模型可解释性
- 前言导读
- Background
- 1、为什么需要可解释性?
- 2、诞生背景
- 3、研究现状
- 4、常见的模型可解释性方法
- 4.1 基于模型自身的可解释性
- 1)Explanation Generation
- 2)Prototype Network
- 4.2 基于结果的可解释性
- 5、应用前景
- 6、面临挑战
前言导读
无论在学术界还是工业界,模型可解释性目前都还是一个相当新的领域。本文用综述的形式对模型可解释性做一个总体介绍,帮助大家了解什么是模型的可解释性,以及它诞生的背景是什么样的,我们为什么需要模型的可解释性;然后对模型可解释性领域的发展过程和现状做一个介绍,包括模型可解释性领域有哪些研究工作,不同的流派和它们的代表性思路;最后会分享我们对这个领域的发展趋势以及应用所面临的挑战的一些思考。
Background
机器学习模型可解释性方面的研究,在近两年的科研会议上成为一个相当热门的话题。随着机器学习应用越来越广泛,大家不再仅仅满足于模型的效果,而是希望对模型效果背后的原因有更好的理解。同时,在工业界落地 AI 时,构建能让用户理解的模型也变得越来越重要,在医疗、金融和司法等高风险应用中,这一点尤其明显。只有可被解释的机器学习模型,才可能被更广泛地采纳,并避免歧视性预测和对决策系统的恶意攻击。但目前模型可解释性的研究仍处于非常早期的阶段,距离应用尚需时日。
本文由 InfoQ 整理自阿里巴巴达摩院智能服务事业部算法专家邱天在 AICUG 线上直播公开课上的分享,希望能够帮助读者更好地了解模型可解释性领域的发展现状。
【原文链接】https://www.infoq.cn/article/xiytqjiic5spsp04adk9
1、为什么需要可解释性?
随着黑箱机器学习模型越来越多地被用于在关键环境中进行重要的预测,人工智能的各个利益相关者对透明度的要求越来越高。黑盒模型的风险在于做出和使用的决策可能不合理、不合法,或者无法对其行为进行详细的解释。
