编者按: IDP开启Embedding系列专栏,力图详细介绍Embedding的发展史、主要技术和应用。
本文是《Embedding技术与应用系列》的第三篇,重点介绍 嵌入技术在生产环境中的应用效果到底如何。
文章作者认为,嵌入技术可以有效地表示用户兴趣偏好,帮助推荐系统进行个性化内容推荐。作者详细分析了Pinterest、YouTube、Google Play、Twitter等平台在推荐系统中应用嵌入技术的案例。这些案例表明,适当使用嵌入技术,可以提升推荐质量,增强用户粘性。作者认为,当具备大量用户数据时,嵌入技术可以成为构建高质量推荐系统的关键工具。
当然,在推荐系统中应用嵌入技术也需要谨慎,比如需要注意避免泛化能力不足的问题。我们期待在后续文章中能看到作者对嵌入技术应用的更多思考。
以下是译文,enjoy!
🚢🚢🚢欢迎小伙伴们加入AI技术软件及技术交流群,追踪前沿热点,共探技术难题~
作者 | Vicki Boykis
编译 | 岳扬
随着 Transformer 模型的出现,更重要的是随着 BERT 的出现,生成大型多模态对象(比如图像、文本、音频等)的特征表示变得更加简单和准确,如果同时使用GPU,计算也可以进行并行加速。这就是embedding的作用,那么我们应该如何使用它们?毕竟,我们绞尽脑汁搞出embedding不仅仅是为了进行数学练习。
所有生产级别的机器学习项目的最终目标是开发机器学习产品并快速将其应用于生产环境。
如今,许多公司正在很多场景中使用嵌入(embedding)技术,基本上涉及了信息检索的各个方面。比如,深度学习模型生成的嵌入正被用于Google Play应用商店推荐系统[1],双重嵌入(dual embeddings)被用于Overstock的产品互补内容推荐功能[2]、Airbnb通过实时排名(real-time ranking)实现搜索结果个性化[3]、Netflix利用嵌入技术进行内容理解(content understanding)[4]、Shutterstock利用嵌入技术进行视觉风格理解[5]等。
01 Pinterest
Pinterest就是一个值得关注的嵌入应用案例。Pinterest是一款应用程序,有许多内容需要向用户进行个性化推荐和分类,特别是首页和购物这两个界面。由于所生成内容的规模非常庞大——每月有3.5亿活跃用户和20亿条内容(Pins 或者用文字描述图片的卡片),因此需要一个强有力的内容过滤和排序策略(filtering and ranking policy)。
为了更好地表示用户的兴趣并呈现有趣的内容,Pinterest开发了PinnerSage [6]。PinnerSage通过多个256维度的嵌入来表示用户的代表性对象,这些嵌入基于相似度(similarity)进行聚类,并通过medioids来表示(译者注:medioids是用户兴趣聚类中心的代表性对象,后文同此)
