Makefile(详细教程)
1. Makefile的相关概念介绍
1.1 Makefile是什么
一个工程中的源文件不计其数,其按类型、功能、模块分别放在若干个目录中,Makefile定义了一系列的规则来指定哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至进行更复杂的功能操作。
1.2 make 和 Makefile 的关系
make 是一个命令工具,它解释 Makefile 中的指令;在 Makefile 文件中描述了整个工程所有文件的编译顺序、编译规则。
1.3 Makefile的命名规则
Makefile 或 makefile,一般使用 Makefile。
1.4 CMake又是什么
CMake 是一个跨平台的安装(编译)工具,可以用简单的语句来描述所有平台的安装(编译过程)。他能够输出各种 makefile 或者project 文件,能测试编译器所支持的 C++ 特性,类似 UNIX 下的automake。只是 CMake 的组态档取名为 CMakeLists.txt。CMake 并不直接建构出最终的软件,而是产生标准的建构档(如 Unix 的Makefile 或 Windows Visual C++ 的 projects/workspaces),然后再依一般的建构方式使用。
补充说明:
组态档:描述项目配置和构建过程的关键文件。
CMakeLists.txt 文件:是使用CMake构建系统时必须包含的文件。CMakeLists.txt 文件用于描述项目的各种信息和设置,例如项目名称、源代码文件路径、库文件路径、编译选项、链接选项等等。
“建构档”(或称为"构建脚本"):是指用于描述软件系统编译和构建过程的文件。这些文件通常包含了编译器、链接器、库等构建工具的命令和选项,以及源代码、头文件、库文件等资源的路径和依赖关系等信息。
1.5 CMake 和 CMakeLists 的关系
cmake是一个命令工具,可用来生成 Makefile。但也要根据 CMakeLists.txt 中的内容来生成,CMakeLists.txt就是写给 cmake 的规则。
1.6 总结
make是一个命令工具,Makefile是一个文件,make执行的时候,去读取Makefile文件中的规则,重点是 Makefile 得自己写。
cmake是一个命令工具,CMakeLists.txt是一个文件,cmake执行的时候,去读取CMakeLists.txt文件中的规则,重点是 CMakeLists.txt 得自己写。
2. 从 hello world 开始
2.1 Makefile的基本语法
目标:依赖
TAB 命令
目标:一般是指要编译的目标,也可以是一个动作。
依赖:指执行当前目标所要依赖的选项,包括其它目标,某个具体文件或库等。
需要注意的是,一个目标可以有多个依赖,但也可以没有。
命令:该目标下要执行的具体命令,可以没有,也可以有多条。但要注意,如果有多条,则每条命令写一行。
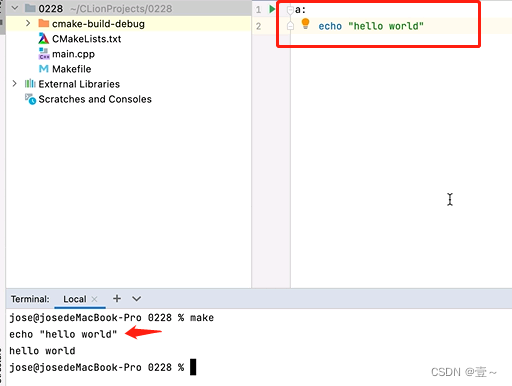
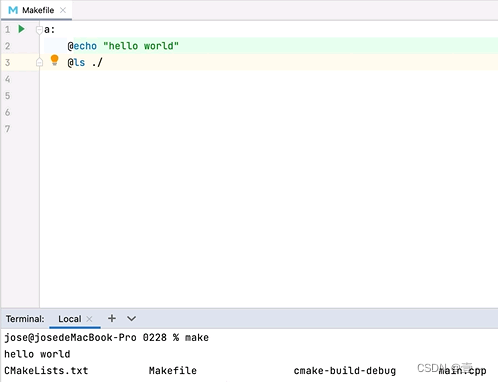
例如上图,a就是目标,可以没有依赖。注意,命令之前别忘了加TAB符。当执行make时,会先打印命令,再执行命令。如果有不想打印命令的需求,可以在命令之前加上@,可以抑制命令的输出。如下图:
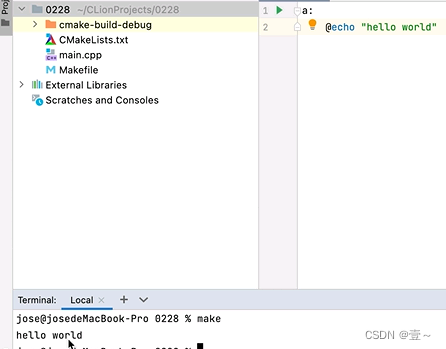
当有多条命令时:
2.2 当有多个目标时
当有多个目标时,用的是第一个目标! 这是默认的!!!