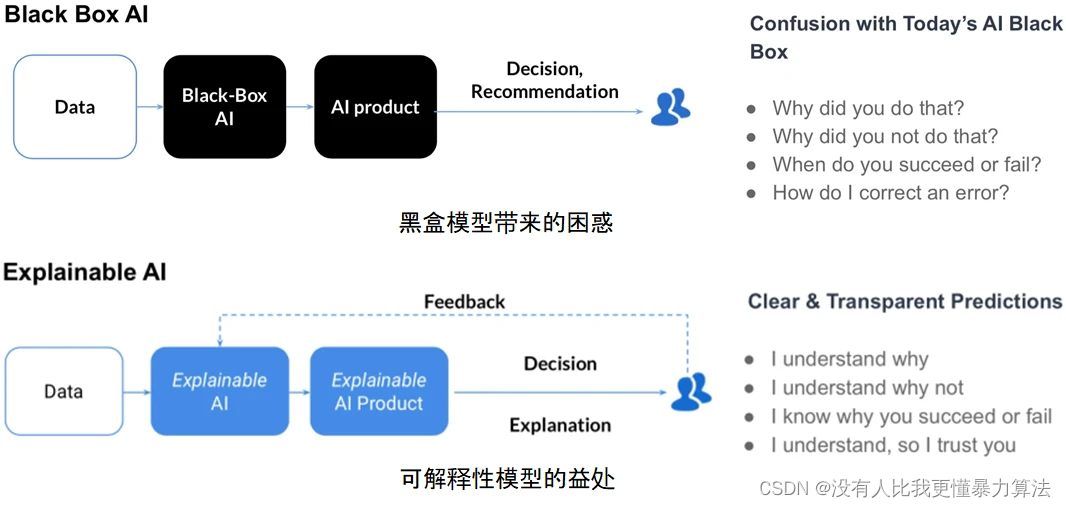
在很多领域,模型的可解释性都十分有必要。例如,在精准医疗中,为了支持诊断,专家需要从模型中获得远比简单的二元预测结果多得多的信息。在自动驾驶汽车,以及交通、安全、金融等关键领域,AI 算法模型也需要是可解释的。
近几年,模型可解释性概念越来越火,相关论文文献的数量也是这两年开始暴增。但这是否意味着我们过去一直没有可解释性呢?其实并不是。
2、诞生背景
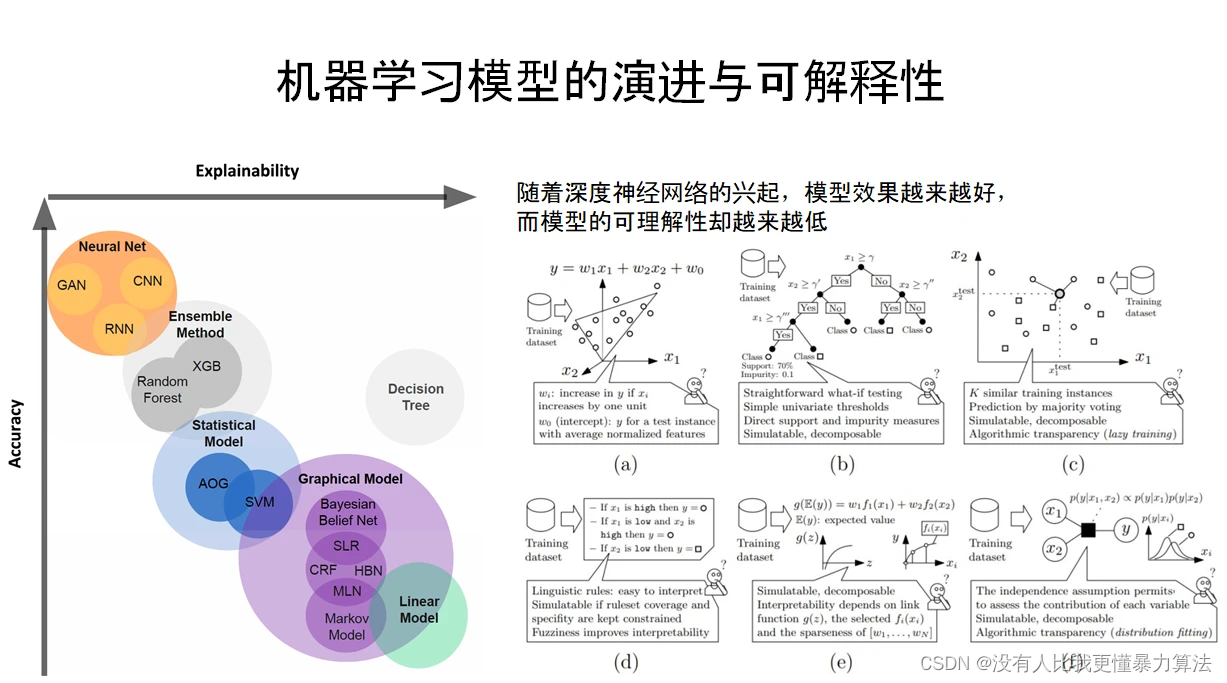
最早的人工智能系统,如上图右侧图(a)的线性模型,其实是很容易解释的。因为线性模型本身涉及的权重很少,而且非常直观,每个权重的大小就意味着对应的特征可以对最后的结果产生多大的贡献。但是过去几年我们见证了不透明决策系统的兴起,比如深度神经网络(DNNs)。深度学习模型(如 RNN、BERT)的成功源于高效的学习算法及其巨大的参数空间的结合,一个参数空间可能由数百层和数百万个参数组成,这使得 DNNs 被认为是复杂的黑盒模型。
随着算力越来越强,算法模型变得越来越复杂、体积也越来越大,我们已经很难解释这些模型了,虽然它的能力确实很强,能够帮我们做越来越多的事情,甚至在很多特定任务上表现超过人类,但是我们越来越无法理解这些模型了,这是一个很棘手的问题。所谓的可解释性,就是希望寻求对模型工作机理的直接理解,打破人工智能的黑盒子。
3、研究现状
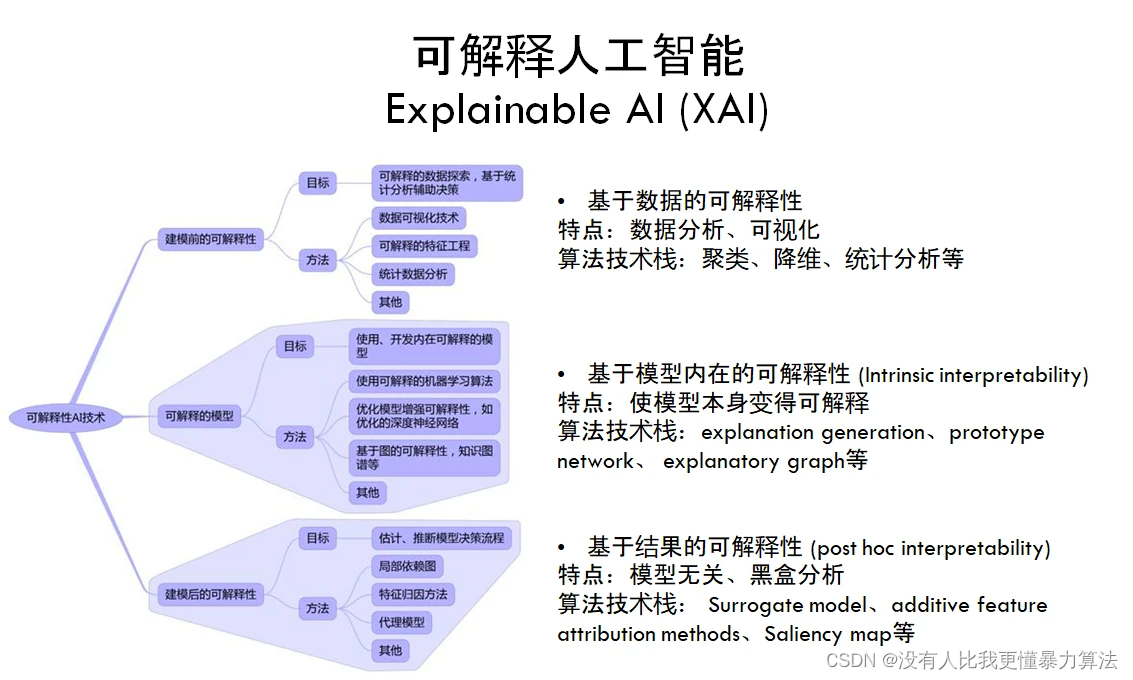
可解释人工智能技术大致可分为三大类,它们有各自的算法技术栈:
- 第一类是基于数据的可解释性,是我们最容易想到的一种方法,也是很多论文里面经常涉及的一类技术;
