参考:
https://www.mindspore.cn/tutorials/en/r1.3/save_load_model.html
https://github.com/mindspore-lab/mindcv/blob/main/docs/zh/tutorials/finetune.md
1、mindspore mindcv图像分类算法
import os
from mindcv.utils.download import DownLoad
import os
import mindspore as ms
os.environ['DEVICE_ID']='0'
ms.set_context(mode=ms.GRAPH_MODE, device_target="CPU", device_id=0) ##指定cpu
#ms.set_context(mode=ms.GRAPH_MODE, device_target="Ascend", device_id=0) ##需要使用才能npu加速
dataset_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/intermediate/Canidae_data.zip"
root_dir = "./"
if not os.path.exists(os.path.join(root_dir, 'data/Canidae')):
DownLoad().download_and_extract_archive(dataset_url, root_dir)
##加载数据
from mindcv.data import create_dataset, create_transforms, create_loader
num_workers = 8
# 数据集目录路径
data_dir = "./data/Canidae/"
# 加载自定义数据集
dataset_train = create_dataset(root=data_dir, split='train', num_parallel_workers=num_workers)
dataset_val = create_dataset(root=data_dir, split='val', num_parallel_workers=num_workers)
# 定义和获取数据处理及增强操作
trans_train = create_transforms(dataset_name='ImageNet', is_training=True)
trans_val = create_transforms(dataset_name='ImageNet',is_training=False)
loader_train = create_loader(
dataset=dataset_train,
batch_size=16,
is_training=True,
num_classes=2,
transform=trans_train,
num_parallel_workers=num_workers,
)
loader_val = create_loader(
dataset=dataset_val,
batch_size=5,
is_training=True,
num_classes=2,
transform=trans_val,
num_parallel_workers=num_workers,
)
#模型微调
from mindcv.models import create_model
network = create_model(model_name='densenet121', num_classes=2, pretrained=True)
#训练
from mindcv.loss import create_loss
from mindcv.optim import create_optimizer
from mindcv.scheduler import create_scheduler
from mindspore import Model, LossMonitor, TimeMonitor
