1引言:
2.实例化过程
CREATE TABLE table_name (
column1 datatype constraint,
column2 datatype constraint,
...
PRIMARY KEY (column1),
INDEX index_name (column2, column3)
);
其中,table_name 是要创建的表的名称,column1, column2, ... 是表的列名,datatype 是列的数据类型,constraint 是列的约束条件。
要创建联合索引,可以使用 INDEX 关键字,后面跟着索引的名称和要包含在索引中的列名。在创建联合索引时,列名之间使用逗号分隔。
最左匹配原则是指在联合索引中,索引会按照列的顺序进行排序,并且查询时只能使用索引的最左边的列开始匹配。这意味着如果查询中的条件不包含索引的最左边的列,那么索引将无法被使用。
例如,假设有一个名为 users 的表,包含以下列:id, first_name, last_name, email。我们想要创建一个联合索引,包含 first_name 和 last_name 列:
CREATE TABLE users (
id INT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(100),
INDEX name_index (first_name, last_name)
);
让我们在上面创建的 users 表中插入一些数据来验证最左匹配原则。
INSERT INTO users (id, first_name, last_name, email) VALUES
(1, 'John', 'Doe', 'john.doe@example.com'),
(2, 'Jane', 'Smith', 'jane.smith@example.com'),
(3, 'John', 'Smith', 'john.smith@example.com'),
(4, 'Jane', 'Doe', 'jane.doe@example.com');
上述语句将向 users 表中插入四条数据。现在,我们可以使用不同的查询条件来验证最左匹配原则。
查询条件包含索引的最左边的列:
SELECT * FROM users WHERE first_name = 'John' AND last_name = 'Doe';
这个查询将返回 id=1 的记录,因为查询条件完全匹配了索引的最左边的列。
SELECT * FROM users WHERE first_name = 'John' AND last_name = 'Smith';
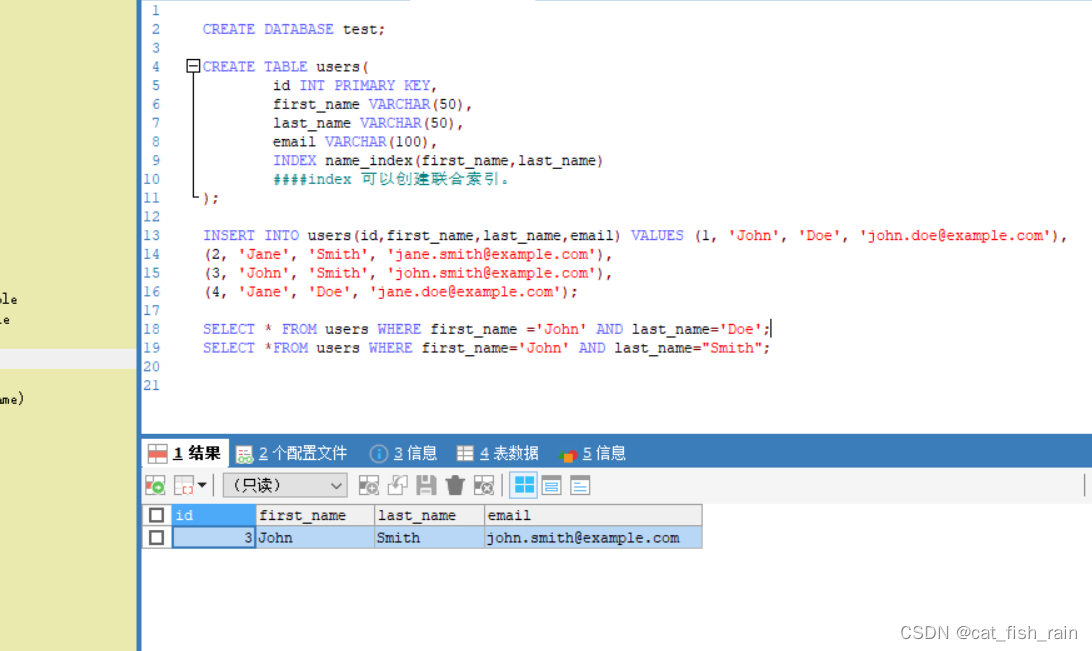
id=3 的记录,因为查询条件完全匹配了索引的最左边的列和第二个列。
SELECT * FROM users WHERE last_name = 'Doe';
这个查询将无法使用索引,因为查询条件没有包含索引的最左边的列。它将执行全表扫描,返回所有满足 last_name = 'Doe' 的记录。
通过以上示例,我们可以看到最左匹配原则的效果。只有当查询条件包含索引的最左边的列时,索引才能被充分利用,加速查询。否则,索引将无法被使用,查询将变得较慢。
3.说明
select * from t where a=1 and b=1 and c =1; #这样可以利用到定义的索引(a,b,c),用上a,b,c select * from t where a=1 and b=1; #这样可以利用到定义的索引(a,b,c),用上a,b select * from t where b=1 and a=1; #这样可以利用到定义的索引(a,b,c),用上a,c(mysql有查询优化器) select * from t where a=1; #这样也可以利用到定义的索引(a,b,c),用上a select * from t where b=1 and c=1; #这样不可以利用到定义的索引(a,b,c) select * from t where a=1 and c=1; #这样可以利用到定义的索引(a,b,c),但只用上a索引,b,c索引用不到
值得注意的是,当遇到范围查询(>、<、between、like)就会停止匹配。也就是:
select * from t where a=1 and b>1 and c =1; #这样a,b可以用到(a,b,c),c索引用不到
这条语句只有 a,b 会用到索引,c 都不能用到索引。这个原因可以从联合索引的结构来解释。
但是如果是建立(a,c,b)联合索引,则a,b,c都可以使用索引,因为优化器会自动改写为最优查询语句。
select * from t where a=1 and b >1 and c=1; #如果是建立(a,c,b)联合索引,则a,b,c都可以使用索引 #优化器改写为 select * from t where a=1 and c=1 and b >1;
这也是最左前缀原理的一部分,索引index1:(a,b,c),只会走a、a,b、a,b,c 三种类型的查询,其实这里说的有一点问题,a,c也走,但是只走a字段索引,不会走c字段。
另外还有一个特殊情况说明下,select * from table where a = '1' and b > ‘2’ and c='3' 这种类型的也只会有 a与b 走索引,c不会走。
像select * from table where a = '1' and b > ‘2’ and c='3' 这种类型的sql语句,在a、b走完索引后,c肯定是无序了,所以c就没法走索引,数据库会觉得还不如全表扫描c字段来的快。
以index (a,b,c)为例建立这样的索引相当于建立了索引a、ab、abc三个索引。一个索引顶三个索引当然是好事,毕竟每多一个索引,都会增加写操作的开销和磁盘空间的开销。