【Linux基础IO篇】用户缓冲区、文件系统、以及软硬链接
目录
- 【Linux基础IO篇】用户缓冲区、文件系统、以及软硬链接
- 深入理解用户缓冲区
- 缓冲区刷新问题
- 缓冲区存在的意义
- File
- 模拟实现C语言中文件标准库
- 文件系统
- 认识磁盘
- 对目录的理解
- 软硬链接
- 软硬链接的删除
- 文件的三个时间
作者:爱写代码的刚子
时间:2023.11.5
前言:本篇博客将介绍缓冲区、磁盘的构成、分区,以及文件系统中的结构、软硬链接
深入理解用户缓冲区
观察几个现象:
正常现象一:
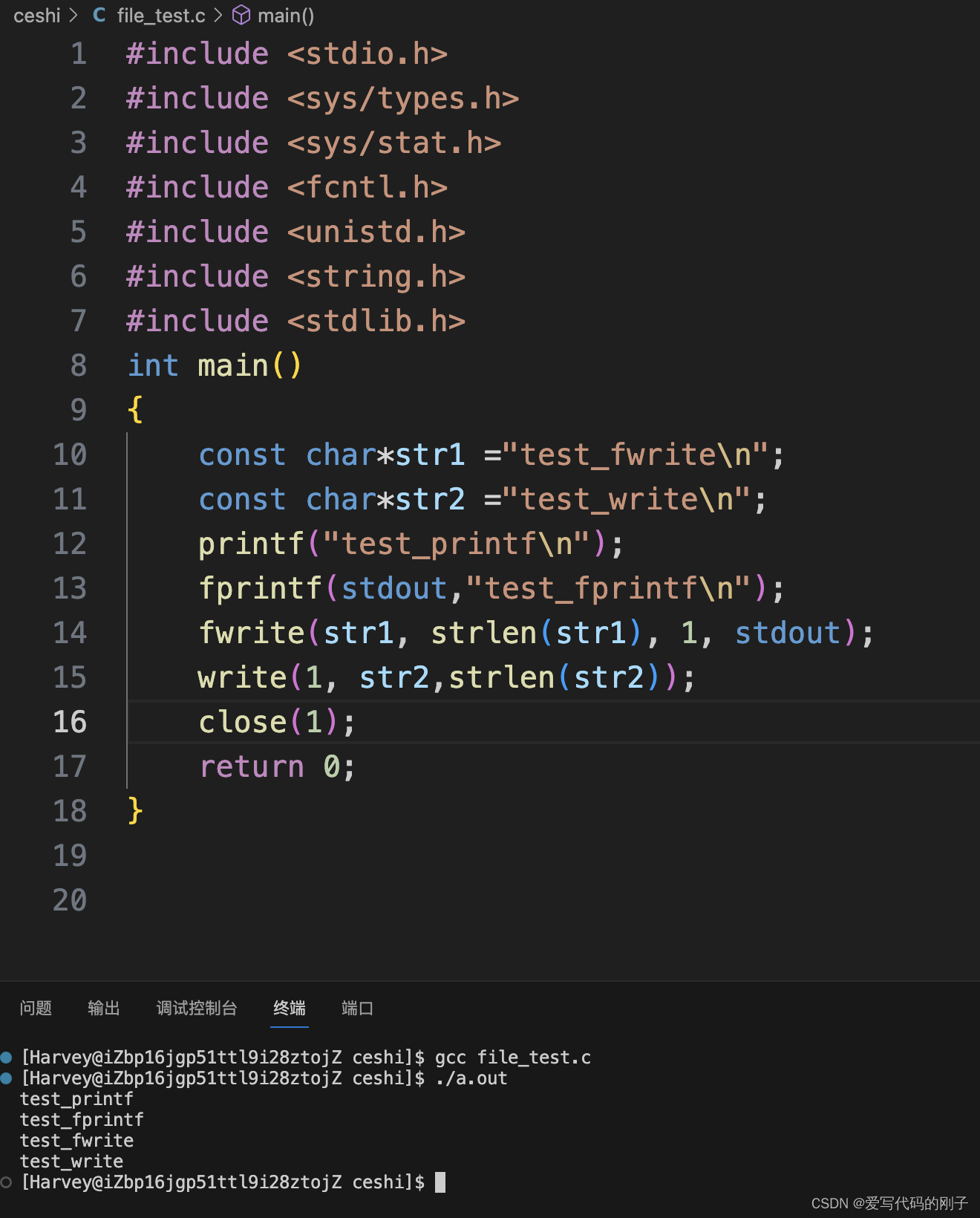
现象二:
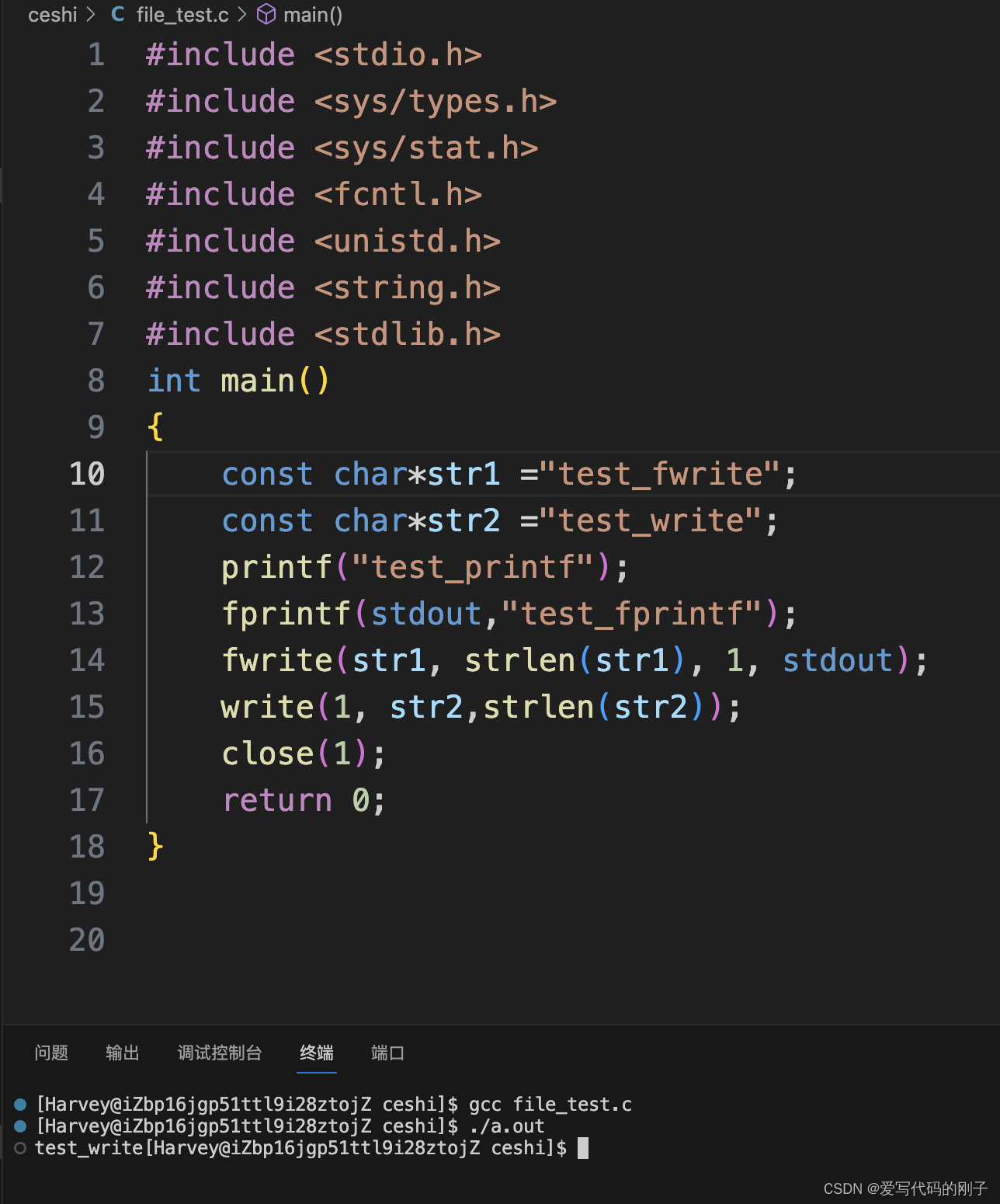
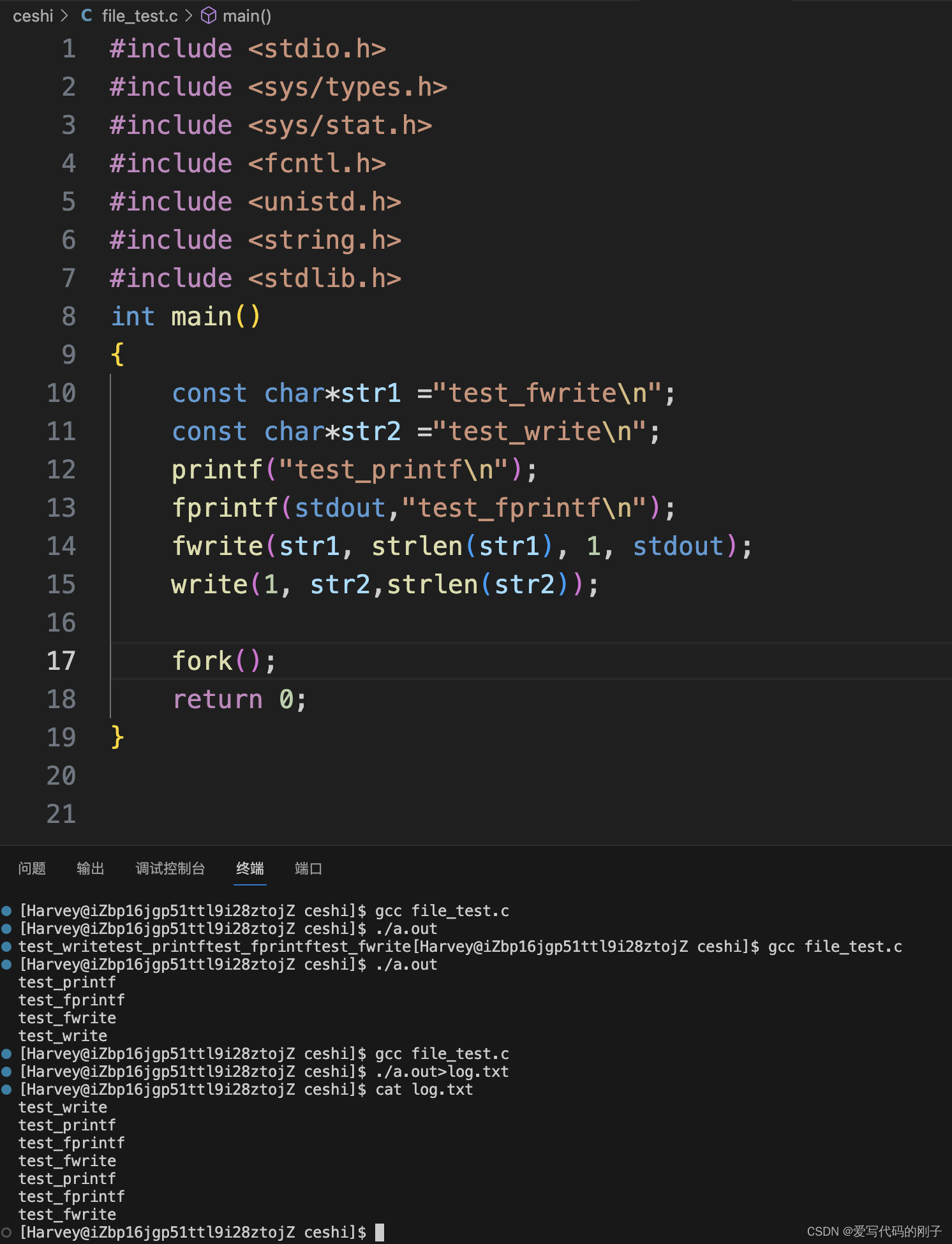
现象三:
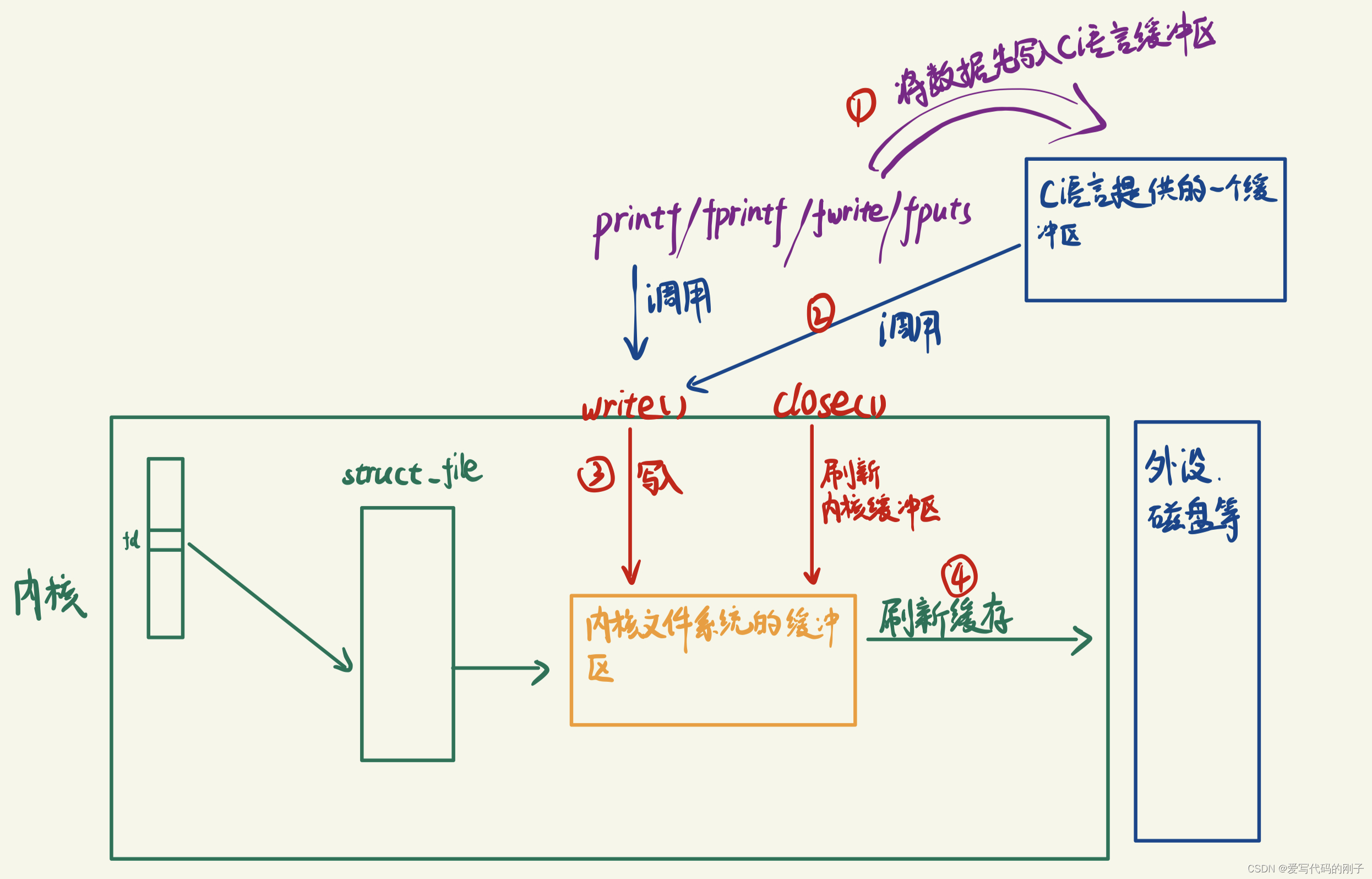
图示:
解释现象:
-
对于现象二:C语言文件操作函数中的字符串不带有’\n’,即数据还停留在C语言的缓冲区中,并未刷新和调用write()函数,将数据刷新到内核系统文件的缓冲区中,而write()函数由于是系统调用函数,能正常执行,但是由于close()函数将显示器文件关闭了,即使进程结束也不能将数据从缓冲区刷新到显示器中。(如果将close函数屏蔽,将会将C语言缓冲区中的数据刷新到显示器)
-
对于现象三:(1)在程序未进行重定向之前,默认是将数据写入显示器中,当遇到’\n’时,将数据从C语言的缓冲区中刷新到内核文件系统的缓冲区,fork()并不影响原本程序的运行。(2)在程序进行重定向之后,数据从向显示器写入变为了向文件中写入,缓冲区从行缓冲变为了全缓冲,所以此时的’\n’并不起作用,所以数据依然存储在C语言的缓冲区中,fork()函数创建子进程时子进程会将父进程的C语言缓冲区进行拷贝,当父子进程结束后将缓冲区里面的内容全部刷新,输出到显示器中。