- 第二类是基于模型的可解释性,这类方法主要是在探讨能不能让模型本身就具有可解释性,模型自身就能告诉我们为什么要这么做;
- 第三类是基于结果的可解释性,思路是直接将现有的模型当作一个黑盒去看待,我们自己给一些输入输出,通过观察模型的行为,去推断出它到底为什么会产生这样的一个结果,我们自己去建模它的可解释性,这种思路的好处是完全对模型无关,什么模型都可以用。
当前在各个顶会上讨论得更多的是后两类,接下来重点介绍这两类方法的典型算法和思路。
4、常见的模型可解释性方法
目前比较常见的模型可解释性方法包括可视化、消融实验(Ablation study)和对输入输出的静态分析等。
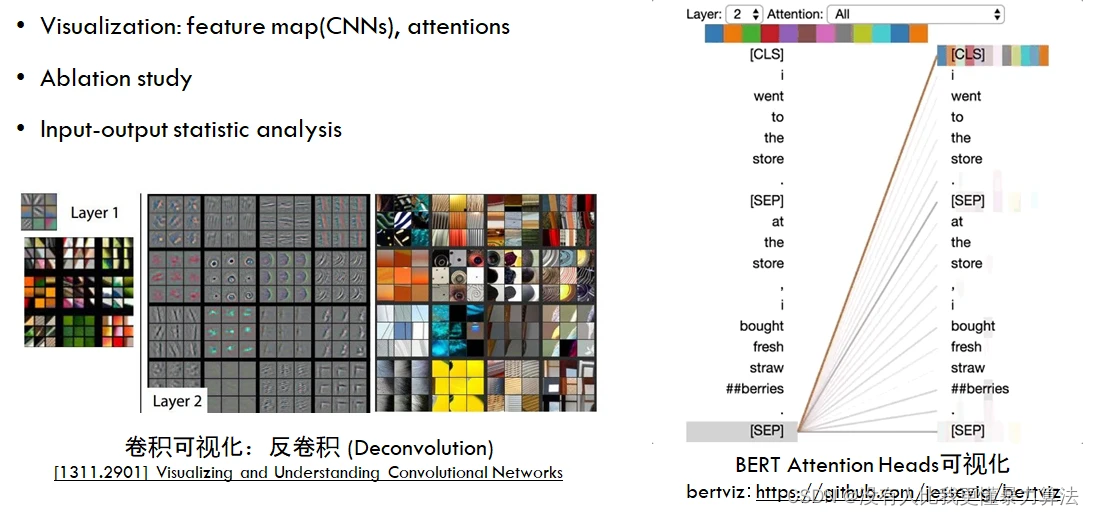
可视化解释不仅能够帮我们调试代码,发现黑盒子神经网络在做某种决策时所犯的明显错误,从而帮助改进模型,还可以寻找输入图片中对最终决策起至关重要的因素,实现知识发现。图右是对于 Attention 的可视化,也是比较经典的一个例子,我们可以把 BERT、Transformer 等这些流行的自然语言处理模型一点点地拆解开,看看里面的这些 Attention 到底是怎么工作的,这是一个比较有意思的实现方式。
4.1 基于模型自身的可解释性
模型自身的可解释性:把模型本身变成一个可解释的模型,它自己能说话,不只是给出单纯的答案,还能给出得到这个答案的理由,可以让研究人员对模型本身有更多的把握。
Explanation Generation 和 Prototype Network是两种经典方法,前者是让模型自己产生可解释的输出,后者则是让模型的思考方式跟人类更接近。
1)Explanation Generation
典型的例子是 VQA explanation,即在训练模型的同时训练一个语言的解释器。我们向模型提问,并给模型提供一些多模态的输入(比如图像或视频),模型给出输出结果的同时,让模型对给出的输出结果做进一步的解释,以帮助我们更好地了解模型是否真的理解了我们的意思,而不是怀疑模型恰好“猜”对了答案。
