更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
【导读】本文旨在探讨火山引擎 DataLeap 在处理计算治理过程中所面临的问题及其解决方案,并展示这些解决方案带来的实际收益。主要内容包括:
-
探讨面临的痛点和挑战
-
提供自动化的解决方案
-
分析实践效果和收益
-
提出结论和未来展望
▌痛点 & 挑战
在分析业务痛点和挑战之前,先要清楚业务现状。
-
现状概览
字节跳动数据平台目前使用了 1 万多个任务执行队列,支持 DTS、HSQL、Spark、Python、Flink、Shell 等 50 多种类型的任务。
自动计算治理框架目前已经完成了离线任务的接入,包括 HSQL、Hive to X 的 DTS 任务、AB test 和底层通过 Spark 引擎执行的任务,涉及到上千个队列,国内 可优化任务 170 万+ 的任务优化覆盖率达到 60%+。另外实时任务的优化也在同步推进。
-
痛点:手动调参常⻅问题

在手动调参的过程中,我们常常面临以下困境:
-
系统复杂度:
大数据计算系统与数据处理架构涵盖多种技术和组件,对其参数的调整需深刻理解各组件的运作机制及其相互依赖。以 Spark 为例,其拥有上百个适用于不同场景的参数,而这些参数可能互相影响,增加了调优的难度。过去,我们通常依赖单一任务模板进行少量参数调整,虽然此法能让单项任务抢占资源,却难以保证整体业务的及时性和稳定性。
-
动态变化:
计算环境、数据量和业务需求可能随时变动,这要求调优工作需具备高度的灵活性和适应性,以迅速应对各种变化。
-
专业知识缺乏:
通常由数据分析师来执行优化任务,但他们更侧重于业务场景而非底层逻辑。因此,我们希望通过自动化方案沉淀专业知识,提供一站式解决方案。
-
一致性与可重复性缺失:
不同人员操作可能导致不一致的结果,手动调优往往难以复现。例如,昨天的分区调优效果良好,但明天可能因数据量增加而导致内存溢出(OOM),后续运维包括复盘将需要投入大量时间成本。