该系统的基础是通过一种名为PinSage[7]的算法开发的一组嵌入。PinSage使用图卷积神经网络(Graph Convolutional neural network)生成嵌入,这是一种考虑到网络中节点之间关系的图神经网络。该算法会查看Pin的最近邻(nearest neighbors),并基于相关邻域访问(neighborhood visits)从附近的Pin中进行采样。输入内容是Pin的嵌入:图像嵌入(image embeddings)和文本嵌入(text embeddings)和找到的最近邻。
然后将 Pinsage 嵌入传递给 Pinnersage,Pinnersage 会获取用户过去90天内操作的 Pin 并对它们进行聚类,然后计算出 medioid 并根据重要性取前3个medioid。如果用户的查询是一个medioid,Pinnersage会使用HNSW执行近似最近邻搜索(approximate nearest neighbors search),在嵌入空间中找到最接近用户查询的pin。

图1 基于嵌入的相似性检索方法:Pinnersage 和 Pinsage
02 YouTube and Google Play Store
2.1 YouTube
YouTube是最早公开分享在生产推荐系统中使用嵌入的大型公司之一,关于这项工作的论文名为“Deep Neural Networks for YouTube Recommendations”。
YouTube拥有超过8亿个视频和26亿活跃用户,他们需要向这些用户推荐这些视频。推荐系统需要向用户推荐现有的视频内容,同时还需要对不断上传的新内容进行归纳。Youtube需要在用户加载新页面时以低延迟推荐视频内容。
在这篇论文[7]中,YouTube 分享了他们如何基于两个深度学习模型创建了一个两阶段的视频推荐系统。该机器学习任务是预测下一个要推荐的视频,给定时间内在 YouTube 推荐栏中向用户展示,以便用户点击。最终的输出被表述为一个分类问题:给出用户的输入特征和视频的输入特征,我们能否预测用户对特定视频的预测观看时间和观看概率。
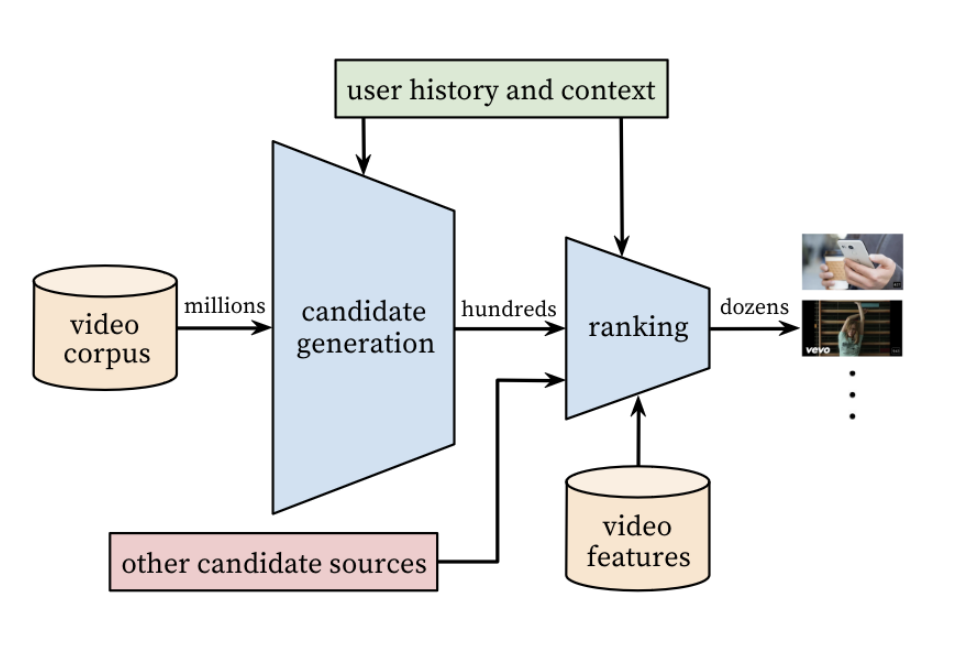
图2 YouTube的端到端(end-to-end)视频推荐系统,包括候选内容生成器和排序器[7]
我们基于用户 U 和上下文 C 设定了这一任务[8]。
考虑到输入数据集的规模比较大,我们需要把该任务分解为两阶段的推荐系统:第一阶段是候选视频生成器,用于将候选视频集的数量减少到数百个;第二个阶段的模型的size和shape与之相似,称为排序器,其用于对这数百个视频按照用户点击并观看的概率进行排序。
