一.数据结构的分类
1.数据结构中分为四大类:线性表,哈希表,树,图。
2.线性表(line table):呈现线性结构的一种数据结构。具有顺序性,也就是所有数据都是有序的;
数组(array):连续的内存结构。大小固定,类型一致;数据查询数据的时间复杂度是O(1)
链表:是一种物理存储单元上非连续,非顺序的存储结构;链表由节点组成,而节点由存储结构的数据域和存储下一节点地址的引用指针域组成;
3.哈希表(hash table):无序表
4.树(tree table)
5.图
二.列表
1.list(列表):底层是一个双向链表的线性表;
创建或者定义列表:利用弱数据类型的特定,直接给[ ]定值,那么对应的变量就会自动变成列表类型;
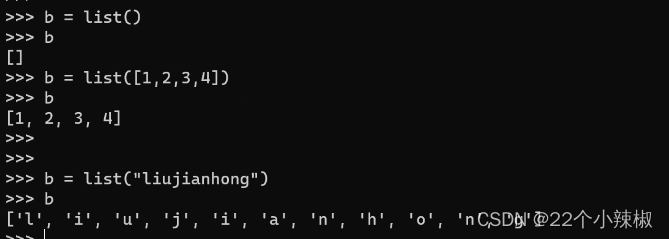
使用全局函数:b = list() 或 b = list([1,2,3,4])
(列表是存在堆里面的)
2.如何获取列表的长度:len()
3.如何获取每一个元素:
列表是有序的序列,它是线性表,线性表都是下角的角标
a[0] #获取第一个元素
a[len(a) - 1] #获取最后一个元素
4. 如何遍历列表:
A. while: 必须是线性表!
B.for循环遍历
5.如何新增元素?如何删除元素?(使用dir列表对象,就可以查看列表中的所有属性和方法)
append(新的元素) #在尾部添加新的元素
insert(index , value) #在index位置添加新的元素
extend(新的列表) #合并列表
remove(元素) #通过元素本身移除元素,如果元素不存在,则抛出异常
pop(默认是从index = -1开始) #默认移除最后一个元素,但是当传递了参数,表示移除对应下标的元素
clear() #清空列表
index(元素) #获取第一个元素所在的角标位置,如果元素不存在,则抛出异常
count(元素) #统计元素个数
copy() #拷贝列表,浅拷贝
reverse() #翻转列表顺序,注意和全局函数reversed的区别
sort() #排序,一定要保证类型一致
总结:结构为a.insert等等
三.set集合
1.底层使用的一个hash table实现的;特点:不能重复,无序。
2.python提供的set,就是有一个标准的哈希表,所以元素是不重复的,且无序的;
3.创建:
s = {1,2,3,4}
s = set{ }
4.访问元素:
set集合中的len跟列表中的一样,len获取元素个数;
只能使用for循环 迭代元素
5.常见方法:
clear #清空集合
copy #拷贝集合,浅集合
add(元素) #插入元素
pop(元素) #随机移除元素
remove(元素) #通过元素本身移除元素,如果元素不存在,则抛出异常
discard(元素) #通过元素本身移除元素,若元素不存在,也不会抛出异常 intersection #交集
union #并集
difference #差集
总结:在集合中,相加运算也有去重的效果;
四.元组
1.定义:元组指的就是一组不变的数据类型,如:性别、四季、方向等等固定的值;
2.注意:元组是一个不可变的数据类型!!!
3.基本数据类型都是不可变的数据!