-
挑战:复杂的优化场景和目标

针对业务方的优化需求,通常包括提高系统稳定性、降低运营成本、解决任务阻塞及提升系统健康度等多个方面。为选择最适合的优化策略,需深入理解以下几个常见场景:
-
稳定性与健康度:提高稳定性通常意味着需要牺牲一些资源利用率以保障运行效率;而提升健康度则旨在追求较高的资源利用率,尽管可能会对运行效率产生一些影响。
-
成本优化:主要包括回收无效成本和最大化资源利用率两个方向。由于业务方常存在大量未被充分利用的资源,我们需要协助他们提升任务的运行效率和缩短产出时间。
-
解决阻塞:通过调整算力和内存等参数来缓解阻塞。若参数调优无法完全解决阻塞问题,就需要与用户协作,优化任务的调度时间。
-
业务优化场景需求分析

针对之前提及的优化场景,以下是一些具体的解决策略:
-
稳定性优化:
推荐资源配额应基于任务的实际使用量,同时为保障稳定性,将近 7 天的波动和失败指标纳入权重计算,确保推荐参数能适应业务的波动和增长。
-
队列阻塞解决:
在 CPU 阻塞而内存正常时,维持总算力不变,减少物理核、增加虚拟核,并相应调整内存配额。
在 CPU 正常而内存阻塞时,降低总算力,从而降低任务申请的物理内存总量。
当 CPU 和内存同时阻塞时,适度降低算力或减少虚拟核,以保任务运行性能在预期范围内。
注意:如参数调优未能解决阻塞问题,需与调度系统协同,将任务调度至合适时段,以彻底解决阻塞问题。
-
计算健康分提升:
CPU 利用率:对于小任务,可减少物理核、增加虚拟核。对普通和大任务,需评估是否调整算力,进而确定调优方向。
内存利用率:通常不宜将内存利用率设置过高以避免 OOM,首先按需分配资源,然后根据内存利用率调整虚拟核。例如,当利用率低于 50%时,提升虚拟核。后期将支持 1/1000 核的微调以逼近理想的内存利用率阈值。内存调优涵盖多个阶段如 map、shuffle 和 reduce 等,每阶段的处理性能和参数配置有所差异。遇到内存调优瓶颈时,可考虑进行 shuffle 优化。