候选视频生成器(The candidate generator)是一个具有多个层的 softmax 深度学习模型,所有层都使用了ReLU激活函数,即修正线性单元激活函数(rectified linear unit activation)。如果输入为正,则直接输出;反之,则输出为零。该模型同时使用嵌入(embedded)特征和表格学习(tabular learning)特征,所有这些特征都将组合在一起。
为了构建模型,我们使用两组嵌入数据用作输入数据:一组是将用户(user)和上下文(context)作为特征,另一组是视频内容项。该模型有几百个特征,包括表格特征和基于嵌入的特征。基于嵌入的特征,包括以下元素:
- 用户的观看历史,由映射到密集向量表征(dense vector representation)中的稀疏视频 ID 向量(vector of sparse video ID elements)来表示。
- 用户的搜索历史,将搜索词映射到从搜索结果点击的视频,同样也是以稀疏向量的形式映射到与用户观看历史相同的空间中。
- 用户的地理位置、年龄和性别,作为表格特征映射。
- 视频以前的观看次数,根据时间对每个用户的数据进行归一化。
所有这些特征都会被组合成一个单一的嵌入,对于用户来说,就是所有用户嵌入特征的混合映射,并会将其输入到模型的softmax层中。该层会比较softmax层的输出(即用户点击推荐视频的概率)和一组真实情况(即用户已经交互的视频项)之间的距离。视频项的对数概率是两个n维向量(即用户查询和视频嵌入)的点积。(译者注:此处的对数概率是指视频被用户点击或观看的概率的对数值。)
我们认为这是隐式反馈(Implicit feedback)的一个例子,即用户没有明确给出的反馈(例如评分),但我们可以从日志数据中捕捉到用户的兴趣,对每个视频类别(大约有一百万个)都会有一个用户喜爱几率的概率结果输出。 (译者注:模型能够预测用户点击或观看每个视频类别的概率,这些概率结果可以用于计算每个用户对于每个视频类别的相对重要性,并为用户推荐最相关的视频。)
这个DNN就是我们前面讨论过的矩阵分解模型(matrix factorization model)的一种泛化形式。
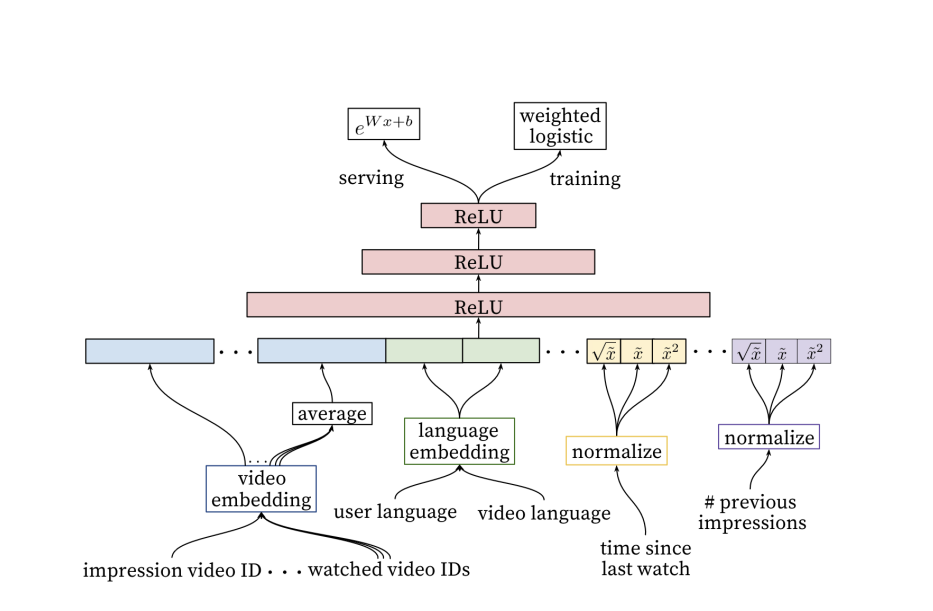
图3 YouTube使用输入嵌入的多步神经网络模型(multi-step neural network model)进行视频推荐[7]
2.2 Google Play App Store
在Google Play应用商店中,也进行了类似的工作,不过使用了不同的架构,如"Wide and Deep Learning for Recommender Systems"[9],该推荐系统可以跨越搜索和推荐领域(search and recommendation space),返回被正确排名和个性化的应用推荐结果。该模型的输入是用户在访问应用商店时所产生的点击流数据(clickstream data)。
