FT' 去扩展,只能选择 {\epsilon}
T′有两个候选式T′→∗FT′∣ϵ,但是∗不能和+匹配,另一个候选式是ϵ,这时我们不能选择∗FT′去扩展,只能选择ϵ
可以看到当候选式有
ϵ
{\epsilon}
ϵ时,会对我们的分析产生困难,如何消除这个困难呢?什么时候才能用
ϵ
{\epsilon}
ϵ去扩展呢?
这里我们就引入了
F
O
L
L
O
W
集
FOLLOW集
FOLLOW集

LL(1)的分析条件
LL(1)文法

- 文法不含左递归
- 对文法中每一个非终结符A的各个产生式的候选终结首符集两两不相交,
A → α 1 ∣ α 2 ∣ . . . ∣ α n A \rightarrow \alpha_1 | \alpha_2 | ... | \alpha_n A→α1∣α2∣...∣αn
则 F I R S T ( α i ) ∩ F I R S T ( α j ) = ∅ 则 FIRST( \alpha_i ) \cap FIRST( \alpha_j ) = \varnothing 则FIRST(αi)∩FIRST(αj)=∅ - 对文法中的每个非终结符A,若它存在某个候选首符集包含 $ { \epsilon }$
F I R S T ( A ) ∩ F O L L W O ( A ) { FIRST(A) \cap FOLLWO(A)} FIRST(A)∩FOLLWO(A)
对于一个LL(1)文法,我们可以对输入串进行有效的无回溯的至上而下分析,假设我们要用非终结符
A
做匹配,面临的输入符号为
α
,
A
A做匹配,面临的输入符号为 \alpha, A
A做匹配,面临的输入符号为α,A的所有产生式为:
A
→
α
1
∣
α
2
∣
.
.
.
∣
α
n
A \rightarrow \alpha_1 | \alpha_2 | ... | \alpha_n
A→α1∣α2∣...∣αn
-
若 a ∈ F I R S T ( α i ) 则指派 α i a \in FIRST(\alpha_i)则指派 \alpha_i a∈FIRST(αi)则指派αi匹配
-
若$ a $不属于任何一个候选首符集,则:
- 若 ϵ ∈ F I R S T ( α i ) 并且 a ∈ F O L L O W ( A ) 则让 A 与 ϵ 自动匹配 \epsilon \in FIRST(\alpha_i)并且a \in FOLLOW(A)则让A与 \epsilon自动匹配 ϵ∈FIRST(αi)并且a∈FOLLOW(A)则让A与ϵ自动匹配
- 否则a的出现是一种语法错误
构造FIRST和FOLLOW集合
构造每个文法符号的FIRST集合
对每一文法符号 $ X \in V_T \cup V_N构造FIRST(X) $
连续使用下面几条规则,直到每个FIRST集合不再增大为止
- 若 $ X \in V_T 则FIRST(X) = {X} $
- 若$ X \in V_N 且有产生式 X \rightarrow a …,则把a加入到FIRST(X)中;若 X \rightarrow \epsilon 也是一条产生式,则把\epsilon也加入FIRST(X) $
- 若 $ X \rightarrow Y 且Y \in V_N,则把FIRST(Y)中的所有非 \epsilon 元素加入到FIRST(X)中 $

构造FOLLOW集合
再回顾一遍FOLLOW集合的定义:
F
O
L
L
O
W
(
A
)
=
{
a
∣
S
⇒
.
.
.
A
a
.
.
.
,
a
∈
V
T
}
FOLLOW(A) = \{ a| S \Rightarrow ...Aa...,a \in V_T\}
FOLLOW(A)={a∣S⇒...Aa...,a∈VT}
对于文法G的每个非终结符A构造FOLLOW(A),连续使用下面的规则,直至每个FOLLOW不再增大为止
- 对于文法的开始符号 S , 置 # 于 F O L L O W ( S ) 中 S ,置 \# 于FOLLOW(S)中 S,置#于FOLLOW(S)中
- 若 A → α B β 是一个产生式,则把 F I R S T ( B ) { β } 加至 F O L L O W ( B ) 中 A \rightarrow \alpha B \beta 是一个产生式,则把FIRST(B)\ \{ \beta \}加至 FOLLOW(B)中 A→αBβ是一个产生式,则把FIRST(B) {β}加至FOLLOW(B)中
- 若 A → α B 是一个产生式,或 A → α B β 是一个产生式,但 β ⇒ ϵ A \rightarrow \alpha B 是一个产生式,或 A \rightarrow \alpha B \beta是一个产生式,但 \beta \Rightarrow \epsilon A→αB是一个产生式,或A→αBβ是一个产生式,但β⇒ϵ则把 F O L L O W ( A ) 加入到 F O L L O W ( B ) FOLLOW(A)加入到FOLLOW(B) FOLLOW(A)加入到FOLLOW(B)
递归下降分析程序
递归下降分析程序