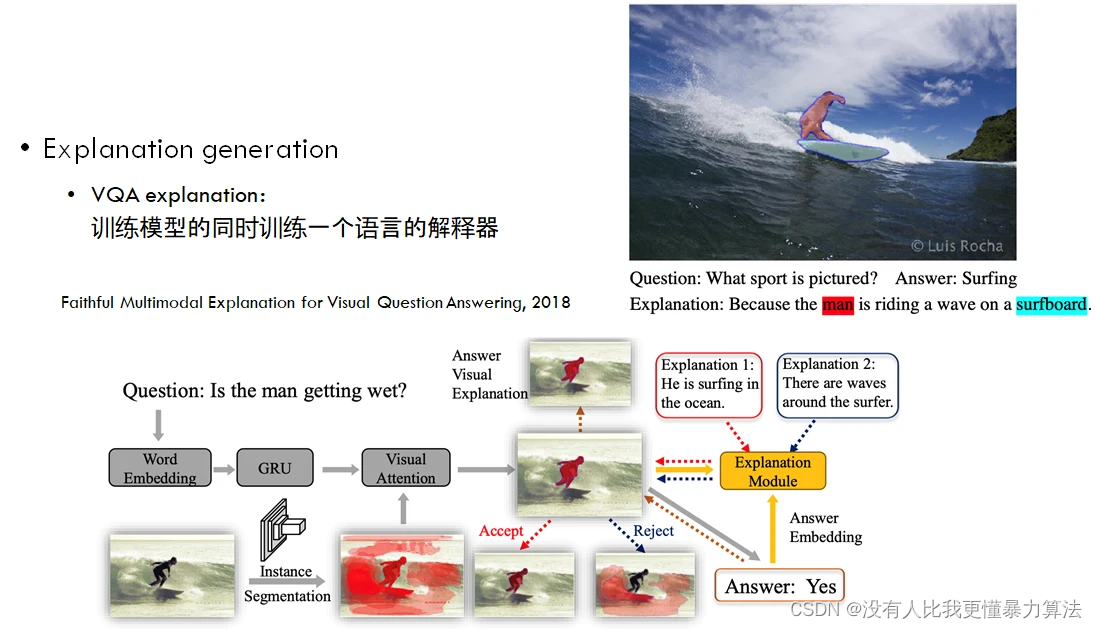
假设我们输入右上角的图片,Question 是 What sport is pictured?也就是问这个模型,这张图在描述一个什么样的运动。模型需要做出回答,Answer:Surfing,回答这是在冲浪,回答对了。这时候我们会想,模型确实回答对了,但是它是怎么回答对的呢?它是因为看到这有一片海所以说是冲浪,还是说看到背后有白云所以说是冲浪,还是说真的看到这有个人站在冲浪板上,它才觉得是冲浪呢?对于模型推断的过程我们是有怀疑的,因为我们不知道它是怎么工作的,这时候就要用到模型可解释性的方法,也就是 VQA explanation。
VQA explanation 要求模型不仅输出 Answer,还要输出一个 Explanation,比如模型给出这么一个解释 Because the man is riding a wave on a surfboard,因为这个人站在冲浪板上冲浪,所以这张图片上的运动是 Surfing。这跟我们自身对于这个图片的理解就是吻合的,同时模型还能把具体的实体跟图像里面的像素区域做高亮显示,说明它确实理解了图像中的人和冲浪板,并把这些实体结合起来,以及连贯整个行为之后推理出来说,这个图片上的运动应该理解成 Surfing。通过应用 VQA explanation 的方法,我们可以将模型变得更可靠,即使模型推理错了,我们也能知道为什么出错。
有时候,就算我们把模型一层层拆解开,也还是无法很直观地了解到,它为什么最后得出了这个结论。因为模型最后得出结论的方式,跟人类看一个问题的思维方式,其中的 Gap 太大了。就算我们真的把每个模型的模块都解析出来并可视化,也不一定能够理解得很清楚。