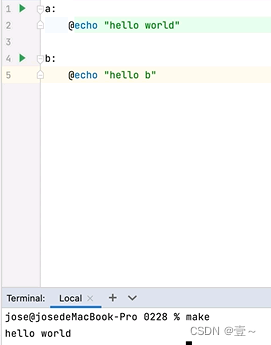
如图,当执行make时,执行的是第一个目标。当想执行下面某一个目标时,就要在make后面加上目标的名字。如下图:
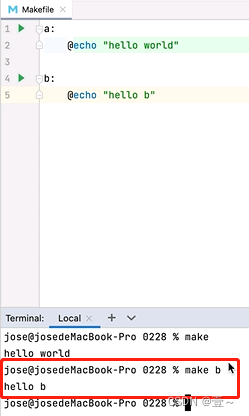
2.3 当有依赖时
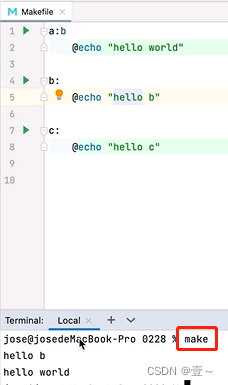
当有依赖时,会先执行依赖再执行自己的命令,如上图,先执行了b,再执行a自己。
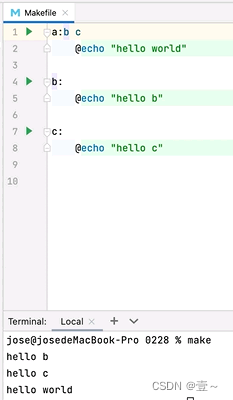
当有多个依赖时,也同理,不过依赖之间也有执行顺序,放在前面的先执行。
2.4 make 的常用选项
make [-f file] [options] [target]
Make 默认在当前目录中寻找文件名为 GUNmakefile,Makefile,makefile 的文件作为 make 的输入文件。
- -f 可以指定除上述文件名之外的文件作为输入文件;
- -v 显示版本号;
- -n 只输出命令,但并不执行,一般用来测试;
- -s 只执行命令,但不显示具体命令,此处可在命令中用@符抑制命令输出;
- -w 显示执行前执行后的路径
- -C dir 指定 makefile 所在的目录
没有指定目标时,默认使用第一个目标。如果指定,则执行对应的命令。
3. 编译流程
3.1 引言(Makefile编写的好习惯)
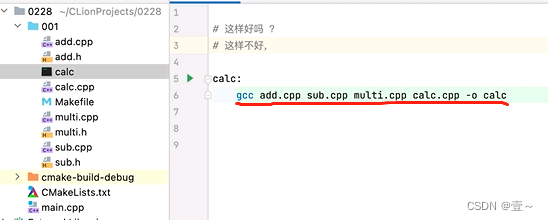
当我们想写一个计算器时,Makefile这样写是不好的。一次性把加减乘和计算器的主文件都一块编译了,这样子会影响效率,因为只有其中有一个改动了,这四个文件都要重新编译。它执行make时是下面这样:

Makefile要改成这样才比较好:

它执行make的结果是下面这样的:
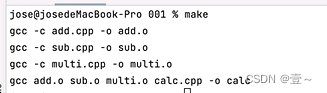
这样子,当你单独修改了add.cpp的时候,就只是重新编译了add和calc。如下图:
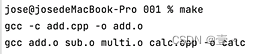
因为 sub.cpp 和 multi.cpp 都没有改动,所以无需再次编译。而 calc 是由于 add.cpp 的改动,而它又需要依赖到 add.o ,所以它也才需要重新编译。
这样写的好处就是只有在第一次编译时,会把全部都编译一次,而后面编译时,只需编译那些改动过的。从而提高了效率,设想一下,如果有成千上万个文件,如果采用第一次那种 Makefile 的写法,则会导致有可能编译会编译很久。而如果采用第二种,则在编译时只会重编那些修改过的。这样分开来写,可以保证只编译改动的代码。 如下图,如果没有改动,则不需要编译:

3.2 编译流程
提示:-o 参数指定了输出的文件名。
下面是一个源文件(main.cpp)的内容:
#include<iostream>
using namesspace std;
int main(){
cout<<"Hello world!"<<endl;
return 0;
}
当执行 gcc -lstdc++ main.cpp 时,会直接从源文件到可执行文件,如果不使用-o指定可执行文件的名字,则默认为a.out。
下面我们把源文件到可执行文件的过程拆分一下:
- 预处理:
gcc -E main.cpp,执行这个命令后,不会生成文件,只是将预处理的结果输出到标准输出流(终端窗口)中。如果希望把预处理的结果保存下来,则可以使用重定向,如gcc -E main.cpp>main.ii,将预处理的结果保存到名为main.ii的文件中。 - 编译:
gcc -S main.ii,得到名为main.s(默认名)的汇编文件。 - 汇编:
gcc -c main.s,得到名为main.o(obj)(默认名)的二进制文件。 - 链接:
gcc -lstdc++ main.o,得到名为a.out的可执行文件。
这样也就可以说明为什么引言部分,Makefile 第二种写法的好处了,当有的文件没有改动,已经是二进制文件了,就没办法要去执行前面的步骤了,只需要去重新编译那些有改动的。
4. Makefile中的变量
4.1 系统常量(可用make -p 查看)
AS: 汇编程序的名称,默认为 as;
CC: C编译期名称,默认为 cc;
CPP: C预编译期名称,默认为 cc -E;
CXX: C++编译器名称,默认为 g++;
RM: 文件删除程序别名,默认为 rm -f;
4.2 自定义变量
定义:变量名=变量值
使用:$(变量名), ${变量值}
对于上面的Makefile,我们可以使用自定义变量进行修改,使它更简便一些:
OBJ=add.o sub.o multi.o calc.o
TARGET=calc
$(TARGET):$(OBJ)
gcc $(OBJ) -o $(TARGET)
add.o:add.cpp
gcc -c add.cpp -o add.o
sub.o:sub.cpp
gcc -c sub.cpp -o sub.o
multi.o:multi.cpp
gcc -c multi.cpp -o multi.o
calc.o:calc.cpp
gcc -c calc.cpp -o calc.o
clean:
rm -rf *.o calc
