之前用pytorch构建了squeezenet,个人觉得pytorch是最好用的,但是有的工程就是需要caffe结构的,所以本篇也用caffe构建一个squeezenet网络。
数据处理
首先要对数据进行处理,跟pytorch不同,pytorch读取数据只需要给数据集所在目录即可直接从中读取数据,而caffe需要一个包含每张图片的绝对路径以及所在类别的txt文件,从中读取数据。写一个生成次txt文件的脚本:
import os
import random
folder = 'cotta' # 数据集目录相对路径
names = os.listdir(folder)
f1 = open('/train_txt/train_cotta.txt', 'a') # 生成的txt地址
f2 = open('/train_txt/test_water_workcloth.txt', 'a')
for name in names:
imgnames = os.listdir(folder + '/' + name)
random.shuffle(imgnames)
numimg = len(imgnames)
for i in range(numimg):
f1.write('%s %s\n' % (folder + '/' + name + '/' + imgnames[i], name[0]))
# if i < int(0.9*numimg):
# f1.write('%s %s\n'%(folder + '/' + name + '/' + imgnames[i], name[0]))
# else:
# f2.write('%s %s\n'%(folder + '/' + name + '/' + imgnames[i], name[0]))
# f2.close()
f1.close()
数据集的目录也要跟pytorch的一致,一个类的数据放在一个目录中,目录名为类名。且脚本与该目录同级。
运行脚本后生成的txt内容如下:
/cotta/0_other/0_1_391_572_68_68.jpg 0
/cotta/1_longSleeves/9605_1_5_565_357_82_70.jpg 1
/cotta/2_cotta/713_0.99796_1_316_162_96_87.jpg 2
......
图片相对路径 图片所属类别
网络结构配置文件
trainval.prototxt
layer {
name: "data"
type: "ImageData"
top: "data"
top: "label"
transform_param {
mirror: true
crop_size: 96
}
image_data_param {
source: "/train_txt/train_cotta.txt" # 生成的txt的相对路径
root_folder: "/data/" # 存放数据集目录的路径
batch_size: 64
shuffle: true
new_height: 96
new_width: 96
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
convolution_param {
num_output: 96
kernel_size: 3
stride: 1
pad: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "BatchNorm1"
type: "BatchNorm"
bottom: "conv1"
top: "BatchNorm1"
}
layer {
name: "relu_conv1"
type: "ReLU"
bottom: "BatchNorm1"
top: "BatchNorm1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "BatchNorm1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "fire2/squeeze1x1"
type: "Convolution"
bottom: "pool1"
top: "fire2/squeeze1x1"
convolution_param {
num_output: 16
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire2/bn_squeeze1x1"
type: "BatchNorm"
bottom: "fire2/squeeze1x1"
top: "fire2/bn_squeeze1x1"
}
layer {
name: "fire2/relu_squeeze1x1"
type: "ReLU"
bottom: "fire2/bn_squeeze1x1"
top: "fire2/bn_squeeze1x1"
}
layer {
name: "fire2/expand1x1"
type: "Convolution"
bottom: "fire2/bn_squeeze1x1"
top: "fire2/expand1x1"
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire2/bn_expand1x1"
type: "BatchNorm"
bottom: "fire2/expand1x1"
top: "fire2/bn_expand1x1"
}
layer {
name: "fire2/relu_expand1x1"
type: "ReLU"
bottom: "fire2/bn_expand1x1"
top: "fire2/bn_expand1x1"
}
layer {
name: "fire2/expand3x3"
type: "Convolution"
bottom: "fire2/bn_expand1x1"
top: "fire2/expand3x3"
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire2/bn_expand3x3"
type: "BatchNorm"
bottom: "fire2/expand3x3"
top: "fire2/bn_expand3x3"
}
layer {
name: "fire2/relu_expand3x3"
type: "ReLU"
bottom: "fire2/bn_expand3x3"
top: "fire2/bn_expand3x3"
}
layer {
name: "fire2/concat"
type: "Concat"