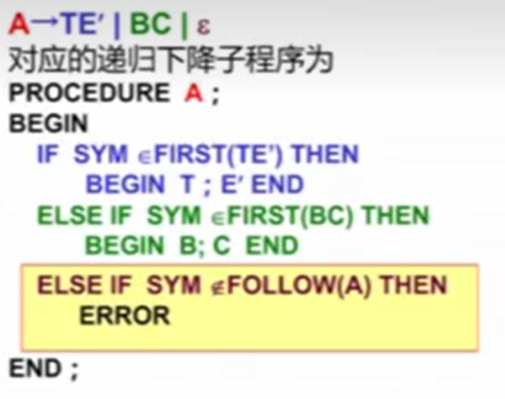
文法
G
(
E
)
:
文法G(E):
文法G(E):
E
→
T
E
′
{E \rightarrow TE'}
E→TE′
E
′
→
+
T
E
′
∣
ϵ
{E' \rightarrow +TE'|\epsilon}
E′→+TE′∣ϵ
T
→
F
T
′
{T \rightarrow FT'}
T→FT′
T
′
→
∗
F
T
′
∣
ϵ
{T' \rightarrow * FT'|\epsilon}
T′→∗FT′∣ϵ
F
→
(
E
)
∣
i
{F \rightarrow (E)|i}
F→(E)∣i


文法的另一种表示方法和转换图


文法
E
→
T
∣
E
+
T
E \rightarrow T | E + T
E→T∣E+T
T
→
F
∣
T
∗
F
T \rightarrow F | T * F
T→F∣T∗F
F
→
i
∣
(
E
)
F \rightarrow i | (E)
F→i∣(E)
用巴克斯范式可以表示为:
E
→
T
{
+
T
}
E \rightarrow T \{ +T \}
E→T{+T}
T
→
F
{
∗
F
}
T \rightarrow F \{ * F \}
T→F{∗F}
F
→
i
∣
(
E
)
F \rightarrow i | (E)
F→i∣(E)
我们还可以用语法图来表示,这种图的每一个子图是一个非终结符,子图和子图之间可以相互引用
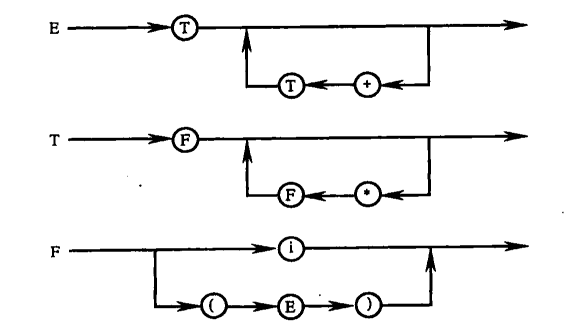
根据语法图和上面的巴克斯范式我们可以写出递归下降程序

预测分析程序
预测分析程序的工作过程
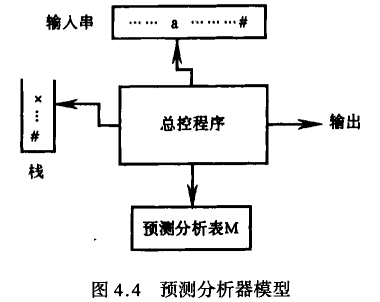

预测分析的总控程序:

预测分析表的构造