- 显示器的文件的刷新方案是行刷新,所以在printf执行完就会在遇到’\n’的时候会立即进行刷新,用户刷新的本质就是将数据通过1+write写入到内核中。(目前我们认为,只要将数据刷新到了内核,数据就可以到硬件了)。
缓冲区刷新问题
- 无缓冲 ——直接刷新
- 行缓冲——不刷新,碰到’\n’刷新(显示器)
- 全缓冲——缓冲区满了才刷新(普通文件的写入)
- 进程退出的时候也会刷新缓冲区
缓冲区存在的意义
- 解决效率问题
- 配合格式化(printf中需要将%d等符号进行替换)
File
FILE里面含有对应打开文件等缓冲区字段和维护信息,同时FILE对象属于用户,这个缓冲区属于用户级缓冲区(语言属于用户层)
模拟实现C语言中文件标准库
- Mystdio.h文件:
#ifndef __MYSTDIO_H__
#define __MYSTDIO_H__
//open头文件
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
//
#include <unistd.h>
//
#include <string.h>
#include <stdlib.h>
#define FILE_MODE 0666
#define SIZE 1024
#define FLUSH_NOW 1//0001
#define FLUSH_LINE 2//0010
#define FLUSH_ALL 4//0100
typedef struct IO_FILE{
int fileno;
int flag;
char inbuffer[SIZE];
int in_pos;
char outbuffer[SIZE];