原文《Faithful Multimodal Explanation for Visual Question Answering》
2)Prototype Network
Prototype Network 的思路是,在模型设计的时候,就让模型的构造出的数据处理加工的方式和人类的思考方式相似,这样它产生结果之后,我们反过来去看这个模型的工作方式,就能很好地理解为什么给出了这么一个结果。
以《This Looks Like That: Deep Learning for Interpretable Image Recognition》这项工作为例,简单解释实现过程。这篇论文的核心任务目标是对鸟类图像做分类。那么人是怎么对鸟类做分类的呢?我们会有一些特定的方法论,比如要看它的嘴是什么样子的,爪子是什么样子的,羽毛是什么样子的,翅膀是什么样子的,通过把这几个特征组合起来去判断这属于什么鸟类。论文提出了原型的概念,把对图像的判断机制拆解为人类思维方式中的各种原子能力,根据人判断的机理来分类图像。在设计模型的时候,让它用跟人类思考类似的方式,通过分解图像得到不同的原型部分,比如先对鸟的嘴、爪子、羽毛逐一判断,再通过组成这些信息最终得到正确的分类。
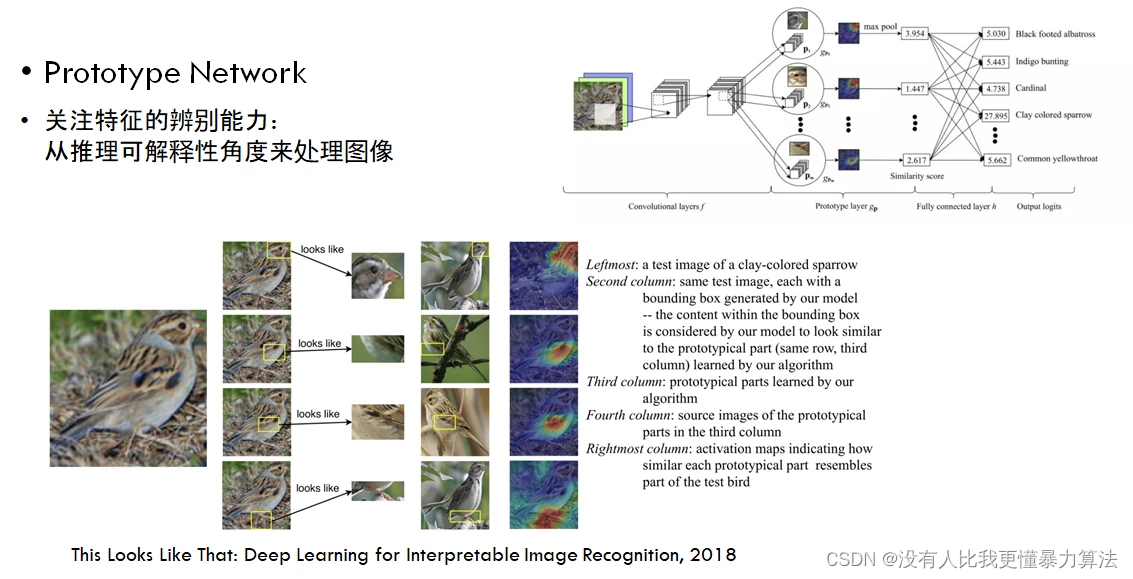
原文《This Looks Like That: Deep Learning for Interpretable Image Recognition》
4.2 基于结果的可解释性
基于结果的可解释性,或者叫事后可解释性,它指的是模型已经是训练好的成品了,事后尝试解释为什么这个模型是这样工作的。
基本思路:仍然把深度模型看成是一个黑盒子,不去打开它,或者说不会去显式地做拆解,而是通过假设和检验去观察这个模型,再去推测这个模型可能是怎么工作的。通过不断地假设检验给出结论,这个结论会慢慢变得越来越符合模型实际的工作方式,通过不断地逼近,最终给出一个合理的解释。这种做法的好处是跟模型无关,适合于任意模型,当然目前也存在一些缺点,后面提到。
