目录
1--self attention原理
2--C++代码
3--拓展
3-1--mask self attention
3-2--cross attention
1--self attention原理
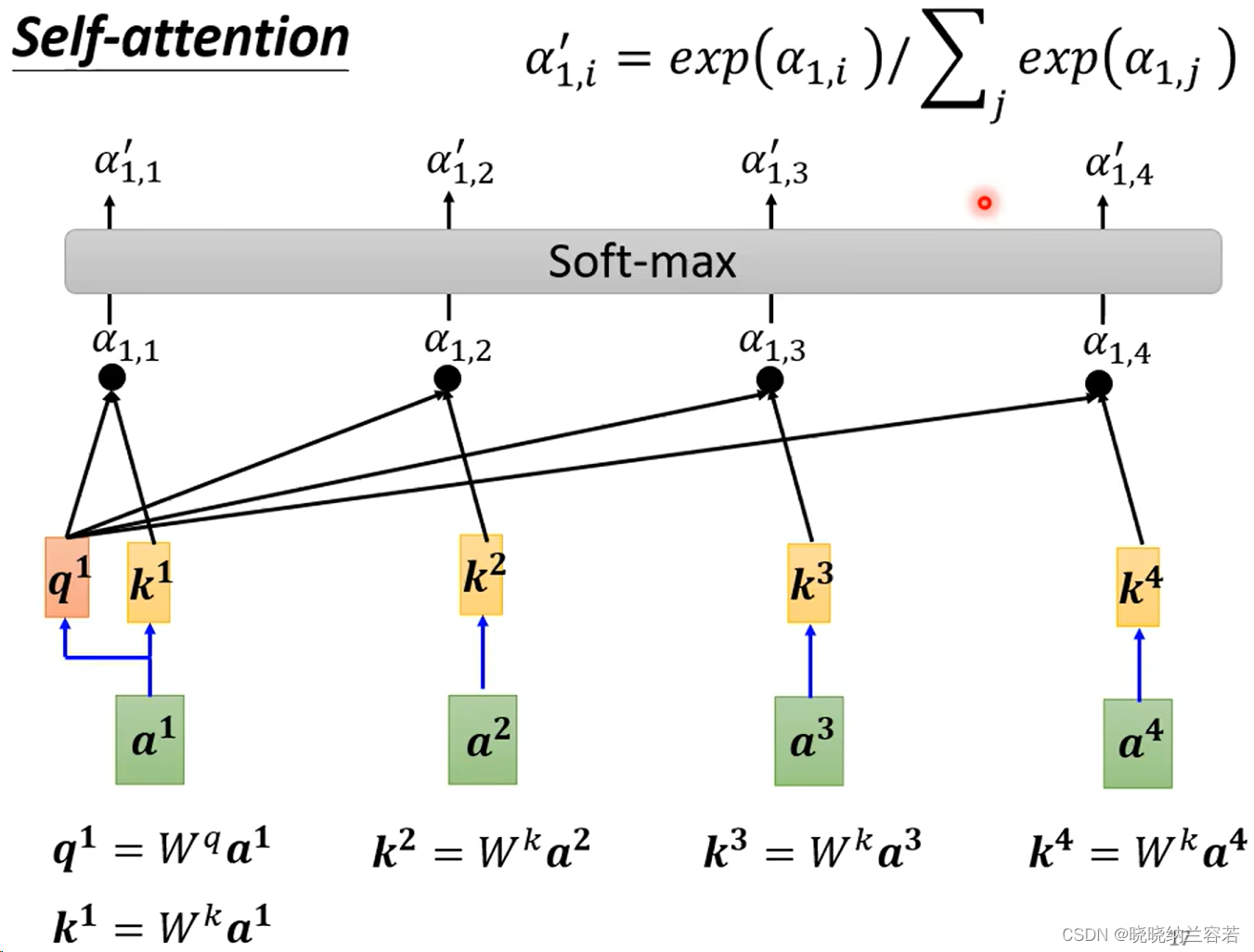
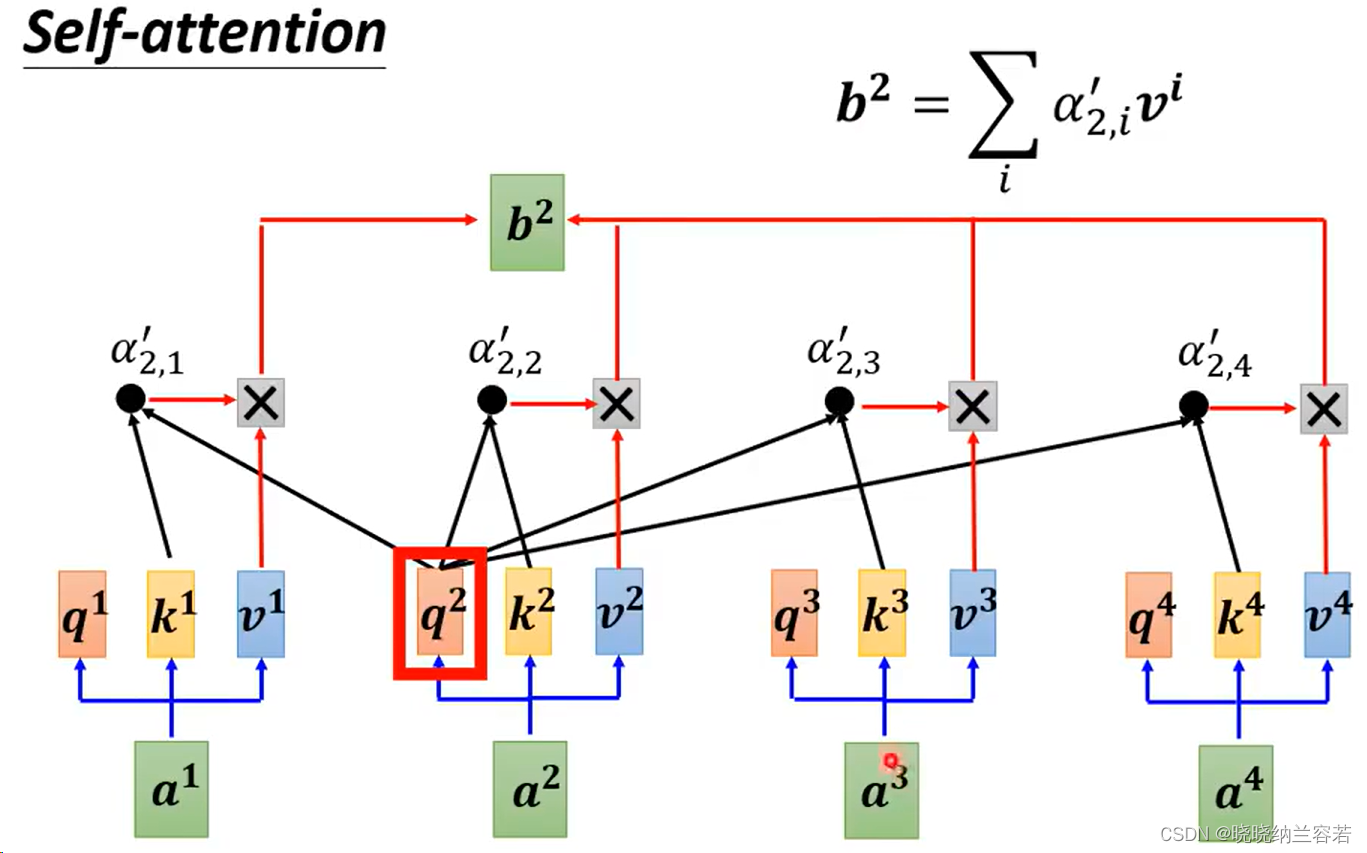
直观来讲,就是每个 token 的 Query 去和其它 token(包括自身)的 Key 进行 dot product(点积)来计算权重 weight,weight 一般需要进行 softmax 归一化操作,然后将 weight 与每个 token 的 Value 进行加权。每个 token 通过这种方式来获取和学习其它 token 的特征,并作为下一层的输入。
2--C++代码
基于 egien 库实现:
#include <iostream>