int out_pos;//缓冲区的有效字符和无效字符分界
}_FILE;
_FILE* _fopen(const char* filename,const char* flag);
int _fwrite(_FILE *fp,const char*s,int len);
void _fclose(_FILE *fp);
#endif
- Mystdio.c文件:
#include "Mystdio.h"
_FILE* _fopen(const char* filename,const char* flag)
{
int f=0;
int fd=-1;
if(strcmp(flag,"w")==0)
{
f=O_CREAT|O_WRONLY|O_TRUNC;
fd= open(filename,f,FILE_MODE);
}
else if(strcmp(flag,"r")==0)
{
f=O_CREAT|O_RDONLY|O_TRUNC;
fd= open(filename,f,FILE_MODE);
}
else if(strcmp(flag,"a")==0)
{
f=O_APPEND;
fd= open(filename,f);
}
else
{
return NULL;
}
if(fd==-1) return NULL;
//创建文件结构对象
_FILE* fp=(_FILE*)malloc(sizeof(_FILE));
if(fp==NULL)return NULL;
fp->fileno = fd;
fp->flag= FLUSH_LINE;
fp->out_pos=0;
return fp;
}
int _fwrite(_FILE *fp,const char*s,int len)
{
memcpy(&fp->outbuffer[fp->out_pos],s,len);//这里省略了异常处理