4.3 系统变量
$*:不包括扩展名的目标文件名称;
$+:所以的依赖文件,以空格分隔;
$<:表示规则中的第一个条件;
$?:所有时间戳比目标文件晚的依赖文件,以空格分隔;
$@:目标文件的完整名称;
$^:所有不重复的依赖文件,以空格分隔;
$%:如果目标是归档成员,则该变量表示目标的归档成员名称;
对上面的Makefile再次修改一下:
OBJ=add.o sub.o multi.o calc.o
TARGET=calc
$(TARGET):$(OBJ)
gcc $^ -o $@
add.o:add.cpp
gcc -c $^ -o $@
sub.o:sub.cpp
gcc -c $^ -o $@
multi.o:multi.cpp
gcc -c $^ -o $@
calc.o:calc.cpp
gcc -c $^ -o $@
clean:
rm -rf *.o $(TARGET)
这样写的好处就是,当行数比较多的时候,而且当依赖和目标比较多的时候,这样写可以比较清晰,且比较不容易漏写。
上面的代码还可以继续完善,运用系统常量:
OBJ=add.o sub.o multi.o calc.o
TARGET=calc
$(TARGET):$(OBJ)
$(CXX) $^ -o $@
add.o:add.cpp
$(CXX) -c $^ -o $@
sub.o:sub.cpp
$(CXX) -c $^ -o $@
multi.o:multi.cpp
$(CXX) -c $^ -o $@
calc.o:calc.cpp
$(CXX) -c $^ -o $@
clean:
$(RM) *.o $(TARGET)
这样写的好处就是,可以实现跨平台的效果,因为可能$(CXX)在不同平台下所代表的是不同的,有的可能是g++,有的是c++。
5. 伪目标和模式匹配
5.1 伪目标
在 Makefile 中,伪目标(Phony Target)是一种特殊的目标,它并不代表要构建的文件,而是一个用于定义需要执行的命令序列的目标。伪目标不是文件,而是一个名字,它与文件名没有关系,不能由Makefile的规则生成。它并不检查日期,无论目标是否存在,相关的命令都会执行。
伪目标通常用于定义一些不产生实际文件输出的操作,比如清理临时文件、运行测试等。它们并不对应真实的文件,所以无论目标名与其他文件名是否冲突,在构建过程中都会被执行。
伪目标的语法格式是在目标名前加上 .PHONY: 关键字,如下所示:
.PHONY: target_name ……
其中,target_name 是你定义的伪目标名称,可以有多个伪目标。
当使用上面的 Makefile 时,又使用touch clean,生成了 clean 文件,这时如果使用make clean命令,则没办法执行到 Makefile 里的 clean。这个时候就需要用到伪目标。把代码改成下面这样:
.PHONY:clean
OBJ=add.o sub.o multi.o calc.o
TARGET=calc
$(TARGET):$(OBJ)
$(CXX) $^ -o $@
add.o:add.cpp
$(CXX) -c $^ -o $@
sub.o:sub.cpp
$(CXX) -c $^ -o $@
multi.o:multi.cpp
$(CXX) -c $^ -o $@
calc.o:calc.cpp
$(CXX) -c $^ -o $@
clean:
$(RM) *.o $(TARGET)
这个时候使用make clean就可以了,有了伪目标,它就会忽略同名的文件。
5.2 模式匹配
(1)%.o:%.cpp: .o依赖于对应的.cpp,也就是说add.o:add.cpp,都是add,就可以使用%.o:%.cpp。也就是目标和依赖相同部分,可以用%来通配。 %就是通配符。
则上面代码又可以再次进行改善:
.PHONY:clean
OBJ=add.o sub.o multi.o calc.o
TARGET=calc
$(TARGET):$(OBJ)
$(CXX) $^ -o $@
%.o:%.cpp
$(CXX) -c $^ -o $@
clean:
$(RM) *.o $(TARGET)
改成这样之后,所有的依赖(OBJ)都会来匹配%.o:%.cpp $(CXX) -c $^ -o $@,因为所有的依赖都符合这个规则。
(2)wildcard:$ (wildcard ./* .cpp)获取当前目录下所有的.cpp文件;
(3)patsubst:$ (patsubst %.cpp,%.o,./*.cpp)将当前目录下的对应的cpp文件名替换成.o文件名;
可以根据这两个对 Makefile 进行修改:
.PHONY:clean
OBJ=$(patsubst %.cpp,%.o,$(wildcard ./\*.cpp))
TARGET=calc
$(TARGET):$(OBJ)
$(CXX) $^ -o $@
%.o:%.cpp
$(CXX) -c $^ -o $@
clean:
$(RM) *.o $(TARGET)
6. Makefile的运行流程
以下面代码为例:
第一次编译calc,因为依赖add.o、sub.o、multi,o都还没有生成,所以需要先编译它们,最后再编译calc。如果过后想要重新编译,只要这些依赖没有改变就无需重新编译,直接使用已经生成的可执行文件就行,但如果有其中几个依赖的源文件发生了改变,就需要重新编译。