#include <Eigen/Dense>
// 定义 Self-Attention 函数
Eigen::MatrixXd selfAttention(const Eigen::MatrixXd& input) {
int seq_length = input.rows();
int hidden_size = input.cols();
// 初始化权重矩阵 WQ, WK, WV
Eigen::MatrixXd WQ = Eigen::MatrixXd::Random(hidden_size, hidden_size);
Eigen::MatrixXd WK = Eigen::MatrixXd::Random(hidden_size, hidden_size);
Eigen::MatrixXd WV = Eigen::MatrixXd::Random(hidden_size, hidden_size);
// 计算 Q, K, V 矩阵
Eigen::MatrixXd Q = input * WQ;
Eigen::MatrixXd K = input * WK;
Eigen::MatrixXd V = input * WV;
// 计算注意力分数
Eigen::MatrixXd scores = (Q * K.transpose()).eval();
// 缩放注意力分数
scores /= sqrt(hidden_size);
// 计算注意力权重(替代softmax)
Eigen::MatrixXd attention_weights = scores.unaryExpr([](double x) { return exp(x); });
Eigen::MatrixXd weights_sum = attention_weights.rowwise().sum(); // 按行求和
for(int i = 0; i < attention_weights.rows(); i++){ // 归一化
attention_weights.row(i) /= weights_sum(i);
}
// 计算输出
Eigen::MatrixXd output = attention_weights * V;
return output;
}
int main(){
int seq_length = 5;
int hidden_size = 4;
Eigen::MatrixXd input = Eigen::MatrixXd::Random(seq_length, hidden_size); // 随机初始化输入矩阵
Eigen::MatrixXd output = selfAttention(input); // 计算 Self-Attention 输出
// 打印输入输出
std::cout << "Input:\n" << input << "\n";
