目录
matlab代码kmeans
matlab代码kmeans++
MNIST DATABASE下载网址: http://yann.lecun.com/exdb/mnist/
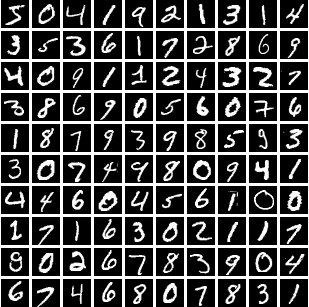
聚类
将物理或抽象对象的集合分成由类似特征组成的多个类的过程称为聚类(clustering)。
对于给定N个n维向量x1,…,xN∈Rn,聚类的目标就是将这N个n维向量分成k个集合,尽量使得同一个集合中的向量彼此接近,如图2所示。
图2 聚类示意效果图
K-means聚类算法迭代过程
首先初始化聚类中心,如图3所示。
图3 k-means初始聚类中心
然后计算每个点到k个聚类中心的聚类,并将其分配到最近的聚类中心所在的聚类中,重新计算每个聚类现在的质心,并以其作为新的聚类中心,如图4所示。
图4 k-means迭代1次
重复迭代,直到达到给定的迭代次数或k个聚类中心的变化值小于某个阈值,形成最终的聚类结果,如图5所示。
图5 k-means最终聚类效果
K均值聚类算法的复杂度分析
初始化:选择K个初始聚类中心。这个步骤的时间复杂度为O(K)。
分配:对每个样本点,计算其与每个聚类中心的距离,并将其分配到距离最近的聚类中心所代表的簇。这个步骤的时间复杂度为O(N * K * d),其中N是样本数,d是特征数。
更新:对每个簇,计算其所有样本点的平均值作为新的聚类中心。这个步骤的时间复杂度为O(N * K * d)。
重复执行第2和第3步,直到满足停止条件,例如达到最大迭代次数或聚类中心变化小于一定阈值。
因此,K均值聚类算法的总体时间复杂度主要由分配和更新两个步骤决定,为O(T * N * K * d),其中T是迭代次数。
K-means手写数字聚类
用kmeas聚类算法对train_images.mat的前100张和前1000张手写数字图像进行聚类,重复测试10次,每次测试的正确率如图6所示,其中100张的平均正确率为59%,最高正确率为66%,平均运行时间为0.1秒,1000张的平均正确率为55%,最高正确率为62%,平均运行时间为3.6秒。
图6 K-means聚类结果
再对train_images.mat的前100张、500张、1000张、2000张和4000张手写数字图像进行聚类,每种图像张数重复测试10次,计算平均正确率和平均运行时间,结果如表1所示。
表1 K-means聚类测试
由表1可知,K-means手写数字聚类在图像数目达到4000张的时候,运行时间达到了41秒,而且平均正确率为60%左右。
K-means性能分析
由结果可以很明显地看出,K-means聚类应用在手写数字上的效果并不是很好,平均正确率只有60%左右,其中有几个原因。一是K-means假设各个簇的大小、形状和密度相似,如果数据集中的簇具有类似的分布特征,K-means能够产生较好的聚类结果,而手写数字数据集的数字并不是均匀分布的,不同的数字可能出现频率不同,而且手写数字的形状有的区别不大;二是K-means在处理高维数据时可能会遇到困难,因为高维空间下的距离计算和聚类结果评估会变得复杂,而实验中手写数字的维度达到了784。
K-means++
K-means聚类算法的一大缺点是初始类别中心的选择对聚类迭代的次数影响很大,而K-means++是想通过选择更好初始类别中心来减少K-means聚类的迭代次数。
那么什么样的初始类别中心是更好的呢?
好的初始类别中心应该能够均匀地覆盖整个数据空间,能够代表数据集中的不同特征。
K-means++算法流程
- 从数据点中随机选择一个点作为第一个聚类中心。
- 对于每个数据点,计算它与当前已选择的聚类中心的距离,选择与已选择的聚类中心距离最大的数据点作为下一个聚类中心。
- 重复步骤②,直到选择出k个初始聚类中心。
K-means++手写数字聚类
用kmeas++聚类算法对train_images.mat的前100张和前1000张手写数字图像进行聚类,重复测试10次,每次测试的正确率如图7所示,其中100张的平均正确率为58%,最高正确率达到了63%,平均运行时间为0.03秒,1000张的平均正确率为57%,最高正确率为61%,平均运行时间为0.76秒。
图7 K-means++聚类结果
我们再对train_images.mat的前100张、1000张、2000张、4000张和8000张手写数字图像进行聚类,每种图像张数重复测试10次,计算平均正确率和平均运行时间,结果如表2所示。
表2 K-means聚类测试
由表2可知,K-means手写数字聚类在图像数目达到8000张的时候,运行时间达到了15秒,而且平均正确率均高于50%。
K-means++性能分析
由结果可以很明显地看出,相比K-means的聚类结果,K-means++的正确率差别不大,基本上也是在60%左右,但是程序运行时间极大的减少了,这说明K-means++的优化,即选择更好的初始类别中心,可以大大的减少算法迭代的过程,迅速聚类。
但是由于K-means++只是为K-means聚类选择更好的初始化中心,这只是减少了聚类的迭代次数,并不能解决K-means聚类手写数字效果不好的问题。
matlab代码kmeans
clc,clear;
load ./train_images.mat;
load ./train_labels.mat;
k=10;
dimension=2;
Dimension=28*28;
picturesNumber=1000;
sample=train_images(:,:,1:picturesNumber);
sample=reshape(sample,28*28,picturesNumber);
sample=sample';
class=zeros(1,picturesNumber);
times=[];
ratios=[];
for time=1:10
tic;
classCenter=sample(randperm(picturesNumber,k),:); % 随机取点
iterator=0;
while(true)
iterator=iterator+1;
nextCenter=zeros(k,Dimension);
classNumber=zeros(1,k);