fp->out_pos+=len;
if(fp->flag & FLUSH_NOW)
{
write(fp->fileno,fp->outbuffer,fp->out_pos);
fp->out_pos=0;
}
else if(fp->flag & FLUSH_LINE)
{
if(fp->outbuffer[fp->out_pos-1]=='\n')//'\n'可能出现在字符中间,这时候需要对字符串做裁剪
{
write(fp->fileno,fp->outbuffer,fp->out_pos);
fp->out_pos=0;
}
}
else if(fp->flag & FLUSH_ALL)
{
if(fp->out_pos==SIZE)
{
write(fp->fileno,fp->outbuffer,fp->out_pos);//全写出去
fp->out_pos=0;
}
}
return len;//成功写入的长度
}
void _fflush(_FILE *fp)
{
if(fp->out_pos>0)
{
write(fp->fileno,fp->outbuffer,fp->out_pos);
fp->out_pos=0;
}
}
void _fclose(_FILE *fp)
{
if(fp==NULL)return ;
_fflush(fp);
close(fp->fileno);
free(fp);
}
Main.c文件:
#include "Mystdio.h"
#define myfile "test.txt"
int main()
{
_FILE* fp=_fopen(myfile,"w");
if(fp==NULL)
{
return 1;
}
int cnt =10;
while(cnt--)
{