std::cout << "Output:\n" << output << "\n";
return 0;
}
3--拓展
拓展记录一下 transformer 中的 mask self attention 和 cross attention 机制。
3-1--mask self attention
mask self attention 与 self attention 最大的区别在于:self attention 中每一个 token 可以看到和获取所有 token 的特征,而 mask self attention 的 token 只能看到其前面(左边)的 token 特征,并不能聚合其后面的 token。
self attention:(全局视野)

mask self attention:
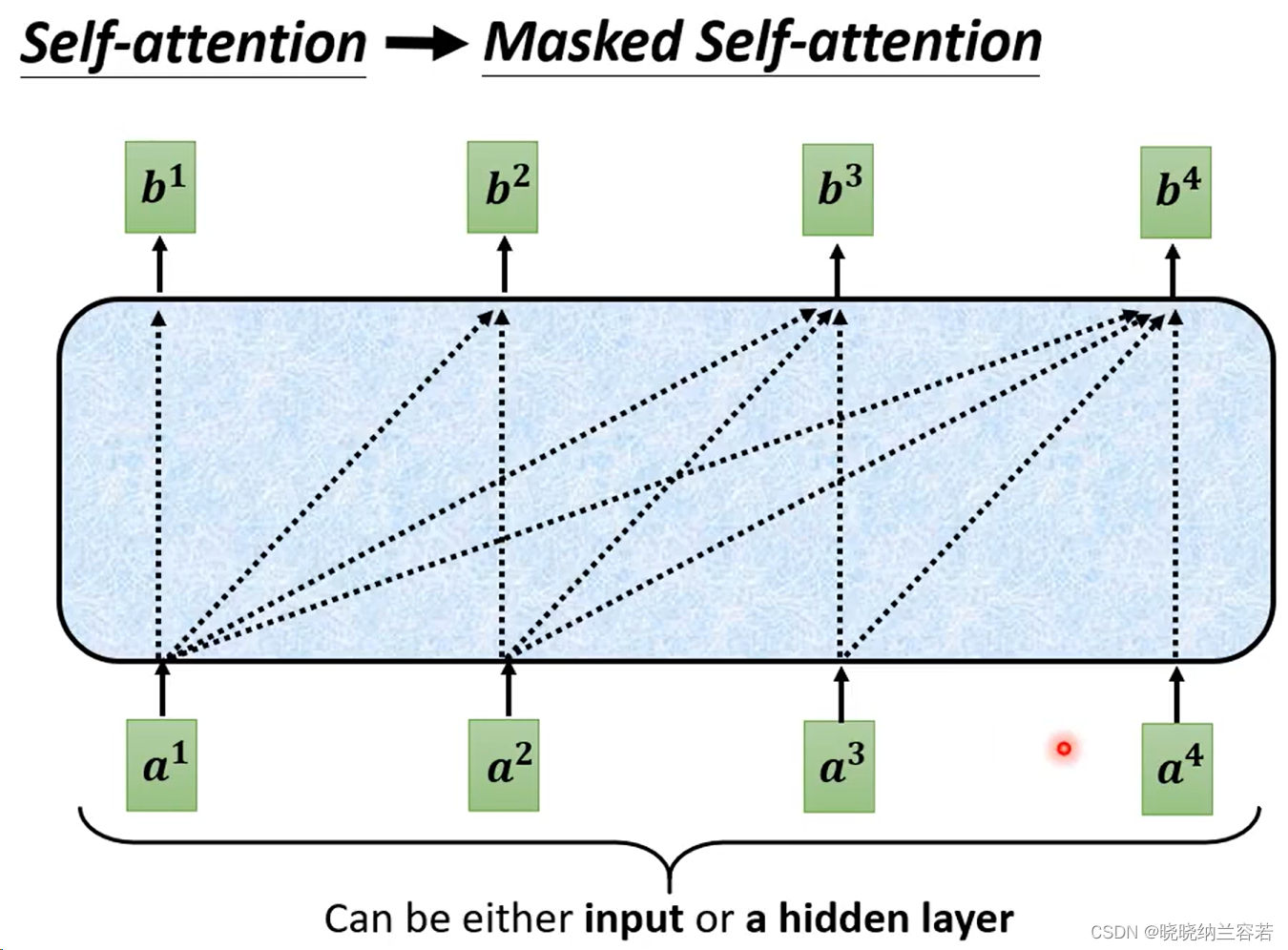
