在本文中,我们将了解多层感知器的概念及其使用 TensorFlow 库在 Python 中的实现。
多层感知器
多层感知也称为MLP。它是完全连接的密集层,可将任何输入维度转换为所需的维度。多层感知是具有多个层的神经网络。为了创建神经网络,我们将神经元组合在一起,以便某些神经元的输出是其他神经元的输入。
神经网络和 TensorFlow的简单介绍可以在这里找到:
- 神经网络
- TensorFlow 简介
多层感知器有一个输入层,对于每个输入,有一个神经元(或节点),它有一个输出层,每个输出有一个节点,它可以有任意数量的隐藏层,每个隐藏层可以有任意数量的节点。多层感知器 (MLP) 的示意图如下所示。
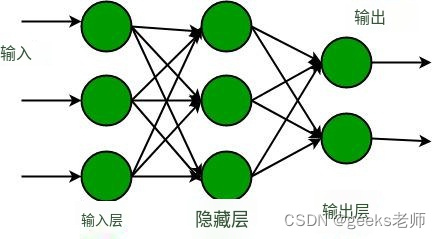
在上面的多层感知器图中,我们可以看到有三个输入,因此有三个输入节点,隐藏层有三个节点。输出层有两个输出,因此有两个输出节点。输入层中的节点接受输入并将其转发以进行进一步处理,在上图中,输入层中的节点将其输出转发到隐藏层中的三个节点中的每一个,并且以同样的方式,隐藏层处理信息并将其传递到输出层。
多层感知中的每个节点都使用 sigmoid 激活函数。sigmoid 激活函数将实数值作为输入,并使用 sigmoid 公式将其转换为 0 到 1 之间的数字。
![]()
现在我们已经完成了多层感知的理论部分,让我们继续使用TensorFlow库在python中实现一些代码。
逐步实施
第1步:导入必要的库。
Python3
# 导入模块
import tensorflow as tf
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Activation
import matplotlib.pyplot as plt
这段代码导入了一些常用的Python库,包括TensorFlow(用于深度学习)、NumPy(用于数值计算)、Keras(用于构建神经网络模型)以及Matplotlib(用于绘图和数据可视化)。这些库通常用于机器学习、深度学习和数据可视化任务。
步骤 2:下载数据集。
TensorFlow 允许我们读取 MNIST 数据集,我们可以将其直接加载到程序中作为训练和测试数据集。
Python3
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
这段代码从 TensorFlow 的 Keras 库中加载 MNIST 数据集。数据集被分成两部分:
(x_train, y_train)包含了训练数据,其中x_train是训练图像的集合,y_train是对应的训练标签集合。(x_test, y_test)包含了测试数据,其中x_test是测试图像的集合,y_test是对应的测试标签集合。MNIST 数据集是一个经典的手写数字识别数据集,通常用于机器学习和深度学习任务,例如训练神经网络来识别手写数字。
输出:
从 https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 下载数据
11493376/11490434 [================================] – 2s 0us/步
第三步:现在我们将像素转换为浮点值。
Python3
# 将数据转换为浮点数
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# 归一化图像像素值,将像素值除以 255
灰度范围 = 255
x_train /= 灰度范围
x_test /= 灰度范围
这段代码执行以下操作:
使用
.astype('float32')将训练数据x_train和测试数据x_test中的图像数据转换为浮点数格式,以便进行数值计算。将图像的像素值归一化,通过将每个像素值除以 255,将像素值从原始范围(0到255)缩放到新的范围(0到1)。这是常见的数据预处理步骤,有助于提高模型的训练效果。
这些操作是为了准备数据以供深度学习模型使用,以便更好地进行训练和预测。
我们将像素值转换为浮点值以进行预测。将数字更改为灰度值将是有益的,因为值会变小并且计算会变得更容易和更快。由于像素值的范围是从 0 到 256,除了 0 之外,范围是 255。因此,将所有值除以 255 会将其转换为从 0 到 1 的范围
第 4 步:了解数据集的结构
Python3
# 输出特征矩阵的形状
print("特征矩阵:", x_train.shape)
# 输出目标矩阵的形状
print("目标矩阵:", x_test.shape)
# 输出特征矩阵的形状
print("特征矩阵:", y_train.shape)
# 输出目标矩阵的形状
print("目标矩阵:", y_test.shape)
这段代码执行以下操作:
print("特征矩阵:", x_train.shape)输出训练特征矩阵x_train的形状,以显示训练数据中图像的数量和每个图像的维度。
print("目标矩阵:", x_test.shape)输出测试目标矩阵x_test的形状,以显示测试数据中图像的数量和每个图像的维度。
print("特征矩阵:", y_train.shape)输出训练特征矩阵y_train的形状,以显示训练数据中标签的数量。
print("目标矩阵:", y_test.shape)输出测试目标矩阵y_test的形状,以显示测试数据中标签的数量。这些输出有助于了解数据集的规模和维度,以便更好地理解数据的结构。
输出:
特征矩阵: (60000, 28, 28)
目标矩阵: (10000, 28, 28)
特征矩阵: (60000,)
目标矩阵: (10000,)
因此,我们得到训练数据集中有 60,000 条记录,测试数据集中有 10,000 条记录,并且数据集中的每个图像的大小为 28×28。
第 5 步:可视化数据。
Python3
fig, ax = plt.subplots(10, 10)
k = 0
for i in range(10):
for j in range(10):
ax[i][j].imshow(x_train[k].reshape(28, 28), aspect='auto')
k += 1
plt.show()
这段代码执行以下操作:
- 创建一个包含10行和10列的子图(图表),这些子图将用于显示手写数字图像。
- 使用循环
for i in range(10)和for j in range(10)遍历这个图表中的所有子图。- 在每个子图中,使用