const char* msage = "hello Linux\n";
_fwrite(fp,msage,strlen(msage));
sleep(1);
}
//_fflush(fp)
return 0;
}
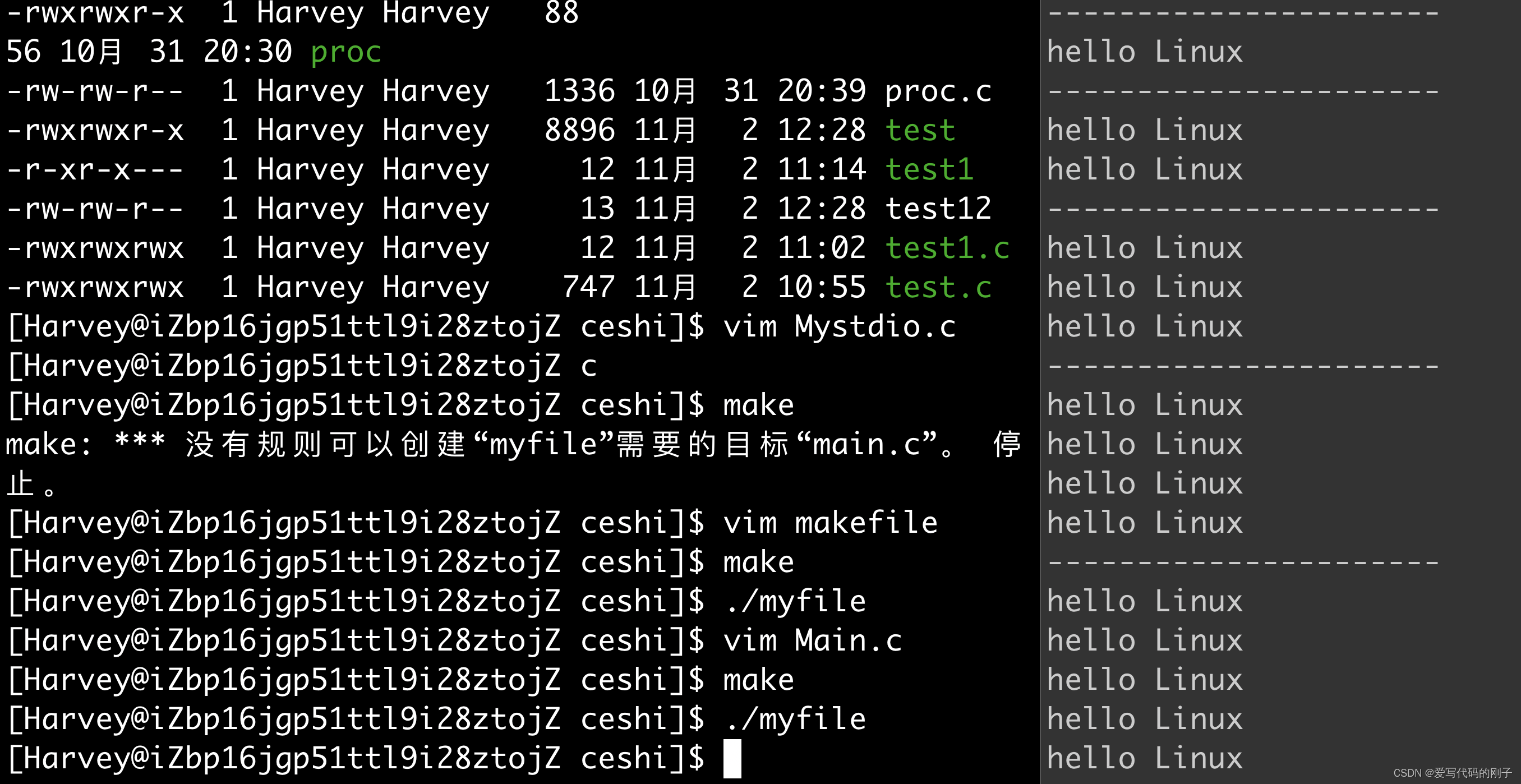
测试:
makefile文件:
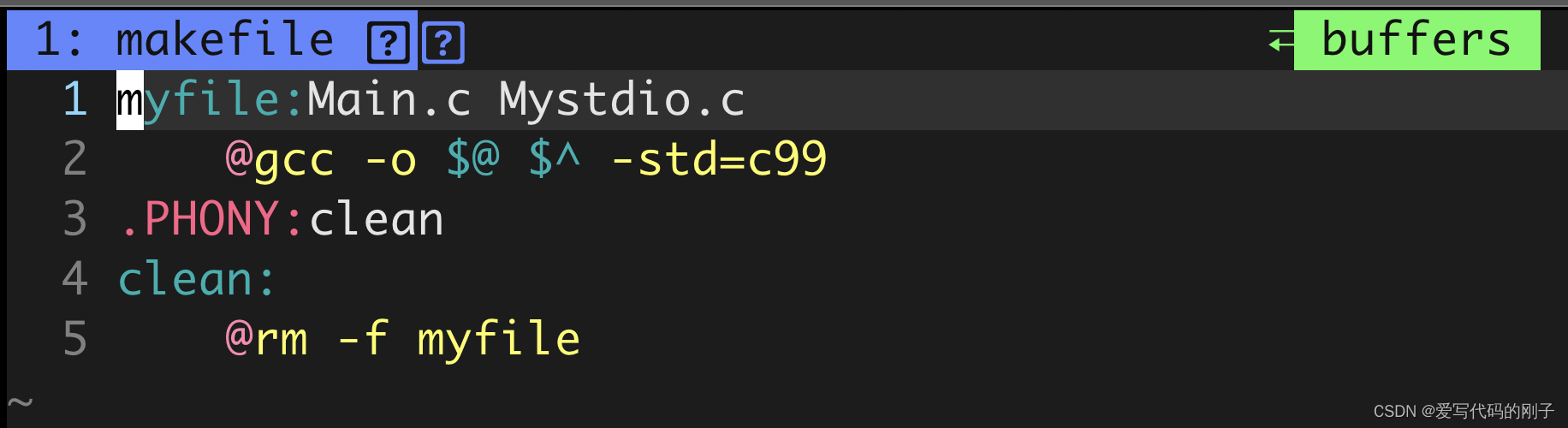
while :;do cat test.txt;sleep 1;echo “----------------------”;done持续打印文件内容
一般C库函数写入文件时是全缓冲的,而写入显示器是行缓冲。 printf fwrite 库函数会自带缓冲区(进度条例子就可以说明),当发生重定向到普通文件时,数据的缓冲方式由行缓冲变成了全缓冲。而我们放在缓冲区中的数据,就不会被立即刷新,甚至fork之后 但是进程退出之后,会统一刷新,写入文件当中。 但是fork的时候,父子数据会发生写时拷贝,所以当你父进程准备刷新的时候,子进程也就有了同样的 一份数据,随即产生两份数据。write没有变化,说明没有所谓的缓冲。
printf fwrite 库函数会自带缓冲区(用户级缓冲区),而 write系统调用没有带缓冲区。(为了提升整机性能,OS也会提供相关内核级缓冲区)
文件系统
认识磁盘
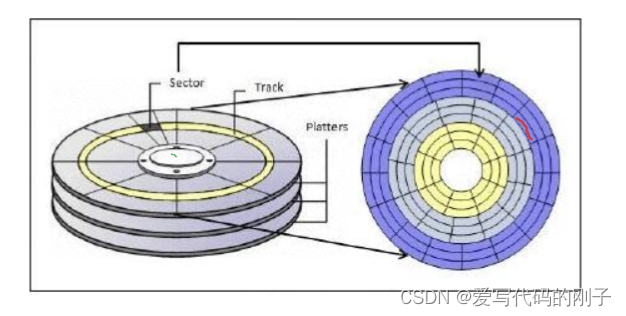
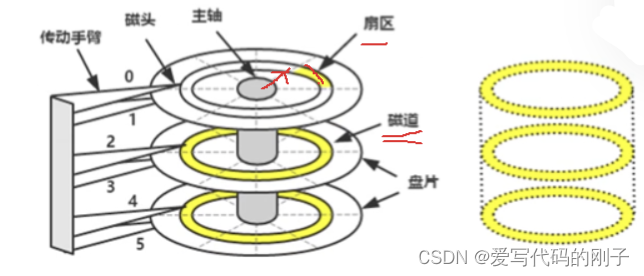
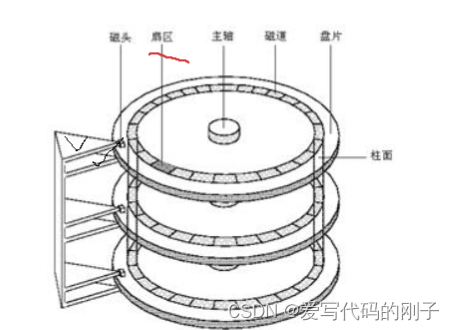

- 磁头是一面一个,磁头和盘面不接触,磁头臂会进行摆动来定位柱面或磁道(磁臂运动越少,效率越高,反之越低),所以在软件设计上一定要有意识将相关数据放在一起