-
成本优化:
Quota 回收型:实际使用量应低于申请量,如需回收 20%,则需确保空闲量超过 30%的时间占比维持在 95%以上,同时保有 10%的可用余量。
Quota 充分利用型:
CPU 型优化:可增加虚拟核或物理核,但由于增加虚拟核可能导致超发,为保障队列稳定性,建议增加物理核。
内存型优化:增加算力、减少物理核、增加虚拟核,以释放更多内存资源,确保内存得到充分利用。
▌自动化解决方案
接下来讲解针对上述场景的自动化解决方案。
-
解决方案:实时规则引擎

首先,我们介绍实时规则引擎及其功能:
-
参数实时推荐与应用:该引擎能够实时收集 Yarn container、Spark event 和 Dtop status 等数据,通过基于 app ID 的聚合,统计所有核心与观测指标,并将数据记录至历史数据库中。在连续的 3-7 天观测期内,引擎会根据收集到的数据进一步优化参数推荐,最终将推荐参数推送到 Spark 等执行引擎,并实时监控任务的执行情况。
-
启发式规则的应用:利用基于规则树的启发式规则,针对不同的场景,我们可以设定不同的优化目标和阈值,为优化过程提供指导。
-
资源使用评估:通过分析最近 3-7 天的资源使用累积指标,实时规则引擎可以评估整体的资源波动情况,为进一步的优化提供数据支持。
-
稳定性与健康分策略:
普通策略:旨在保障系统的稳定性,通过分析实际的资源使用量来提供参数推荐。
激进策略:着眼于提高资源利用率,不断探索任务的性能边界,同时能自适应地应对 OOM 风险,保障系统的运行效率。
为确保系统的稳定运行,一旦任务实例失败,实时规则引擎会自动将参数回滚至上一个稳定版本。若连续失败多次,则暂停该任务的优化过程,直至任务恢复稳定运行。我们每周会对失败案例进行复盘分析,以持续优化和改进实时规则引擎的性能和准确性。
-
解决方案:实时监控 & 自适应调整

