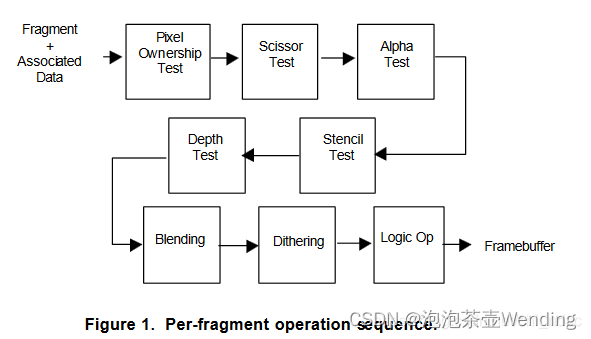
什么是激活函数?
在人工神经网络中,节点的激活函数定义了该节点或神经元对于给定输入或一组输入的输出。然后将该输出用作下一个节点的输入,依此类推,直到找到原始问题的所需解决方案。
它将结果值映射到所需的范围,例如 0 到 1或-1 到 1 等。这取决于激活函数的选择。例如,使用逻辑激活函数会将实数域中的所有输入映射到 0 到 1 的范围内。
二元分类问题的示例:
在二元分类问题中,我们有一个输入 x,比如一张图像,我们必须将其分类为是否具有正确的对象。如果它是正确的对象,我们将为其分配 1,否则为 0。因此,这里我们只有两个输出 - 图像要么包含有效对象,要么不包含。这是二元分类问题的示例。
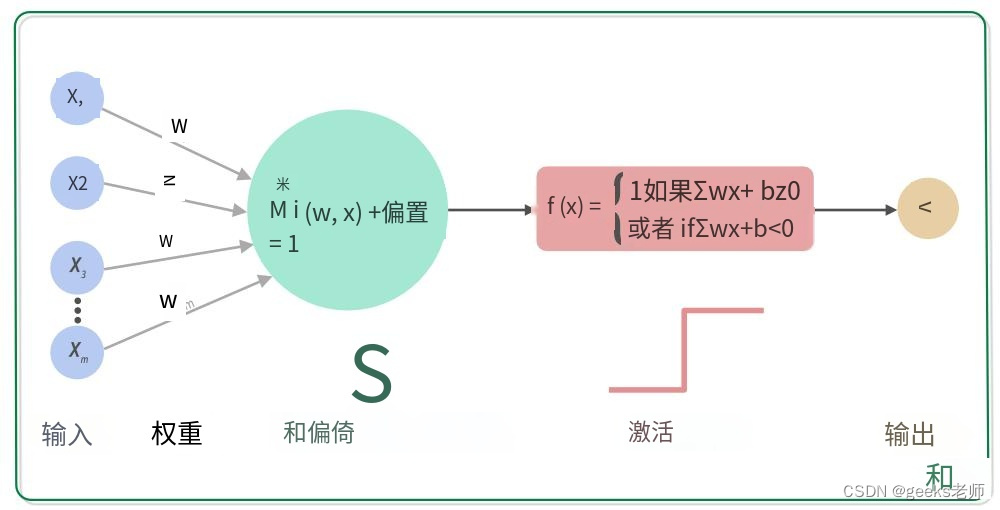
当我们将每个特征与权重(w1,w2,...,wm)相乘并将它们全部加在一起时,
节点输出 = 激活(输入的加权和)。
(1)
`
一些重要的术语和数学概念 –
- 传播是反复调整权重以最小化实际输出和期望输出之间的差异的过程。
- 隐藏层是堆叠在输入和输出之间的神经元节点,允许神经网络学习更复杂的特征(例如异或逻辑)。
- 反向传播是反复调整权重以最小化实际输出和期望输出之间的差异的过程。
它允许信息通过网络从成本向后返回,以计算梯度。因此,以逆拓扑顺序从最终节点开始循环节点,以计算最终节点输出的导数。这样做将帮助我们了解谁对最多的错误负责,并朝该方向适当更改参数。
- 训练机器学习模型时使用梯度下降。它是一种基于凸函数的优化算法,迭代地调整其参数以将给定函数最小化至局部最小值。梯度测量的是如果稍微改变输入,函数的输出会发生多少变化。