磁盘的逻辑结构是线性的(对磁盘理解和建模)
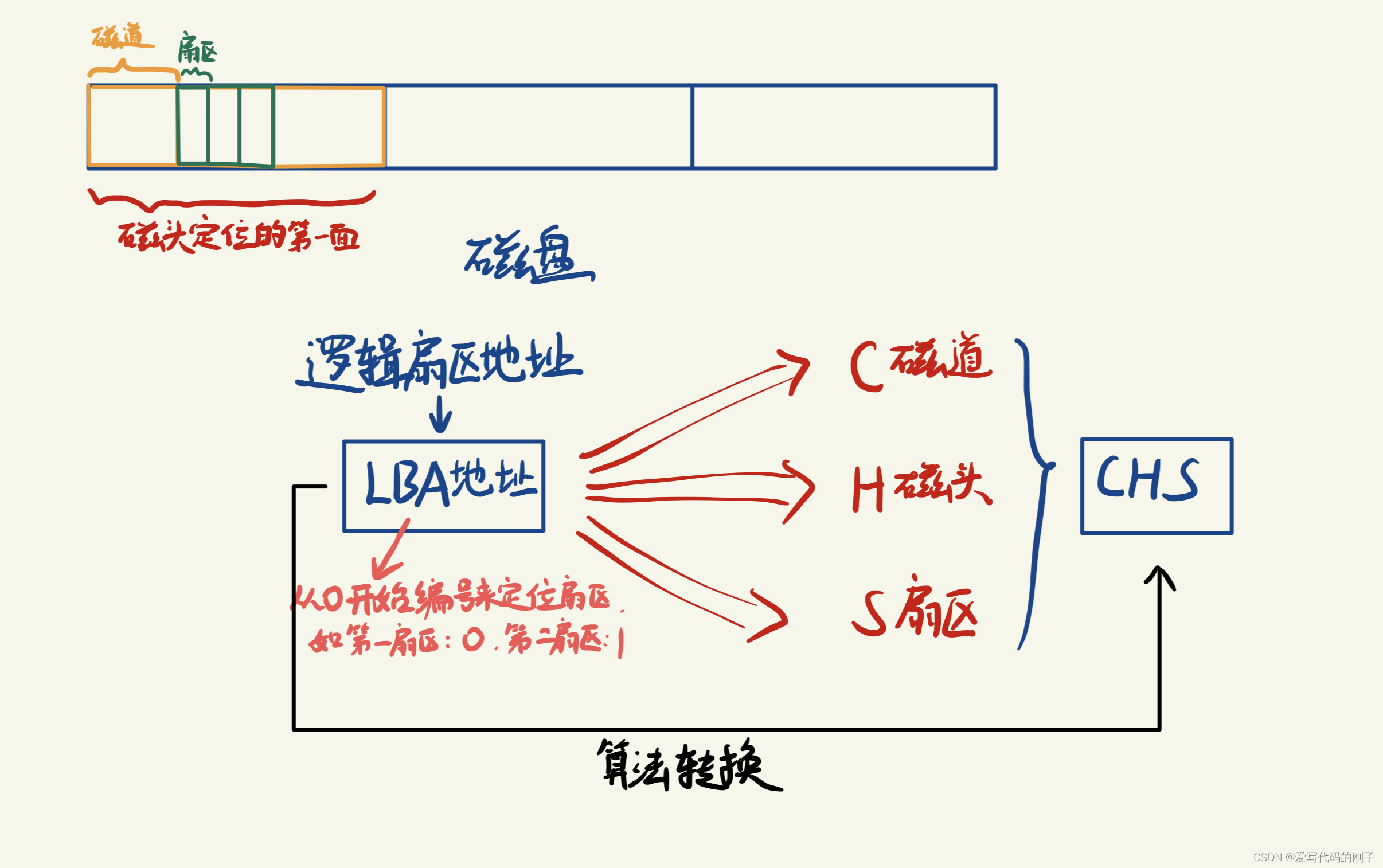
- 扇区的一般大小是512字节或者4kb
不仅CPU有寄存器,其他设备(外设)也存在寄存器

对磁盘进行分区
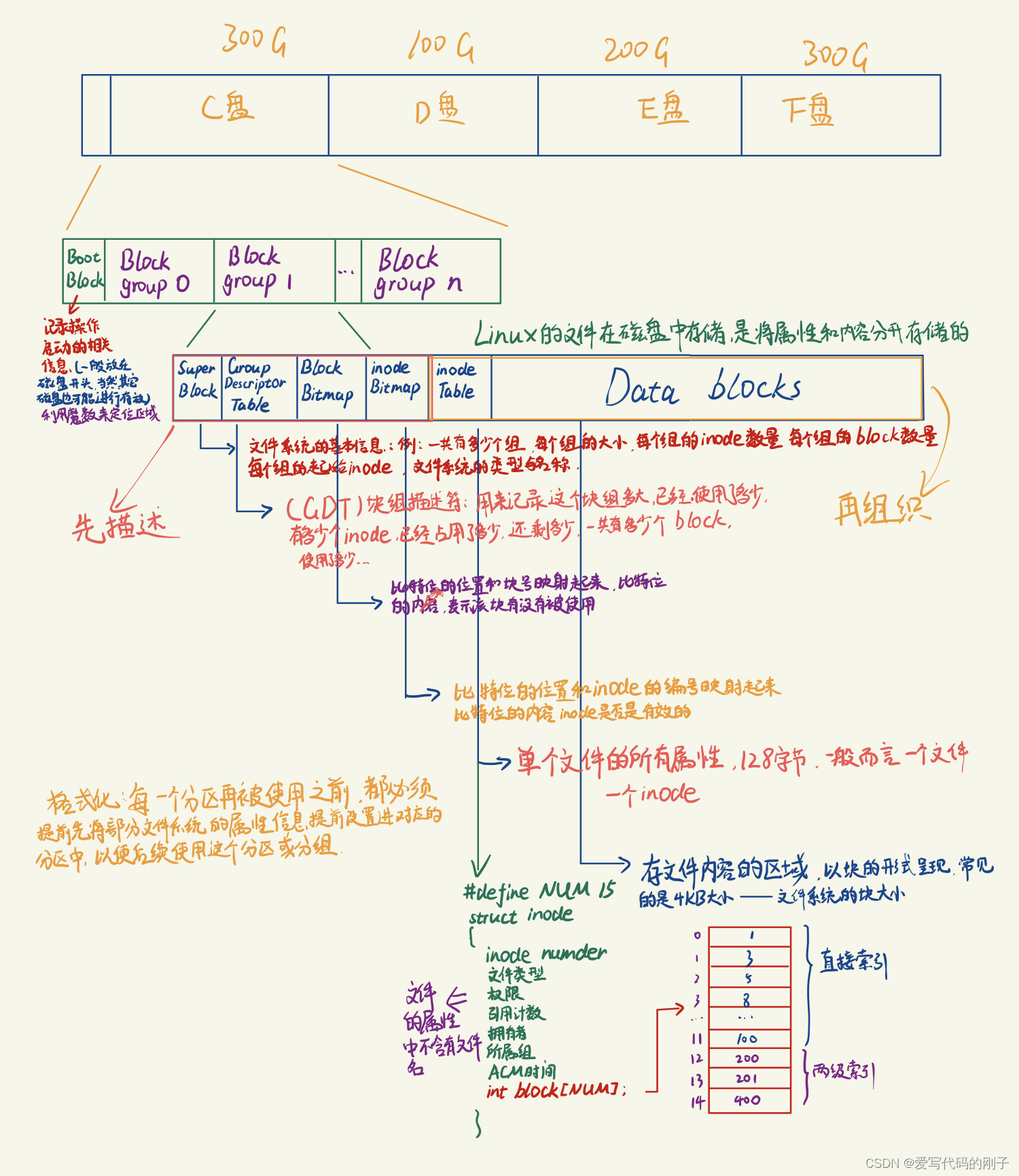
关于inode中的block数组:
inode中有struct inode结构体,里面包括了文件所有的属性,和一个blocks[15]数组,其中的下标[0, 11]直接保存的就是该文件对应的blocks编号,下标[12, 15]指向一个datablock,但是这个datablock不保存有效数据,而保存文件所适用的其它块的编号。(相当于一个二级索引)
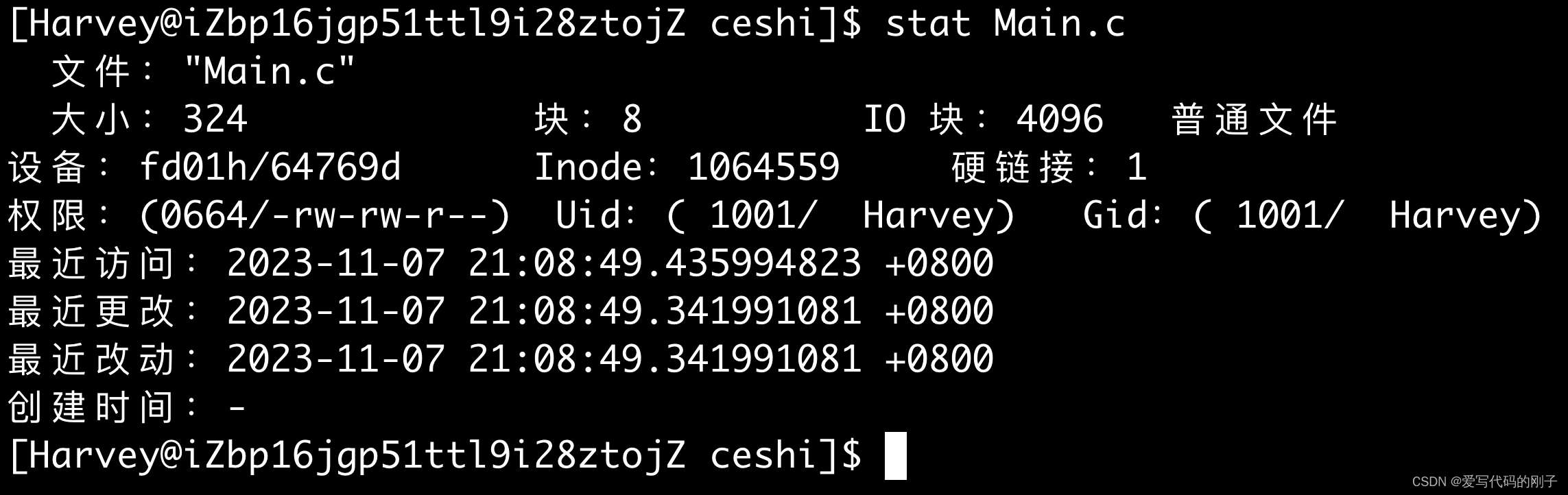
stat +文件名查看文件的具体信息
ls -lia查看所有文件的信息(包括文件的inode)
ls -i查看当前目录下各文件的inode编号
启动块的大小是确定的,而块组的大小是由格式化的时候确定的,并且不可以更改。
文件 = 内容 + 属性,二者都是数据,都要存储。Linux采用的是将内容和属性数据分开存储的方案,内容在block中(4KB),内容是可以无限增多的。属性数据在inode中(128字节),文件的属性是稳定的。
注意一个要点,inode可能会存在用完的情况
- Linux系统中,一个文件一个inode,每一个inode。每一个inode都有自己的inode编号(inode的设置是以分区为单位的,不能跨分区)
对目录的理解
Linux下一切皆文件,目录也是一个文件,通过文件名(对应的inode编号)-> 找到自己所处的目录 -> 根据目录的inode,找到目录的data block -> 将文件名和inode编号的映射关系写入到目录的数据块中。