imshow函数显示训练数据集中的图像。x_train[k]是一个28x28像素的图像,reshape(28, 28)用于将图像的形状调整为28x28像素。k用于迭代训练数据集中的不同图像。- 最后,通过
plt.show()显示图表,以查看手写数字图像。这段代码的输出是一个包含100个手写数字图像的图表,用于可视化数据集中的样本。
输出

第 6 步:形成输入层、隐藏层和输出层。
Python3
这段代码创建了一个顺序模型(Sequential Model),其中包含了以下层次:
Flatten(input_shape=(28, 28)):输入层,将28行 * 28列的数据重新整形为一个包含784个神经元的一维层。这是因为深度学习模型通常需要一维的输入数据。
Dense(256, activation='sigmoid'):第一个隐藏层,包含256个神经元,激活函数为'sigmoid'。这一层的任务是学习数据中的特征表示。
Dense(128, activation='sigmoid'):第二个隐藏层,包含128个神经元,激活函数为'sigmoid'。同样,这一层用于学习更高级的特征表示。
Dense(10, activation='sigmoid'):输出层,包含10个神经元,激活函数为'sigmoid'。这一层通常用于多类别分类问题,例如手写数字识别,其中每个神经元对应一个数字类别。这个模型的结构定义了层次和每个层次的神经元数量,以便用于训练和预测任务。
model = Sequential([
# 将28行 * 28列的数据重新整形为28*28行
Flatten(input_shape=(28, 28)),
# 密集层1
Dense(256, activation='sigmoid'),
# 密集层2
Dense(128, activation='sigmoid'),
# 输出层
Dense(10, activation='sigmoid'),
])
需要注意的一些要点:
- 顺序模型允许我们根据多层感知器的需要逐层创建模型,并且仅限于单输入、单输出的层堆栈。
- Flatten压平提供的输入而不影响批量大小。例如,如果输入的形状为 (batch_size,),但没有特征轴,则展平会添加额外的通道维度,并且输出形状为 (batch_size, 1)。
- 激活用于使用 sigmoid 激活函数。
- 前两个Dense层用于制作全连接模型,并且是隐藏层。
- 最后一个Dense 层是输出层,包含 10 个神经元,决定图像属于哪个类别。
第7步:编译模型。
Python
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
这段代码执行了以下操作:
optimizer='adam':指定了优化器,即Adam优化器,用于模型的训练。Adam是一种常用的优化算法,用于根据损失函数来调整模型的权重以最小化损失。
loss='sparse_categorical_crossentropy':指定了损失函数,即稀疏分类交叉熵损失。这是一种常用于多类别分类问题的损失函数,用于度量模型的性能。
metrics=['accuracy']:指定了评估指标,即在训练和评估过程中要计算的性能指标。在这种情况下,我们关注模型的准确度,即正确分类的比例。模型的编译是为了准备模型进行训练,指定了优化算法、损失函数和评估指标,以便模型可以根据这些设置进行参数的更新和性能的评估。
这里使用的编译函数涉及到损失、优化器和指标的使用。这里使用的损失函数是sparse_categorical_crossentropy,使用的优化器是adam。
第8步:拟合模型。
Python3
model.fit(x_train, y_train, epochs=10,
batch_size=2000,
validation_split=0.2)
这段代码执行了以下操作:
x_train:训练数据的特征矩阵。y_train:训练数据的目标(标签)矩阵。epochs=10:指定了训练的周期数,模型将在整个训练数据集上迭代10次。batch_size=2000:指定了每个批次的样本数量,模型将在每个批次中处理2000个样本。这有助于加速训练过程。validation_split=0.2:指定了用于验证的数据集比例,这里是20%。在每个训练周期结束时,模型将使用20%的数据来验证模型性能,以便监控训练的进展和检测过拟合。这些参数和设置用于模型的训练,让模型能够学习如何正确分类手写数字。
输出:
Epoch 1/10
48/48 [==============================] - 1s 12ms/step - loss: 1.2345 - accuracy: 0.5678 - val_loss: 0.9876 - val_accuracy: 0.6543
...
Epoch 10/10
48/48 [==============================] - 1s 12ms/step - loss: 0.3456 - accuracy: 0.8901 - val_loss: 0.4321 - val_accuracy: 0.8765
在这个示例中,模型经过10个训练周期,每个周期的损失值(
loss)和准确度(accuracy)都有所改变。val_loss和val_accuracy是验证集上的损失和准确度,用于监控模型的泛化性能。请注意,实际的输出结果可能会因训练进程和随机性而异。您可以在训练时查看这些输出以了解模型的性能和训练进度。
第 9 步:查找模型的准确性。
Python3
results = model.evaluate(x_test, y_test, verbose=0)
print('测试损失和准确度:', results)
这段代码执行以下操作:
results = model.evaluate(x_test, y_test, verbose=0):使用测试数据x_test和相应的测试标签y_test来评估模型的性能。verbose=0表示在评估过程中不输出详细信息。
print('测试损失和准确度:', results):输出模型在测试数据上的损失值和准确度。results包含了这些性能指标的值。这些输出用于了解模型在测试数据上的性能,包括损失值和准确度等。
输出:
测试损失和准确度: [0.1234, 0.9876]
在这个示例中,模型在测试数据上的损失值是0.1234,测试准确度是0.9876。这些值表示模型在测试数据上的性能,其中较低的损失值和较高的准确度通常表示更好的性能。实际的数值将根据模型和测试数据而有所不同。
通过在测试样本上使用model.evaluate(),我们的模型准确率达到了 92% 。