注意:如果梯度下降正常工作,成本函数应该在每次迭代后减小。
激活功能的类型:
激活函数基本上有两种类型:
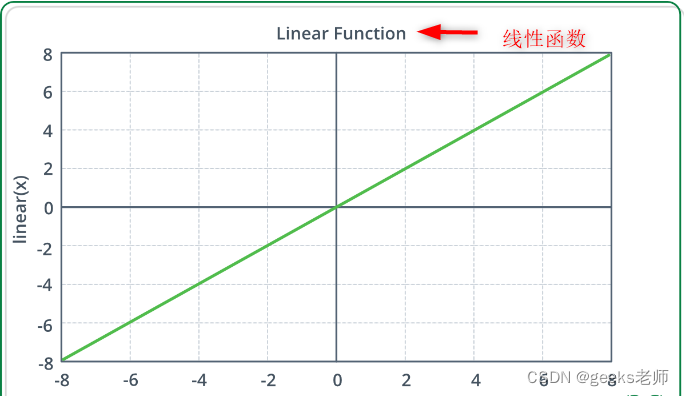
1. 线性激活函数 –
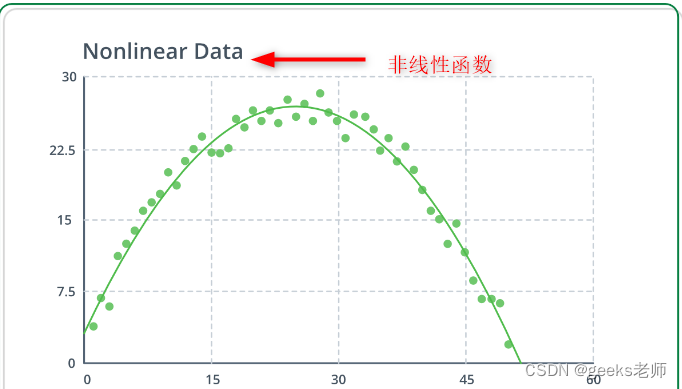
2. 非线性激活函数——
它使模型可以轻松地概括各种数据并区分输出。通过仿真发现,对于较大的网络,ReLU 的速度要快得多。事实证明,ReLU 可以大大加快大型网络的训练速度。非线性意味着输出不能从输入的线性组合中再现。
非线性函数需要理解的主要术语是:
1. 导数: y 轴的变化相对于 x 轴的变化。它也被称为坡度。
2. 单调函数:完全不增或不减的函数。
非线性激活函数主要根据其范围或曲线划分如下:
让我们更深入地了解每个激活函数 -
1.乙状结肠:
它也称为二元分类器或逻辑激活函数,因为函数始终选择 0(假)或 1(真)值。
sigmoid 函数产生与阶跃函数类似的结果,输出在 0 和 1 之间。曲线在 z=0 处与 0.5 相交,我们可以为激活函数设置规则,例如:如果 sigmoid 神经元的输出大于或等于0.5,输出1;如果输出小于0.5,则输出0。
sigmoid 函数的曲线没有急动。它是平滑的,并且有一个非常好的和简单的导数,它在曲线上的任何地方都是可微的。
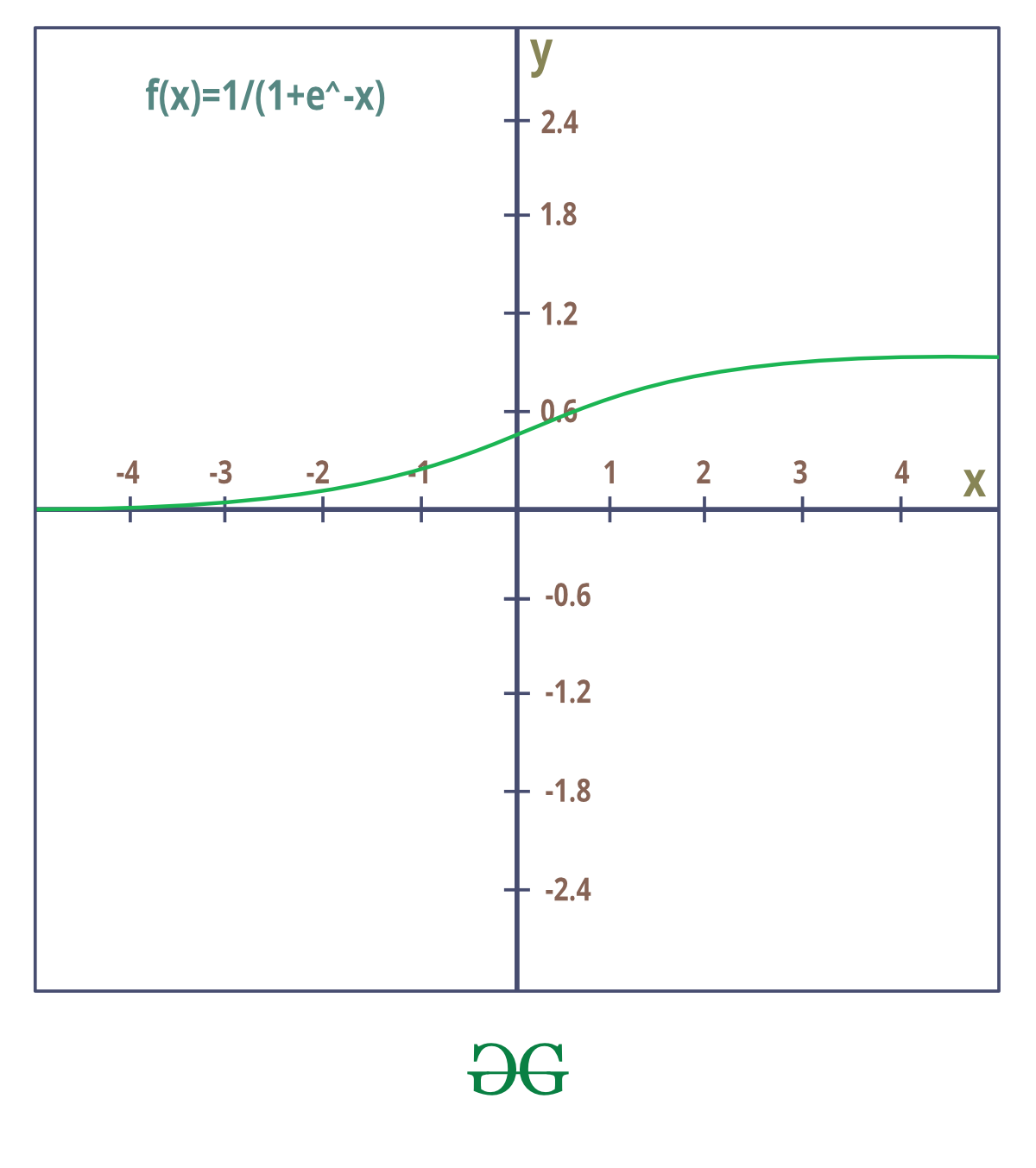
Sigmoid 的推导:
S 型函数会饱和并杀死梯度。sigmoid 的一个非常常见的属性是,当神经元的激活在 0 或 1 处饱和时,这些区域的梯度几乎为零。回想一下,在反向传播期间,该局部梯度将乘以整个目标的该门输出的梯度。因此,如果局部梯度非常小,它将有效地“杀死”梯度,几乎没有信号会通过神经元流向其权重并递归至其数据。此外,还会添加额外的惩罚来初始化 S 形神经元的权重,以防止饱和。例如,如果初始权重太大,那么大多数神经元将变得饱和,网络几乎无法学习。