bottom: "fire2/bn_expand1x1"
bottom: "fire2/bn_expand3x3"
top: "fire2/concat"
}
#fire2 ends: 128 channels
layer {
name: "fire3/squeeze1x1"
type: "Convolution"
bottom: "fire2/concat"
top: "fire3/squeeze1x1"
convolution_param {
num_output: 16
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire3/bn_squeeze1x1"
type: "BatchNorm"
bottom: "fire3/squeeze1x1"
top: "fire3/bn_squeeze1x1"
}
layer {
name: "fire3/relu_squeeze1x1"
type: "ReLU"
bottom: "fire3/bn_squeeze1x1"
top: "fire3/bn_squeeze1x1"
}
layer {
name: "fire3/expand1x1"
type: "Convolution"
bottom: "fire3/bn_squeeze1x1"
top: "fire3/expand1x1"
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire3/bn_expand1x1"
type: "BatchNorm"
bottom: "fire3/expand1x1"
top: "fire3/bn_expand1x1"
}
layer {
name: "fire3/relu_expand1x1"
type: "ReLU"
bottom: "fire3/bn_expand1x1"
top: "fire3/bn_expand1x1"
}
layer {
name: "fire3/expand3x3"
type: "Convolution"
bottom: "fire3/bn_expand1x1"
top: "fire3/expand3x3"
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire3/bn_expand3x3"
type: "BatchNorm"
bottom: "fire3/expand3x3"
top: "fire3/bn_expand3x3"
}
layer {
name: "fire3/relu_expand3x3"
type: "ReLU"
bottom: "fire3/bn_expand3x3"
top: "fire3/bn_expand3x3"
}
layer {
name: "fire3/concat"
type: "Concat"
bottom: "fire3/bn_expand1x1"
bottom: "fire3/bn_expand3x3"
top: "fire3/concat"
}
#fire3 ends: 128 channels
layer {
name: "bypass_23"
type: "Eltwise"
bottom: "fire2/concat"
bottom: "fire3/concat"
top: "fire3_EltAdd"
}
layer {
name: "fire4/squeeze1x1"
type: "Convolution"
bottom: "fire3_EltAdd"
top: "fire4/squeeze1x1"
convolution_param {
num_output: 32
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire4/bn_squeeze1x1"
type: "BatchNorm"
bottom: "fire4/squeeze1x1"
top: "fire4/bn_squeeze1x1"
}
layer {
name: "fire4/relu_squeeze1x1"
type: "ReLU"
bottom: "fire4/bn_squeeze1x1"
top: "fire4/bn_squeeze1x1"
}
layer {
name: "fire4/expand1x1"
type: "Convolution"
bottom: "fire4/bn_squeeze1x1"
top: "fire4/expand1x1"
convolution_param {
num_output: 128
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire4/bn_expand1x1"
type: "BatchNorm"
bottom: "fire4/expand1x1"
top: "fire4/bn_expand1x1"
}
layer {
name: "fire4/relu_expand1x1"
type: "ReLU"
bottom: "fire4/bn_expand1x1"
top: "fire4/bn_expand1x1"
}
layer {
name: "fire4/expand3x3"
type: "Convolution"
bottom: "fire4/bn_expand1x1"
top: "fire4/expand3x3"
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire4/bn_expand3x3"
type: "BatchNorm"
bottom: "fire4/expand3x3"
top: "fire4/bn_expand3x3"
}
layer {
name: "fire4/relu_expand3x3"
type: "ReLU"
bottom: "fire4/bn_expand3x3"
top: "fire4/bn_expand3x3"
}
layer {
name: "fire4/concat"
type: "Concat"
bottom: "fire4/bn_expand1x1"
bottom: "fire4/bn_expand3x3"
top: "fire4/concat"
}
#fire4 ends: 256 channels
layer {
name: "pool4"
type: "Pooling"
bottom: "fire4/concat"
top: "pool4"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
