ORDER BY子句用于对查询结果进行排序 .
它可以按照一个或多个列的值进行升序或降序排序 .
在SELECT语句中 , ORDER BY子句应该位于结尾 , 其基本语法如下 :
SELECT 字段 1 , 字段 2 , . . .
FROM 表名
ORDER BY 列名 1 [ ASC|DESC ] , 列名 2 [ ASC|DESC ] , . . .
其中 , ASC ( ascend ) : 表示升序 ( 默认 ) , DESC ( descend ) 表示降序 ; 排序的字段可以使用别名 .
mysql> SELECT last_name, job_id, department_id, hire_date
- > FROM employees
- > ORDER BY hire_date ;
+
| last_name | job_id | department_id | hire_date |
+
| King | AD_PRES | 90 | 1987 - 06 - 17 |
| Whalen | AD_ASST | 10 | 1987 - 09 - 17 |
| Kochhar | AD_VP | 90 | 1989 - 09 - 21 |
| . . . | . . . | 00 | . . . |
| Ande | SA_REP | 80 | 2000 - 03 - 24 |
| Banda | SA_REP | 80 | 2000 - 04 - 21 |
| Kumar | SA_REP | 80 | 2000 - 04 - 21 |
+
107 rows in set ( 0.00 sec)
mysql> SELECT last_name, job_id, department_id, hire_date
- > FROM employees
- > ORDER BY hire_date DESC ;
+
| last_name | job_id | department_id | hire_date |
+
| Banda | SA_REP | 80 | 2000 - 04 - 21 |
| Kumar | SA_REP | 80 | 2000 - 04 - 21 |
| . . . | . . . | 00 | . . . |
| Whalen | AD_ASST | 10 | 1987 - 09 - 17 |
| King | AD_PRES | 90 | 1987 - 06 - 17 |
+
107 rows in set ( 0.00 sec)
mysql> SELECT employee_id, last_name, salary * 12 AS "annsal"
- > FROM employees
- > ORDER BY annsal;
+
| employee_id | last_name | annsal |
+
| 132 | Olson | 25200.00 |
| 128 | Markle | 26400.00 |
| 136 | Philtanker | 26400.00 |
| 127 | Landry | 28800.00 |
| . . . | . . . | . . . |
| 205 | Higgins | 144000.00 |
| 201 | Hartstein | 156000.00 |
| 146 | Partners | 162000.00 |
| 145 | Russell | 168000.00 |
| 101 | Kochhar | 204000.00 |
| 102 | De Haan | 204000.00 |
| 100 | King | 288000.00 |
+
107 rows in set ( 0.00 sec)
在对多列进行排序的时候 , 首先排序的第一列必须有相同的列值 , 才会对第二列进行排序 .
如果第一列数据中所有值都是唯一的 , 将不再对第二列进行排序 .
mysql> SELECT last_name, department_id, salary
- > FROM employees
- > ORDER BY department_id, salary DESC ;
+
| last_name | department_id | salary |
+
| Grant | NULL | 7000.00 |
| Whalen | 10 | 4400.00 |
| . . . | . . | . . . |
| Bull | 50 | 4100.00 |
| Bell | 50 | 4000.00 |
| . . . | . . | . . . |
| Gietz | 110 | 8300.00 |
+
107 rows in set ( 0.00 sec)
需求背景 :
背景 1 : 查询返回的记录太多了 , 查看起来很不方便 .
背景 2 :表里有 4 条数据 , 只想要显示第 2 , 3 条数据 .
分页原理 : 将数据库中的结果集 , 按需要的条件一段一段显示出来 .
MySQL中使用LIMIT子句实现分页 , 语法格式 :
SELECT 字段 1 , 字段 2 , . . .
FROM 表名
ORDER BY 排序字段 1 , . . .
LIMIT [ offset, ] count ;
第一个 '位置偏移量' 参数指示MySQL从哪一行开始显示 , 是一个可选参数 , 如果不指定 '位置偏移量' ,
将会从表中的第一条记录开始 ( 第一条记录的位置偏移量是 0 , 第二条记录的位置偏移量是 1 , 以此类推 ) ;
第二个参数 '行数' 指示返回的记录条数 .
注意 : LIMIT子句必须放在整个SELECT语句的最后 !
例 :
获取表中前 10 条记录 : SELECT * FROM 表名 LIMIT 0 , 10 ; 或者 SELECT * FROM 表名 LIMIT 10 ;
获取表中第 11 - 20 条记录 : SELECT * FROM 表名 LIMIT 10 , 10 ;
获取表中第 21 - 20 条记录 : SELECT * FROM 表名 LIMIT 20 , 10 ;
分页显式公式 : ( 当前页数 - 1 ) * 每页条数 , 每页条数 ;
SELECT * FROM table LIMIT ( PageNo - 1 ) * PageSize , PageSize ;
* MySQL8 . 0 新特性 : LIMIT count OFFSET offset ; 使用OFFSET子句后行数在前 , 偏移量在后 .
mysql> SELECT employee_id, first_name FROM employees LIMIT 1 ;
+
| employee_id | first_name |
+
| 100 | Steven |
+
1 row in set ( 0.00 sec)
mysql> SELECT employee_id, first_name FROM employees LIMIT 1 , 1 ;
+
| employee_id | first_name |
+
| 101 | Neena |
+
1 row in set ( 0.00 sec)
mysql> SELECT employee_id, first_name FROM employees LIMIT 10 ;
+
| employee_id | first_name |
+
| 100 | Steven |
| 101 | Neena |
| 102 | Lex |
| 103 | Alexander |
| 104 | Bruce |
| 105 | David |
| 106 | Valli |
| 107 | Diana |
| 108 | Nancy |
| 109 | Daniel |
+
10 rows in set ( 0.00 sec)
mysql> SELECT employee_id, first_name FROM employees LIMIT 10 , 10 ;
+
| employee_id | first_name |
+
| 110 | John |
| 111 | Ismael |
| 112 | Jose Manuel |
| 113 | Luis |
| 114 | Den |
| 115 | Alexander |
| 116 | Shelli |
| 117 | Sigal |
| 118 | Guy |
| 119 | Karen |
+
10 rows in set ( 0.00 sec)
mysql> SELECT employee_id, first_name FROM employees LIMIT 20 , 10 ;
+
| employee_id | first_name |
+
| 120 | Matthew |
| 121 | Adam |
| 122 | Payam |
| 123 | Shanta |
| 124 | Kevin |
| 125 | Julia |
| 126 | Irene |
| 127 | James |
| 128 | Steven |
| 129 | Laura |
+
10 rows in set ( 0.00 sec)
mysql> SELECT employee_id, first_name, salary FROM employees WHERE salary > 6000 ORDER BY salary DESC LIMIT 10 ;
+
| employee_id | first_name | salary |
+
| 100 | Steven | 24000.00 |
| 101 | Neena | 17000.00 |
| 102 | Lex | 17000.00 |
| 145 | John | 14000.00 |
| 146 | Karen | 13500.00 |
| 201 | Michael | 13000.00 |
| 108 | Nancy | 12000.00 |
| 147 | Alberto | 12000.00 |
| 205 | Shelley | 12000.00 |
| 168 | Lisa | 11500.00 |
+
10 rows in set ( 0.00 sec)
mysql> SELECT employee_id, last_name, salary FROM employees ORDER BY salary DESC LIMIT 1 ;
+
| employee_id | last_name | salary |
+
| 100 | King | 24000.00 |
+
1 row in set ( 0.00 sec
-- 显示员工表中第32, 33条数据的员工名字:
mysql> SELECT first_name FROM employees LIMIT 31, 2;
+------------+
| first_name |
+------------+
| James |
| TJ |
+------------+
2 rows in set (0.00 sec)
mysql> SELECT first_name FROM employees LIMIT 2 OFFSET 31 ;
+
| first_name |
+
| James |
| TJ |
+
2 rows in set ( 0.00 sec)
在深入探讨连表操作之前 , 有必要了解SQL的多个版本标准规范 , 因为不同的标准下 , 表连接操作存在细微的差异 .
在SQL的发展历程中 , 出现了众多标准 , 其中最受关注且被广泛应用的便是SQL92和SQL99 .
这些数字代表的是标准发布的年份 , SQL92即为 1992 年发布的标准规范 .
除了SQL92和SQL99之外 , SQL的发展历程中还出现了SQL- 86 , SQL- 89 以及后续的SQL : 2003 , SQL : 2008 , SQL : 2011 和SQL : 2016 等版本 .
然而 , 在如此多的标准中 , SQL92和SQL99被公认为最重要的两个版本 .
简单来说 , SQL92的形式更直观 , 但语句通常较长 , 导致可读性较差 .
相对而言 , SQL99的语法更为复杂 , 但其结构化的形式提高了可读性 .
从两者发布的页数也可看出其复杂性 : SQL92的标准内容约为 500 页 , 而SQL99的标准则超过了 1000 页 .
实际上 , 自SQL99之后 , 由于内容过于庞大 , 很少有人能够完全掌握所有细节 .
与我们使用Windows , Linux和Office等软件类似 , 大多数人只需要掌握满足日常工作需求的核心功能即可 .
SQL92和SQL99不仅是经典的SQL标准 , 也被称为SQL- 2 和SQL- 3 标准 .
随着这两个标准的发布 , SQL的影响力逐渐扩大 , 甚至超越了数据库领域的范畴 .
如今 , SQL不仅是数据库领域的主流语言 , 也成为了信息领域中信息处理的主流工具 .
在图形检索 , 图像检索 , 语音检索以及其他各种应用中 , 我们都能看到SQL语言的身影 .
因此 , 对于学习SQL的人来说 , 掌握SQL92和SQL99的基本概念和核心功能是非常必要的 ,
它们不仅可以满足日常工作的需求 , 也是进一步学习和理解SQL的基础 .
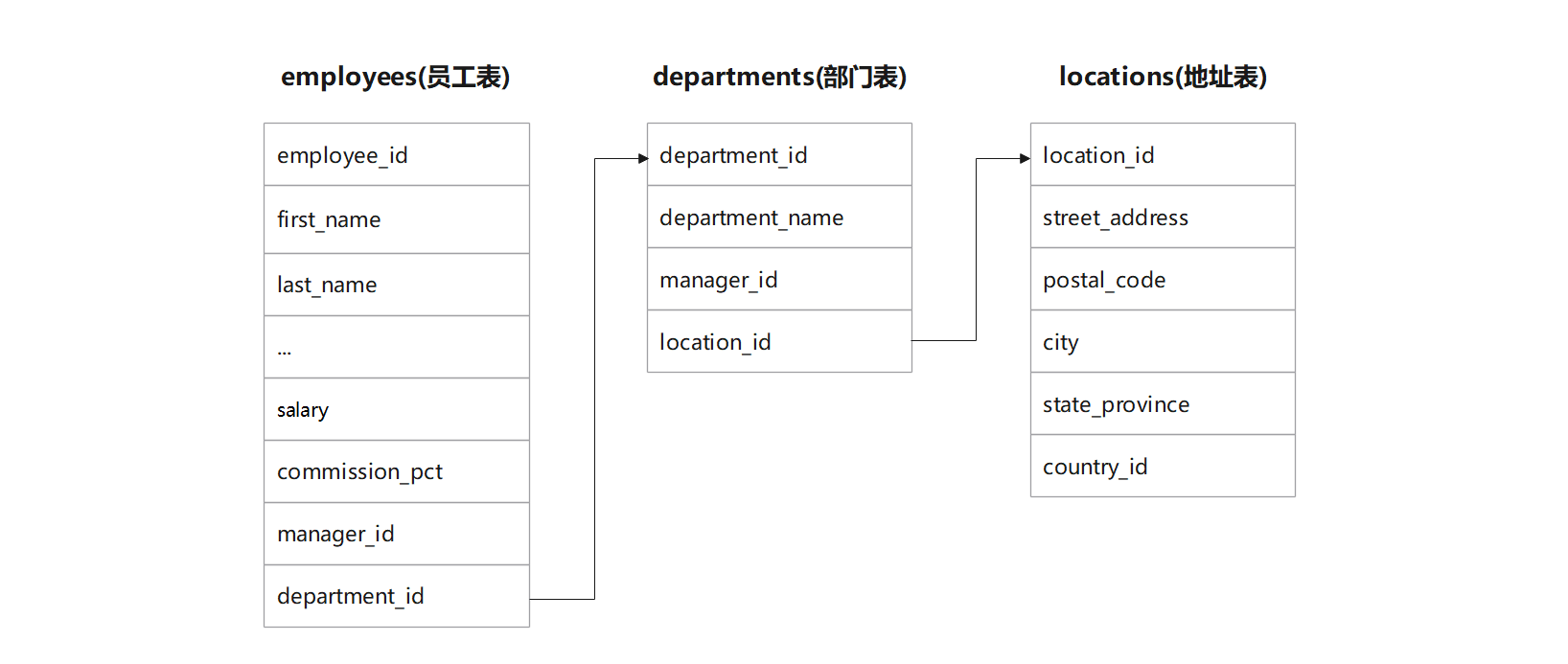
多表查询 ( 也称为关联查询或联结查询 ) : 是一种在数据库中使用的方法 , 用于从两个或多个相互关联的表中检索数据 .