2.ReLU(修正线性单元):
它是使用最广泛的激活函数。因为几乎所有的卷积神经网络都使用它。ReLU是从底部开始进行半整流的。该函数及其导数都是单调的。
f(x) = 最大值(0, x)
接近线性的模型很容易优化。由于 ReLU 具有线性函数的许多属性,因此它往往可以很好地解决大多数问题。唯一的问题是导数没有在 z = 0 处定义,我们可以通过将 z = 0 处的导数分配给 0 来克服这个问题。然而,这意味着对于 z <= 0 梯度为零,并且再次无法学习。
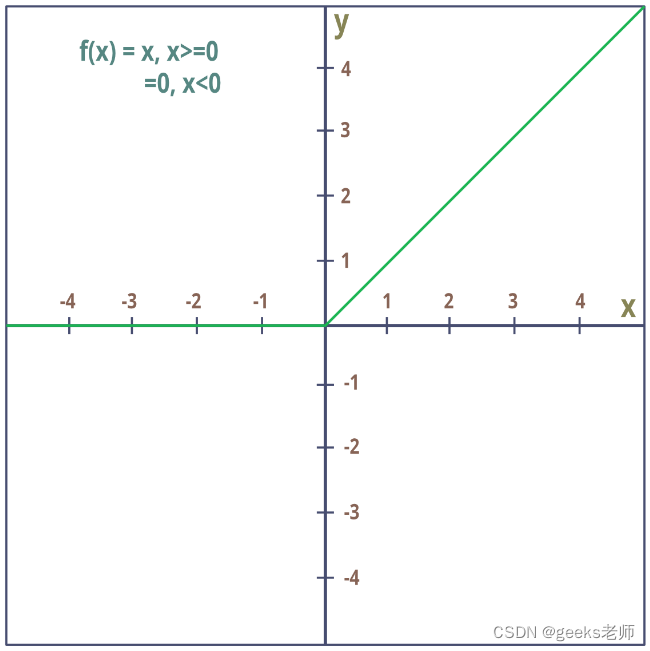
3. 泄漏 ReLU:
Leaky ReLU 是 ReLU 函数的改进版本。ReLU 函数,当 x<0 时梯度为 0,这使得神经元因该区域的激活而死亡。Leaky ReLU 就是为了解决这个问题而定义的。我们不是将 Relu 函数定义为 x 小于 0 时的 0,而是将其定义为 x 的一个小的线性分量。Leaky ReLU 是解决 Dying ReLU 问题的一种尝试。当 x < 0 时,函数不会为零,而是泄漏 ReLU 将具有较小的负斜率(0.01 左右)。也就是说,该函数计算:![]()
(2) 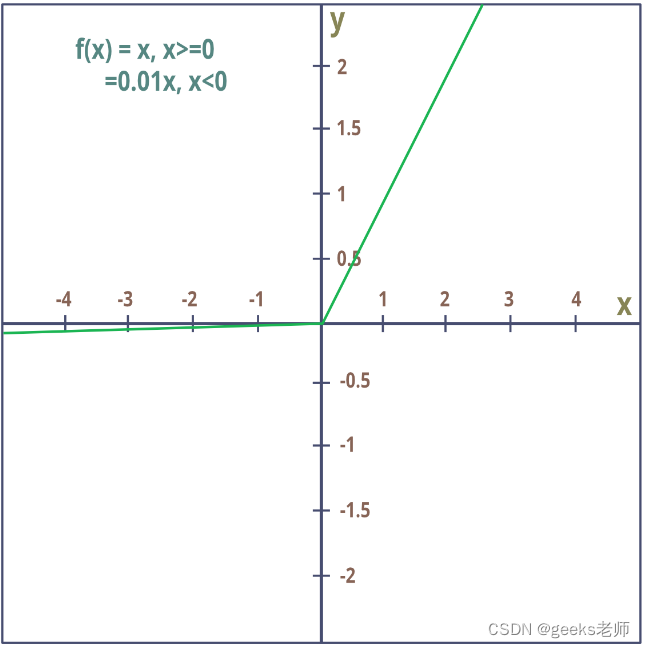 4. Tanh 或双曲正切:
4. Tanh 或双曲正切:
它将实数值压缩到 [-1, 1] 范围内。与 S 型神经元一样,它的激活会饱和,但与 S 型神经元不同的是,它的输出是以零为中心的。因此,tanh 非线性始终优于 sigmoid 非线性。tanh 神经元只是一个缩放的 s 形神经元。
Tanh 也类似于逻辑 sigmoid,但更好。优点是负输入将映射为强负值,零输入将映射为 tanh 图中接近零的值。
该函数是可微单调的,但其导数不是单调的。tanh 和逻辑 Sigmoid 激活函数都用于前馈网络。
它实际上只是 sigmoid 函数的缩放版本。
tanh(x)=2 sigmoid(2x)-1

5.Softmax:
sigmoid 函数可以轻松应用,ReLU 不会在您的训练过程中消除效果。然而,当你想要处理分类问题时,它们就没有多大帮助了。sigmoid 函数只能处理两个类,这不是我们所期望的,但我们想要更多。softmax 函数将每个单元的输出压缩到 0 到 1 之间,就像 sigmoid 函数一样。它还对每个输出进行除法,使输出的总和等于 1。
softmax 函数的输出相当于分类概率分布,它告诉您任何类别为真的概率。


其中0是输出层输入的向量(如果有 10 个输出单元,则 z 中有 10 个元素)。同样,j 对输出单位进行索引,因此 j = 1, 2, …, K。
Softmax 函数的属性 –
1.计算的概率将在 0 到 1 的范围内。
2.所有概率的总和等于 1。
Softmax 函数用法 –
1.用于多分类逻辑回归模型。
2.在构建神经网络时,softmax 函数用于不同层和多层感知器。
例子:
(3) 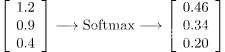
Softmax 函数将 logits [1.2, 0.9, 0.4] 转换为概率 [0.46, 0.34, 0.20],并且概率之和为 1。