4. index(元素) #获取一个元素所在的角标位置,如果元素不存在,则抛出异常;
count(元素) #统计元素数量;
5.注意:t = (1) 和 t = (1,)的区别;
t = (1)是指一个整形,t = (1,)是一个元组;在元组中,逗号(,)是有特殊意义的。
五.字典
1.字典:字典类型和集合一样,底层还是使用hash table实现的,只是字典对哈希表进行了封装,得到了k-v键值对的格式;
注意:所有的键只能由字符串和数字充当;
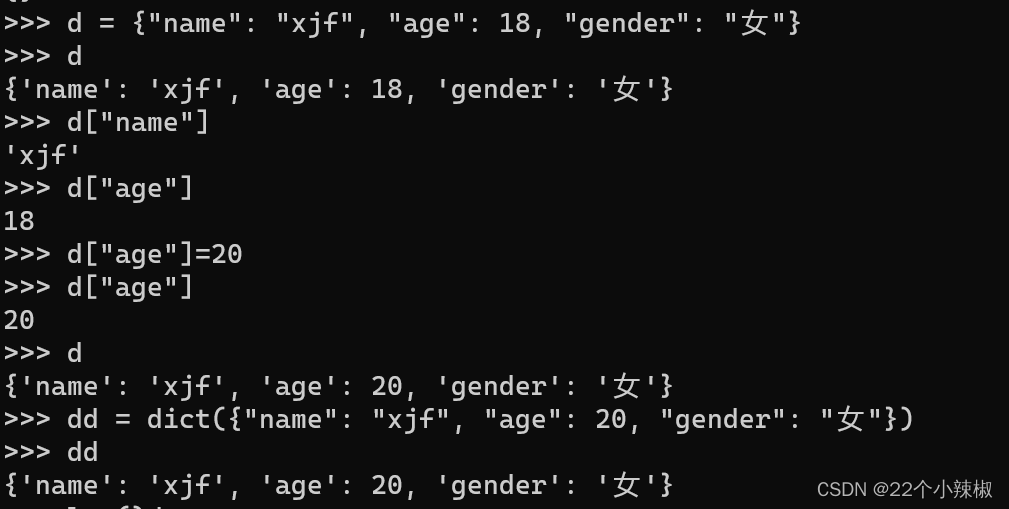
2.创建或者定义字典类型
3.获取或者访问字典的值
字典对象[key] #获取key对应的值
字典对象[key] = 值 #修改key的值,或者常见一个键值对;
4.获取有多少个键值对
len(d)
5.常见方法:
clear #删除字典中的所有元素
copy #复制
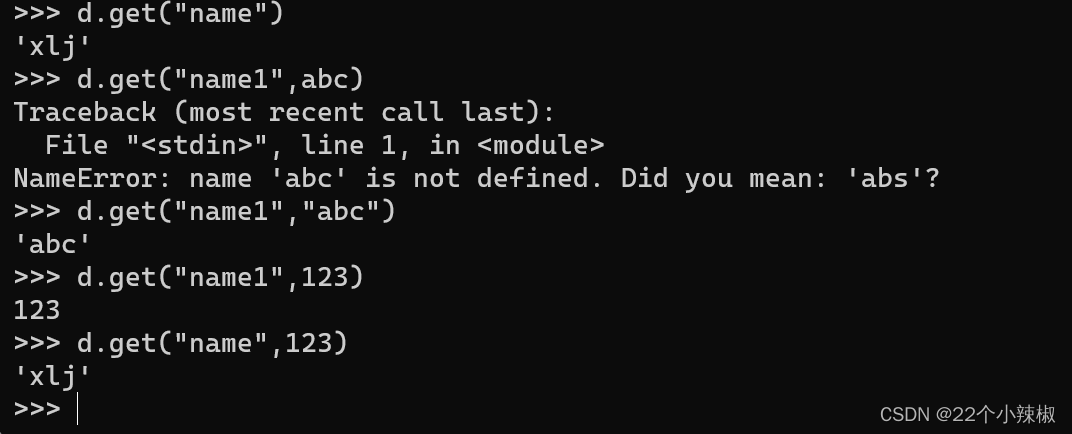
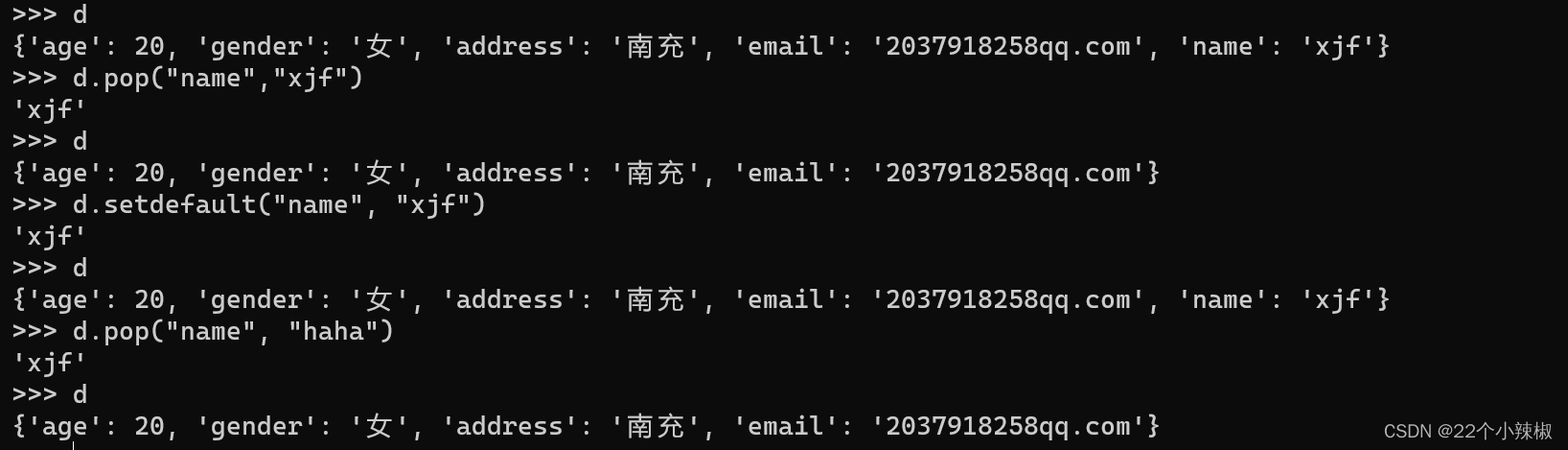
get(key,[默认值]) #通过key获取值
注意:假设aa在字典中不存在;d.get("aa")不会报错,会返回null;但是d["aa"]会报错,这是两者的区别!
另外:如果想给不存在的aa的返回值设置一个新的值,则用d.get("aa",默认值),只有该返回值不存在,才会返回我们设置的默认值;
items(后续用于遍历,很好使用) #返回键值对
keys() #获取键值对个数
update() #合并字典,注意:当key重复了,则会更新这个值;
del #是可以删除任何东西;
del 变量 #删除变量
del 字典对象 #删除字典对象
del 字典对象 key #删除有一个对应的键值对

values()
setdefault(key,[None]) #设置键值对
如果setdefault没有给值的话,就默认返回None;
fromkeys() #当所有键对应同一个值时,使用fromkeys()方法创建
fromkeys #静态方法,可以通过dict.fromkeys(iterable)
pop(key) #LIFO删除键值对
注意:只要key写对了,就可以删除;如果key对应的值写错了,也是可以正确删除的;
popitem() #LIFO(先进后删)随机删除并返回一个键值对
items() #返回键值对
update() #合并字典;
注意:如果key重复了,则会更新这个值;





六.函数
1.什么是函数?
函数是具有名称的功能代码的集合,函数就是封装了代码,本质就是为了实现代码的高度复用;
函数跟其他代码之间要空两行!这是规范!
2.函数是具有名称的功能代码的集合!