这种方法允许用户根据表之间的关系来获取所需的信息 , 而这些信息可能分布在多个表中 .
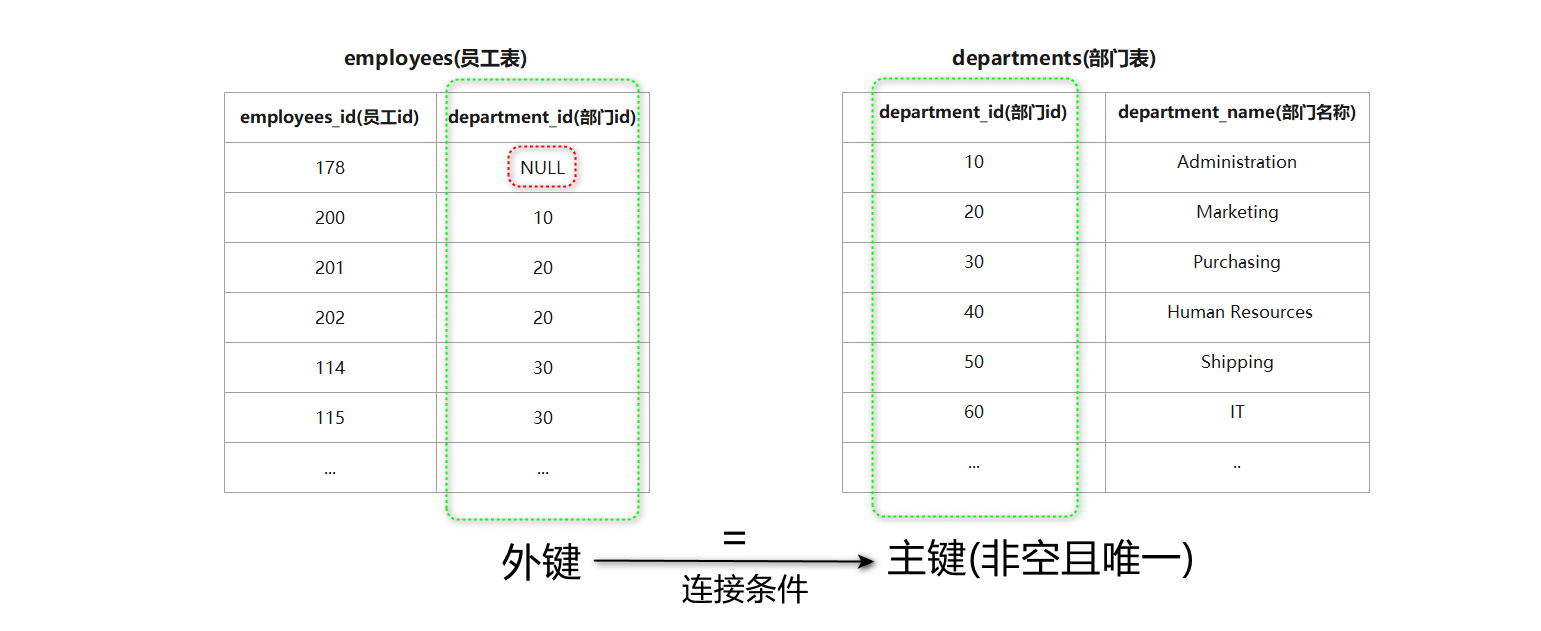
进行多表查询的前提条件是这些表之间存在某种关联关系 , 这种关联关系通常是通过外键来建立的 .
在一个表中 , 外键是指向另一个表中主键的字段 . 通过这种关联关系 , 可以将不同表中的数据连接起来 , 形成一个完整的结果集 .
mysql> DESC employees;
+
| Field | Type | Null | Key | Default | Extra |
+
| employee_id | int | NO | PRI | 0 | |
| first_name | varchar ( 20 ) | YES | | NULL | |
| last_name | varchar ( 25 ) | NO | | NULL | |
| email | varchar ( 25 ) | NO | UNI | NULL | |
| phone_number | varchar ( 20 ) | YES | | NULL | |
| hire_date | date | NO | | NULL | |
| job_id | varchar ( 10 ) | NO | MUL | NULL | |
| salary | double ( 8 , 2 ) | YES | | NULL | |
| commission_pct | double ( 2 , 2 ) | YES | | NULL | |
| manager_id | int | YES | MUL | NULL | |
| department_id | int | YES | MUL | NULL | |
+
11 rows in set ( 0.01 sec)
mysql> DESC departments;
+
| Field | Type | Null | Key | Default | Extra |
+
| department_id | int | NO | PRI | 0 | |
| department_name | varchar ( 30 ) | NO | | NULL | |
| manager_id | int | YES | MUL | NULL | |
| location_id | int | YES | MUL | NULL | |
+
4 rows in set ( 0.00 sec)
mysql> DESC locationS;
+
| Field | Type | Null | Key | Default | Extra |
+
| location_id | int | NO | PRI | 0 | |
| street_address | varchar ( 40 ) | YES | | NULL | |
| postal_code | varchar ( 12 ) | YES | | NULL | |
| city | varchar ( 30 ) | NO | | NULL | |
| state_province | varchar ( 25 ) | YES | | NULL | |
| country_id | char ( 2 ) | YES | MUL | NULL | |
+
6 rows in set ( 0.00 sec)
员工表通过 "部门id" 关联部门表 , 部门表通过 "地址id" 关联地址表 .
查询名字为 'Jack' 的工作的城市 .
查询方法 : 可以通过一张表一张表分步查询 .
* 1. 先从员工表中获取获取jack的部门id .
* 2. 拿着部门id去部门表获取地址id .
* 3. 最后通过地址id获取城市的名字 .
mysql> SELECT first_name, department_id FROM employees WHERE first_name = 'Jack' ;
+
| first_name | department_id |
+
| Jack | 80 |
+
1 row in set ( 0.03 sec)
mysql> SELECT department_id, location_id FROM departments WHERE department_id = 80 ;
+
| department_id | location_id |
+
| 80 | 2500 |
+
1 row in set ( 0.01 sec)
mysql> SELECT location_id, city FROM locations WHERE location_id = 2500 ;
+
| location_id | city |
+
| 2500 | Oxford |
+
1 row in set ( 0.01 sec)
当使用分步骤查询多张表时 , 每次查询只能获取一张表的数据 , 然后再通过条件去查询下一张表 , 以此类推 .
这样的处理方式 , 需要进行多次数据库查询操作 , 增加了数据库的负担 , 降低了查询效率 .
此外 , 分步骤查询还可能导致数据的冗余传输 , 即每次查询都需要将上一次查询的结果集传递给下一次查询 , 增加了数据传输的开销 .
连表查询 : 通过一定的连接条件将多个表进行关联查询的操作 .
隐式的交叉连接 ( implicit cross join ) : 是指在查询语句中直接使用逗号连接多个表的查询方式 .
这种查询语句将返回所有表的笛卡尔积 ( 有人也称它为笛卡尔积连接 ) ,
即将左侧表中的每一行与右侧表中的每一行进行组合 , 生成所有可能的组合结果 .
例如 , 假设有两个表A和B , 它们分别包含两列数据 , 如下所示 :
表 A :
列 1 | 列 2
----- | -----
1 | a
2 | b
表 B :
列 1 | 列 2
----- | -----
x | 10
y | 20
使用逗号进行隐式的交叉连接查询 :
SELECT 列 1 , 列 2
FROM A , B ;
将返回下列笛卡尔积形式的结果集 :
列 1 | 列 2
----- | -----
1 | a
1 | 10
1 | 20
2 | b
2 | 10
2 | 20
隐式的交叉连接会产生非常大的结果集 , 并且往往不是我们需要的结果 .
SELECT first_name, department_name FROM employees, departments;
mysql> SELECT first_name, department_name FROM employees, departments;
+
| first_name | department_name |
+
| Steven | Payroll |
| . . . | . . . |
| William | Administration |
+
2889 rows in set ( 0.03 sec)
笛卡尔积的错误会在下面条件下产生 :
* 1. 省略多个表的连接条件 ( 或关联条件 ) .
* 2. 连接条件 ( 或关联条件 ) 无效 .
* 3. 所有表中的所有行互相连接
为了避免笛卡尔积 , 可以在WHERE加入有效的连接条件 .
当多个表中具有相同列名时 , 需要使用表名前缀来区分不同表中的列名 .
在使用带有表名前缀的列名时 , 查询语句如下 :
SELECT table1 . column , table2 . column
FROM table1 , table2
WHERE table1 . column1 = table2 . column2 ;
使用了WHERE子句来指定连接条件 , 即table1 . column1 = table2 . column2 .
这个连接条件指定了如何将table1和table2中的数据组合在一起 .
注意 : 使用隐式连接时 , 如果不使用表名前缀指定列名 , 则可能会出现名字冲突 , 并且sql检查器可能无法确定需要连接哪些列从而产生错误 .
因此 , 使用表名前缀来指定列名是一种很好的习惯 .
mysql> SELECT first_name, department_name FROM employees, departments
- > WHERE employees. department_id = departments. department_id;
+
| first_name | department_name |
+
| Jennifer | Administration |
| Michael | Marketing |
| Pat | Marketing |
| Den | Purchasing |
| Alexander | Purchasing |
| . . . | . . . |
| John | Finance |
| Ismael | Finance |
| Jose Manuel | Finance |
| Luis | Finance |
| Shelley | Accounting |
| William | Accounting |
+
106 rows in set ( 0.01 sec)
mysql> SELECT first_name, department_id FROM employees WHERE department_id <=> NULL ;
+
| first_name | department_id |
+
| Kimberely | NULL |
+
1 row in set ( 0.01 sec)
mysql> SELECT employees. first_name, departments. department_name FROM employees, departments
WHERE employees. department_id = departments. department_id;
+
| first_name | department_name |
+
| Jennifer | Administration |
| Michael | Marketing |
| Pat | Marketing |
| Den | Purchasing |
| Alexander | Purchasing |
| . . . | . . . |
| John | Finance |
| Ismael | Finance |
| Jose Manuel | Finance |
| Luis | Finance |
| Shelley | Accounting |
| William | Accounting |
+
106 rows in set ( 0.00 sec)
mysql> mysql> SELECT manager_id, department_id FROM employees, departments
WHERE employees. department_id = departments. department_id;
ERROR 1052 ( 23000 ) : Column 'manager_id' in field list is ambiguous
mysql> SELECT employees. manager_id, employees. department_id, departments. manager_id, departments. department_id
FROM employees, departments
WHERE employees. department_id = departments. department_id;
mysql> SELECT employees. manager_id, employees. department_id, departments. manager_id, departments. department_id
- > FROM employees, departments
- > WHERE employees. department_id = departments. department_id;
+
| manager_id | department_id | manager_id | department_id |
+
| NULL | 90 | 100 | 90 |
| 100 | 90 | 100 | 90 |
| 100 | 90 | 100 | 90 |
| 102 | 60 | 103 | 60 |
| 103 | 60 | 103 | 60 |
| 103 | 60 | 103 | 60 |
| 103 | 60 | 103 | 60 |
| . . . | . . | . . . | . . |
| 149 | 80 | 145 | 80 |
| 101 | 10 | 200 | 10 |
| 100 | 20 | 201 | 20 |
| 201 | 20 | 201 | 20 |
| 101 | 40 | 203 | 40 |
| 101 | 70 | 204 | 70 |
| 101 | 110 | 205 | 110 |
| 205 | 110 | 205 | 110 |
+
106 rows in set ( 0.00 sec)
可以使用AS语句 ( 或者使用空格作为别名分隔符 ) 设置别名 , 使用表别名可以让查询语句更易读 , 易理解 .
表别名可以给每个表指定一个简短的名称 , 这样在查询语句中引用这些表时 , 可以使用简短的别名代替完整的表名 , 使查询语句更简洁明了 .
这样的查询语句更容易阅读 , 也更容易理解其含义 .