对于上图的 mask self attention,a1 只能聚合本身的特征,a2 可以聚合 a1 和本身的特征,a4 则可以聚合前面全部 token 的特征;
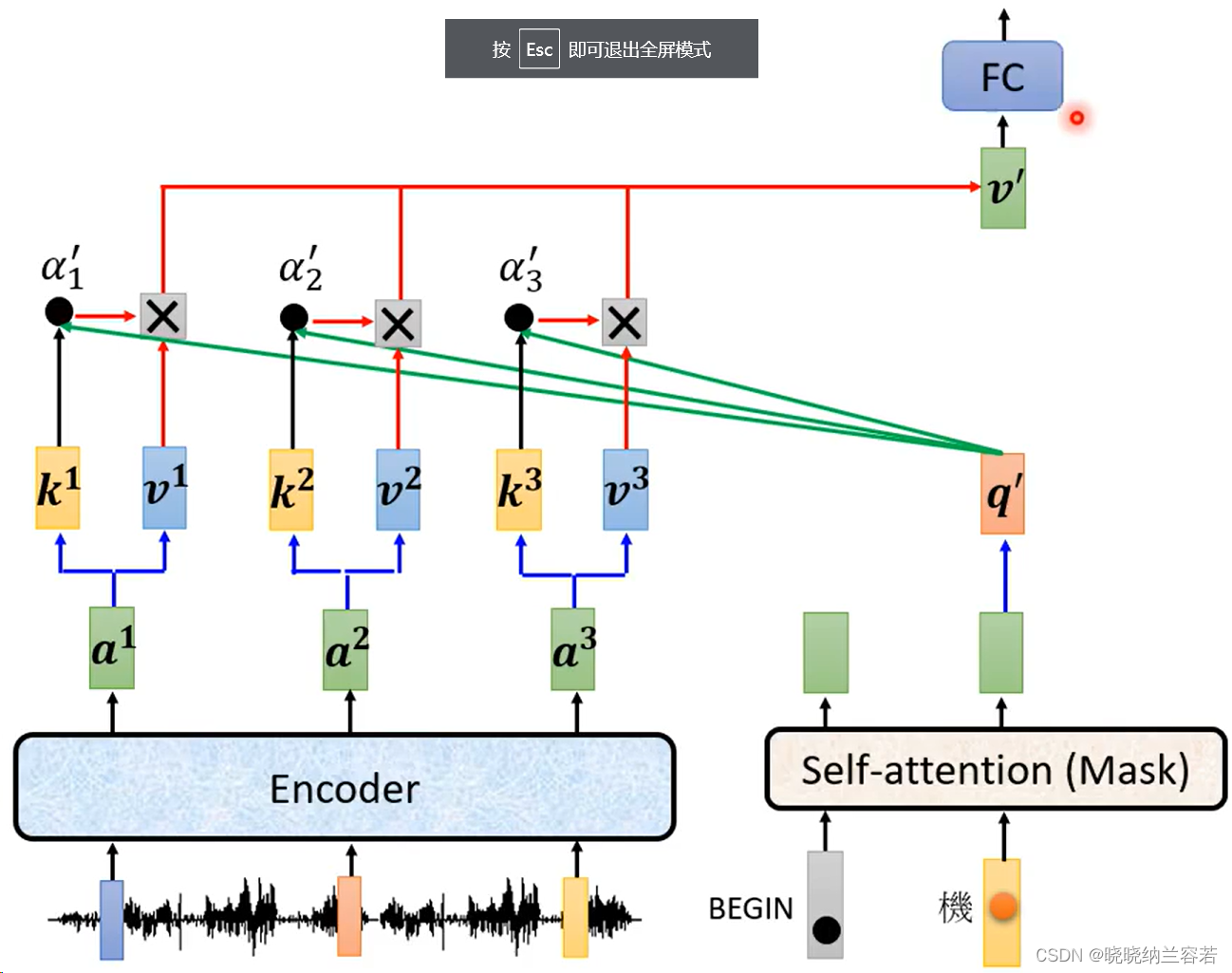
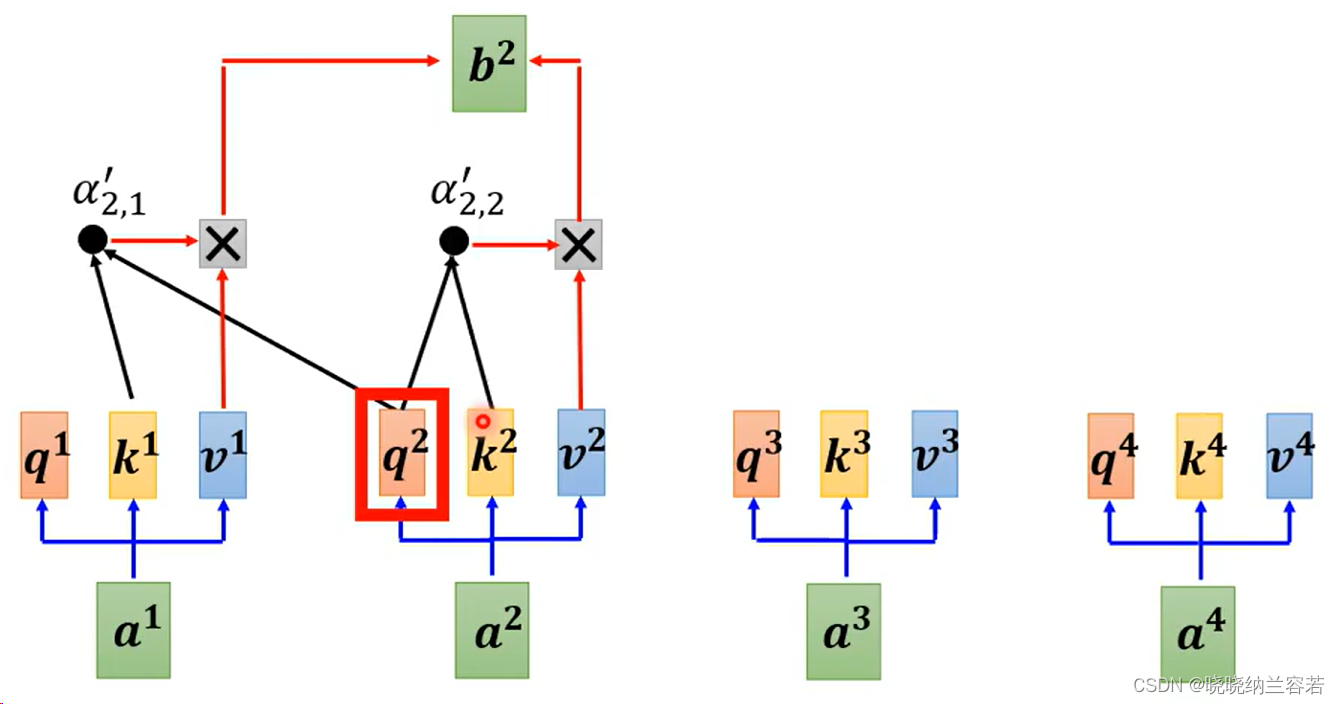
具体实现,就是下图中的 a2 的 Query 只去和 a1 和本身的 Key 来计算权重 weight,并且 weight 也只和 a1 和 a2 的 Value 进行加权;
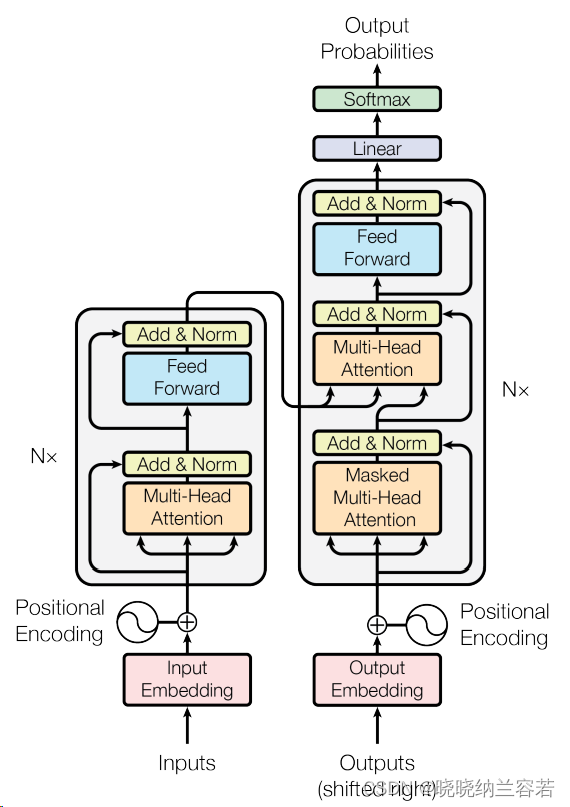
3-2--cross attention

上图中,transformer的 decoder 部分引入了 cross attention,其输入包括三部分,其中两部分来自于 encoder,即 Key 和 Value;第三部分来自于 decoder,即 Query;Query 通过查询来聚合来自 encoder 的特征;