# 定义优化器和损失函数
opt = create_optimizer(network.trainable_params(), opt='adam', lr=1e-4)
loss = create_loss(name='CE')
# 实例化模型
model = Model(network, loss_fn=loss, optimizer=opt, metrics={'accuracy'})
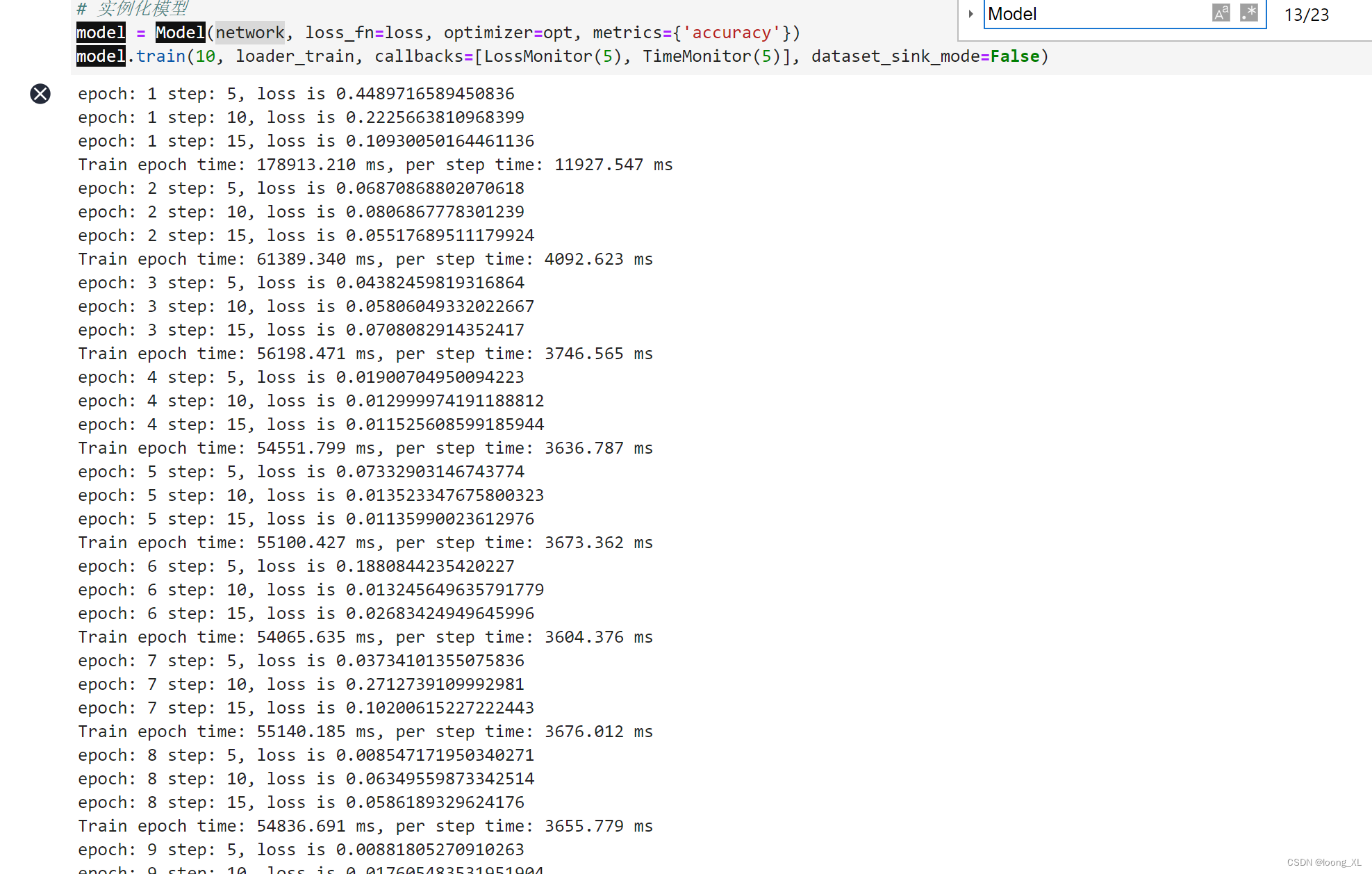
model.train(10, loader_train, callbacks=[LossMonitor(5), TimeMonitor(5)], dataset_sink_mode=False)
res = model.eval(loader_val)
print(res)
import matplotlib.pyplot as plt
import mindspore as ms
import numpy as np
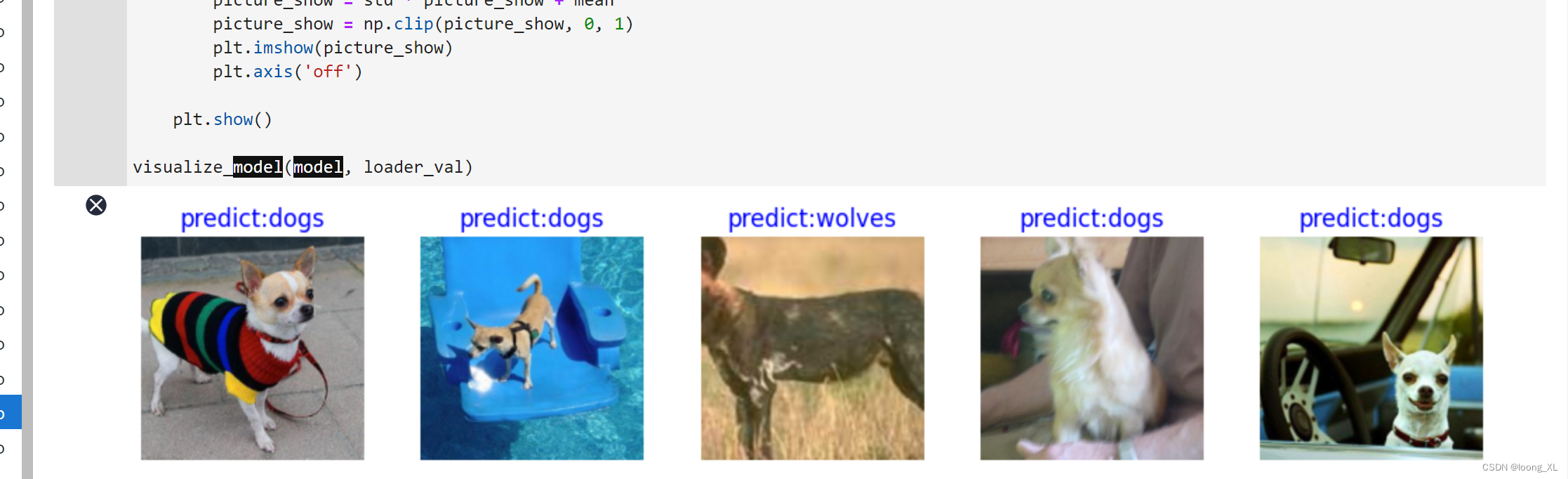
def visualize_model(model, val_dl, num_classes=2):
# 加载验证集的数据进行验证
images, labels= next(val_dl.create_tuple_iterator())
# 预测图像类别
output = model.predict(images)
pred = np.argmax(output.asnumpy(), axis=1)
# 显示图像及图像的预测值
images = images.asnumpy()
labels = labels.asnumpy()
class_name = {0: "dogs", 1: "wolves"}
plt.figure(figsize=(15, 7))
for i in range(len(labels)):
plt.subplot(3, 6, i + 1)
# 若预测正确,显示为蓝色;若预测错误,显示为红色
color = 'blue' if pred[i] == labels[i] else 'red'
plt.title('predict:{}'.format(class_name[pred[i]]), color=color)
picture_show = np.transpose(images[i], (1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
picture_show = std * picture_show + mean
picture_show = np.clip(picture_show, 0, 1)
plt.imshow(picture_show)
plt.axis('off')
plt.show()
visualize_model(model, loader_val)
2、模型保存与加载
## 保存模型
import mindspore as ms
from mindcv.models import create_model
network = create_model(model_name='densenet121', num_classes=2, pretrained=True)
ms.save_checkpoint(network, "model1.ckpt")
## 加载模型
from mindspore import load_checkpoint, load_param_into_net
from mindspore import Model
param_dict = load_checkpoint("model1.ckpt")
param_not_load = load_param_into_net(network, param_dict)
print(param_not_load)
model1 = Model(network, loss, metrics={"accuracy"})






![[C语言基础]文件读取模式简析](https://img-blog.csdnimg.cn/b9c66b7e0f1847ee8373981643533343.png)