注意事项 :
* 1. 一旦为表设置了别名 , 就应该使用这个别名来引用这个表 , 而不能再使用原名 , 否则会报错 .
* 2. 当表名或列名中包含空格 , 特殊字符或与MySQL关键字冲突时 , 可以通过使用反引号 ( ` ) 包裹 ,
这样可以确保MySQL正确解析这些标识符 ( 不能使用单双引号 ) .
mysql> SELECT ` e mp` . first_name, dept. department_name FROM employees AS ` e mp` , departments AS ` dept` - > WHERE ` e mp` . department_id = dept. department_id;
+
| first_name | department_name |
+
| Jennifer | Administration |
| Michael | Marketing |
| Pat | Marketing |
| Den | Purchasing |
| Alexander | Purchasing |
| . . . | . . . |
| John | Finance |
| Ismael | Finance |
| Jose Manuel | Finance |
| Luis | Finance |
| Shelley | Accounting |
| William | Accounting |
+
106 rows in set ( 0.00 sec)
如果有n个表实现多表的查询 , 则需要至少n- 1 个连接条件 .
mysql> SELECT locs. city FROM employees AS ` emp` , departments AS ` dept` , locations AS ` locs` WHERE emp. department_id = dept. department_id AND dept. location_id = locs. location_id AND emp. first_name = 'Jack' ;
+
| city |
+
| Oxford |
+
1 row in set ( 0.00 sec)
交叉连接完整格式 : 表与表之间使用关键字CROSS JOIN连接 :
SELECT 列 1 , 列 2
FROM A CROSS JOIN B ;
WHERE A . column1 = B . column2 ;
mysql> SELECT locs. city FROM employees AS ` emp` CROSS JOIN departments AS ` dept` CROSS JOIN locations AS ` locs` - > WHERE emp. department_id = dept. department_id AND dept. location_id = locs. location_id AND emp. first_name = 'Jack' ;
+
| city |
+
| Oxford |
+
1 row in set ( 0.02 sec)
等值连接和非等值连接是关系型数据库查询中的两种主要连接方式 , 它们的主要区别在于连接条件的不同 .
* 1. 等值连接 ( Equi-Join ) : 在等值连接中 , 连接条件是两个表中的列值相等 .
也就是说 , 等值连接会根据连接条件从一个表中选取每一行数据 , 然后与另一个表中满足相同条件的行进行连接 .
例如 , 如果有两个表A和B , 其中一个连接条件为 "A.id = B.id" , 那么这个连接就是一个等值连接 ,
它会将A表中id字段的值与B表中id字段的值相等的行连接起来 .
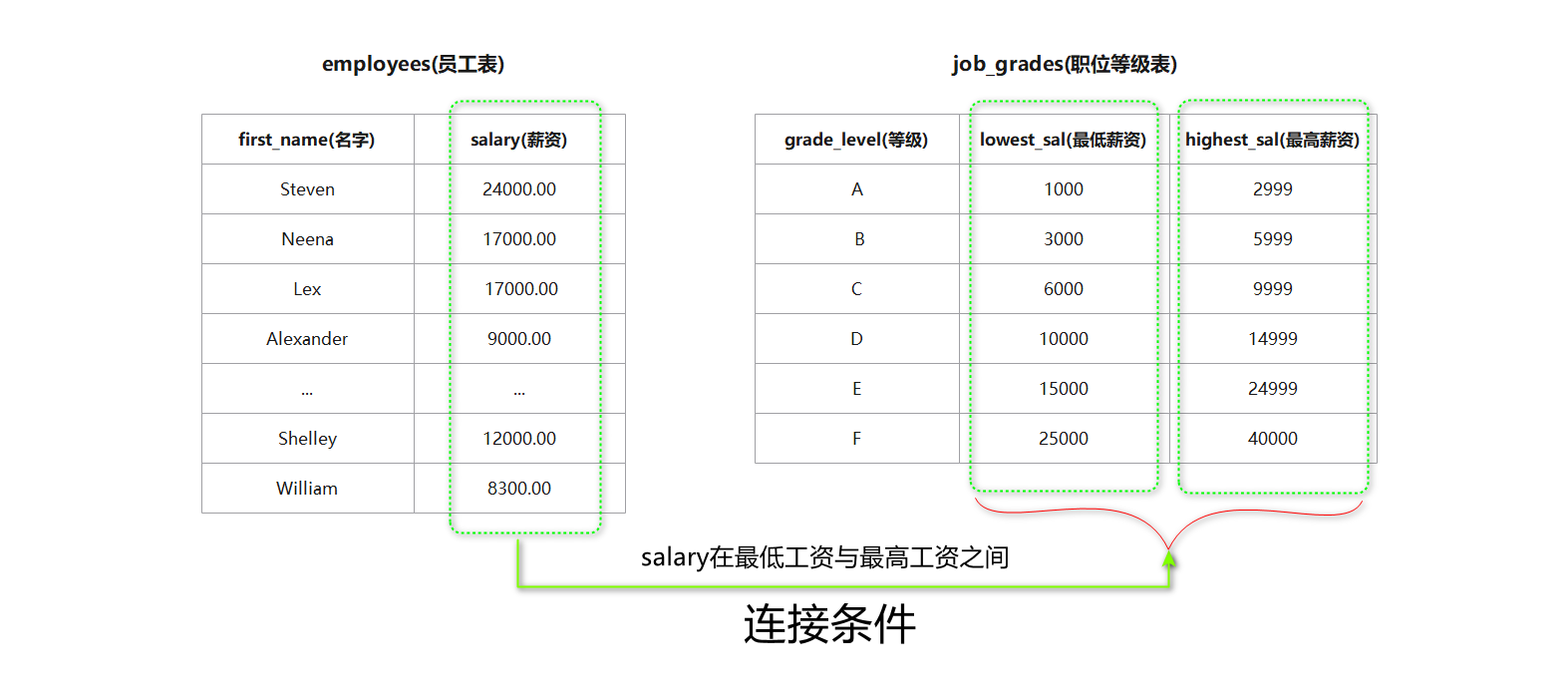
* 2. 非等值连接 ( Non-Equi-Join ) : 在非等值连接中 , 连接条件可以是两个表中的列值不等或者使用其他比较运算符 ( 如 < , > , < = , > = 等 ) .
非等值连接会根据连接条件从一个表中选取每一行数据 , 然后与另一个表中满足条件的行进行连接 .
例如 , 如果有两个表A和B , 其中一个连接条件为 "A.salary > B.salary" , 那么这个连接就是一个非等值连接 ,
它会将A表中salary字段的值大于B表中salary字段的值的行连接起来 .
* 等值连接要求连接条件中的列值相等 , 而非等值连接则可以使用其他比较运算符进行连接 .
mysql> SELECT emp. first_name, dept. department_name FROM employees AS ` emp` , departments AS ` dept` - > WHERE emp. department_id = dept. department_id;
+
| first_name | department_name |
+
| Jennifer | Administration |
| Michael | Marketing |
| Pat | Marketing |
| Den | Purchasing |
| Alexander | Purchasing |
| Shelli | Purchasing |
| Sigal | Purchasing |
| . . . | . . . |
| Jose Manuel | Finance |
| Luis | Finance |
| Shelley | Accounting |
| William | Accounting |
+
106 rows in set ( 0.04 sec)
mysql> select * from job_grades;
+
| grade_level | lowest_sal | highest_sal |
+
| A | 1000 | 2999 |
| B | 3000 | 5999 |
| C | 6000 | 9999 |
| D | 10000 | 14999 |
| E | 15000 | 24999 |
| F | 25000 | 40000 |
+
6 rows in set ( 0.01 sec)
mysql> SELECT emp. first_name, emp. salary, jg. grade_level FROM employees AS ` emp` , job_grades AS ` jg` WHERE emp. salary BETWEEN jg. lowest_sal AND jg. highest_sal;
+
| first_name | salary | grade_level |
+
| Steven | 24000.00 | E |
| Neena | 17000.00 | E |
| Lex | 17000.00 | E |
| Alexander | 9000.00 | C |
| . . . | . . . | . |
| Jennifer | 4400.00 | B |
| Michael | 13000.00 | D |
| Pat | 6000.00 | C |
| Susan | 6500.00 | C |
| Hermann | 10000.00 | D |
| Shelley | 12000.00 | D |
| William | 8300.00 | C |
+
107 rows in set ( 0.00 sec)
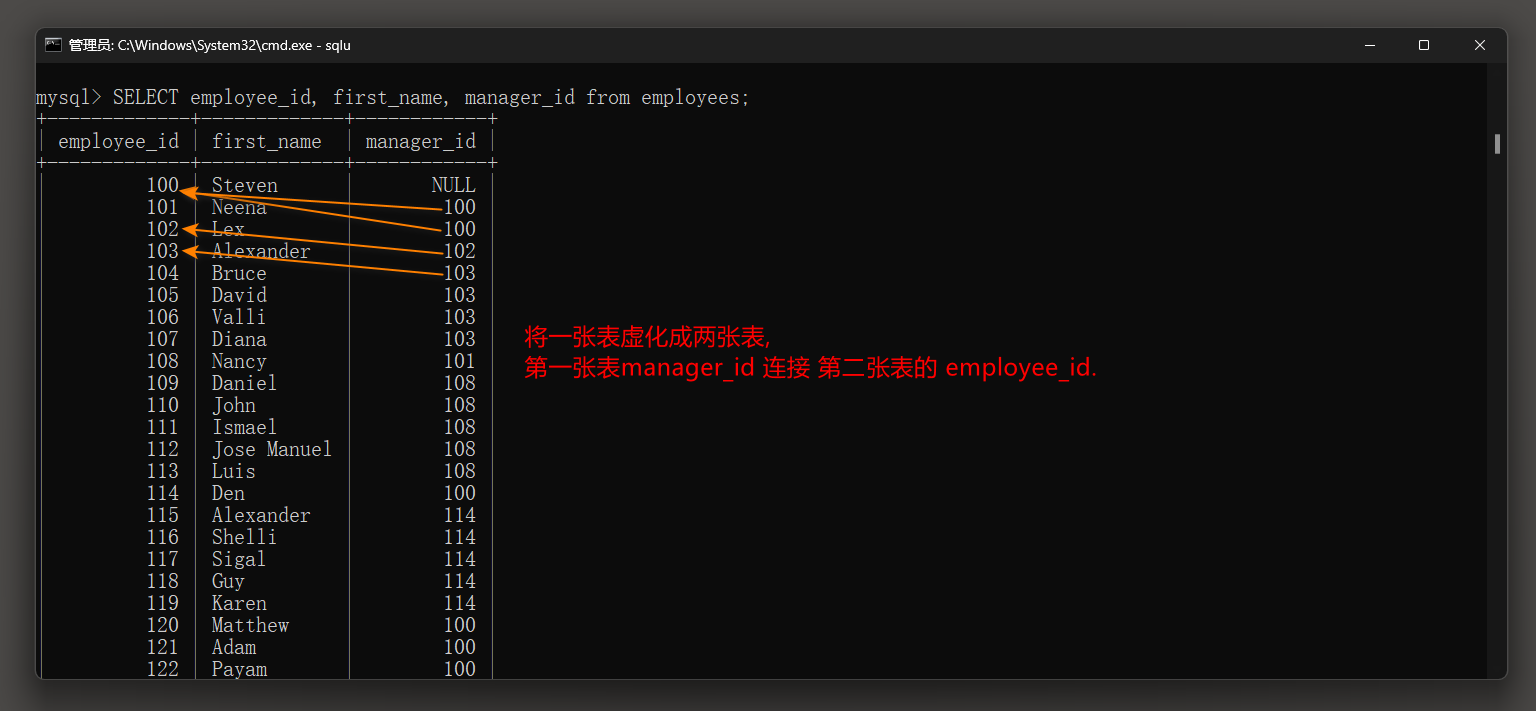
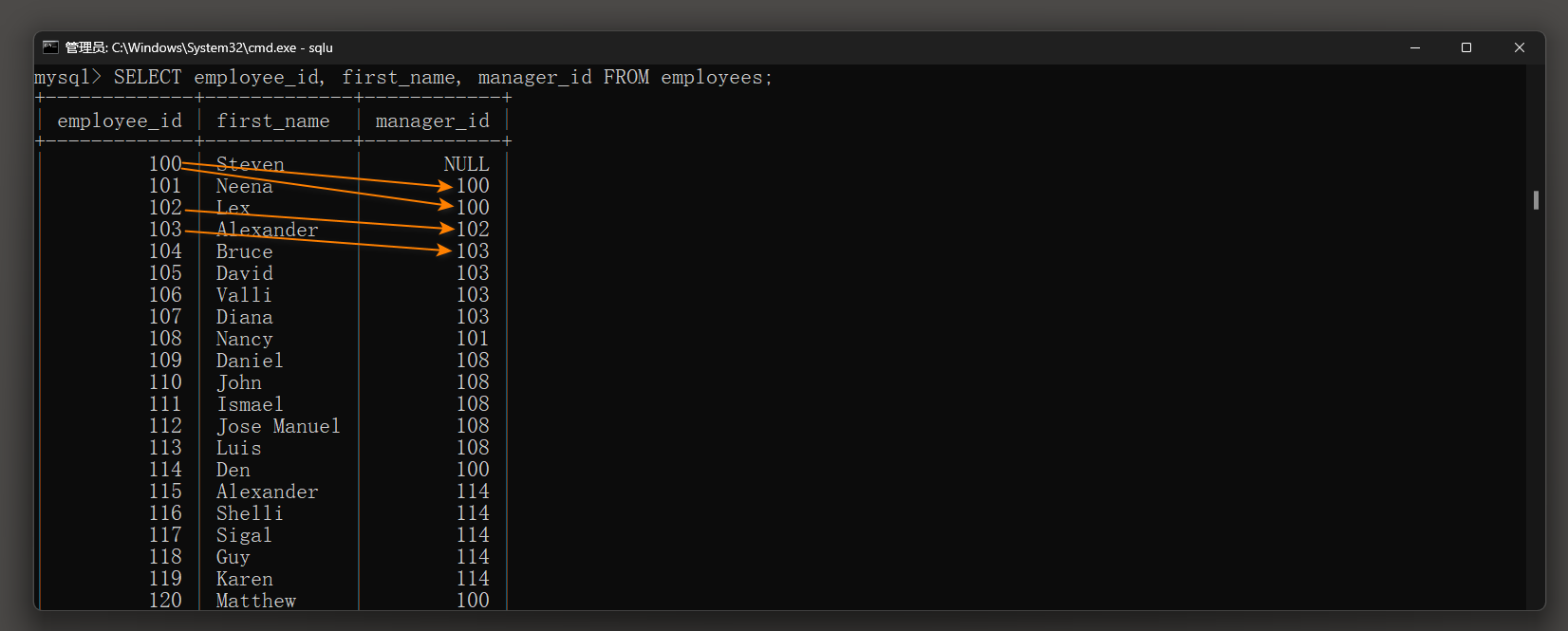
自连接和非自连接都是关系型数据库中的连接操作 , 但它们连接的表的数量和类型有所不同 .