#fire4 ends: 256 channels / pooled
layer {
name: "fire5/squeeze1x1"
type: "Convolution"
bottom: "pool4"
top: "fire5/squeeze1x1"
convolution_param {
num_output: 32
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire5/bn_squeeze1x1"
type: "BatchNorm"
bottom: "fire5/squeeze1x1"
top: "fire5/bn_squeeze1x1"
}
layer {
name: "fire5/relu_squeeze1x1"
type: "ReLU"
bottom: "fire5/bn_squeeze1x1"
top: "fire5/bn_squeeze1x1"
}
layer {
name: "fire5/expand1x1"
type: "Convolution"
bottom: "fire5/bn_squeeze1x1"
top: "fire5/expand1x1"
convolution_param {
num_output: 128
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire5/bn_expand1x1"
type: "BatchNorm"
bottom: "fire5/expand1x1"
top: "fire5/bn_expand1x1"
}
layer {
name: "fire5/relu_expand1x1"
type: "ReLU"
bottom: "fire5/bn_expand1x1"
top: "fire5/bn_expand1x1"
}
layer {
name: "fire5/expand3x3"
type: "Convolution"
bottom: "fire5/bn_expand1x1"
top: "fire5/expand3x3"
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire5/bn_expand3x3"
type: "BatchNorm"
bottom: "fire5/expand3x3"
top: "fire5/bn_expand3x3"
}
layer {
name: "fire5/relu_expand3x3"
type: "ReLU"
bottom: "fire5/bn_expand3x3"
top: "fire5/bn_expand3x3"
}
layer {
name: "fire5/concat"
type: "Concat"
bottom: "fire5/bn_expand1x1"
bottom: "fire5/bn_expand3x3"
top: "fire5/concat"
}
#fire5 ends: 256 channels
layer {
name: "bypass_45"
type: "Eltwise"
bottom: "pool4"
bottom: "fire5/concat"
top: "fire5_EltAdd"
}
layer {
name: "fire6/squeeze1x1"
type: "Convolution"
bottom: "fire5_EltAdd"
top: "fire6/squeeze1x1"
convolution_param {
num_output: 48
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire6/bn_squeeze1x1"
type: "BatchNorm"
bottom: "fire6/squeeze1x1"
top: "fire6/bn_squeeze1x1"
}
layer {
name: "fire6/relu_squeeze1x1"
type: "ReLU"
bottom: "fire6/bn_squeeze1x1"
top: "fire6/bn_squeeze1x1"
}
layer {
name: "fire6/expand1x1"
type: "Convolution"
bottom: "fire6/bn_squeeze1x1"
top: "fire6/expand1x1"
convolution_param {
num_output: 192
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire6/bn_expand1x1"
type: "BatchNorm"
bottom: "fire6/expand1x1"
top: "fire6/bn_expand1x1"
}
layer {
name: "fire6/relu_expand1x1"
type: "ReLU"
bottom: "fire6/bn_expand1x1"
top: "fire6/bn_expand1x1"
}
layer {
name: "fire6/expand3x3"
type: "Convolution"
bottom: "fire6/bn_expand1x1"
top: "fire6/expand3x3"
convolution_param {
num_output: 192
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire6/bn_expand3x3"
type: "BatchNorm"
bottom: "fire6/expand3x3"
top: "fire6/bn_expand3x3"
}
layer {
name: "fire6/relu_expand3x3"
type: "ReLU"
bottom: "fire6/bn_expand3x3"
top: "fire6/bn_expand3x3"
}
layer {
name: "fire6/concat"
type: "Concat"
bottom: "fire6/bn_expand1x1"
bottom: "fire6/bn_expand3x3"
top: "fire6/concat"
}
#fire6 ends: 384 channels
layer {
name: "fire7/squeeze1x1"
type: "Convolution"
bottom: "fire6/concat"
top: "fire7/squeeze1x1"
convolution_param {
num_output: 48