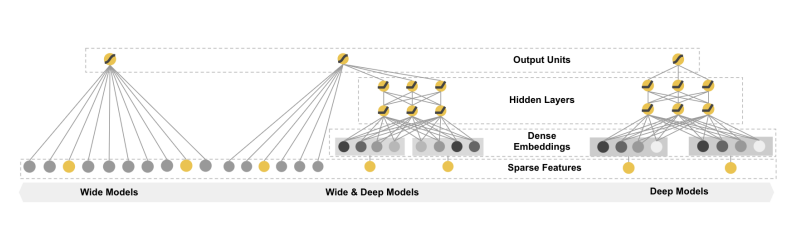
图4 Wide and deep[9]
该系统将推荐问题的解决分配给两个联合训练的模型。在训练时的各个epoch,权重在两个模型之间共享和交叉传播(shared and cross-propagated)。
在尝试构建推荐系统所需的模型时,通常会遇到两个问题:记忆能力(memorization)和泛化能力(generalization)。 模型需要通过学习历史数据中应用是如何一起被用户下载的来学习用户模式,同时也需要能够为用户提供以前未见过但仍然与用户相关的新应用推荐,从而提高推荐内容的多样性。通常,一个单独的模型无法同时兼顾这两个方面。
Wide and deep由两个互补的模型组成:
- Wide模型通过传统的表格特征(tabular features)来提高模型的记忆能力。 这是一个通用的线性模型(linear model),它是在数千个应用程序中使用稀疏的独热编码特征(如 user_installed_app=netflix)进行训练的。记忆能力(Memorization)的作用是创建二元特征,这些二元特征是特征的组合,例如AND(user_installed_app=netflix, impression_app_pandora),使我们能够看到与目标相关的可能共同出现的不同组合。然而,该模型无法泛化到训练数据之外的新应用。
- Deep模型通过使用前馈神经网络(feed-forward neural network)来实现泛化能力,该网络由分类特征(categorical features)组成,并将这些特征转换为嵌入(例如用户使用的语言、设备类别以及用户对给定应用程序是否有印象等)。 每个嵌入向量的维度范围都在0-100之间,这些向量被组合成一个具有1200维的稠密向量嵌入空间,并对其进行随机初始化。对嵌入向量的值进行训练,以最终函数的loss值的最小化,该函数是Deep和Wide模型共同使用的逻辑损失函数(logistic loss function)。Deep模型能够泛化到模型以前没有见过的应用程序,从而提高了推荐的多样性。
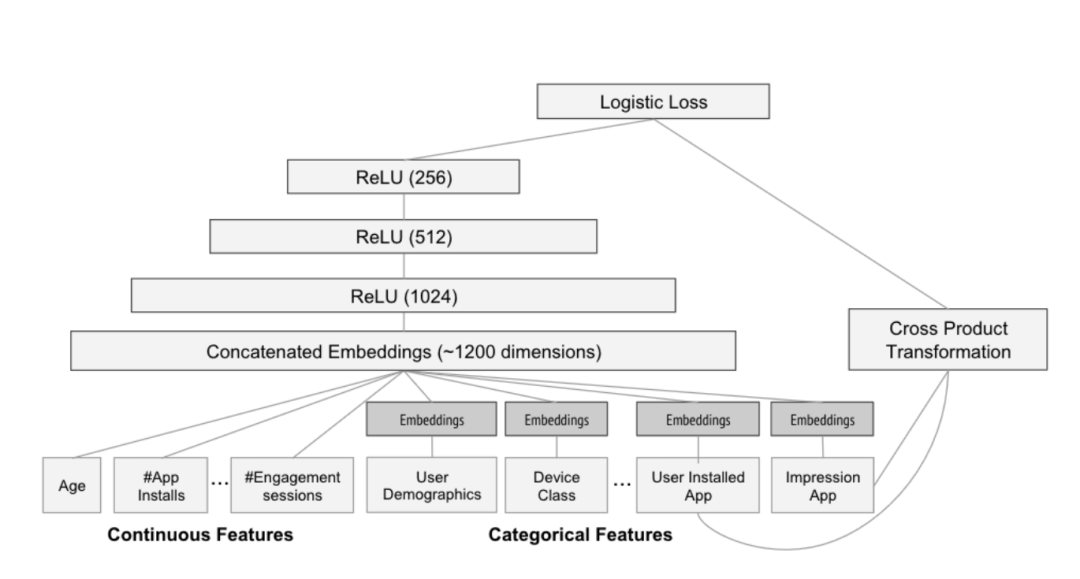
图5 wide and deep模型的deep部分[9]
该模型使用 5000 亿个样本进行训练,并使用 AUC 进行离线评估,同时使用应用下载转化率(即人们完成下载应用整个步骤的速度)进行在线评估。根据论文,与对照组相比,使用这种方法提高了应用商店主页面上的应用下载转化率达3.9%。
03 Twitter