计算机判断源文件有无发生改变的标准: 计算机会分别记录目标和源文件的时间戳,然后进行比较,如果依赖的时间比目标的时间晚,则该目标需要重新编译。以上面的例子为例,如果已经有编译过add.o,后来修改了add.cpp,这时add.cpp的时间戳比add.o晚,这时add.o就需要重新编译。而calc又是需要依赖到add.o,所以calc也需要重新编译。
它 make 的结果如下:
7. 动态链接库
7.1 概念
在C++中,动态库(Dynamic Library)是一种可由程序动态加载和链接的库文件,它包含了可供其他程序调用和使用的函数、类、变量以及其他资源。动态库通常以 .dll(在Windows下)或 .so(在Linux和类Unix系统下)的文件扩展名来命名。动态库提供了一种灵活的机制,可以在程序运行时动态加载和链接这些库,从而实现代码的共享和重用。
使用动态库的好处包括:
-
节省内存:多个程序可以共享同一个动态库,避免了重复加载和占用内存空间。
-
灵活更新:如果动态库需要更新或修复bug,只需替换动态库文件,无需重新编译和链接整个程序。
-
模块化设计:将功能模块分装成动态库,便于不同项目之间的共享和复用。
-
耦合性弱: 程序可以和库文件分离,可以分别发版。
在C++中,使用动态库可以通过链接器进行操作,如在编译时指定动态库的位置和名称。另外,在程序运行时,可以使用相关的函数和API动态加载和卸载库,并根据需要调用其中的函数和使用库中的其他资源。
动态链接库:不会把代码编译到二进制文件中,而是在运行时才去加载,所以只需要维护一个地址。
常见参数选项:
-fPIC 产生位置无关的代码;
-shared 可以将源代码编译成共享库。当执行链接操作时,编译器会将所有需要的符号和函数引用收集起来,并创建一个共享库文件,在运行时会动态地将共享库加载到内存中,并将符号解析为实际的函数或数据;
-l(小L) 指定头文件目录,默认当前目录;
-I(大i) 指定头文件目录,默认只链接共享目录;
共享库可以通过动态链接的方式被运行时环境加载和使用。这意味着多个程序可以共享同一个共享库的实例,节省了系统资源,并且在更新共享库时,不需要重新编译依赖它的程序。
7.2 例子
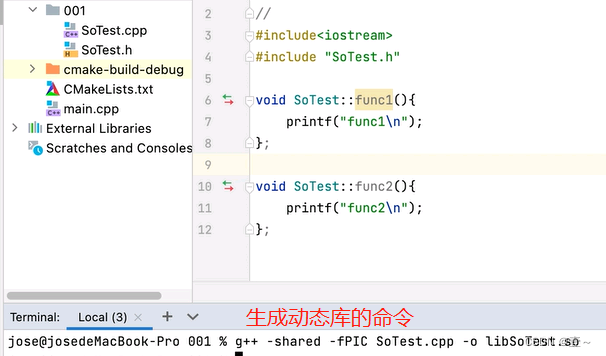
生成动态库的命令:g++ -shared -fPIC SoTest.cpp -o libSoTest.so。
注意动态库的命名规则:如果要编译的文件名为SoTest.cpp,则动态库的名字要为libSoTest.so。要在编译的文件前面加上lib,而.so是因为在Linux系统下。
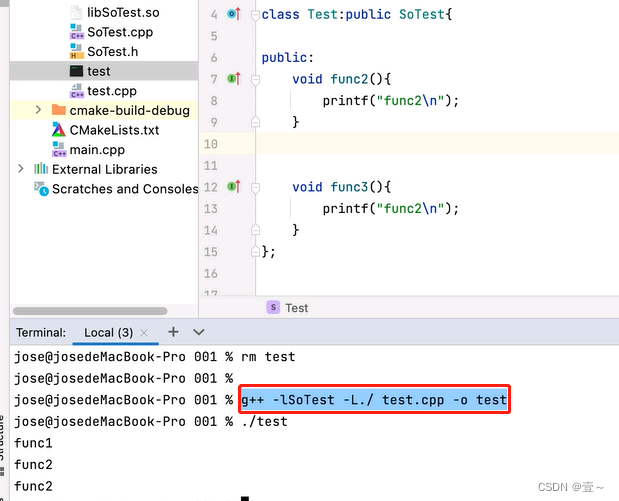
g++ -lSoTest -L./ test.cpp -o test可生成可执行文件test。
命令的各个参数的含义如下:
g++: C++编译器。
-lSoTest: 指定需要链接的共享库,其中的 “-l” 表示链接库,“SoTest” 是共享库的名称。
-L./: 指定共享库的搜索路径,“./” 表示当前路径。编译器会在该路径下查找名为 “libSoTest.so” 的共享库。
test.cpp: 要编译的源文件名称。
-o test: 指定输出的可执行文件名为 “test”。
该命令将编译名为 “test.cpp” 的源文件,并链接一个名为 “libSoTest.so” 的共享库,生成一个名为 “test” 的可执行文件。在编译过程中,编译器会搜索并加载位于当前路径下的 “libSoTest.so” 共享库。
当我们已经编完了动态库时,其实当我们要给别人使用SoTest的时候,只需要把动态库(libSoTest)和头文件(SoTest.h)给到客户就行。

注意:不好意思,上面图中“调用”写出“调研”了。
编译命令:g++ -lSoTest -L./001 main.cpp -o main,指定了动态库存放的目录,存放在./001中。
但会发生上面那种错误是因为编译时指定了要指定要依赖的动态库,但运行时找不到.so文件。因为运行时,系统是去默认的动态库路径下(/lib和/usr/lib)去找动态库文件,如果找不到就会发生上面那种错误。
以下是一些常见的默认搜索路径:
- /lib:该目录包含一些核心的系统动态库。
- /lib64:类似于/lib,但用于64位系统。
- /usr/lib:作为系统级别的库存放位置,用于常见的动态库。
- /usr/local/lib:用于本地安装的软件包所使用的动态库。
- /usr/lib64:类似于/usr/lib,但用于64位系统。
这些路径是根据常见的Linux系统配置提供的示例,并且实际路径可能因操作系统和具体配置而有所不同。此外,可以通过编辑配置文件(如/etc/ld.so.conf)或设置LD_LIBRARY_PATH环境变量来添加自定义的动态库搜索路径。
"/etc/ld.so.conf"是一个配置文件,用于指定动态库搜索路径的顺序。在该文件中,每行指定一个目录作为动态库的搜索路径。系统在加载动态库时会按照文件中的顺序逐个搜索这些目录,直到找到所需的库文件或搜索完所有路径。
该文件通常包含一些默认的搜索路径,如"/lib"和"/usr/lib",但也可以手动添加其他路径。如果您需要将其他目录添加到动态库的搜索路径中,可以编辑"/etc/ld.so.conf"文件,将目录路径添加到新的一行中,然后保存文件。