* 1. 自连接 : 是指一张表与其自身进行连接 , 通过将同一张表复制为两份并对它们进行连接操作 , 可以找出表内的相关数据并进行比较 .
自连接通常用于查找存在于同一表中的相关数据 , 例如员工与员工的上下级关系 , 物品与物品的相似度等 .
* 2. 非自连接则是指连接不同的表 , 通过将不同表的列进行匹配 , 可以从多个表中获取相关联的数据并进行更复杂的查询操作 .
非自连接可以用于执行各种联接操作 , 包括内连接 , 外连接 , 交叉连接等 .
总之 , 自连接和非自连接都是关系型数据库中的连接操作 , 但它们的操作对象和目的有所不同 .
mysql> SELECT worker. first_name AS "员工名字" , manager. first_name AS "管理者名字"
FROM employees AS ` worker` , employees AS ` manager` WHERE worker. manager_id = manager. employee_id;
+
| 员工名字 | 管理者名字 |
+
| Neena | Steven |
| Lex | Steven |
| Alexander | Lex |
| Bruce | Alexander |
| David | Alexander |
| Valli | Alexander |
| . . . | . . . |
| Jennifer | Neena |
| Michael | Steven |
| Pat | Michael |
| Susan | Neena |
| Hermann | Neena |
| Shelley | Neena |
| William | Shelley |
+
106 rows in set ( 0.00 sec)
SQL99 ( SQL 1999 ) : 引入了标准的多表查询语法 , 以提供更强大和灵活的多表查询功能 .
以下是SQL99多表查询的一般语法结构 :
SELECT 列名1 , 列名2 , . . .
FROM 表名1
JOIN 表名2 ON 连接条件
[ JOIN 表名3 ON 连接条件]
. . .
WHERE 条件;
这里是每个部分的解释:
- SELECT : 指定要从查询结果中返回的列 .
- FROM : 指定要查询的表 , 可以指定一个或多个表 .
- JOIN : 用于将表连接起来 , 可以使用多个JOIN语句实现多个表的连接 .
- ON : 指定连接条件 , 用于确定如何连接表 .
- WHERE : 可选项 , 用于指定额外的过滤条件 .
* 关键字 JOIN , INNER JOIN , CROSS JOIN的含义是一样的 , 都表示内连接 .
mysql> SELECT locs. city
FROM employees AS ` emp` JOIN departments AS ` dept` ON emp. department_id = dept. department_id
JOIN locations AS ` locs` ON dept. location_id = locs. location_id
WHERE emp. first_name = 'Jack' ;
+
| city |
+
| Oxford |
+
1 row in set ( 0.00 sec)
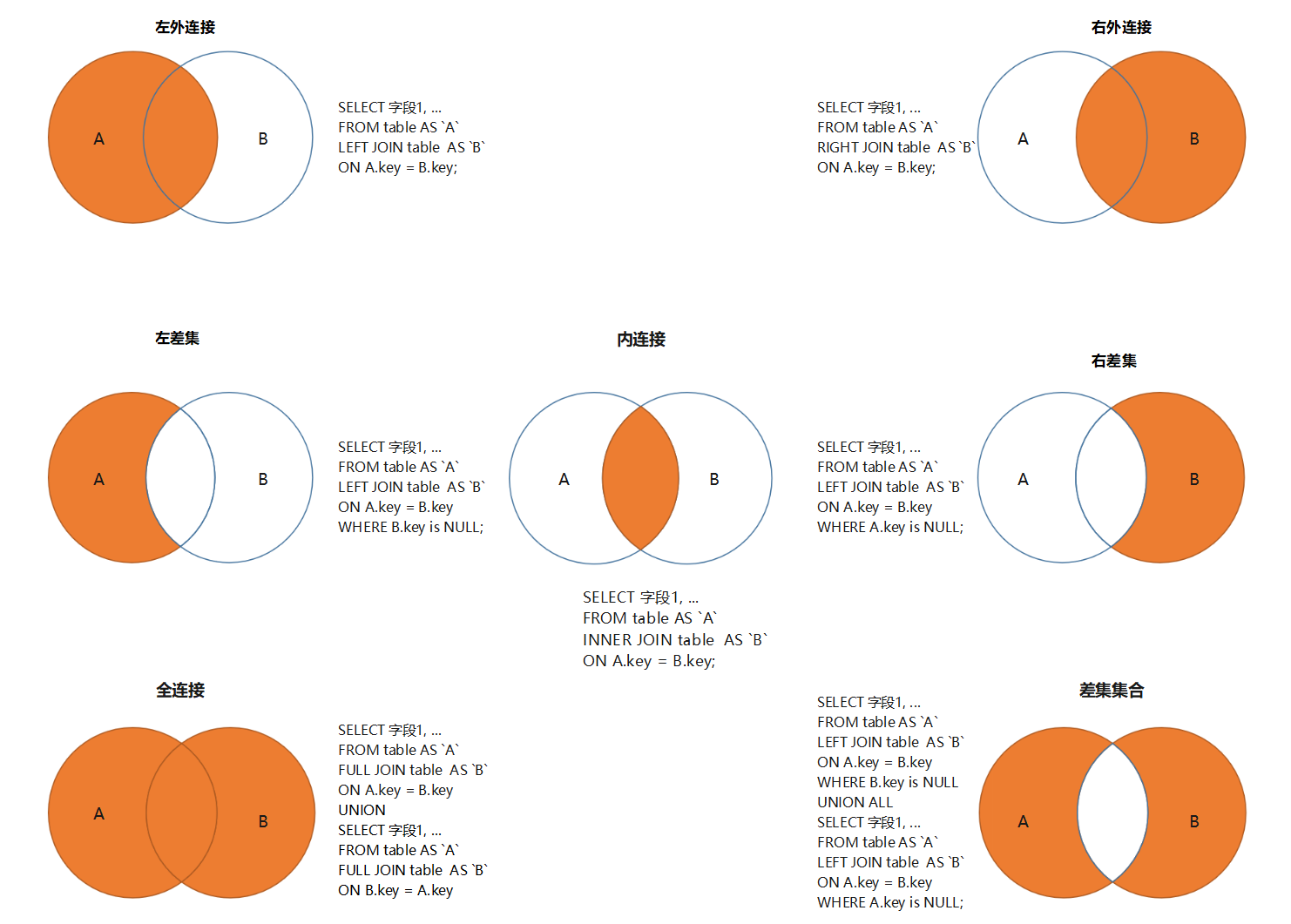
内连接和外连接是数据库中两种主要的连接类型 , 它们在多表查询中起着重要的作用 .
* 1. 内连接 ( Inner Join ) : 也被称为自然连接 , 它是最常见的连接类型 .
它基于两个或多个表之间的相等关系 , 返回满足连接条件的匹配行 .
内连接只返回符合连接条件的行 , 其他不满足条件的行将被排除 .
* 2. 外连接则包括左外连接 , 右外连接和全外连接 .
1. LEFT JOIN ( 左连接 ) : 左连接将返回左表中的所有行 , 以及符合连接条件的右表中的匹配行 .
如果右表中没有与左表匹配的行 , 则返回NULL值 .
左连接常用于需要包含左表中的全部数据 , 并根据连接条件关联右表的查询需求 .
2. RIGHT JOIN ( 右连接 ) : 右连接与左连接相反 , 它将返回右表中的所有行 , 以及符合连接条件的左表中的匹配行 .
如果左表中没有与右表匹配的行 , 则返回NULL值 .
右连接在需要包含右表中的全部数据 , 并根据连接条件关联左表的查询需求时使用 .
3. FULL JOIN ( 全连接 ) : 全连接返回两个表中所有行的组合 , 不管是否满足连接条件 .
如果没有匹配的行 , 则返回NULL值 .
全连接常用于需要包含两个表中全部数据的查询 .
总的来说 , 内连接只返回两个表中相关联的数据 , 而外连接则返回更全面的数据结果 , 包括了没有匹配的行 .
在MySQL中 , "左表" 和 "右表" 是相对于SQL中使用多表查询时指定的表的位置 .
当使用JOIN操作将两个或多个表连接时 , 左表是在JOIN操作中使用的第一个表 , 而右表是在JOIN操作中使用的第二个表 ( 或后续表 ) .
这个术语通常用于描述不同类型的JOIN操作 , 如LEFT JOIN和RIGHT JOIN .
LEFT JOIN将左表作为主表 , 并在结果中包含左表的所有记录 , 而右表中匹配的记录将按照JOIN条件进行连接 .
相反 , RIGHT JOIN将右表作为主表 , 并在结果中包含右表的所有记录 , 同时将左表中匹配的记录进行连接 .
总之 , 左表和右表是相对于多表查询中使用的表的位置 , 用于描述JOIN操作中的表连接顺序和结果 .