在Twitter中,预先计算的嵌入向量是许多应用功能实现推荐功能的关键组成部分,包括新用户的主题兴趣预测、推荐的推文、主页时间线构建、用户关注推荐和广告推荐等。
Twitter拥有许多基于嵌入向量的模型,但在这里我们只介绍其中的两个项目:Twice [10]和TwHIN [11]。
Twice是一个基于内容的嵌入向量模型,旨在查找 Tweets 的丰富表示形式(包含文本和视觉数据的推文),以便在主页时间线(home timeline)、通知(Notifications)和主题(Topics)中呈现推文。
Twitter还开发了TwHIN [11],即Twitter异构信息网络(Twitter Heterogeneous Information Network),它是一组基于图的嵌入向量(graph-based embeddings),用于个性化广告的排序、账户关注推荐、有害内容检测和搜索内容排序等任务,该异构信息网络基于节点(如用户和广告商)和代表实体交互的边。
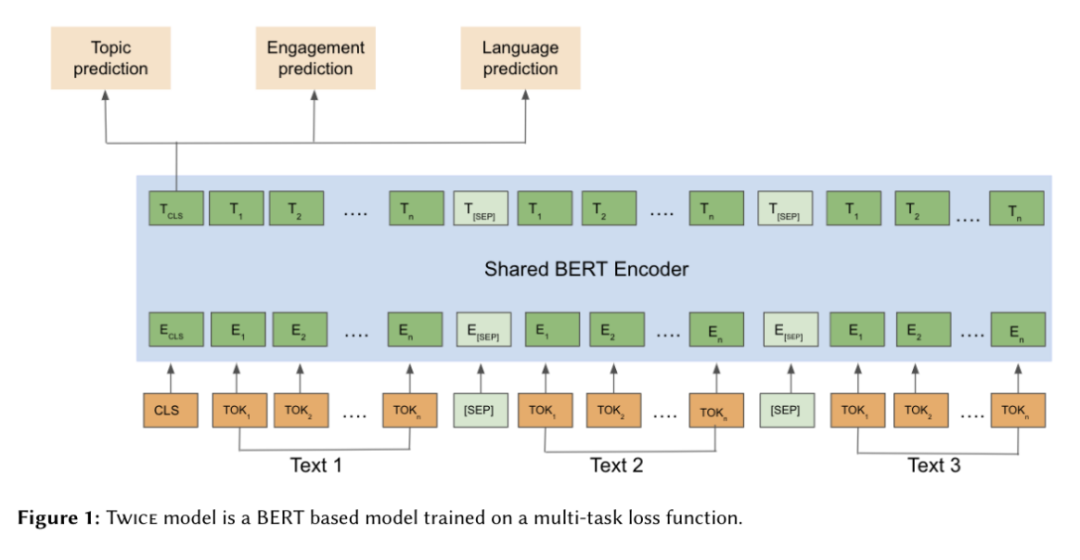
图6 Twitter的Twice Embeddings是一个经过训练的BERT模型[10]
Twice 是一个从头开始训练的 BERT 模型,其以 Twitter 用户在 90 天内产生的 2 亿条推文作为训练语料,并包括这些推文与用户本身的关系。该模型的目标是优化以下几项任务:主题预测(即与推文相关的主题,可能有多个) 、参与度预测(用户参与推文(译者注:可能是点赞、评论、转发等操作)的可能性) 和语言预测,以将相同语言的推文聚类在一起。
相比于仅关注推文内容,TwHIN将Twitter环境中的所有实体(推文、用户、广告实体)视为联合嵌入空间图(joint embedding space graph)中的一部分。联合嵌入是通过使用用户和推文的互动、广告和“关注用户”的数据来创建多模态嵌入(multi-model embeddings)来完成的。TWHin用于候选推荐内容的生成。候选推荐内容生成器(The candidate generator)使用HNSW或Faiss来检索候选可推荐内容,找到可推荐关注的用户或可推荐参与的推文。然后使用TWHin嵌入向量来查询候选的推荐内容,并增加候选推荐内容的多样性。
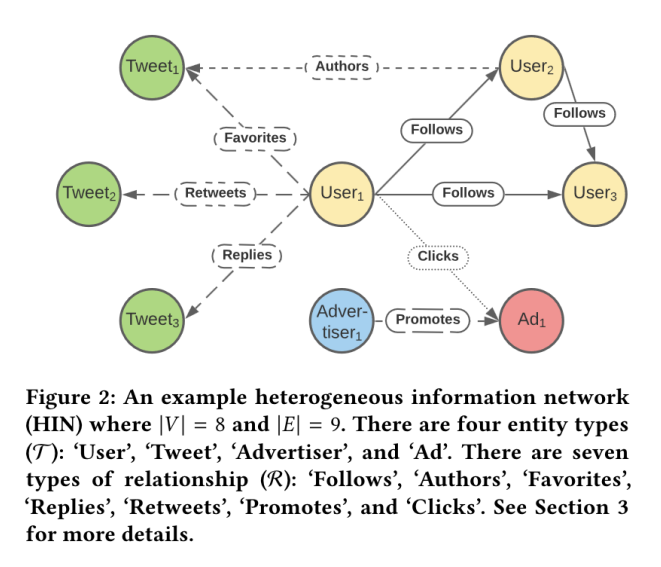
图7 Twitter的异构信息网络模型[11]
04 在通过Flutter开发的应用程序中使用嵌入向量技术