- 问题1:为什么同一个目录下不能存在同名文件?
因为一个文件只存在一个inode,文件名是作为key值去找inode的,如果存在同名文件就会破坏对应的映射关系。
- 问题2:为什么没有w权限就不能创建文件?
即便是能创建文件,也不能将该文件与inode的映射关系写到数据块中。
- 问题3:为什么没有r权限就不能查看文件?
无法拿到该目录文件中文件与inode之间的映射关系
- 问题4:为什么没有x权限就不能进入目录?
不让用户更改环境变量中的目录信息
查找任何一个文件时,我们必须从当前目录递归到根目录,然后从根目录信息中查找对应子目录的inode信息(效率会低)
所以Linux中会存在提升效率的方法,将常用的路径信息进行缓存(dentry缓存,里面的结构算法较复杂)
软硬链接
建立软链接
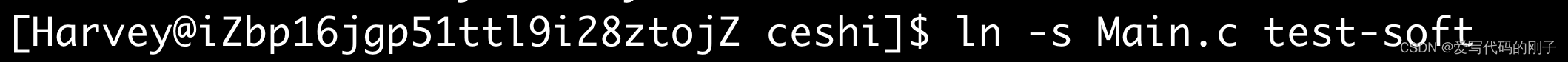


软链接的inode不同
软连接又叫符号链接,软连接文件相当于源文件来说是一个独立的文件,该文件有自己的inode号,但是该文件只包含了源文件的路径名,所以软连接文件的大小要比源文件小得多。软连接就类似于Windows操作系统当中的快捷方式。软链接保存的是对应文件的所在路径
ln -s 对应的路径 软链接的名字添加快捷方式
建立硬链接

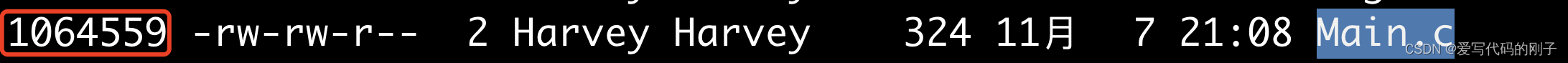

硬链接的inode相同,同时文件的引用计数变为了2
- 硬连接数本质就是该文件inode属性中的计数器count,标识有几个文件名和我的inode建立了映射关系。简言之,就是有几个文件名指向我的inode(文件本身)硬链接就是让多个不在或者同在一个目录下的文件名,同时能够修改同一个文件,其中一个修改后,所有与其有硬链接的文件都一起修改了。
为什么文件被创建出来,默认的硬连接数是1?
