一 网络信息浏览
1 HTTP协议
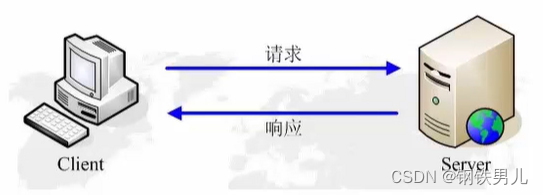
2 客户端与服务器
3 Request与Response
4 Stream
5 Get与Post
二 一些查看工具
1 Fiddler2
http://www.fidddler2.com
2 其他工具
如NetworkMoniter、Visula Sniffer、httpwatch、WireShark
3 Chrom/FireFox等浏览器F12
① Chrome 中按F12,或点右键,“审查元素”;
② FireFox中安装FireBug;
三 使用System.Web
① System.Web提供支持浏览器/服务器通讯的类和接口。
② 此命名空间包括提供有关当前HTTP请求的大量信息的Request类,管理HTTP到客户端的输出Response类,以及提供对服务器端实用工具和进程的访问的HttpServerUtility对象。
③ System.Web还包括用于Cookie操作、文件传输、异常信息和输出缓存控制的类。
四 WebClient类
1 DownloadData及DownloadFile
① 后来又有DownloadStriing;
② UploadData及UploadFile;
③ OpenRead及OpenWrite;
2 示例:WebClientDownload.cs
① string url=@“http://www.baidu.com”;
② WebClient client=new WebClient();
③ byte[] pageData=client.DownloadData(url);
④ string pageHtml=Encoding.Default.GetString(pageData);
⑤ Console.WriteLine(pageHtml);
3 WebRequest及WebResponse
① WebRequest myRequest=
WebRequest.Create(“http://www.contoso.com”);
② WebResponse myREsponse=myRequest.GetResponse();
③ Stream requestStream =myRequest.GetRequestStream();
④ Stream receiveStream=myWebResponse.GetResponseStream();
using System;
using System.Collections.Generic;
using System.Linq;
using System.Net;
using System.Text;
using System.Threading.Tasks;
namespace 使用WebClient
{
internal class Program
{
static void Main(string[] args)
{
string url = @"https://localhost/test.html";
WebClient client = new WebClient();
byte[] pageData = client.DownloadData(url);
string pageHtml = Encoding.Default.GetString(pageData);
Console.WriteLine(pageHtml);
Console.ReadKey();
}
}
}
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Net;
using System.Text;
using System.Threading.Tasks;
namespace DownloadString
{
internal class Program
{
static void Main(string[] args)
{
string url = "https://www.baidu.com";
if (args.Length != 0)
url = args[0];
string str = DownloadString(url);
Console.WriteLine(str);
Console.ReadKey();
}
public static string DownloadString(string url)
{
try
{
HttpWebRequest request = WebRequest.Create(url) as HttpWebRequest;
request.Credentials = CredentialCache.DefaultCredentials;
HttpWebResponse response = request.GetResponse() as HttpWebResponse;
Stream responseStream = response.GetResponseStream();
Encoding encoding = Encoding.UTF8;
StreamReader reader = new StreamReader(responseStream, encoding);
string str = reader.ReadToEnd();
reader.Close();
responseStream.Close();
response.Close();
return str;
}
catch(UriFormatException exception)
{
Console.WriteLine(exception.Message.ToString());
Console.WriteLine("Invalid URL format.Please use https://www.yoursite.com");
}
catch(WebException exception2)
{
Console.WriteLine(exception2.Message.ToString());
}
return "";
}
}
}
using System;
using System.Collections;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Net;
using System.Text;
using System.Text.RegularExpressions;
using System.Threading.Tasks;
namespace 猜字符的编码
{
internal class Program
{
static void Main(string[] args)
{
string url = "https://www.pku.edu.cn";
if (args.Length != 0)
url = args[0];
string str = DownloadString(url);
Console.WriteLine(str);
Console.ReadKey();
}
public static string DownloadString(string url)
{
string html = "";
try
{
HttpWebRequest request = WebRequest.Create(url) as HttpWebRequest;
request.Credentials = CredentialCache.DefaultCredentials;
HttpWebResponse response = request.GetResponse() as HttpWebResponse;
Stream responseStream = response.GetResponseStream();
Encoding encoding = GuessDownloadEncoding(response);//用这个编码更好
if (encoding != null)
{
StreamReader reader = new StreamReader(responseStream, encoding);