一旦我们综合了足够多的系统架构,我们会看到一些开发模式开始慢慢出现,我们可以考虑将这些模式用于开发 Flutter 类应用程序的相关推荐系统。(译者注:Flutter是一个由谷歌开发的开源跨平台应用软件开发工具包,用于为Android、iOS、Windows、macOS、Linux Desktop、Google Fuchsia开发应用。)首先,我们需要大量的输入数据才能进行准确的预测,并且这些数据应该包含有关显式数据或更可能是隐式数据的信息,例如用户的点击和购买数据,这样我们才能构建用户偏好模型。我们需要大量数据的原因有两个。首先,神经网络需要大量的训练数据才能正确推断出各种关系,相比传统模型而言,它们对训练数据量的需求更高。其次,大量数据需要一个大的管道。
如果我们没有太多的数据,那么一个更简单的模型就足够了,因此我们需要确保我们确实达到了嵌入和神经网络能够帮助我们解决业务问题的规模。我们可以从更简单的模型开始。事实上,最近一篇论文认为,基于矩阵分解的简单点积运算优于神经网络模型[12],这篇论文由开发因式分解机(推荐系统中的一种重要方法)的最初研究人员之一撰写。其次,为了获得良好的嵌入,我们需要花费大量时间清理和处理数据并创建表征,就像我们在 YouTube 论文中所做的那样,因此结果必须值得花费时间。
其次,我们需要能够理解用户与他们互动的内容之间的潜在关系。在传统的推荐系统中,只要我们的语料库不会太大,我们就可以使用 TF-IDF 来查找加权的单词特征,作为特定 flit 的一部分,然后在不同文档之间进行比较。在更高级的推荐系统中,我们可以通过研究简单的关联规则,或将推荐作为一个基于交互的协同过滤问题来学习用户和内容的潜在特征(也称为嵌入向量)。事实上,这正是Levy和Goldberg在《Neural Word Embedding as Implicit Matrix Factorization》[13]中所提出的观点。他们研究了 Word2Vec 的 skipgram 实现,并发现它隐式地对单词-上下文矩阵(word-context matrix)进行了因子分解。
我们也可以将表格特征作为协同过滤问题(collaborative filtering problem)的输入,但使用神经网络[14]而非简单的点积来收敛正确的关系和模型的下游排序。
鉴于我们对嵌入向量和推荐系统如何工作有了新的认识,我们现在可以将嵌入向量融入到Flutter的flit推荐中。如果我们想推荐相关内容,根据业务需求,我们可以采用多种不同的方式。在语料库中,有数以亿计的消息,我们需要筛选出数以百计的消息向用户展示。因此,我们可以从Word2Vec或其他类似的baseline开始,然后通过嵌入的力量,采用任何BERT或其他神经网络方法来开发模型输入特征、向量相似性搜索和排序等功能。
嵌入向量具有无限的灵活性和无尽的用途,可以提高多模态机器学习工作流程(multimodal machine learning workflows)的性能。然而,正如我们刚才看到的,如果我们决定使用它们,还需要注意一些事项。我们将在下一篇文章详细讨论需要注意的事项!