SELECT 字段列表 FROM A表 LEFT OUTER JOIN B表 ON 关联条件 WHERE 等其他子句;
SELECT 字段列表 FROM A表 LEFT JOIN B表 ON 关联条件 WHERE 等其他子句;
mysql> SELECT emp. first_name, emp. employee_id, dept. department_id, dept. department_name
FROM employees AS ` emp` LEFT JOIN departments AS ` dept` ON emp. department_id = dept. department_id;
+
| first_name | employee_id | department_id | department_name |
+
| Steven | 100 | 90 | Executive |
| . . . | . . . | . . | . . . |
| Kimberely | 178 | NULL | NULL |
| . . . | . . . | . . | . . . |
| Hermann | 204 | 70 | Public Relations |
| Shelley | 205 | 110 | Accounting |
| William | 206 | 110 | Accounting |
+
107 rows in set ( 0.00 sec)
SELECT 字段列表 FROM A表 RIGHT OUTER JOIN B表 ON 关联条件 WHERE 等其他子句;
SELECT 字段列表 FROM A表 RIGHT JOIN B表 ON 关联条件 WHERE 等其他子句;
mysql> select * from departments;
+
| department_id | department_name | manager_id | location_id |
+
| 10 | Administration | 200 | 1700 |
| 20 | Marketing | 201 | 1800 |
| 30 | Purchasing | 114 | 1700 |
| 40 | Human Resources | 203 | 2400 |
| 50 | Shipping | 121 | 1500 |
| 60 | IT | 103 | 1400 |
| 70 | Public Relations | 204 | 2700 |
| 80 | Sales | 145 | 2500 |
| 90 | Executive | 100 | 1700 |
| 100 | Finance | 108 | 1700 |
| 110 | Accounting | 205 | 1700 |
| 120 | Treasury | NULL | 1700 |
| 130 | Corporate Tax | NULL | 1700 |
| 140 | Control And Credit | NULL | 1700 |
| 150 | Shareholder Services | NULL | 1700 |
| 160 | Benefits | NULL | 1700 |
| 170 | Manufacturing | NULL | 1700 |
| 180 | Construction | NULL | 1700 |
| 190 | Contracting | NULL | 1700 |
| 200 | Operations | NULL | 1700 |
| 210 | IT Support | NULL | 1700 |
| 220 | NOC | NULL | 1700 |
| 230 | IT Helpdesk | NULL | 1700 |
| 240 | Government Sales | NULL | 1700 |
| 250 | Retail Sales | NULL | 1700 |
| 260 | Recruiting | NULL | 1700 |
| 270 | Payroll | NULL | 1700 |
+
27 rows in set ( 0.00 sec)
mysql> SELECT DISTINCT department_id FROM employees;
+
| department_id |
+
| NULL |
| 10 |
| 20 |
| 30 |
| 40 |
| 50 |
| 60 |
| 70 |
| 80 |
| 90 |
| 100 |
| 110 |
+
12 rows in set ( 0.00 sec)
部门表中有 27 个部门的信息 ,
员工表中右一个人没有部门 , 其他的 106 人分别在 11 个部门下工作 , 那么部门表中还有 16 个部门没有员工 .
使用右连接后应该有 : 106 + 16 = 122 条数据 .
106 : 是满足 "emp.department_id = dept.department_id" 的数据 .
16 : 是没有满足 "emp.department_id = dept.department_id" 的数据 .
mysql> SELECT emp. first_name, emp. employee_id, dept. department_id, dept. department_name
FROM employees AS ` emp` RIGHT JOIN departments AS ` dept` ON emp. department_id = dept. department_id;
+
| first_name | employee_id | department_id | department_name |
+
| Jennifer | 200 | 10 | Administration |
| . . . | . . . | . . | . . . |
| NULL | NULL | 120 | Treasury |
| NULL | NULL | 130 | Corporate Tax |
| NULL | NULL | 140 | Control And Credit |
| NULL | NULL | 150 | Shareholder Services |
| NULL | NULL | 160 | Benefits |
| NULL | NULL | 170 | Manufacturing |
| NULL | NULL | 180 | Construction |
| NULL | NULL | 190 | Contracting |
| NULL | NULL | 200 | Operations |
| NULL | NULL | 210 | IT Support |
| NULL | NULL | 220 | NOC |
| NULL | NULL | 230 | IT Helpdesk |
| NULL | NULL | 240 | Government Sales |
| NULL | NULL | 250 | Retail Sales |
| NULL | NULL | 260 | Recruiting |
| NULL | NULL | 270 | Payroll |
+
122 rows in set ( 0.02 sec)
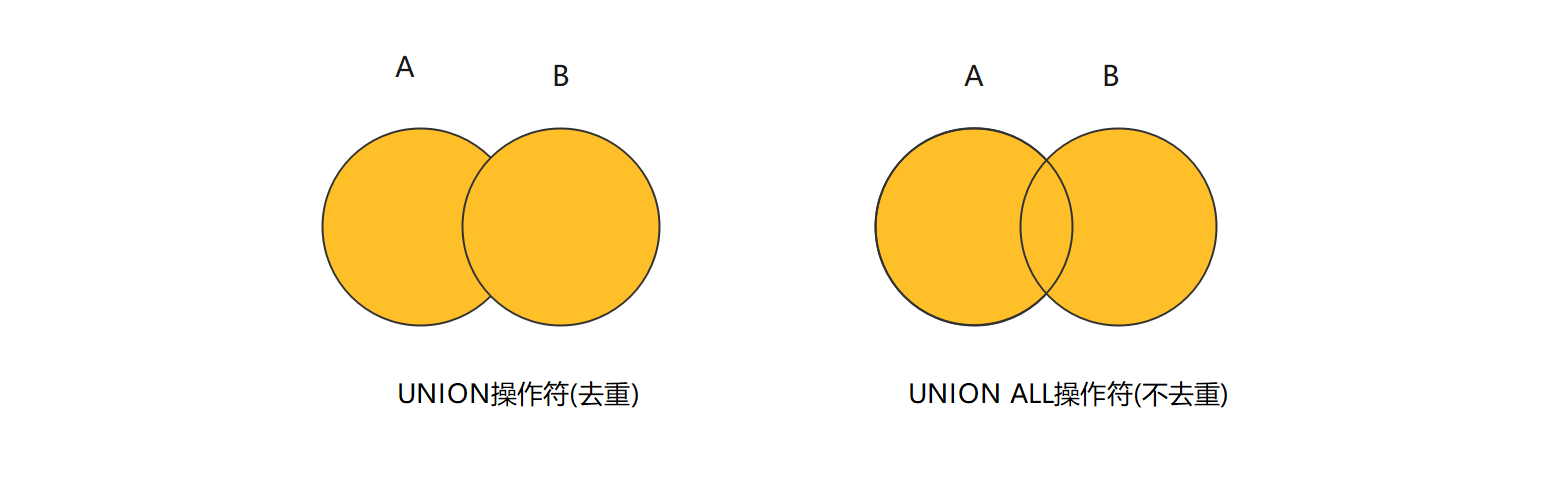
UNION关键字 : 用于将两个或更多SELECT语句的结果集合并成一个结果集 , 它用于在SQL查询中合并多个查询的结果 .
当使用UNION时 , 每个SELECT语句必须具有相同的列数和相似的数据类型 , 因为UNION会将它们的结果合并到一个结果集中 .
UNION会自动去重 , 即如果两个查询结果中有相同的行 , UNION只会保留其中一个 .
除了UNION外 , 还有UNION ALL , 它与UNION类似 , 但不会去重 , 即会保留所有查询结果中的行 , 包括重复的行 .
SELECT 字段列表 FROM A表 LEFT JOIN B表 ON 关联条件 WHERE 等其他子句;
UNION [ ALL ]
SELECT 字段列表 FROM A表 RIGHT JOIN B表 ON 关联条件 WHERE 等其他子句;
使用全连接后应该有 : 1 + 106 + 16 = 123 条数据 .
106 : 是满足 "emp.department_id = dept.department_id" 的数据 .
17 : 是没有满足 "emp.department_id = dept.department_id" 的数据 ( 左边有 1 条不满足 , 右边有 16 条不满足 ) .
mysql> SELECT emp. first_name, emp. employee_id, dept. department_id, dept. department_name
FROM employees AS ` emp` LEFT JOIN departments AS ` dept` ON emp. department_id = dept. department_id
UNION
SELECT emp. first_name, emp. employee_id, dept. department_id, dept. department_name
FROM employees AS ` emp` RIGHT JOIN departments AS ` dept` ON emp. department_id = dept. department_id;
+
| first_name | employee_id | department_id | department_name |
+
| Steven | 100 | 90 | Executive |
| . . . | . . . | . . | . . . |
| Jack | 177 | 80 | Sales |
| Kimberely | 178 | NULL | NULL |
| . . . | . . . | . . | . . . |
| NULL | NULL | 120 | Treasury |
| NULL | NULL | 130 | Corporate Tax |
| NULL | NULL | 140 | Control And Credit |
| NULL | NULL | 150 | Shareholder Services |
| NULL | NULL | 160 | Benefits |
| NULL | NULL | 170 | Manufacturing |
| NULL | NULL | 180 | Construction |
| NULL | NULL | 190 | Contracting |
| NULL | NULL | 200 | Operations |
| NULL | NULL | 210 | IT Support |
| NULL | NULL | 220 | NOC |
| NULL | NULL | 230 | IT Helpdesk |
| NULL | NULL | 240 | Government Sales |
| NULL | NULL | 250 | Retail Sales |
| NULL | NULL | 260 | Recruiting |
| NULL | NULL | 270 | Payroll |
+
123 rows in set ( 0.01 sec)
mysql> SELECT emp. first_name, emp. employee_id, dept. department_id, dept. department_name
FROM employees AS ` emp` LEFT JOIN departments AS ` dept` ON emp. department_id = dept. department_id
UNION ALL
SELECT emp. first_name, emp. employee_id, dept. department_id, dept. department_name
FROM employees AS ` emp` RIGHT JOIN departments AS ` dept` ON emp. department_id = dept. department_id;
+
| first_name | employee_id | department_id | department_name |
+
| Steven | 100 | 90 | Executive |
| . . . | . . . | . . | . . . |
| NULL | NULL | 270 | Payroll |
+
229 rows in set ( 0.00 sec)
mysql> SELECT department_id, first_name, email FROM employees
WHERE department_id > 90 OR email LIKE '%a%' ;
+
| department_id | first_name | email |
+
| 90 | Neena | NKOCHHAR |
| 90 | Lex | LDEHAAN |
| 60 | Alexander | AHUNOLD |
| . . | . . . | . . . |
| 40 | Susan | SMAVRIS |
| 70 | Hermann | HBAER |
| 110 | Shelley | SHIGGINS |
| 110 | William | WGIETZ |
+
67 rows in set ( 0.00 sec)
mysql> SELECT department_id, first_name, email FROM employees WHERE department_id > 90
UNION
SELECT department_id, first_name, email FROM employees WHERE email LIKE '%a%' ;
+
| department_id | first_name | email |
+
| 90 | Neena | NKOCHHAR |
| 90 | Lex | LDEHAAN |
| 60 | Alexander | AHUNOLD |
| . . | . . . | . . . |
| 40 | Susan | SMAVRIS |
| 70 | Hermann | HBAER |
| 110 | Shelley | SHIGGINS |
| 110 | William | WGIETZ |
+
67 rows in set ( 0.00 sec)
SQL99引入自然连接 ( NATURAL JOIN ) : 它会帮你自动查询两张连接表中所有相同的字段然后进行等值连接 .
自然连接是一种特殊的内连接 , 它要求相连接的两张表的连接依据列必须是相同的字段 ( 字段名相同 , 字段属性相同 ) .
在结果集中 , 自然连接会将两张表中名称相同的列仅出现一次 , 即去除重复的列 .
mysql> SELECT DISTINCT manager_id FROM departments;
+
| manager_id |
+
| NULL |
| 100 |
| 103 |
| 108 |
| 114 |
| 121 |
| 145 |
| 200 |
| 201 |
| 203 |
| 204 |
| 205 |
+
12 rows in set ( 0.00 sec)
mysql> SELECT DISTINCT manager_id FROM employees;
+
| manager_id |
+
| NULL |
| 100 |
| 101 |
| 102 |
| 103 |
| 108 |
| 114 |
| 120 |
| 121 |
| 122 |
| 123 |
| 124 |
| 145 |
| 146 |
| 147 |
| 148 |
| 149 |
| 201 |
| 205 |
+
19 rows in set ( 0.00 sec)
mysql> SELECT emp. department_id, emp. manager_id, emp. first_name
FROM employees AS ` emp` JOIN departments AS ` dept` ON emp. department_id = dept. department_id
AND emp. manager_id = dept. manager_id;
+
| department_id | manager_id | first_name |
+
| 90 | 100 | Neena |
| 90 | 100 | Lex |
| 60 | 103 | Bruce |
| 60 | 103 | David |
| 60 | 103 | Valli |
| . . . | . . . | . . . |
| 80 | 145 | David |
| 80 | 145 | Peter |
| 80 | 145 | Christopher |
| 80 | 145 | Nanette |
| 80 | 145 | Oliver |
| 20 | 201 | Pat |
| 110 | 205 | William |
+
32 rows in set ( 0.00 sec)
mysql> SELECT emp. department_id, emp. manager_id, emp. first_name
FROM employees AS ` emp` NATURAL JOIN departments AS ` dept` ;
+
| department_id | manager_id | first_name |
+
| 90 | 100 | Neena |
| 90 | 100 | Lex |
| 60 | 103 | Bruce |
| 60 | 103 | David |
| 60 | 103 | Valli |
| . . . | . . . | . . . |
| 80 | 145 | David |
| 80 | 145 | Peter |
| 80 | 145 | Christopher |
| 80 | 145 | Nanette |
| 80 | 145 | Oliver |
| 20 | 201 | Pat |
| 110 | 205 | William |
+
32 rows in set ( 0.00 sec)
在SQL99标准中 , 引入了USING关键字来指定数据表中的同名字段进行等值连接 , 是一种简化连接条件的方式 .