for i=1:picturesNumber
distances=zeros(1,k);
for j=1:k
distances(j)=pdist2(sample(i,:),classCenter(j,:));
end
[~,index]=sort(distances);
class(i)=index(1);
classNumber(class(i))=classNumber(class(i))+1;
nextCenter(class(i),:)=nextCenter(class(i),:)+sample(i,:);
end
temp=classCenter;
for i=1:k
if classNumber(i)~=0
classCenter(i,:)=nextCenter(i,:)/classNumber(i);
end
end
if temp==classCenter
break
end
end
map=containers.Map('KeyType','int32','ValueType','int32');
for i=1:k
number=[];
for j=1:picturesNumber
if class(j)==i
number=[number,train_labels(j)];
end
end
map(i)=mode(number);
end
count=0;
for i=1:picturesNumber
if map(class(i))==train_labels(i)
count=count+1;
end
end
ratio=count/picturesNumber;
ratios=[ratios,ratio];
times=[times,toc];
endmatlab代码kmeans++
clc;
clear;
load ./train_images.mat;
load ./train_labels.mat;
k = 10;
dimension = 2;
Dimension = 28 * 28;
picturesNumber = 100;
sample = train_images(:, :, 1:picturesNumber);
sample = reshape(sample, 28 * 28, picturesNumber);
sample = sample';
class = zeros(1, picturesNumber);
times = [];
ratios = [];
for time = 1:10
tic;
% K-Means++ initial center selection
classCenter = zeros(k, Dimension);
classCenter(1, :) = sample(randi(picturesNumber), :);
for j = 2:k
distances = pdist2(sample, classCenter(1:j-1, :));
minDistances = min(distances, [], 2); % 为什么挑最近的呢?因为是挑离所有已选中心最远的
[~, index] = max(minDistances);
classCenter(j, :) = sample(index, :);
end
iterator = 0;
while (true)
iterator = iterator + 1;
nextCenter = zeros(k, Dimension);
classNumber = zeros(1, k);
for i = 1:picturesNumber
distances = pdist2(sample(i, :), classCenter);
[~, index] = min(distances);
class(i) = index;
classNumber(class(i)) = classNumber(class(i)) + 1;
nextCenter(class(i), :) = nextCenter(class(i), :) + sample(i, :);
end
temp = classCenter;
for i = 1:k
if classNumber(i) ~= 0
classCenter(i, :) = nextCenter(i, :) / classNumber(i);
end
end
if isequal(temp, classCenter)
break;
end
end
map = containers.Map('KeyType', 'int32', 'ValueType', 'int32');
for i = 1:k
number = [];
for j = 1:picturesNumber
if class(j) == i
number = [number, train_labels(j)];
end
end
map(i) = mode(number);
end
count = 0;
for i = 1:picturesNumber
if map(class(i)) == train_labels(i)
count = count + 1;
end
end
ratio = count / picturesNumber;
ratios = [ratios, ratio];
times = [times, toc];
end


![【算法每日一练]-单调队列,滑动窗口(保姆级教程 篇1) #滑动窗口 #求m区间的最小值 #理想的正方形 #切蛋糕](https://img-blog.csdnimg.cn/fb8a0cd6585a41738fa99b61c1a8d7eb.png)


![[vuex] unknown mutation type: SET_SOURCE](https://img-blog.csdnimg.cn/f25632fba81b4a0992b467ce7e48377b.png)





![路径总和[简单]](https://img-blog.csdnimg.cn/60348911162c46298b7362e67cee9db9.png)