编辑完成后,需要运行以下命令使更改生效:
sudo ldconfig
该命令会重新加载动态库缓存并更新搜索路径。
配置文件也有搜索顺序,要设置可以通过一下方法:
“/etc/ld.so.conf.d/*.conf” 是一个目录,用于存放动态库搜索路径的配置文件。 在该目录下,每个以".conf"为扩展名的文件表示一个独立的配置文件。系统在加载动态库时会依次读取这些配置文件,并按照文件中指定的顺序进行搜索。
使用"/etc/ld.so.conf.d/*.conf" 目录的好处是可以将不同的动态库搜索路径配置分散到多个文件中,便于管理和维护。每个配置文件只需包含一个目录路径,无需担心格式和冲突问题。
要添加新的动态库搜索路径,可以创建一个以".conf"为扩展名的新文件,然后在该文件中写入要添加的目录路径。例如,您可以创建一个名为"mylibs.conf"的文件,并将目录路径"/path/to/mylibs"写入其中。
编辑完成后,运行以下命令使更改生效:
sudo ldconfig
系统将重新加载动态库缓存并更新搜索路径,以包含新添加的目录路径。
所以要解决上面的问题就只需要把动态库(libSoTest.so)放到默认的动态库搜索路径下,就可以编译成功。
所以要注意,动态库编译之后要发布(放到对应客户机器的动态库搜索路径下),否则程序运行时会找不到。不过也有第二种方法,就是上面说的,设置LD_LIBRARY_PATH环境变量来告诉系统动态库的搜索路径。
以上面的例子为例,在当前终端会话下输入以下两条命令:
LD_LIBRARY_PATH=./001
export LD_LIBRARY_PATH
当输入完再去输入执行可执行文件的命令(./main),这时就可以运行成功了。不过要注意的是,在终端中设置了 LD_LIBRARY_PATH 环境变量后,它仅对当前终端会话中执行的程序有效。一旦关闭终端会话,该环境变量设置就会失效,其他终端会话和系统中的其他进程无法访问到这个环境变量。如果您想要将 LD_LIBRARY_PATH 环境变量设置为全局的,可以考虑将其添加到系统的环境变量配置文件中,如 .bashrc (对于 Bash 终端) 或者 /etc/environment (对于整个系统)。这样,所有的终端会话和系统中的进程都能够访问到该环境变量的设置。然而,修改全局环境变量需要相应的权限和谨慎操作。
8. 静态链接库
静态库的文件后缀名一般为 .a(在 Linux 和 macOS 平台上)或 .lib(在 Windows 平台上)。静态库经过编译后,不管目标程序的哪个模块使用了该库的函数,都会将库的全部代码链接到目标程序中,占用空间较大。
不过在程序编译完成后,甚至可以把静态库给删了,因为库中的全部代码已经链接到程序中了。而动态库则不能这样,动态链接库必须余程序同时部署,还要保证程序能加载到库文件。
与动态库相比,静态库可以不用部署(因为已经被加载到程序里面了),而且运行时速度更快(因为不用去加载),但是会导致程序体积更大,并且库中的内容如果有更新,则需要重新编译生成程序。而动态库则不需要,只要动态库里的接口不变,则只需重新编译动态库,不需要重新编译程序。
静态库还有一个缺点就是:如果多个目标程序使用相同的静态库,则每个目标程序都会包含该库的代码,会造成资源浪费。
需要注意的是,静态库只能提供函数和全局变量等数据,不能在运行时加载其他动态库或者自修改代码,这就限制了它的一些应用场景。
8.1 生成静态库的命令
假设现在有hello.cpp和world.cpp两个源文件,现在要根据它们生成静态库libhello.a。则生成静态库的命令如下:
//生成hello.o和world.o(二进制文件) -c 选项表示只编译,不链接,生成目标文件
g++ -c hello.cpp world.cpp
//ar 命令则用于将目标文件打包成静态库
ar crv libhello.a hello.o world.o
具体地,ar 命令的参数解释如下:
- c: 创建新的静态库,如果已经存在同名的静态库,则替换它。
- r: 将目标文件插入静态库中,如果该目标文件已经存在于静态库中,则用新的目标文件覆盖旧的目标文件。
- v: 显示操作过程的详细信息,包括插入的目标文件名等。
当编译完之后发布一般是发布.a和.h文件,把这些文件给到客户。生成静态库后,我们可以使用 -l 选项来将其链接到目标程序中。例如:
//链接静态库 libhello.a 以及 main.c,并生成可执行文件 main
g++ -lhello -L. main.cpp -o main
这里 -L. 选项表示在当前目录下查找库文件,-lhello 则表示链接名为 libhello.a 的静态库。
8.2 反汇编指令
objdump -DC main>main.txt
objdump 是一个用于查看目标文件或可执行文件的工具,它可以显示二进制文件的汇编代码、符号表以及其他相关信息。通过将 objdump 的输出重定向到文件,可以将其结果保存到指定的文本文件中。
9. 通用部分做公共头文件
9.1 第一部分
一般在程序中当有一些通用的部分代码或头文件时,我们会选择把它们放到同一个文件中,然后使用include,把它包含进去。而在 makefile 中也有这种设计思想。