需要注意的是 , USING关键字只能与JOIN一起使用 , 包括INNER JOIN , LEFT JOIN , RIGHT JOIN等 .
它不能单独使用 , 也不能与其他连接条件 ( 如WHERE子句 ) 一起使用 .
使用USING关键字的目的是简化连接条件的指定 , 特别是在两个表中存在同名字段时 .
通过USING关键字 , 你可以指定同名字段进行等值连接 , 而无需在连接条件中明确指定字段名和比较操作符 .
SELECT *
FROM table1
JOIN table2 USING ( column_name)
mysql> SELECT emp. employee_id, emp. first_name, dept. department_name
FROM employees AS ` emp` JOIN departments AS ` dept` ON emp. department_id = dept. department_id;
+
| employee_id | first_name | department_name |
+
| 200 | Jennifer | Administration |
| 201 | Michael | Marketing |
| 202 | Pat | Marketing |
| 114 | Den | Purchasing |
| 115 | Alexander | Purchasing |
| . . . | . . . | . . . |
| 111 | Ismael | Finance |
| 112 | Jose Manuel | Finance |
| 113 | Luis | Finance |
| 205 | Shelley | Accounting |
| 206 | William | Accounting |
+
106 rows in set ( 0.00 sec)
mysql> SELECT emp. employee_id, emp. first_name, dept. department_name
FROM employees AS ` emp` JOIN departments AS ` dept` USING ( department_id) ;
+
| employee_id | first_name | department_name |
+
| 200 | Jennifer | Administration |
| 201 | Michael | Marketing |
| 202 | Pat | Marketing |
| 114 | Den | Purchasing |
| 115 | Alexander | Purchasing |
| . . . | . . . | . . . |
| 111 | Ismael | Finance |
| 112 | Jose Manuel | Finance |
| 113 | Luis | Finance |
| 205 | Shelley | Accounting |
| 206 | William | Accounting |
+
106 rows in set ( 0.00 sec)
在进行多表操作时 , 为了避免产生笛卡尔积错误 , 需要设置连接的条件 .
例如 : WHERE , ON , USING , 三种约束方式 .
WHERE : 适用于所有关联查询 , 不仅可以用于表间的连接条件 , 还可以用于过滤数据 .
它的使用非常灵活 , 可以在查询语句的任意位置使用 , 也可以同时指定多个条件 .
ON : 只能和JOIN一起使用 , 用于指定连接条件 . 它的作用范围仅限于连接两个表的条件 , 因此在ON子句中只能写关联条件 .
虽然关联条件也可以合并到WHERE子句中和其他条件一起写 , 但分开写通常可读性更好 , 也更符合SQL的语义 .
USING : 只能和JOIN语句一起使用 , 要求两个关联字段在关联表中名称一致 , 它用于简化连接条件的指定 .
当两个表中的关联字段名称相同时 , 可以使用USING来指定它们进行等值连接 .
但需要注意的是 , USING关键字只能表示关联字段值相等 , 不能用于其他类型的连接条件 .
SELECT first_name, department_name
FROM employees, departments
WHERE employees. department_id = departments. department_id;
SELECT first_name, department_name
FROM employees INNER JOIN departments
ON employees. department_id = departments. department_id;
SELECT first_name, department_name
FROM employees CROSS JOIN departments
ON employees. department_id = departments. department_id;
SELECT first_name, department_name
FROM employees JOIN departments
ON employees. department_id = departments. department_id;
SELECT first_name, department_name
FROM employees JOIN departments
USING ( department_id) ;
SELECT first_name, department_name, job_title FROM employees, departments, jobs
WHERE employees. department_id = departments. department_id
AND employees. job_id = jobs. job_id;
SELECT first_name, department_name, job_title
FROM employees INNER JOIN departments INNER JOIN jobs
ON employees. department_id = departments. department_id
AND employees. job_id = jobs. job_id;
SELECT first_name, department_name, job_title
FROM employees INNER JOIN departments ON employees. department_id = departments. department_id
INNER JOIN jobs ON employees. job_id = jobs. job_id;
注意事项 : 需要控制连接表的数量 .
多表连接就相当于嵌套for循环一样 , 非常消耗资源 , 会让SQL查询性能下降得很严重 , 因此不要连接不必要的表 .
在许多DBMS中 , 也都会有最大连接表的限制 .
超过三个表禁止join , 需要join的字段 , 数据类型保持绝对一致 ; 多表关联查询时 , 保证被关联的字段需要有索引 .
即使双表join也要注意表索引 , SQL性能 .
mysql> SELECT employee_id, first_name, department_name
FROM employees AS ` EMP` JOIN departments AS ` dept` ON emp. ` department_id` = dept. ` department_id` ;
+
| employee_id | first_name | department_name |
+
| 200 | Jennifer | Administration |
| 201 | Michael | Marketing |
| . . . | . . . | . . . |
| 113 | Luis | Finance |
| 205 | Shelley | Accounting |
| 206 | William | Accounting |
+
106 rows in set ( 0.00 sec)
SELECT employee_id, first_name, department_name
FROM employees AS ` EMP` JOIN departments AS ` dept` USING ( department_id) ;
mysql> SELECT emp. first_name, emp. employee_id, dept. department_id, dept. department_name
FROM employees AS ` emp` LEFT JOIN departments AS ` dept` ON emp. department_id = dept. department_id;
+
| first_name | employee_id | department_id | department_name |
+
| Steven | 100 | 90 | Executive |
| . . . | . . . | . . | . . . |
| Kimberely | 178 | NULL | NULL |
| . . . | . . . | . . | . . . |
| Hermann | 204 | 70 | Public Relations |
| Shelley | 205 | 110 | Accounting |
| William | 206 | 110 | Accounting |
+
107 rows in set ( 0.00 sec)
mysql> SELECT emp. first_name, emp. employee_id, dept. department_id, dept. department_name
FROM employees AS ` emp` LEFT JOIN departments AS ` dept` USING ( department_id) ;
mysql> SELECT emp. first_name, emp. employee_id, dept. department_id, dept. department_name
FROM employees AS ` emp` RIGHT JOIN departments AS ` dept` ON emp. department_id = dept. department_id;
+
| first_name | employee_id | department_id | department_name |
+
| Jennifer | 200 | 10 | Administration |
| . . . | . . . | . . | . . . |
| NULL | NULL | 120 | Treasury |
| NULL | NULL | 130 | Corporate Tax |
| NULL | NULL | 140 | Control And Credit |
| NULL | NULL | 150 | Shareholder Services |
| NULL | NULL | 160 | Benefits |
| NULL | NULL | 170 | Manufacturing |
| NULL | NULL | 180 | Construction |
| NULL | NULL | 190 | Contracting |
| NULL | NULL | 200 | Operations |
| NULL | NULL | 210 | IT Support |
| NULL | NULL | 220 | NOC |
| NULL | NULL | 230 | IT Helpdesk |
| NULL | NULL | 240 | Government Sales |
| NULL | NULL | 250 | Retail Sales |
| NULL | NULL | 260 | Recruiting |
| NULL | NULL | 270 | Payroll |
+
122 rows in set ( 0.02 sec)
SELECT emp. first_name, emp. employee_id, dept. department_id, dept. department_name
FROM employees AS ` emp` RIGHT JOIN departments AS ` dept` USING ( department_id) ;
mysql> SELECT emp. first_name, emp. employee_id, dept. department_id, dept. department_name
FROM employees AS ` emp` LEFT JOIN departments AS ` dept` ON emp. department_id = dept. department_id
WHERE dept. department_id is null ;
+
| first_name | employee_id | department_id | department_name |
+
| Kimberely | 178 | NULL | NULL |
+
1 row in set ( 0.00 sec)
mysql> SELECT emp. first_name, emp. employee_id, dept. department_id, dept. department_name
FROM employees AS ` emp` LEFT JOIN departments AS ` dept` USING ( department_id)
WHERE dept. department_id is null ;
SELECT A. *
FROM table_A A
LEFT JOIN table_B B ON A. key_column = B. key_column
WHERE B. key_column IS NULL ;
SQL查询中 , 使用LEFT JOIN来连接table_A和table_B .
这意味着 , 获取到 table_A 的所有记录 , 并与table_B中匹配的记录进行连接 .
如果table_B中没有与table_A中的记录匹配的记录 , 那么table_B中的所有列都将为NULL .
因此 , 当我们使用WHERE B . key_column IS NULL , 我们实际上是在查找那些在table_B中没有与table_A中的记录匹配的记录 .
换句话说 , 这些记录存在于table_A中 , 但不存在于table_B中 , 即 A - ( A ∩ B ) .
现在有一个员工的id为null , 那么A . key_column IS NULL得到的结果没有问题 ( 但这并不代表这个方式是正确的 ) .
如果员工的id不是null , 而是其他不存在与B表中的id , 那么那么A . key_column IS NULL得到的结果就是一个空集 .
B . key_column IS NULL能保证结果一定是对的 , 而A . key_column IS NULL无法保证 !
mysql> SELECT emp. first_name, emp. employee_id, dept. department_id, dept. department_name
FROM employees AS ` emp` RIGHT JOIN departments AS ` dept` ON emp. department_id = dept. department_id
WHERE emp. department_id IS NULL ;
+
| first_name | employee_id | department_id | department_name |
+
| NULL | NULL | 120 | Treasury |
| NULL | NULL | 130 | Corporate Tax |
| NULL | NULL | 140 | Control And Credit |
| NULL | NULL | 150 | Shareholder Services |
| NULL | NULL | 160 | Benefits |
| NULL | NULL | 170 | Manufacturing |
| NULL | NULL | 180 | Construction |
| NULL | NULL | 190 | Contracting |
| NULL | NULL | 200 | Operations |
| NULL | NULL | 210 | IT Support |
| NULL | NULL | 220 | NOC |
| NULL | NULL | 230 | IT Helpdesk |
| NULL | NULL | 240 | Government Sales |
| NULL | NULL | 250 | Retail Sales |
| NULL | NULL | 260 | Recruiting |
| NULL | NULL | 270 | Payroll |
+
16 rows in set ( 0.00 sec)
mysql> SELECT emp. first_name, emp. employee_id, dept. department_id, dept. department_name
FROM employees AS ` emp` RIGHT JOIN departments AS ` dept` USING ( department_id)
WHERE emp. department_id IS NULL ;
mysql> SELECT emp. first_name, emp. employee_id, dept. department_id, dept. department_name
FROM employees AS ` emp` LEFT JOIN departments AS ` dept` ON emp. department_id = dept. department_id
UNION
SELECT emp. first_name, emp. employee_id, dept. department_id, dept. department_name
FROM employees AS ` emp` RIGHT JOIN departments AS ` dept` ON emp. department_id = dept. department_id;
+
| first_name | employee_id | department_id | department_name |
+
| Steven | 100 | 90 | Executive |
| . . . | . . . | . . | . . . |
| Jack | 177 | 80 | Sales |
| Kimberely | 178 | NULL | NULL |
| . . . | . . . | . . | . . . |
| NULL | NULL | 120 | Treasury |
| NULL | NULL | 130 | Corporate Tax |
| NULL | NULL | 140 | Control And Credit |
| NULL | NULL | 150 | Shareholder Services |
| NULL | NULL | 160 | Benefits |
| NULL | NULL | 170 | Manufacturing |
| NULL | NULL | 180 | Construction |
| NULL | NULL | 190 | Contracting |
| NULL | NULL | 200 | Operations |
| NULL | NULL | 210 | IT Support |
| NULL | NULL | 220 | NOC |
| NULL | NULL | 230 | IT Helpdesk |
| NULL | NULL | 240 | Government Sales |
| NULL | NULL | 250 | Retail Sales |
| NULL | NULL | 260 | Recruiting |
| NULL | NULL | 270 | Payroll |
+
123 rows in set ( 0.01 sec)
mysql> SELECT emp. first_name, emp. employee_id, dept. department_id, dept. department_name
FROM employees AS ` emp` LEFT JOIN departments AS ` dept` USING ( department_id)
UNION
SELECT emp. first_name, emp. employee_id, dept. department_id, dept. department_name
FROM employees AS ` emp` RIGHT JOIN departments AS ` dept` USING ( department_id) ;
mysql> SELECT emp. first_name, emp. employee_id, dept. department_id, dept. department_name
FROM employees AS ` emp` LEFT JOIN departments AS ` dept` ON emp. department_id = dept. department_id
WHERE dept. department_id IS NULL
UNION ALL
SELECT emp. first_name, emp. employee_id, dept. department_id, dept. department_name
FROM employees AS ` emp` RIGHT JOIN departments AS ` dept` ON emp. department_id = dept. department_id
WHERE emp. department_id IS NULL ;
+
| first_name | employee_id | department_id | department_name |
+
| Kimberely | 178 | NULL | NULL |
| NULL | NULL | 120 | Treasury |
| NULL | NULL | 130 | Corporate Tax |
| NULL | NULL | 140 | Control And Credit |
| NULL | NULL | 150 | Shareholder Services |
| NULL | NULL | 160 | Benefits |
| NULL | NULL | 170 | Manufacturing |
| NULL | NULL | 180 | Construction |
| NULL | NULL | 190 | Contracting |
| NULL | NULL | 200 | Operations |
| NULL | NULL | 210 | IT Support |
| NULL | NULL | 220 | NOC |
| NULL | NULL | 230 | IT Helpdesk |
| NULL | NULL | 240 | Government Sales |
| NULL | NULL | 250 | Retail Sales |
| NULL | NULL | 260 | Recruiting |
| NULL | NULL | 270 | Payroll |
+
17 rows in set ( 0.00 sec)
mysql> SELECT emp. first_name, emp. employee_id, dept. department_id, dept. department_name
FROM employees AS ` emp` LEFT JOIN departments AS ` dept` USING ( department_id)
WHERE dept. department_id IS NULL
UNION ALL
SELECT emp. first_name, emp. employee_id, dept. department_id, dept. department_name
FROM employees AS ` emp` RIGHT JOIN departments AS ` dept` USING ( department_id)
WHERE emp. department_id IS NULL ;
* 1. 查询员工的姓名和部门号和年薪 , 按年薪降序 , 按姓名升序显示 .