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire7/bn_squeeze1x1"
type: "BatchNorm"
bottom: "fire7/squeeze1x1"
top: "fire7/bn_squeeze1x1"
}
layer {
name: "fire7/relu_squeeze1x1"
type: "ReLU"
bottom: "fire7/bn_squeeze1x1"
top: "fire7/bn_squeeze1x1"
}
layer {
name: "fire7/expand1x1"
type: "Convolution"
bottom: "fire7/bn_squeeze1x1"
top: "fire7/expand1x1"
convolution_param {
num_output: 192
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire7/bn_expand1x1"
type: "BatchNorm"
bottom: "fire7/expand1x1"
top: "fire7/bn_expand1x1"
}
layer {
name: "fire7/relu_expand1x1"
type: "ReLU"
bottom: "fire7/bn_expand1x1"
top: "fire7/bn_expand1x1"
}
layer {
name: "fire7/expand3x3"
type: "Convolution"
bottom: "fire7/bn_expand1x1"
top: "fire7/expand3x3"
convolution_param {
num_output: 192
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire7/bn_expand3x3"
type: "BatchNorm"
bottom: "fire7/expand3x3"
top: "fire7/bn_expand3x3"
}
layer {
name: "fire7/relu_expand3x3"
type: "ReLU"
bottom: "fire7/bn_expand3x3"
top: "fire7/bn_expand3x3"
}
layer {
name: "fire7/concat"
type: "Concat"
bottom: "fire7/bn_expand1x1"
bottom: "fire7/bn_expand3x3"
top: "fire7/concat"
}
#fire7 ends: 384 channels
layer {
name: "bypass_67"
type: "Eltwise"
bottom: "fire6/concat"
bottom: "fire7/concat"
top: "fire7_EltAdd"
}
layer {
name: "fire8/squeeze1x1"
type: "Convolution"
bottom: "fire7_EltAdd"
top: "fire8/squeeze1x1"
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire8/bn_squeeze1x1"
type: "BatchNorm"
bottom: "fire8/squeeze1x1"
top: "fire8/bn_squeeze1x1"
}
layer {
name: "fire8/relu_squeeze1x1"
type: "ReLU"
bottom: "fire8/bn_squeeze1x1"
top: "fire8/bn_squeeze1x1"
}
layer {
name: "fire8/expand1x1"
type: "Convolution"
bottom: "fire8/bn_squeeze1x1"
top: "fire8/expand1x1"
convolution_param {
num_output: 256
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire8/bn_expand1x1"
type: "BatchNorm"
bottom: "fire8/expand1x1"
top: "fire8/bn_expand1x1"
}
layer {
name: "fire8/relu_expand1x1"
type: "ReLU"
bottom: "fire8/bn_expand1x1"
top: "fire8/bn_expand1x1"
}
layer {
name: "fire8/expand3x3"
type: "Convolution"
bottom: "fire8/bn_expand1x1"
top: "fire8/expand3x3"
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire8/bn_expand3x3"
type: "BatchNorm"
bottom: "fire8/expand3x3"
top: "fire8/bn_expand3x3"
}
layer {
name: "fire8/relu_expand3x3"
type: "ReLU"
bottom: "fire8/bn_expand3x3"
top: "fire8/bn_expand3x3"
}
layer {
name: "fire8/concat"
type: "Concat"
bottom: "fire8/bn_expand1x1"
bottom: "fire8/bn_expand3x3"
top: "fire8/concat"
}
#fire8 ends: 512 channels
layer {
name: "pool8"
type: "Pooling"
bottom: "fire8/concat"
top: "pool8"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
#fire8 ends: 512 channels
layer {
name: "fire9/squeeze1x1"
type: "Convolution"
bottom: "pool8"
top: "fire9/squeeze1x1"
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire9/bn_squeeze1x1"
type: "BatchNorm"
bottom: "fire9/squeeze1x1"