方法举例:代理模型的方法(surrogate model),在模型局部采用一种简单可解释的模型去近似原有的黑盒模型,当精度足够逼近的时候,就可以用代理模型来解释原黑盒模型,这里我们列举两种产生代理模型的算法,分别是 LIME 算法和 SHAP 算法。

LIME 算法的思路可以简化理解成:尝试用一个比较容易解释的简单的模型(比如线性模型)去逼近、拟合原来比较复杂且不好理解的深度模型,如果能产生一个跟原来的复杂模型结果近似的模型,那这个简单模型的表征状态,就可以用来解释原来的模型。当然 LIME 算法不会把整个模型进行线性的降维,因为这样做不现实,它是假设局部可线性化,把一个模型做无限的拆解,拆解到每个局部点,再对每个点用一个局部的线性模型或简单模型进行近似,一旦局部跟一个简单的线性模型之间产生了近似的拟合关系,就可以用简单模型去解释这个局部,局部得到解释之后,整体也就可以解释了。
- LIME 算法:https://arxiv.org/abs/1602.04938
- SHAP 算法:https://arxiv.org/abs/1705.07874
5、应用前景
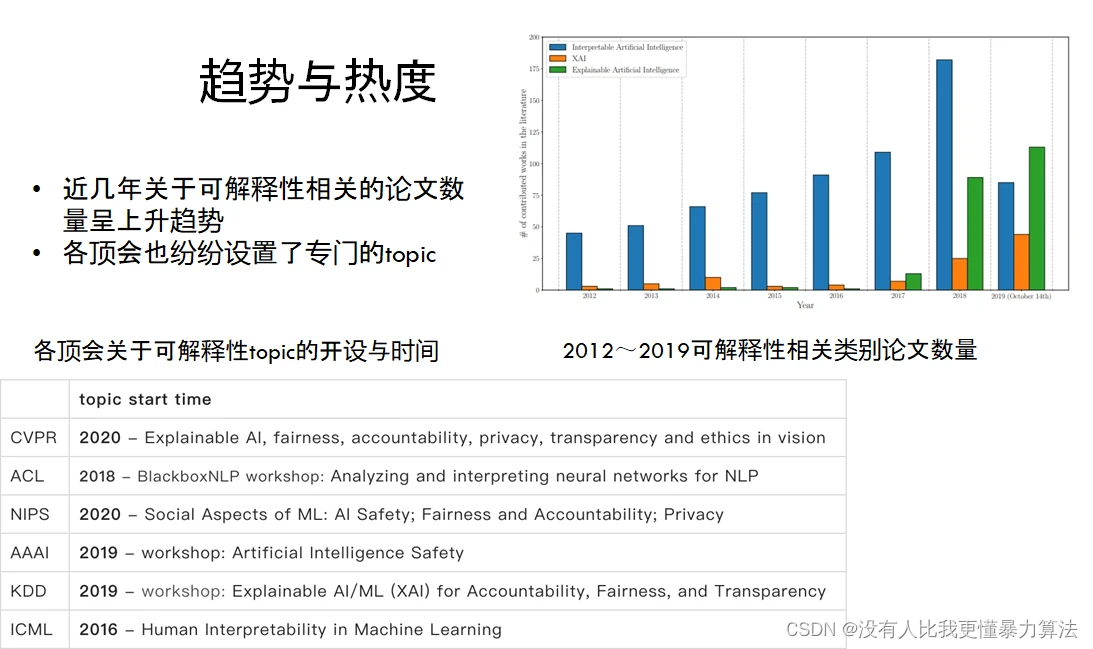
可以看到,过去几年可解释性相关的论文数量呈逐年上升趋势,各个领域的国际顶会都纷纷开设了可解释性的 Topic。解释 AI 模型的技术兴趣在 2018 年左右开始渗透到整个研究领域。我们认为可解释性能够更好地推动深度学习、人工智能在整个业界的应用,它可以带来以下好处:
- 可信赖。可解释性能够让模型变得更加可信赖,尤其是对于非技术工作人员,有助于推动深度学习在金融、交通、安全等关键领域的大规模应用,是人工智能在各行各业落地的重要基础。