mysql> SELECT last_name, department_id, salary * 12 AS 'annual_sal' FROM employees ORDER BY annual_sal DESC , last_name;
+
| last_name | department_id | annual_sal |
+
| King | 90 | 288000.00 |
| De Haan | 90 | 204000.00 |
| Kochhar | 90 | 204000.00 |
| Russell | 80 | 168000.00 |
| Partners | 80 | 162000.00 |
| . . . | . . | . . . |
| Perkins | 50 | 30000.00 |
| Sullivan | 50 | 30000.00 |
| Vargas | 50 | 30000.00 |
| Gee | 50 | 28800.00 |
| Landry | 50 | 28800.00 |
| Markle | 50 | 26400.00 |
| Philtanker | 50 | 26400.00 |
| Olson | 50 | 25200.00 |
+
107 rows in set ( 0.01 sec)
* 2. 选择工资不在 8000 到 17000 的员工的名字和工资 , 按工资降序显示第 21 到 40 位置的数据 .
mysql> SELECT first_name, salary FROM employees
WHERE salary NOT BETWEEN 8000 AND 17000 ORDER BY salary DESC LIMIT 20 , 20 ;
+
| first_name | salary |
+
| Bruce | 6000.00 |
| Pat | 6000.00 |
| Kevin | 5800.00 |
| David | 4800.00 |
| Valli | 4800.00 |
| Jennifer | 4400.00 |
| Diana | 4200.00 |
| Nandita | 4200.00 |
| Alexis | 4100.00 |
| Sarah | 4000.00 |
| Britney | 3900.00 |
| Kelly | 3800.00 |
| Jennifer | 3600.00 |
| Renske | 3600.00 |
| Trenna | 3500.00 |
| Julia | 3400.00 |
| Laura | 3300.00 |
| Jason | 3300.00 |
| Stephen | 3200.00 |
| Julia | 3200.00 |
+
20 rows in set ( 0.00 sec)
* 3. 查询邮箱中包含e的员工的名字 , 邮箱 , 部门id , 并先按邮箱的字节数降序 , 再按部门号升序 .
LENGTH ( ) 获取邮箱的字节数 .
mysql> SELECT first_name, email, department_id FROM employees
WHERE email LIKE '%e%' ORDER BY LENGTH( email) DESC , department_id;
+
| first_name | email | department_id |
+
| Michael | MHARTSTE | 20 |
| Den | DRAPHEAL | 30 |
| Karen | KCOLMENA | 30 |
| Julia | JDELLING | 50 |
| Randall | RPERKINS | 50 |
| Britney | BEVERETT | 50 |
| Donald | DOCONNEL | 50 |
| Diana | DLORENTZ | 60 |
| Eleni | EZLOTKEY | 80 |
| . . . | . . . | . . |
| Lisa | LOZER | 80 |
| Ellen | EABEL | 80 |
| John | JCHEN | 100 |
| Ki | KGEE | 50 |
| John | JSEO | 50 |
| David | DLEE | 80 |
+
47 rows in set ( 0.00 se
mysql> SELECT emp. first_name, dept. department_id, dept. department_name
FROM employees AS ` emp` JOIN departments AS ` dept` USING ( department_id) ;
+
| first_name | department_id | department_name |
+
| Jennifer | 10 | Administration |
| Michael | 20 | Marketing |
| Pat | 20 | Marketing |
| Den | 30 | Purchasing |
| Alexander | 30 | Purchasing |
| . . . | . . | . . . |
| Nancy | 100 | Finance |
| Daniel | 100 | Finance |
| John | 100 | Finance |
| Ismael | 100 | Finance |
| Jose Manuel | 100 | Finance |
| Luis | 100 | Finance |
| Shelley | 110 | Accounting |
| William | 110 | Accounting |
+
106 rows in set ( 0.00 sec)
mysql> SELECT dept. department_id, emp. job_id, dept. location_id
FROM employees AS ` emp` JOIN departments AS ` dept` USING ( department_id) WHERE dept. department_id = 90 ;
+
| department_id | job_id | location_id |
+
| 90 | AD_PRES | 1700 |
| 90 | AD_VP | 1700 |
| 90 | AD_VP | 1700 |
+
3 rows in set ( 0.00 sec)
mysql> SELECT emp. first_name, dept. department_name, dept. location_id, loca. city
FROM employees AS ` emp` JOIN departments AS ` dept` USING ( department_id)
JOIN locations AS ` loca` USING ( location_id)
WHERE emp. commission_pct IS NOT NULL ;
+
| first_name | department_name | location_id | city |
+
| John | Sales | 2500 | Oxford |
| Karen | Sales | 2500 | Oxford |
| Alberto | Sales | 2500 | Oxford |
| Gerald | Sales | 2500 | Oxford |
| Eleni | Sales | 2500 | Oxford |
| . . . | . . . | . . . | . . . |
| Harrison | Sales | 2500 | Oxford |
| Tayler | Sales | 2500 | Oxford |
| William | Sales | 2500 | Oxford |
| Elizabeth | Sales | 2500 | Oxford |
| Sundita | Sales | 2500 | Oxford |
| Ellen | Sales | 2500 | Oxford |
| Alyssa | Sales | 2500 | Oxford |
| Jonathon | Sales | 2500 | Oxford |
| Jack | Sales | 2500 | Oxford |
| Charles | Sales | 2500 | Oxford |
+
34 rows in set ( 0.00 sec)
mysql> SELECT emp. first_name, emp. job_id, dept. department_id, dept. department_name, loca. city
FROM employees AS ` emp` JOIN departments AS ` dept` USING ( department_id)
JOIN locations AS ` loca` USING ( location_id)
WHERE loca. city = 'Toronto' ;
+
| first_name | job_id | department_id | department_name | city |
+
| Michael | MK_MAN | 20 | Marketing | Toronto |
| Pat | MK_REP | 20 | Marketing | Toronto |
+
2 rows in set ( 0.00 sec)
mysql> SELECT emp. first_name, emp. salary, dept. department_name, loca. street_address
FROM employees AS ` emp` JOIN departments AS ` dept` USING ( department_id)
JOIN locations AS ` loca` USING ( location_id)
WHERE dept. department_name = 'Executive' ;
+
| first_name | salary | department_name | street_address |
+
| Steven | 24000.00 | Executive | 2004 Charade Rd |
| Neena | 17000.00 | Executive | 2004 Charade Rd |
| Lex | 17000.00 | Executive | 2004 Charade Rd |
+
3 rows in set ( 0.00 sec)
mysql> SELECT
emp. employee_id AS '员工id' , emp. first_name AS '员工名字' ,
emp. manager_id AS '管理者id' , mgr. first_name AS '管理者名字'
FROM
employees AS ` emp` LEFT JOIN
employees AS ` mgr` ON emp. manager_id = mgr. employee_id;
+
| 员工id | 员工名字 | 管理者id | 管理者名字 |
+
| 100 | Steven | NULL | NULL |
| 101 | Neena | 100 | Steven |
| 102 | Lex | 100 | Steven |
| 103 | Alexander | 102 | Lex |
| . . . | . . . | . . . | . . . |
| 202 | Pat | 201 | Michael |
| 203 | Susan | 101 | Neena |
| 204 | Hermann | 101 | Neena |
| 205 | Shelley | 101 | Neena |
| 206 | William | 205 | Shelley |
+
107 rows in set ( 0.00 sec)
employee_id 有 107 个 , 某个员工可能有多个下属 , 那就意味着有些员工们是没有下属的 .
左外连接时 , 写在前面的字段允许出现为NULL的情况 .
如果筛选条件是 "emp.employee_id = mgr.manager_id" , 那么会出现很多employee_id为空的情况 .
manager_id与employee_id是多对一的关系 , 那么就要使用 "emp.manager_id = mgr.employee_id" ,
这样不会出现employee_id为NULL的情况 , 只会出现manager_id为NULL的情况 , 这正是我们想要的 .