top: "fire9/bn_squeeze1x1"
}
layer {
name: "fire9/relu_squeeze1x1"
type: "ReLU"
bottom: "fire9/bn_squeeze1x1"
top: "fire9/bn_squeeze1x1"
}
layer {
name: "fire9/expand1x1"
type: "Convolution"
bottom: "fire9/bn_squeeze1x1"
top: "fire9/expand1x1"
convolution_param {
num_output: 256
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire9/bn_expand1x1"
type: "BatchNorm"
bottom: "fire9/expand1x1"
top: "fire9/bn_expand1x1"
}
layer {
name: "fire9/relu_expand1x1"
type: "ReLU"
bottom: "fire9/bn_expand1x1"
top: "fire9/bn_expand1x1"
}
layer {
name: "fire9/expand3x3"
type: "Convolution"
bottom: "fire9/bn_expand1x1"
top: "fire9/expand3x3"
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire9/bn_expand3x3"
type: "BatchNorm"
bottom: "fire9/expand3x3"
top: "fire9/bn_expand3x3"
}
layer {
name: "fire9/relu_expand3x3"
type: "ReLU"
bottom: "fire9/bn_expand3x3"
top: "fire9/bn_expand3x3"
}
layer {
name: "fire9/concat"
type: "Concat"
bottom: "fire9/bn_expand1x1"
bottom: "fire9/bn_expand3x3"
top: "fire9/concat"
}
#fire9 ends: 512 channels
layer {
name: "conv10_new"
type: "Convolution"
bottom: "fire9/concat"
top: "conv10"
convolution_param {
num_output: 3
kernel_size: 1
weight_filler {
type: "gaussian"
mean: 0.0
std: 0.01
}
}
}
layer {
name: "pool10"
type: "Pooling"
bottom: "conv10"
top: "pool10"
pooling_param {
pool: AVE
global_pooling: true
}
}
# loss, top1, top5
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "pool10"
bottom: "label"
top: "loss"
include {
# phase: TRAIN
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "pool10"
bottom: "label"
top: "accuracy"
#include {
# phase: TEST
#}
}
在最后一层卷积层conv10中的num_output修改类别数量。
模型超参配置文件
solver.prototxt
test_iter: 2000 #not subject to iter_size
test_interval: 1000000
# base_lr: 0.0001
base_lr: 0.005 # 学习率
display: 40
# max_iter: 600000
max_iter: 200000 # 迭代数
iter_size: 2 #global batch size = batch_size * iter_size
lr_policy: "poly"
power: 1.0 #linearly decrease LR
momentum: 0.9
weight_decay: 0.0002
snapshot: 10000 # 每多少次迭代保存一个模型
snapshot_prefix: "/data/zxc/classfication/model/model_cotta/cotta_" # 模型保存路径
solver_mode: GPU
random_seed: 42
net: "./trainNets_drive/trainval.prototxt" # 网络结构配置文件的路径
test_initialization: false
average_loss: 40
- max_iter:caffe用的是迭代数而不是pytorch的轮数。pytorch中训练完全部的训练集为一轮,而caffe中训练完一个batch_size的数据为一个迭代。如果想要等价与轮数的话,一轮就等于:len(train_data) / batch_size。如果有余数就要看pytorch里的dataloader里面设置舍去还是为一个batch,如果舍去就是向下取整,如果不舍去就是向上取整;
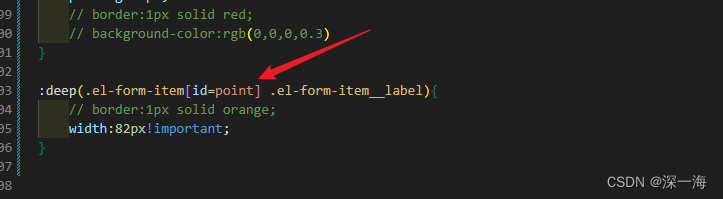
- snapshot_prefix:最后一部分为每个保存模型的前缀,如图:

运行命令
将运行命令写入bash文件中:
train.sh
/home/seg/anaconda3/envs/zxc/bin/caffe train -gpu 1 -solver ./solvers/solver_3.prototxt -weights=/data/classfication/model/model_cotta/cotta__iter_200000.caffemodel 2>&1 | tee log_3_4_class.txt
- -gpu:选择哪块卡,如果就一块就是0;
- -solver:后面跟网络超参配置文件路径;
- -weights:后面跟预训练模型,可以用官方给的squeezenet的caffe版本的预训练模型,我这里是训练中断从断点继续训练
编写完成后source activate 环境名称进入source环境,然后source train.sh运行bash文件就能开始训练。