我们还实施了一系列实时监控和自适应调整方案,以增强 Spark 等底层引擎的性能和稳定性:
-
OOM 自适应处理:针对易发生 OOM 的任务,我们将其调度至独立的 executor,让其独享 container 资源,从而在不增加总资源的前提下,减缓 OOM 的发生,保障任务的稳定运行。
-
Shuffle 溢写分裂管理:我们设定了每个容器的 Shuffle 磁盘写入量阈值。一旦写入量超过阈值,系统会自动分裂出新的容器,避免单个容器的溢写,同时减轻 ESS 的压力。
-
Shuffle 分级限流机制:根据任务的优先级,分配不同的查询处理速率(QPS)。高优先级任务将获得更多的 QPS,而低优先级任务的 QPS 会相应限制,以防止 ESS 服务过载,确保高优先级任务的顺利执行。
-
节点黑名单优化:为了降低任务失败率,我们实现了节点黑名单机制。当节点因特定失败原因被标记时,任务会尽量避免在该节点上执行。我们还提供了设置黑名单节点数量上限的功能,防止过多节点被拉黑,影响整个集群的可用性。
-
失败回滚与参数管理:当任务实例失败时,系统会自动将参数回滚至上一个稳定版本。若连续失败两次,系统会自动抹除推荐参数并暂停优化,以避免对任务造成进一步的干扰。这种机制有助于降低业务波动对执行的风险,同时减少人工干预的成本。
-
Dataleap 一站式的治理解决方案
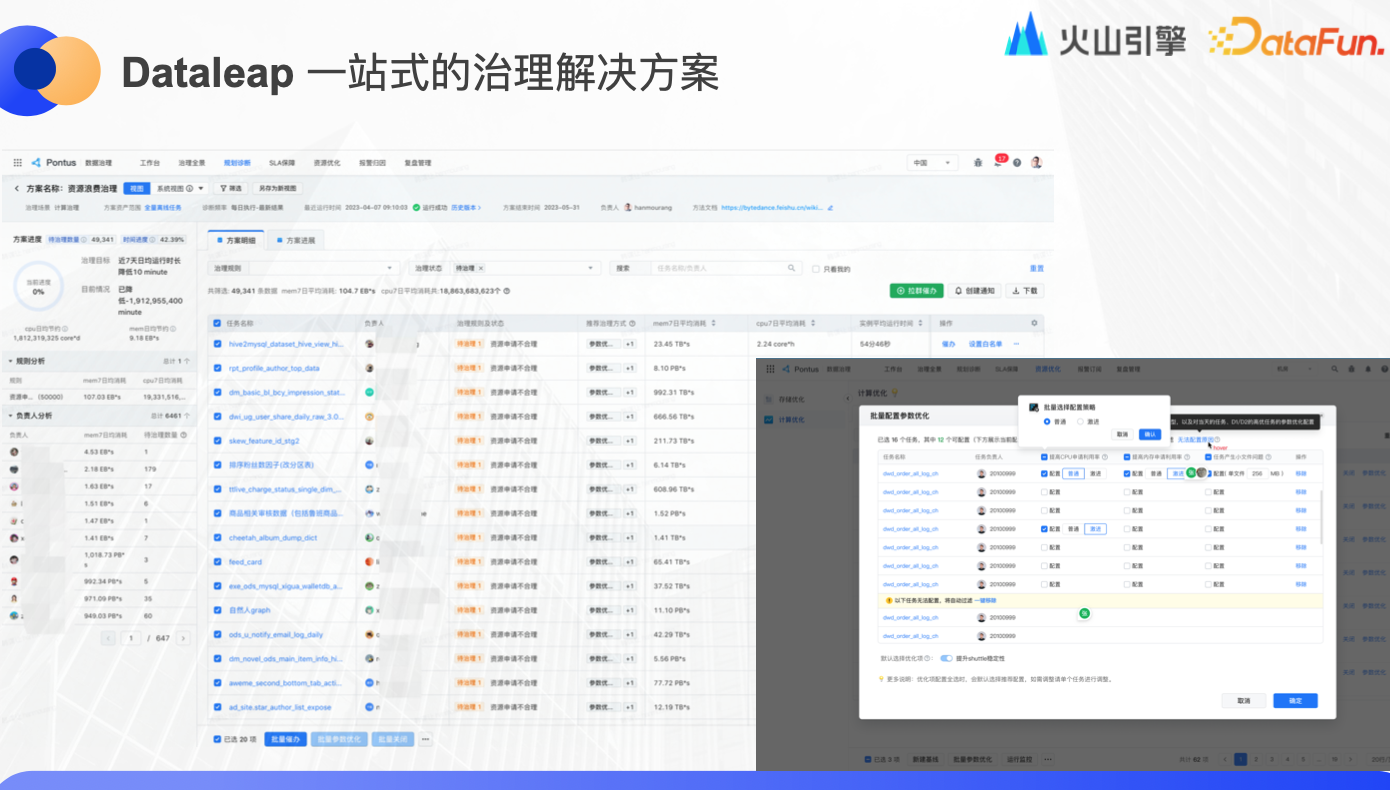
最后还有产品侧的一站式解决方案,用户可以快速发起治理。系统界面可以看到每个用户当前可治理的资源量等信息,可以批量或者单个开启优化,可以选择激进或普通策略,支持小文件优化,系统会根据业务场景自动适配。在做优化方案的同时,系统就会预估出成本和收益。
▌实践 & 收益
接下来复盘一个具体的优化案例。
-
优化实践:队列优化前后效果
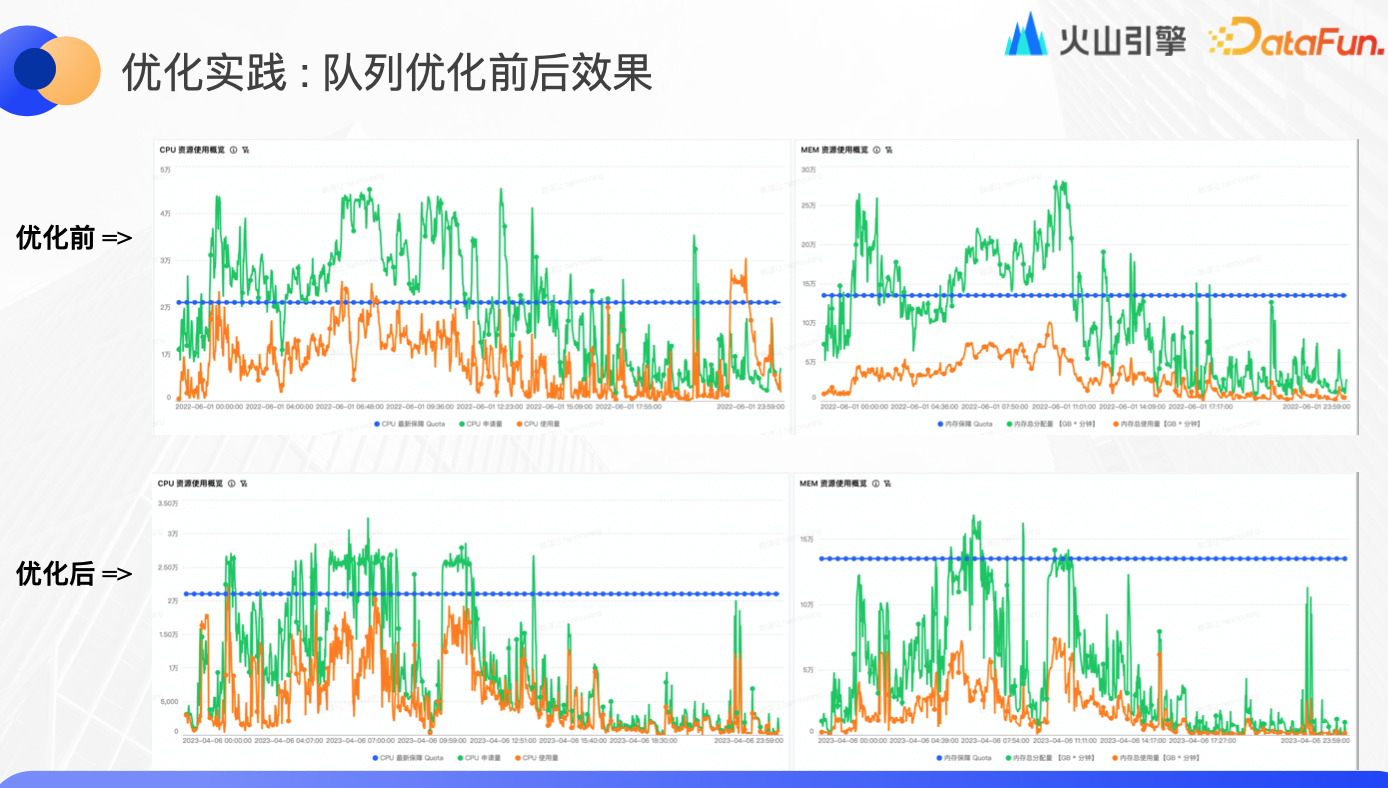