下面给出一个例子:
在001文件夹中:
//001的文件夹中,有下面四个文件
//a.cpp
#include<iostream>
void func1(){
printf("func1-cpp\n");
}
//b.cpp
#include<iostream>
void func2(){
printf("func2-cpp\n");
}
//c.cpp
extern void func1();
extern void func2();
int main(){
func1();
func2();
return 0;
}
//Makefiile
TARGET=c
OBJ=a.o b.o c.o
.PHONY=clean
c:a.o b.o c.o
gcc %^ -o %@
%.o:%.cpp
gcc -c &^ -o %@
clean:
$(RM) $(TARGET) $(OBJ)
文件结构如下:
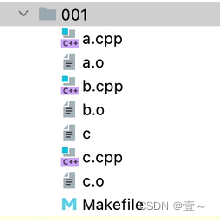
正常情况下,makefile 如上面那样写,但也可以删掉两行:
//Makefiile
TARGET=c
OBJ=a.o b.o c.o
.PHONY=clean
$(TARGET):$(OBJ)
$(GXX) %^ -o %@
#这两句可以删掉,因为编译器会自动推导,根据上面所需的依赖,生成对应的依赖
#%.o:%.cpp
# gcc -c &^ -o %@
clean:
$(RM) $(TARGET) $(OBJ)
执行 make 时,结果如下:

在002文件加中:
//在002文件夹中,有下面四个文件
//x.c
#include<stdio.h>
void func1(){
printf("func1-c\n");
}
//y.cpp
#include<stdio.h>
void func2(){
printf("func2-c\n");
}
//z.cpp
extern void func1();
extern void func2();
int main(){
func1();
func2();
return 0;
}
//makefiile
TARGET=z
OBJ=x.o y.o z.o
.PHONY=clean
$(TARGET):$(OBJ)
clean:
$(RM) $(TARGET) $(OBJ)
文件结构如下:
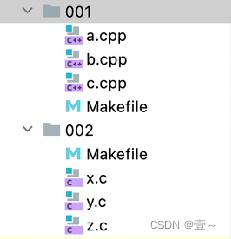
仔细点,你会发现,001文件夹里的 Makefile 和002文件夹里的 Makefile 中的内容大部分一致,除了定义的变量不同。
所以我们可以将以下这部分,提出去,放到001和002的父目录下。
TARGET=z
OBJ=x.o y.o z.o
.PHONY=clean
$(TARGET):$(OBJ)
clean:
$(RM) $(TARGET) $(OBJ)
我们把它放到0304目录下的 makefile 里吧,文件结构如下图所示:
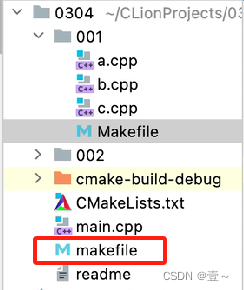
这样之后,就可以修改一下001下和002下的 Makefile 了,具体如下:
//001的Makefile
TARGET=c
OBJ=a.o b.o c.o
include ../makefile
//002的Makefile
TARGET=z
OBJ=x.o y.o z.o
include ../makefile
这样做的效果就起到一个公共头文件的作用。
然而,还可以使用模式匹配将 makefile 修改一下,代码如下:
//makefile
#找出当前路径下所有的cpp和c文件
SOURCE=$(wildacard ./*.cpp ./*.c)
#将SOURCE种的cpp文件转换成.o文件,然后连同.c文件一起赋值给OBJ
OBJ=$(patsubsst %.cpp,%.o,$(SOURCE))
#将OBJ中的.c文件转换成.o文件
OBJ:=$(patsubst %.c,%.o,$(OBJ))
.PHONY:clean
$(TARGET):$(OBJ)
&(CXX) $^ -o $@
clean:
$(RM) $(TARGET) $(OBJ)
//001的Makefile
TARGET=c
include ../makefile
//002的Makefile
TARGET=z
include ../makefile
9.2 第二部分
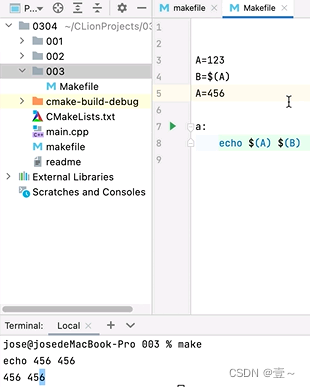
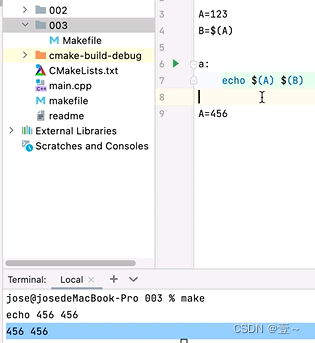
注意上面两张图中,Makefile中,无论 A 最后赋值的位置在哪里,都是取最后一个值,而 B 受 A 的值的影响,所以也是取终值。
9.2.1 =和:=的区别
在Makefile中,变量的赋值是从上到下按顺序执行的。当使用=进行赋值时,变量的展开是延迟进行的,即在使用变量的时候才会进行展开计算。而使用:=进行赋值时,变量的展开是立即进行的,即在赋值的时候就会展开计算。
它们的区别在一些场景下的使用很重要。
X=789
Y=$(X)
Y=$(Y)
首先,变量X被赋值为789。然后,变量Y被赋值为$(X),也就是789。但是在下一行,Y再次被赋值为$(Y),这里的$(Y)实际上是指向自己,形成了一个循环引用,Make解析器无法展开这个循环引用,导致报错。因为等号是延迟展开的,所以有可能在上面代码的下方有可能会有修改到Y的语句,因此Y的值其实也是不确定的。