- 公平性。当前人工智能、深度学习大部分都依赖于大数据,而大数据本身是来源于人的,其中难免存在偏差(bias),机器对这些存在偏差的数据进行学习的时候,也会把偏差学进去,但这些偏差并不是我们想要的。我们希望模型本身能够抵抗这些偏差,而不是单纯的去模拟数据的偏差,比如在金融风控领域,模型可能对于特定性别、特定地域来源、特定年龄的人的判别存在偏差。如果能够让模型本身可解释、可理解,我们就能够把偏差纠正过来,让它变得更公平。
- 可转移性。我们现在经常提迁移学习(Transfer Learning),就是把模型从一个领域迁移到另一个领域。如果模型是个黑盒子,我们不清楚它具体是怎么工作的,就很难清晰地界定模型迁移的边界在哪里,哪里可用、哪里不可用,这些都无从知晓。如果我们能够对模型有更深的了解,就可以更好地把模型模块化,进而更好地对模型进行无缝的迁移,迁移学习的领域运用也会更加的广阔。
- 高效率。假设 AI 产品部署之后出现 Bug,如果模型是个黑盒,我们就无法知道它是如何工作的,自然也不可能知道 Bug 出在哪里,只能用小修小补的方式把 Bug 屏蔽掉,而不能真正地解决问题。如果模型可解释,我们就可以更快速地定位和修正 badcase。
- 多样性:模型可解释可以推动生成模型的广泛应用。以阿里小蜜为例,它是一个会话机器人,目前一些生成模型技术(如括文本生成)已经相当成熟了,能够给我们提供一些比较好的生成结果,如果我们将生成模型应用到会话机器人中,可以提供比传统的检索方法更好的个性化回答服务,对于会话服务的整体质量会有很好的提升。可是我们却没办法这么用,为什么呢?因为工业界应用对模型可靠性有一定的要求,但生成模型一个比较大的问题在于它是不可控的,特别是深度的生成模型,我们根本无法控制输入一个问题之后它会给出一个什么样的回答,可能导致实际应用中出现各种意外情况。这就需要我们对模型有更深层次的把握,能够更好地理解生成模型是怎么工作的、怎么在一定程度上控制它,这之后才能够让模型更好地应用起来。
