目录
4 文件IO性能监控
4.1 I/O 的两种方式(缓存 I/O 和直接 I/O)
1 缓存 I/O
2 直接 I/O
4.2 监控磁盘I/O的命令
1 iostat IO状态
2 swapon查看分区使用情况
3 df硬盘使用情况
4 du目录文件大小
4.3 文件IO写入频繁案例分析
C/C++Linux服务器开发/后台架构师【零声教育】-学习视频教程-腾讯课堂
4 文件IO性能监控
写入速度
读取速度
写入次数
读取次数
io等待时间 时间越大说明文件操作频繁
磁盘的统计参数
tps:该设备每秒的传输次数(Indicate the number of transfers per second that were issued tothe device.)。"一次传输"意思是"一次I/O请求"。
多个逻辑请求可能会被合并为"一次I/O请求"。"一次传输"请求的大小是未知的。
kB_read/s:每秒从设备(drive expressed)读取的数据量;
kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
kB_read:读取的总数据量;
kB_wrtn:写入的总数量数据量;这些单位都为Kilobytes。
系统调用、VFS、缓存、文件系统以及块存储之间的关系如下图所示:
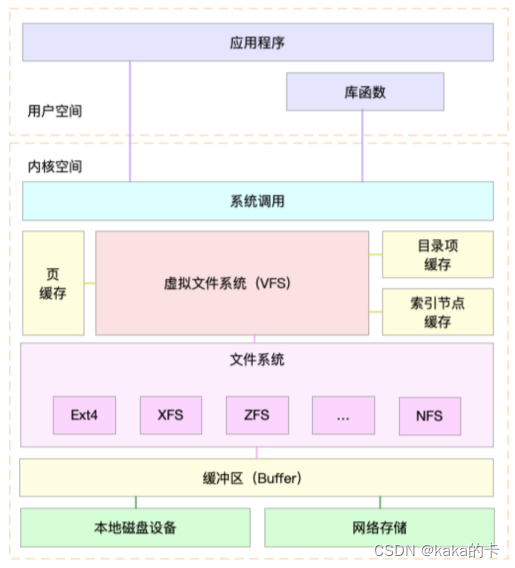
Linux 内核在用户进程和文件系统的中间,又引入了一个抽象层,也就是虚拟文件系统 VFS(Virtual FileSystem)。
I/O 指的是相对内存而言的 input 和 output。从文件、数据库、网络向内存中写入数据叫做 input;从内存向文件、数据库、网络中输出数据叫做 output。Linux 系统 I/O 分为内核准备数据和将数据从内核拷贝到用户空间两个阶段
4.1 I/O 的两种方式(缓存 I/O 和直接 I/O)
1 缓存 I/O
缓存 I/O 又被称作标准 I/O,大多数文件系统的默认 I/O 操作都是缓存 I/O。在 Linux 的缓存 I/O 机制中,数据先从磁盘复制到内核空间的缓冲区,然后从内核空间缓冲区复制到应用程序的地址空间(用户空间)。
读操作:操作系统检查内核空间的缓冲区有没有需要的数据,如果已经缓存了,那么就直接从缓存中返回,也就是将数据复制到应用程序的用户空间;否则从磁盘中读取数据至内核空间的缓冲区,再将内核空间缓冲区的数据返回。
写操作:将数据从用户空间复制到内核空间的缓冲区,这时对用户程序来说写操作就已经完成。至于什么时候将数据从内核空间写到磁盘中,这步由操作系统决定,除非显示地调用了 sync 同步命令。
缓存 I/O 的优点:
1. 在一定程度上分离了内核空间和用户空间,保护系统本身的运行安全;
2. 可以减少读盘的次数,从而提高性能。
缓存 I/O 的缺点:
- 在缓存 I/O 机制中,DMA 方式可以将数据直接从磁盘读到内核空间的页缓存中,或者将数据从内核空间的页缓存中直接写回到磁盘上,而不能直接在应用程序地址空间(用户空间)和磁盘之间进行数据传输。这样,数据在传输过程中需要在应用程序地址空间(用户空间)和页缓存(内核空间)之间进行多次数据拷贝操作,这些数据拷贝操作所带来的 CPU 以及内存开销是比较大的。
2 直接 I/O
直接 IO 就是应用程序直接访问磁盘,而不经过内核缓冲区,这样做的目的是减少一次从内核缓冲区到用户程序地址空间的数据复制操作。
例如数据库管理系统这类应用,它们更倾向于选择自己的缓存机制,因为数据库管理系统往往比操作系统更了解数据库中存放的数据。数据库管理系统可以提供一种更加高效的缓存机制来提高数据库中存取数据的性能。
4.2 监控磁盘I/O的命令
1 iostat IO状态
该命令用于监控CPU占用率、平均负载值及I/O读写速度等。
参数介绍
iostat [ -c ] [ -d ] [ -h ] [ -N ] [ -k | -m ] [ -t ] [ -V ] [ -x ] [ -z ] [ device [...] | ALL ] [ -p [ device [,...] | ALL ]] [ interval [ count ] ]
常用参数
1. -c: 输出cpu统计信息
2. -d: 输出磁盘统计信息 注:默认是两个都输出
3. -k|-m: 以kb/s|mb/s代替原来的块/s
4. -t: 输出时打印收集信息时刻的时间 注:时间的打印格式和系统变量S_TIME_FORMAT相关
5. -x: 输出详细的拓展统计数据,比如各种等待时间,队列,利用率等信息。
6. interval [count] :interval是统计的时间间隔单位是s,count则是统计次数
await指的是平均等待时间,一般都在10ms左右