本例的队列在优化前的每天 10 点前都处于超发状态,导致任务阻塞非常严重,很多任务长期处于等待状态。优化后的资源申请量明显降低,申请量和使用量之间的 gap 趋向理想范围,由于减轻了内存超发,使 OOM 问题得到改善,让平台使用更少的成本和资源做了更多的事情。
-
收益分析:队列优化收益指标
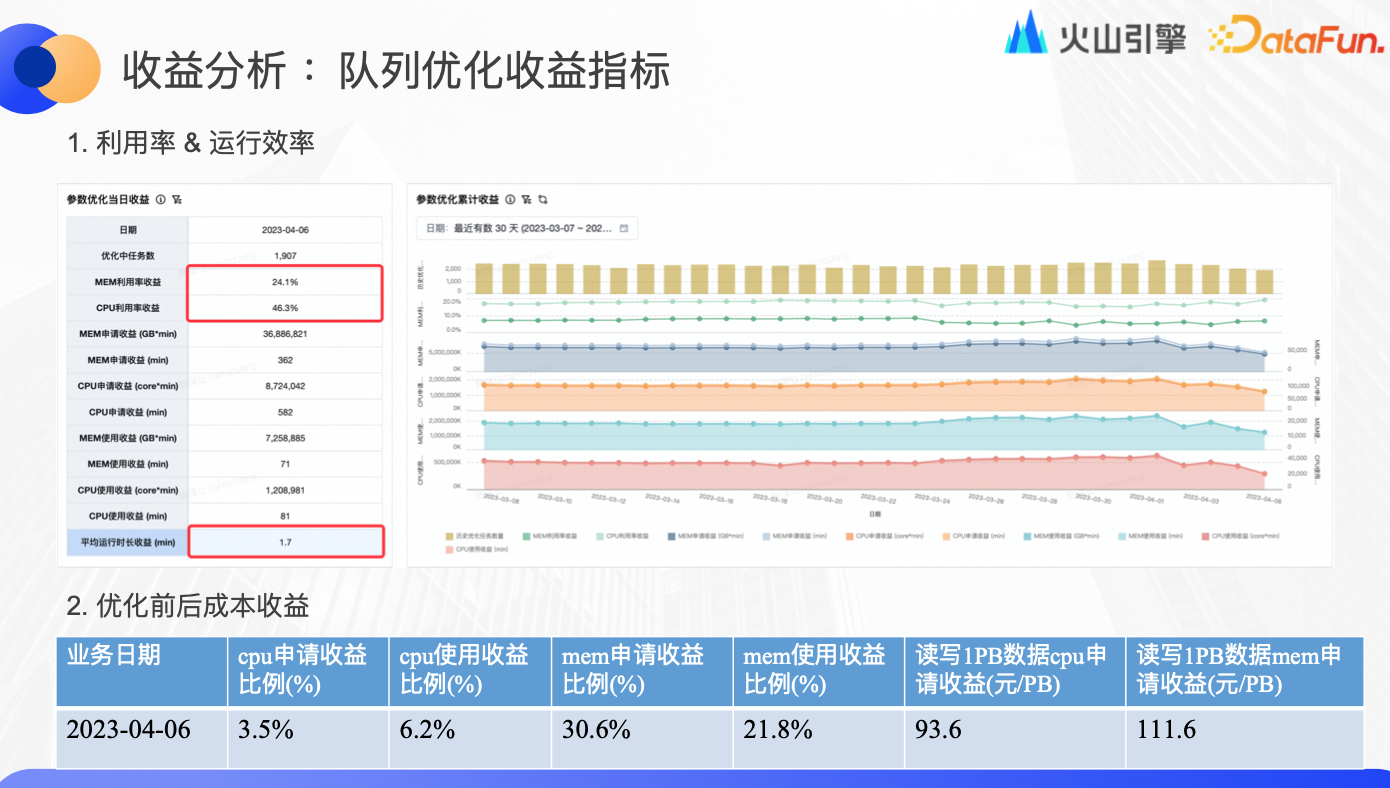
由于每个用户对于底层的理解程度不同,如果按单个任务、单个用户去优化,很难保障人力成本和时间成本。而通过平台的自动化解决方案,就可以保证所有业务、队列都可以达到一个非常好的预期效果。
如上图所示,该队列一共有 1900 多个任务,优化完成后,CPU 申请量减少 3.5%、使用量减少 6.2%、利用率提升 46.3%,内存申请量减少 30.6%、使用量减少 21.8%、利率提升 24%,所有任务的平均运行时长减少了 1.7 分钟,每 PB 数据 CPU 节约近百元、内存节约百元以上。
-
收益概览:业务队列普通策略优化效果

稳定策略对于内存使用率的目标是 75%-80%,已完成优化的 TOP20 队列普遍提升了 20%,CPU 使用率普遍达到了 70%-80%,整体运行时长也有提升。
另外还有一些激进策略、深度优化和成本优化策略,可以帮助大部分业务在资源利用率和运行效率之间寻求平衡。
-
收益概览:增量小文件合并

增量小文件合并是在 reduce 阶段,会把产出不合理的文件进一步合并,这个操作导致线上 2000 多个任务的平均运行时间增加了 18%,对当前任务来说是负向收益。但是合并完成后下游任务读取数据性能比之前提高很多,对整个队列、集群来说是长期正向收益。后续我们会争取把小文件合并的性能损耗从 18%降到 10%以内。
▌结论 & 展望
-
自动化方案优势 & 局限性

自动化方案的优势包括:
-
效率提升:通过运用先进的算法和实时监控机制,自动化方案能够迅速锁定最优参数组合,从而提升调优效率。
-