X=789
Y=$(X)
Y:=$(Y)
同样,变量X被赋值为789,变量Y被赋值为$(X),也就是789。在下一行,Y被赋值为$(Y),这里的$(Y)会立即被展开成789,因此不会形成循环引用,也不会报错。
因此,使用:=进行赋值可以避免循环引用的问题。当出现类似的循环引用情况时,使用:=赋值可以确保变量在赋值时立即展开,避免出现报错。
10. 实现在Makefile中调用shell命令
//makefile
A:=$(shell ls ../) #输出上级目录下的所有文件
B:=$(shell pwd) #输出当前目录
a:
echo $(A)
echo $(B)
11. Makefile中的嵌套调用
以上面9.1中的./001和./002的Makefile为例:
#在./001和./002的公共父目录下的Makefile
#-C 指定工作目录
all:
make -C ./001
make -C ./002
clean:
make -C ./001 clean
make -C ./002 clean
该Makefile可以嵌套调用./001和./002下的Makefile。
可以对上面的代码进行改写:
./PHONY:001 002 clean
DIR=001 002
all:$(DIR)
$(DIR):
make -C $@
clean:
echo $(shell for dir in $(DIR);do make -C $$dir clean;done)
.PHONY是告诉make,001和002都是伪目标,而不是文件或目录。因此,对于这两个目标,就不会检查实际文件或目录的存在,而是直接执行对应的规则,也就是make -C $@。
$(shell command): 这是Makefile的一个内置函数,它的功能是执行括号中的shell命令并返回结果。这样,你可以在Makefile中使用复杂的shell命令。
for dir in $(DIR);do make -C $$dir clean;done:这是一个shell的for循环,它会遍历$(DIR)包含的每个目录,并对每个目录执行 make -C $$dir clean 命令。 Make命令中的 -C 参数是指定在哪个目录下执行Makefile,$$dir 则是当前循环的目录名。 clean 是一个通常在Makefile中定义的目标,用于删除所有由make生成的文件。
在make的上下文中,$$ 对应于shell中的$,用于引用环境变量。因此, $$dir 在shell中会被解析为变量 $dir。即 $$表示展开shell中的变量。
12. Makefile中的条件判断

例子如下:
A:=123
RS1:=
ifeq ($(A),123)
RS1:=yes
else
RS1:=no
endif
all:
echo $(RS1)
注意,ifeq、ifneq与条件之间要有空格,不然会报错。而且没有elseif的用法,如果有这种需求,就只能选择嵌套。
A:=123
RS1:=
ifeq ($(A),123)
RS1:=yes
else
#在这嵌套
ifeq ($(A),321)
RS1=321
else
RS1:=no-123-321
endif
endif
all:
echo $(RS1)
ifdef和ifndef也同理。
ifdef A
RS2:=yes
else
RS2:=no
endif
make 指令还可以传参。
all:
echo $(FLAG)
当在终端下输入make FLAG=123,会输出123。
13. Makefile中的循环
makefile 中只有一个循环语句 foreach,只支持GNU Make,其他平台的 make,可以用 shell 中的循环来实现。
makefile中循环的作用就是,可以逐个的操作每个值,包括去修改它。
TARGET:=a b c d
all:
echo $(foreach v,$(TARGET),$v) #输出a b c d
touch $(foreach v,$(TARGET),$v.txt) #会创建a.txt b.txt c.txt d.txt
#shell的语法
for v in $(TARGET);\
do echo $$v.txt;\
done;
#输出结果如下:
#a.txt
#b.txt
#c.txt
#d.txt
#这也是shell的语法,创建对于的-txt文件
$(shell for v in $(TARGET);do touch $$v-txt;done)
14. Makefile中的自定义函数
自定义函数,不是真正的函数,本质上是多行命令放在外面定义的函数内了。还有一点就是,Makefile中的自定义函数没有返回值。

它相当于下面这样:

14.1 传参
格式如下:
A:=123
#定义和实现
define FUNC1
echo $(1) $(2)
endef
all:
#调用函数
$(call FUNC1,abc,def)
上面的输出结果是abc def。函数FUNC1,用$(1) $(2)来接收参数。
A:=123
define FUNC1
echo $(1) $(2)
endef
all:
$(call FUNC1,abc,def,gh)