- 如果硬链接数是0,那么就应该是被关闭的文件了,所以至少应该从1开始。此外,普通文件的文件名,本身就和自己的inode具有映射关系,且只有1个,所以文件的默认硬连接数是1。
创建一个新目录时引用计数默认为2
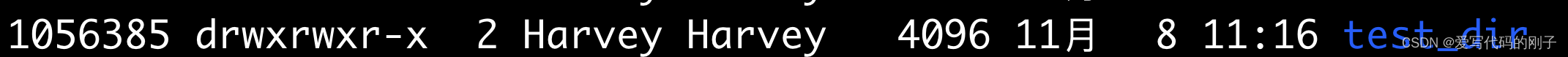
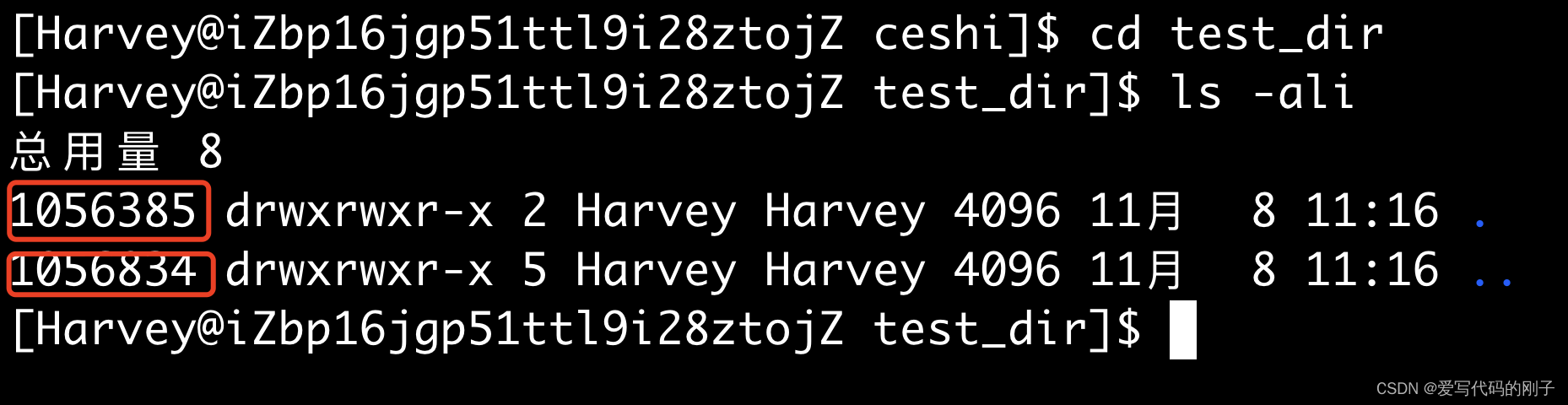
- 我们也可以根据系统的硬连接数,不进入文件,从而估算出文件的目录数(一个目录下相邻的子目录数 = 该目录的硬连接数 - 2)。因此,硬链接的一个作用就是进行路径切换。
软硬链接的删除
unlink(unlink也可以删除普通文件,与rm没什么区别)

文件的三个时间
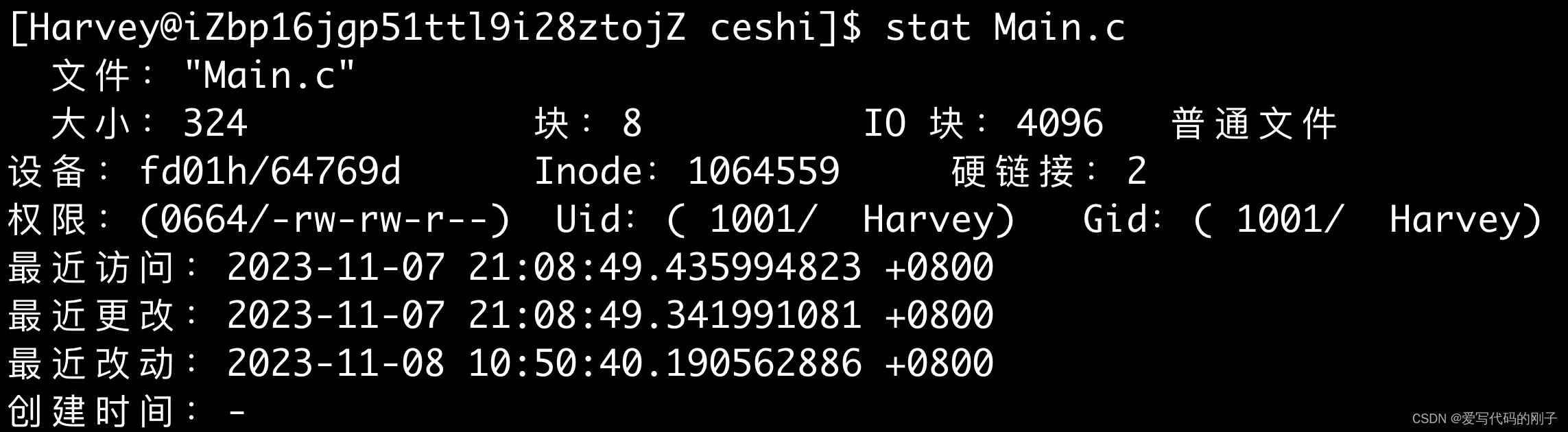
这其中包含了文件的三个时间信息:
- Access: 文件最后被访问的时间。
- Modify: 文件内容最后的修改时间。
- Change: 文件属性最后的修改时间。
当我们修改文件内容时,文件的大小一般会随之改变,所以Modify的改变会带动Change一起改变,但对该文件属性一般不会影响文件内容,所以一般情况下Change的改变不会带动Modify的改变。此外,我们可以使用touch命令把这三个时间都更新到最新状态。(当一文件存在时使用touch命令,此时touch命令的作用变为更新文件信息)。