准确性增强:能够妥善处理参数间复杂的相互影响,为复杂系统呈现更为精准的调优结果,进一步提高调优的准确性。
-
人力成本节省:自动化方案减少了人力的投入,有助于降低企业及组织的运营成本。
-
实时监控与自适应调整:实时监控系统的状态和性能,根据数据的变化自动做出调整,确保系统始终运行在最佳状态。
然而,自动化方案也存在一些局限性:
-
算法依赖:方案的效果高度依赖于所选用的算法,选取合适的算法和优化策略成为关键。
-
可解释性与可控性的局限:自动化方案可能会在可解释性和可控性方面显示出一些限制,增加了在特定情况下对系统理解和调整的难度。
-
特定场景的应对困难:在某些特定的场景下,自动化方案无法完全取代人工调优,仍需专业人员的参与和经验。
-
未来发展与挑战

最后来看一下未来的发展规划和可能面对的挑战。
发展重点:
-
元数据闭环多产品化:
分级保障:实现 Pontus 和 Dorado 之间的元数据通信,针对服务等级协议(SLA)和核心链路节点,确保高优先级的稳定性和及时性。
队列管理:明确在 Megatron 侧为各业务配置的资源使用规则:
回溯管理:设定指定时段内回溯任务所能使用的资源上限。
用户资源管理:通过设定单个用户可使用的资源比例上限,以控制该用户名下任务的可用计算力。
Ad-hoc 资源控制:在系统高负载时段,自动调整 adhoc 查询的资源使用管控。
-
用户干预参数推荐:
提供固定值、最大/最小阈值、参数屏蔽等选项,允许用户根据实际需求调整参数。
-
结合规则引擎与算法优化:
通过集成规则引擎和算法优化,实现更为高效且准确的参数调优。
预见挑战:
-
适应变化的数据环境:
面对大数据领域的快速进展,持续优化自动化解决方案以适应不断变化的数据环境。
-
提升算法性能:
为实现更高效的自动化解决方案,持续研究和提升算法性能。
-
保障系统的可解释性和可控性:
在推进自动化的过程中,确保系统的可解释性和可控性,以便用户能够理解并进行调整。
点击跳转DataLeap了解更多