🚢🚢🚢欢迎小伙伴们加入AI技术软件及技术交流群,追踪前沿热点,共探技术难题~
在实际工程中使用Embedding技术需要注意些什么?下一期,我们将探析Embedding技术使用中的挑战和注意事项,敬请期待。
相关文章:
Embedding技术与应用 (2) :神经网络的发展及现代Embedding方法简介
Embeddig技术与应用 (1) :Embedding技术发展概述及Word2Vec
END
参考资料
[1]Shuai Zhang, Lina Yao, Aixin Sun, and Yi Tay. Deep learning based recommender system: A survey and new perspectives. ACM computing surveys (CSUR), 52(1):1–38, 2019.
[2]Giorgi Kvernadze, Putu Ayu G Sudyanti, Nishan Subedi, and Mohammad Hajiaghayi. Two is better than one: Dual embeddings for complementary product recommendations. arXiv preprint arXiv:2211.14982, 2022.
[3]Mihajlo Grbovic and Haibin Cheng. Real-time personalization using embeddings for search ranking at airbnb. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, pages 311–320, 2018.
[4]Melody Dye, Chaitanya Ekandham, Avneesh Saluja, and Ashish Rastogi. Supporting content decision makers with machine learning, Dec 2020. URL https://netflixtechblog.com/supporting-contentdecision-makers-with-machine-learning-995b7b76006f.
[5]Raul Gomez Bruballa, Lauren Burnham-King, and Alessandra Sala. Learning users’ preferred visual styles in an image marketplace. In Proceedings of the 16th ACM Conference on Recommender Systems, pages 466–468, 2022.
[6]Aditya Pal, Chantat Eksombatchai, Yitong Zhou, Bo Zhao, Charles Rosenberg, and Jure Leskovec. Pinnersage: Multi-modal user embedding framework for recommendations at pinterest. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 2311–2320, 2020.
[7]Paul Covington, Jay Adams, and Emre Sargin. Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM conference on recommender systems, pages 191–198, 2016.
[8]Thorsten Joachims. Text categorization with support vector machines: Learning with many relevant features. In Machine Learning: ECML-98: 10th European Conference on Machine Learning Chemnitz, Germany, April 21–23, 1998 Proceedings, pages 137–142. Springer, 2005.
[9]Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al. Wide & deep learning for recommender systems. In Proceedings of the 1st workshop on deep learning for recommender systems, pages 7–10, 2016.
[10]Xianjing Liu, Behzad Golshan, Kenny Leung, Aman Saini, Vivek Kulkarni, Ali Mollahosseini, and Jeff Mo. Twice-twitter content embeddings. In CIKM 2022, 2022.
[11]Ahmed El-Kishky, Thomas Markovich, Serim Park, Chetan Verma, Baekjin Kim, Ramy Eskander, Yury Malkov, Frank Portman, Sofía Samaniego, Ying Xiao, et al. TwHIN: Embedding the Twitter Heterogeneous Information Network for Personalized Recommendation. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 2842–2850, 2022.
[12]Steffen Rendle, Walid Krichene, Li Zhang, and John Anderson. Neural collaborative filtering vs. matrix factorization revisited. In Proceedings of the 14th ACM Conference on Recommender Systems, pages 240–248, 2020.
[13]Omer Levy and Yoav Goldberg. Neural word embedding as implicit matrix factorization. Advances in neural information processing systems, 27, 2014.
[14]Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. Neural collaborative filtering. In Proceedings of the 26th international conference on world wide web, pages 173–182, 2017.
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:
https://vickiboykis.com/what_are_embeddings/index.html