3.函数的分类:
a.根据有无参数
b.根据有无返回值
c.定义者:
--- 系统函数
--- 自定义函数
--- 第三方函数
4.函数部分:
局部变量和全局变量
函数调用的内存分析
值传递和引用传递问题
5.局部变量和全局变量:形参是局部变量;
打印结果:10 100
20 200
6.注意:在python中,全局变量不允许被函数内部修改!!!是基于安全和可靠性!!!
7. 在python中,全局变量在函数中,如果需要修改它的值,则必须声明!!!
8.函数调用的内存分析:
通过分析函数在内存中存储和调用过程,来看看函数的本质
9.在python中,函数也是对象,函数也不能存储在栈中,它是存储在堆空间中;当我们调用函数时,函数就会进入执行栈,进行代码运行;(push ,推栈)等函数执行完成后,立刻释放执行栈的内存;(pop,弹栈)
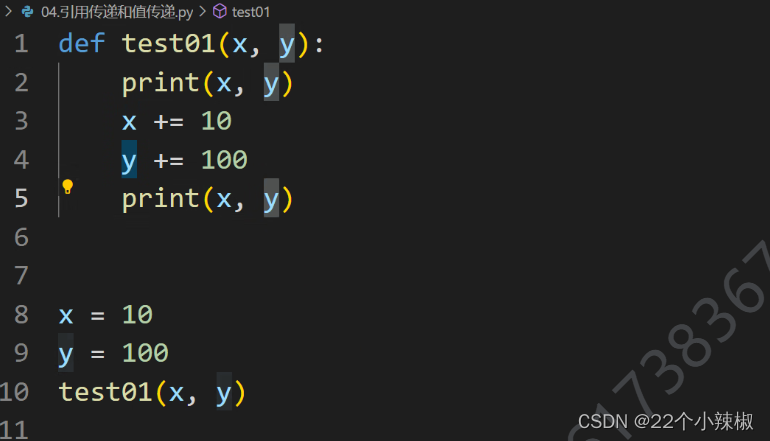
10.值传递跟引用传递问题:
值传递:函数的参数类型是数值类型,调用时,传递的仅仅是全局变量的值;因此在函数内部,修改传递后的值,不会影响全局变量;
引用传递:函数的参数类型是对象,(引用|指针|地址),所以传递后,形参函数指向全局变量地址对应的内存区域,因此形参修改,全局变量也会随之修改;
11.默认值参数 ----- set 、end函数:对于函数中一些参数,如果调用时,参数大多数情况下是一个固定值的时候,我们可以设置这个固定值,便于调用;
注意:函数中,普通参数(位置参数),一定要在默认值参数之前!
12. *+变量名 -------------- 可变参数:表示一批参数,简化多个参数的传递;
函数会自动将这些参数包装为一个元组对象;
代码要扩展的时候,可以加上:
13. 关键字参数:【命名参数】
将参数以键值对的形式传递过来,会被函数自动包装称字典对象;
注意:如果函数将来有可能需要扩展功能,建议添加可变参数关键字参数;
14. python在3.8版本后,提供过了类型声明功能,可以不使用,但是一定要认识,建议使用!
15. 在python中,只要是对象,就可以作为函数的参数;
16. 有括号是传的返回值,无括号传回的是函数本身!
17. 匿名函数: 没有名称的函数;
18. lambda表达式:本来就是简化函数的一种写法,在python中,如果函数较少,我们完成使用一行代码定义这个函数;
格式:lambda [参数] :函数
18.
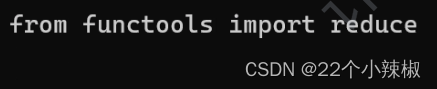
reduce可以转换!
19.偏函数:python中存在一种函数得特殊使用,称为偏函数;
如果函数在调用某个函数时,恰好某一个,某一些函数都是一个固定值(正好不是默认值),为了方便调用,我们可以通过特殊手段修改默认值;
格式 新的函数 = partial(原函数名称,参数 = 新的值)
20.递归(recursion):虽然有些问题使用这个很方便,但是很占内存!