如果你像上面这样写也不会报错,只不过没有输出第三个参数而已。
A:=123
define FUNC1
echo $(1) $(2) $(3)
endef
all:
$(call FUNC1,abc,def)
像上面这样写也不会报错,就是$(3)为空而已。
需要注意的就是,函数中的$(0)是它自己的函数名。
A:=123
define FUNC1
echo $(0)
endef
all:
$(call FUNC1,abc,def)
#输出FUNC1
15. make install的实现
一般会有以下三个命令:
- make:将源文件编译成二进制可执行文件(包括各种库文件);
- make install:install是Makefile中的一个目标。
- 创建目录,将可执行文件拷贝到指定目录(安装目录);
- 加入全局可执行的路径;
- 加入全局的启停脚本;
- make clean:重置编辑环境,删除无关文件;
//006_main.cpp
#include<iostream>
#include<unistd.h>
using namespace std;
int main(){
int i=0;
while(true){
i++;
cout<<"006-main-running-"<<i<<endl;
sleep(1);
}
return 0;
}
//前置条件:在006文件夹下有006_main.cpp
TARGET:=006_main
OBJ:=$(TARGET).o
.PHONY=clean install
CC=g++
#用来存放可执行文件的目录
PATH:=/tmp/006_main/
#用于存放系统默认安装的路径,系统的环境变量会来该目录检索
BIN:=/usr/local/bin/
#不写具体命令,则依赖和目标,make都会自动推导后生成
$(TARGET):$(OBJ)
install:$(TARGET)
if [ -d $(PATH) ];\ #判断指定的目录路径是否存在且是一个目录
then echo $(PATH) exist;\
else\
/bin/mkdir $(PATH);\
/bin/cp $(TARGET) $(PATH);\
/bin/ln -sv $(PATH)$(TARGET) $(BIN);\ #在指定的链接路径($(BIN))创建指向目标文件的路径和名称($(PATH)$(TARGET))软连接(-s表示创建软连接)
fi; #结束 if 语句
clean:
$(RM) $(TARGET) $(OBJ)
$(RM) -rf $(PATH)
上面代码基本就已经将源文件编译成可执行文件、将可执行文件放到指定目录、可以在任何一个目录中去执行./006_main(也就是实现了全局可执行),还有就是实现了重置编译环境。
就差一个全局的启停脚本了。
TARGET:=006_main
OBJ:=$(TARGET).o
.PHONY=clean install
CC=g++
PATHS:=/tmp/006_main/
BIN:=/usr/local/bin/
START_SH:=$(TARGET)_start
STOP_SH:=$(TARGET)_stop
$(TARGET):$(OBJ)
install:$(TARGET)
if [ -d $(PATH) ];\
then echo $(PATHS) exist;\
else\
mkdir $(PATHS);\
cp $(TARGET) $(PATHS);\
ln -sv $(PATHS)$(TARGET) $(BIN);\
#将$(TARGET)重定向输出到$(START_SH)
echo $(TARGET)>$(PATHS)$(START_SH);\
#将"killall $(TARGET)"字符串重定向输出到$(START_SH)
echo "killall $(TARGET)">$(PATHS)$(STOP_SH);\
#修改$(START_SH)文件权限为可执行
chmod a+x $(PATHS)$(START_SH);\
chmod a+x $(PATHS)$(STOP_SH);\
ln -sv $(PATHS)$(START_SH) $(BIN);\
ln -sv $(PATHS)$(STOP_SH) $(BIN);\
fi;
clean:
$(RM) $(TARGET) $(OBJ) $(BIN)$(TARGET) $(BIN)$(START_SH) $(BIN)$(STOP_SH)
$(RM) -rf $(PATHS)
在上面代码中,echo $(TARGET)>$(PATHS)$(START_SH);表示把可执行文件006_main写入启动脚本(006_main_start)中,启动脚本也是可执行文件(因为我们执行了chmod a+x $(PATHS)$(START_SH);),所以当我们在终端中执行006_main_start时,就相当于执行006_main。echo "killall $(TARGET)">$(PATHS)$(STOP_SH);也同理,就是执行终止当前的006_main进程。



![[unity]多脚本情况下update函数的执行顺序](https://img-blog.csdnimg.cn/92ff06b432f945e7812bdca850ffa916.png)