html = reader.ReadToEnd();
reader.Close();
}
else
{
byte[] htmlByte = GetByteContent(responseStream);
html = Encoding.GetEncoding("utf-8").GetString(htmlByte);
string reg_charset = "(<meta[^>]*charset=(?<charset>[^>'\"]*)[\\s\\S]*?>)|(xml[^>]+encoding=(\"|')*(?<charset>[^>'\"]*)[\\s\\S]*?>)";
Regex r = new Regex(reg_charset, RegexOptions.IgnoreCase);
Match m = r.Match(html);
string encodingName = (m.Captures.Count != 0) ? m.Result("${charset}") : "";
Console.WriteLine(encodingName);
if (encodingName != "")
{
html = Encoding.GetEncoding(encodingName).GetString(htmlByte);
}
}
responseStream.Close();
response.Close();
}
catch (UriFormatException exception)
{
Console.WriteLine(exception.Message.ToString());
}
catch (WebException exception2)
{
Console.WriteLine(exception2.Message.ToString());
}
return html;
}
private static byte[] GetByteContent(Stream stream)
{
ArrayList arBuffer = new ArrayList();
byte[] buffer = new byte[1024];
int offset = 1024;
int count = stream.Read(buffer, 0, offset);
while(count>0)
{
for(int i=0;i<count;i++)
{
arBuffer.Add(buffer[i]);
}
count = stream.Read(buffer, 0, offset);
}
return (byte[])arBuffer.ToArray(typeof(byte));
}
private static Encoding GuessDownloadEncoding(HttpWebResponse response)
{
string charset = GetCharSet(response.ContentType);
if (charset == "")
charset = GetCharSet(response.Headers["Content-Type"]);
try
{
if (charset != "")
return Encoding.GetEncoding(charset);
}
catch { }
return null;
}
private static string GetCharSet(string contentType)
{
Console.WriteLine("contentType:" + contentType);
if (contentType == null | contentType == "")
return "";
string[] strArray = contentType.ToLower().Split(new char[] { ',', '=', ' ' });
bool flag = false;
foreach(string str2 in strArray)
{
if(str2=="charset")
{
flag = true;
}
else if(flag)
{
return str2;
}
}
return "";
}
}
}
using System;
using System.Collections.Generic;
using System.Linq;
using System.Net;
using System.Text;
using System.Text.RegularExpressions;
using System.Threading.Tasks;
namespace 下载网页中的所有图片
{
internal class Program
{
static void Main(string[] args)
{
string pattern = @"(<)(.[^<]*)((src|href)=)('|""| )?(?<fileUrl>(.[^'|\s|""]*)(\.)(jpg|gif|png|bmp|jpeg|swf))('|""|\s|>)(.[^>]*)(>)";
string pageUrl = @"https://www.pku.edu.cn/";
if(args!=null&&args.Length>0)
{
pageUrl = args[0];
}
pageUrl = pageUrl.Replace('\\', '/');
int p = pageUrl.LastIndexOf('/');
string urlPath = pageUrl.Substring(0, p + 1);
int ph = pageUrl.IndexOf('/', pageUrl.IndexOf('/') + 2);
string urlHost = pageUrl.Substring(0, ph);
string pageContent = DownOnePage(pageUrl);
Console.WriteLine(pageContent);
Regex rx = new Regex(pattern, RegexOptions.IgnoreCase);
MatchCollection mc = rx.Matches(pageContent);
Console.WriteLine("有{0}次匹配", mc.Count);
foreach(Match mt in mc)
{
string fileUrl = mt.Result("${fileUrl}");
fileUrl = fileUrl.Replace('\\', '/');
if(fileUrl.IndexOf(':')<0)//它不包含协议名
{
if (fileUrl[0] == '/')//它是绝对路径
fileUrl = urlHost + fileUrl;
else//相对路径
fileUrl = urlPath + fileUrl;
}
Console.WriteLine(fileUrl);
int p2 = fileUrl.LastIndexOf('/');
string fileName = fileUrl.Substring(p2 + 1);
DownOneFile(fileUrl, fileName);
Console.ReadKey();
}
}
static void DownOneFile(string url,string fileName)
{
WebClient client = new WebClient();
client.DownloadFile(url, fileName);
}
static string DownOnePage(string url)
{
WebClient client = new WebClient();
byte[] pageData = client.DownloadData(url);
string pageHtml = Encoding.UTF8.GetString(pageData);
return pageHtml;
}
}
}