6、面临挑战
- 挑战 1:算法成熟度
对于两类代表性的模型可解释性
1)模型自身的可解释性,其本身跟模型强绑定,需要根据模型和应用场景一对一地进行迭代,才能够让它产生可解释性,通用性非常受限,修改的难度也比较大。
2)基于结果的可解释性,虽然能把它看成一个黑盒子,但目前算法本身还存在一些问题。比如 LIME 算法,因为它是一种近似,它对于采样有一定依赖,导致结果不稳定。不过算法本身的问题也在不断迭代改进,LIME 算法是 2016 年提出来的,现在 Linkedin 又提出了 xLIME 算法,针对 LIME 存在的问题做了一些改进。通过工业界和学术界一步一步地探索,相信这些算法会变得越来越好,离大规模应用也会越来越近。
- 挑战 2:算力成本
挑战2跟挑战1是紧密相关的。基于结果的可解释性方法对采样有依赖,结果也不太稳定,那对一部分可以工作的比较好的模型,我们总可以用了吧?但我们发现要真正用起来还有一个问题:对于目前的算法,包括 LIME 也好、SHAP 也好,它本身的算法复杂度还是太高。一篇 200 字段落的 MRC,通过 SHAP 算法基于模特卡洛抽样也需要迭代超过 5000 次,耗时数小时,才能较好地拟合一个样本。假设有几万篇样本,那得算到什么时候呢?解决的办法一方面是优化算法,降低复杂度,另一方面是继续提升算力。 - 挑战 3:数据稀疏
对于模型自身可解释性方法,需要训练出模型的解释器,这往往是一个有监督的训练过程,意味着需要大量的样本和大量的标注它才能够最后给出自身的解释。但工业界现在并没有这么大量的对于可解释性的额外的数据标注,如果我们用人工的方法进行海量数据标注,成本非常高,甚至是不可承担的。一种可能的方式是,借助无监督或者半监督的方法,把我们自身已经有的一些算法的数据标注运用起来,让它产生可解释性,这是最合理或者说最可能行得通的一种方法。