每个输出消息含义:
rrqm/s: 每秒对该设备的读请求被合并次数,文件系统会对读取同块(block)的请求进行合并
wrqm/s: 每秒对该设备的写请求被合并次数
r/s: 每秒完成的读次数
w/s: 每秒完成的写次数
rkB/s: 每秒读数据量(kB为单位)
wkB/s: 每秒写数据量(kB为单位)
avgrq-sz:平均每次IO操作的数据量(扇区数为单位) ,比如1616.56
avgqu-sz: 平均等待处理的IO请求队列长度,比如2.74
await: 平均每次IO请求等待时间(包括等待时间和处理时间,毫秒为单位),比如w_await 2.97
svctm: 平均每次IO请求的处理时间(毫秒为单位),比如0.72
%util: 采用周期内用于IO操作的时间比率,即IO队列非空的时间比率。表示该设备的繁忙程度,比如82.80。例如,如果统计间隔1秒,该设备有0.5秒在处理IO,而0.5秒闲置,则该设备的%util =0.5/1 = 50%。一般地,如果该参数是100%表示设备已经接近满负荷运行。
cpu的统计信息,如果是多cpu系统,显示的所有cpu的平均统计信息。
%user:用户进程消耗cpu的比例
%nice:用户进程优先级调整消耗的cpu比例
%sys:系统内核消耗的cpu比例
%iowait:等待磁盘io所消耗的cpu比例
%idle:闲置cpu的比例(不包括等待磁盘I/O)
常用用法
// kb/s显示磁盘信息,每2s刷新一次
iostat -d -k 2
// kb/s显示磁盘统计信息及扩展信息,每1s刷新 ,刷新10次结束
iostat -dkx 1 10
2 swapon查看分区使用情况
查看交互分区的使用情况
使用方法:swapon -s
[root@VM_0_ubuntu ~]# swapon -s
Filename Type Size Used Priority
/var/swap file 8191996 473856 -2
我们在安装系统的时候已经建立了 swap 分区。swap 分区通常被称为交换分区,这是一块特殊的硬盘空间,即当实际内存不够用的时候,操作系统会从内存中取出一部分暂时不用的数据,放在交换分区中,从而为当前运行的程序腾出足够的内存空间。 也就是说,当内存不够用时,我们使用 swap 分区来临时顶替。这种“拆东墙,补西墙”的方式应用于几乎所有的操作系统中
一般来讲,swap 分区容量应大于物理内存大小,建议是内存的两倍,但不超过 2GB。
3 df硬盘使用情况
该命令用于查看文件系统的硬盘挂载点和空间使用情况。
使用方式:df -h

4 du目录文件大小
du常用的选项:
-h:以人类可读的方式显示,显示M或K
-a:显示目录占用的磁盘空间大小,还要显示其下目录和文件占用磁盘空间的大小-s:显示目录占用的磁盘空间大小,不显示其下子目录和文件占用的磁盘空间大小-c:显示几个目录或文件占用的磁盘空间大小,还要统计它们的总和
du -a 显示目录和目录下子目录和文件占用磁盘空间的大小。直接使用-a 以字节为单位,-ha 如下图以M或K为结果显示。
du -s 显示当前所在目录大小
du -s -h home 显示home目录大小
du -c 显示几个目录或文件占用的磁盘空间大小,还要统计它们的总和
du -lh --max-depth=1 : 查看当前目录下一级子文件和子目录占用的磁盘容量。
4.3 文件IO写入频繁案例分析
1. 启动iostat -x命令监测
iostat -dkx 1 30
2. 使用sysbench模拟数据读写
sysbench的性能测试都需要做prepare,run,cleanup这三步,准备数据,跑测试,删除数据。在准备阶段创建测试所需数据,在清理阶段删除这些数据。
#cd要到你测试的磁盘目录下
cd /data/disktest
# 线程数=4 每隔4s输出一次结果 测试时间=60s
# 文件数=10 文件总大小=10G 文件操作模式=随机读写
sysbench --num-threads=4 --max-time=60 --test=fileio --file-num=10 --file-totalsize=10G --file-test-mode=rndrw prepare
sysbench --num-threads=4 --max-time=60 --test=fileio --file-num=10 --file-totalsize=10G --file-test-mode=rndrw run
sysbench --num-threads=4 --max-time=60 --test=fileio --file-num=10 --file-totalsize=10G --file-test-mode=rndrw cleanup