如果使用使用 "emp.employee_id = mgr.manager_id" , 那么久写成右外连接 , 写在后面的字段允许为NULL , 如下 :
mysql> SELECT
mgr. employee_id AS '员工id' , mgr. first_name AS '员工姓名' ,
emp. employee_id AS '管理者id' , emp. first_name AS '管理者名字'
FROM
employees AS ` emp` RIGHT JOIN
employees AS ` mgr` ON
emp. employee_id = mgr. manager_id;
+
| 员工id | 员工姓名 | 管理者id | 管理者名字 |
+
| 100 | Steven | NULL | NULL |
| 101 | Neena | 100 | Steven |
| 102 | Lex | 100 | Steven |
| 103 | Alexander | 102 | Lex |
| 104 | Bruce | 103 | Alexander |
| 105 | David | 103 | Alexander |
| 106 | Valli | 103 | Alexander |
| 107 | Diana | 103 | Alexander |
| 108 | Nancy | 101 | Neena |
| . . . | . . . | . . . | . . . |
| 201 | Michael | 100 | Steven |
| 202 | Pat | 201 | Michael |
| 203 | Susan | 101 | Neena |
| 204 | Hermann | 101 | Neena |
| 205 | Shelley | 101 | Neena |
| 206 | William | 205 | Shelley |
+
107 rows in set ( 0.00 sec)
mysql> SELECT dept. department_id, dept. department_name, emp. department_id, emp. first_name
FROM employees AS ` emp` RIGHT JOIN departments AS ` dept` USING ( department_id) WHERE emp. first_name IS NULL ;
+
| department_id | department_name | department_id | first_name |
+
| 120 | Treasury | NULL | NULL |
| 130 | Corporate Tax | NULL | NULL |
| 140 | Control And Credit | NULL | NULL |
| 150 | Shareholder Services | NULL | NULL |
| 160 | Benefits | NULL | NULL |
| 170 | Manufacturing | NULL | NULL |
| 180 | Construction | NULL | NULL |
| 190 | Contracting | NULL | NULL |
| 200 | Operations | NULL | NULL |
| 210 | IT Support | NULL | NULL |
| 220 | NOC | NULL | NULL |
| 230 | IT Helpdesk | NULL | NULL |
| 240 | Government Sales | NULL | NULL |
| 250 | Retail Sales | NULL | NULL |
| 260 | Recruiting | NULL | NULL |
| 270 | Payroll | NULL | NULL |
+
16 rows in set ( 0.00 sec)
mysql> SELECT
loca. city, dept. department_name
FROM
departments AS ` dept` RIGHT JOIN
locations AS ` loca` USING
( location_id)
WHERE
dept. department_name IS NULL ;
+
| city | department_name |
+
| Roma | NULL |
| Venice | NULL |
| Tokyo | NULL |
| Hiroshima | NULL |
| South Brunswick | NULL |
| Whitehorse | NULL |
| Beijing | NULL |
| Bombay | NULL |
| Sydney | NULL |
| Singapore | NULL |
| Stretford | NULL |
| Sao Paulo | NULL |
| Geneva | NULL |
| Bern | NULL |
| Utrecht | NULL |
| Mexico City | NULL |
+
16 rows in set ( 0.00 sec)
mysql> SELECT
emp. employee_id, emp. first_name, dept. department_name
FROM
employees AS ` emp` JOIN
departments AS ` dept` USING
( department_id)
WHERE
dept. department_name
IN
( 'Sales' , 'IT' ) ;
+
| employee_id | first_name | department_name |
+
| 103 | Alexander | IT |
| 104 | Bruce | IT |
| 105 | David | IT |
| 106 | Valli | IT |
| . . . | . . . | . . |
| 171 | William | Sales |
| 172 | Elizabeth | Sales |
| 173 | Sundita | Sales |
| 174 | Ellen | Sales |
| 175 | Alyssa | Sales |
| 176 | Jonathon | Sales |
| 177 | Jack | Sales |
| 179 | Charles | Sales |
+
39 rows in set ( 0.00 sec)
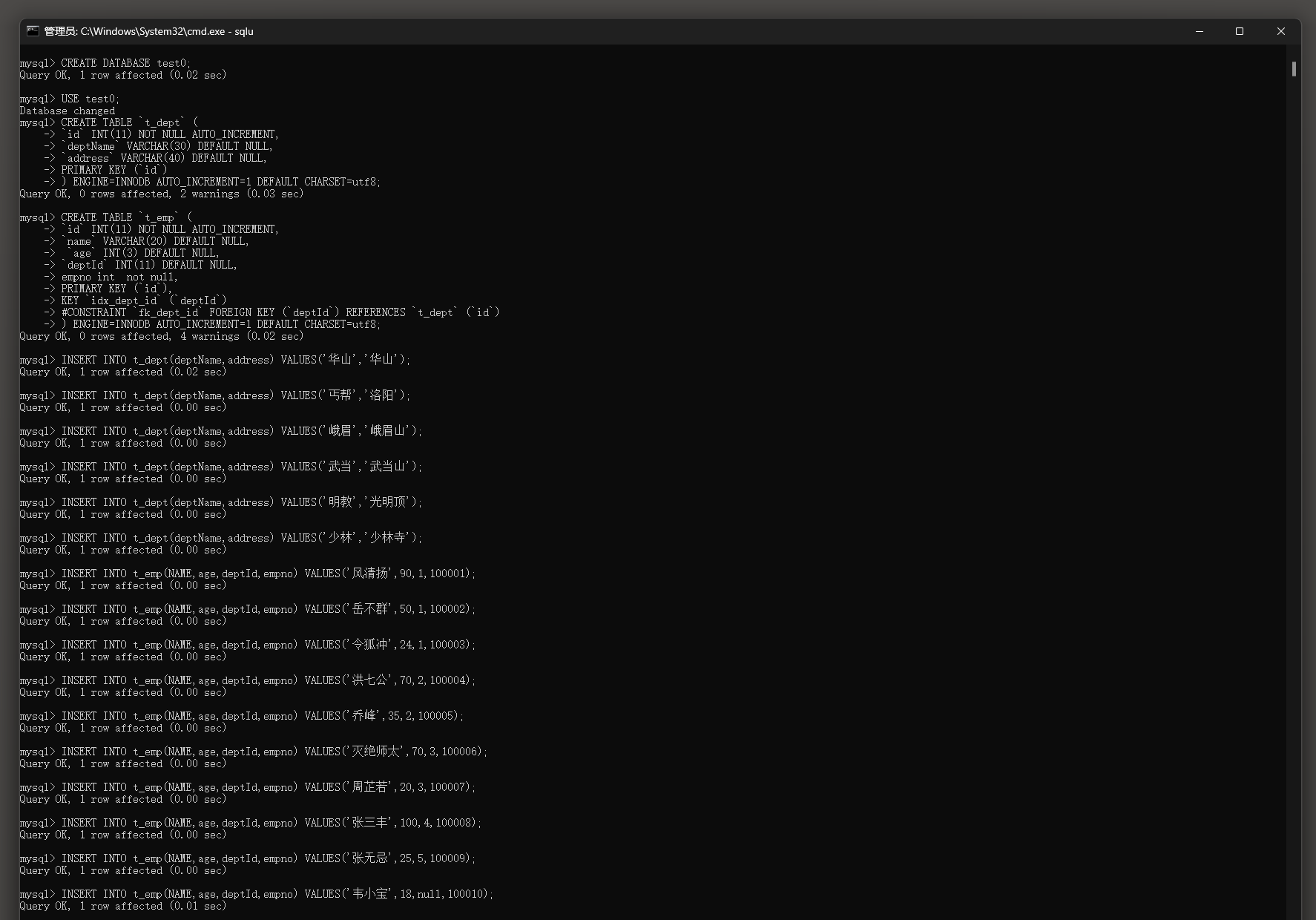
CREATE DATABASE test0;
USE test0;
CREATE TABLE ` t_dept` (
` id` INT ( 11 ) NOT NULL AUTO_INCREMENT ,
` deptName` VARCHAR ( 30 ) DEFAULT NULL ,
` address` VARCHAR ( 40 ) DEFAULT NULL ,
PRIMARY KEY ( ` id` )
) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
CREATE TABLE ` t_emp` (
` id` INT ( 11 ) NOT NULL AUTO_INCREMENT ,
` name` VARCHAR ( 20 ) DEFAULT NULL ,
` age` INT ( 3 ) DEFAULT NULL ,
` deptId` INT ( 11 ) DEFAULT NULL ,
empno int not null ,
PRIMARY KEY ( ` id` ) ,
KEY ` idx_dept_id` ( ` deptId` )
) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
INSERT INTO t_dept( deptName, address) VALUES ( '华山' , '华山' ) ;
INSERT INTO t_dept( deptName, address) VALUES ( '丐帮' , '洛阳' ) ;
INSERT INTO t_dept( deptName, address) VALUES ( '峨眉' , '峨眉山' ) ;
INSERT INTO t_dept( deptName, address) VALUES ( '武当' , '武当山' ) ;
INSERT INTO t_dept( deptName, address) VALUES ( '明教' , '光明顶' ) ;
INSERT INTO t_dept( deptName, address) VALUES ( '少林' , '少林寺' ) ;
INSERT INTO t_emp( NAME, age, deptId, empno) VALUES ( '风清扬' , 90 , 1 , 100001 ) ;
INSERT INTO t_emp( NAME, age, deptId, empno) VALUES ( '岳不群' , 50 , 1 , 100002 ) ;
INSERT INTO t_emp( NAME, age, deptId, empno) VALUES ( '令狐冲' , 24 , 1 , 100003 ) ;
INSERT INTO t_emp( NAME, age, deptId, empno) VALUES ( '洪七公' , 70 , 2 , 100004 ) ;
INSERT INTO t_emp( NAME, age, deptId, empno) VALUES ( '乔峰' , 35 , 2 , 100005 ) ;
INSERT INTO t_emp( NAME, age, deptId, empno) VALUES ( '灭绝师太' , 70 , 3 , 100006 ) ;
INSERT INTO t_emp( NAME, age, deptId, empno) VALUES ( '周芷若' , 20 , 3 , 100007 ) ;
INSERT INTO t_emp( NAME, age, deptId, empno) VALUES ( '张三丰' , 100 , 4 , 100008 ) ;
INSERT INTO t_emp( NAME, age, deptId, empno) VALUES ( '张无忌' , 25 , 5 , 100009 ) ;
INSERT INTO t_emp( NAME, age, deptId, empno) VALUES ( '韦小宝' , 18 , null , 100010 ) ;
mysql> show tables ;
+
| Tables_in_test0 |
+
| t_dept |
| t_emp |
+
2 rows in set ( 0.01 sec)
mysql> select * from t_emp;
+
| id | name | age | deptId | empno |
+
| 1 | 风清扬 | 90 | 1 | 100001 |
| 2 | 岳不群 | 50 | 1 | 100002 |
| 3 | 令狐冲 | 24 | 1 | 100003 |
| 4 | 洪七公 | 70 | 2 | 100004 |
| 5 | 乔峰 | 35 | 2 | 100005 |
| 6 | 灭绝师太 | 70 | 3 | 100006 |
| 7 | 周芷若 | 20 | 3 | 100007 |
| 8 | 张三丰 | 100 | 4 | 100008 |
| 9 | 张无忌 | 25 | 5 | 100009 |
| 10 | 韦小宝 | 18 | NULL | 100010 |
+
10 rows in set ( 0.01 sec)
mysql> select * from t_dept;
+
| id | deptName | address |
+
| 1 | 华山 | 华山 |
| 2 | 丐帮 | 洛阳 |
| 3 | 峨眉 | 峨眉山 |
| 4 | 武当 | 武当山 |
| 5 | 明教 | 光明顶 |
| 6 | 少林 | 少林寺 |
+
6 rows in set ( 0.00 sec)
mysql> SELECT * FROM t_emp JOIN t_dept ON t_emp. deptId = t_dept. id;
+
| id | name | age | deptId | empno | id | deptName | address |
+
| 1 | 风清扬 | 90 | 1 | 100001 | 1 | 华山 | 华山 |
| 2 | 岳不群 | 50 | 1 | 100002 | 1 | 华山 | 华山 |
| 3 | 令狐冲 | 24 | 1 | 100003 | 1 | 华山 | 华山 |
| 4 | 洪七公 | 70 | 2 | 100004 | 2 | 丐帮 | 洛阳 |
| 5 | 乔峰 | 35 | 2 | 100005 | 2 | 丐帮 | 洛阳 |
| 6 | 灭绝师太 | 70 | 3 | 100006 | 3 | 峨眉 | 峨眉山 |
| 7 | 周芷若 | 20 | 3 | 100007 | 3 | 峨眉 | 峨眉山 |
| 8 | 张三丰 | 100 | 4 | 100008 | 4 | 武当 | 武当山 |
| 9 | 张无忌 | 25 | 5 | 100009 | 5 | 明教 | 光明顶 |
+
9 rows in set ( 0.00 sec)
mysql> SELECT * FROM t_emp LEFT JOIN t_dept ON t_emp. deptId = t_dept. id;
+
| id | name | age | deptId | empno | id | deptName | address |
+
| 1 | 风清扬 | 90 | 1 | 100001 | 1 | 华山 | 华山 |
| 2 | 岳不群 | 50 | 1 | 100002 | 1 | 华山 | 华山 |
| 3 | 令狐冲 | 24 | 1 | 100003 | 1 | 华山 | 华山 |
| 4 | 洪七公 | 70 | 2 | 100004 | 2 | 丐帮 | 洛阳 |
| 5 | 乔峰 | 35 | 2 | 100005 | 2 | 丐帮 | 洛阳 |
| 6 | 灭绝师太 | 70 | 3 | 100006 | 3 | 峨眉 | 峨眉山 |
| 7 | 周芷若 | 20 | 3 | 100007 | 3 | 峨眉 | 峨眉山 |
| 8 | 张三丰 | 100 | 4 | 100008 | 4 | 武当 | 武当山 |
| 9 | 张无忌 | 25 | 5 | 100009 | 5 | 明教 | 光明顶 |
| 10 | 韦小宝 | 18 | NULL | 100010 | NULL | NULL | NULL |
+
10 rows in set ( 0.00 sec)
mysql> SELECT * FROM t_emp RIGHT JOIN t_dept ON t_emp. deptId = t_dept. id;
+
| id | name | age | deptId | empno | id | deptName | address |
+
| 1 | 风清扬 | 90 | 1 | 100001 | 1 | 华山 | 华山 |
| 2 | 岳不群 | 50 | 1 | 100002 | 1 | 华山 | 华山 |
| 3 | 令狐冲 | 24 | 1 | 100003 | 1 | 华山 | 华山 |
| 4 | 洪七公 | 70 | 2 | 100004 | 2 | 丐帮 | 洛阳 |
| 5 | 乔峰 | 35 | 2 | 100005 | 2 | 丐帮 | 洛阳 |
| 6 | 灭绝师太 | 70 | 3 | 100006 | 3 | 峨眉 | 峨眉山 |
| 7 | 周芷若 | 20 | 3 | 100007 | 3 | 峨眉 | 峨眉山 |
| 8 | 张三丰 | 100 | 4 | 100008 | 4 | 武当 | 武当山 |
| 9 | 张无忌 | 25 | 5 | 100009 | 5 | 明教 | 光明顶 |
| NULL | NULL | NULL | NULL | NULL | 6 | 少林 | 少林寺 |
+
10 rows in set ( 0.00 sec)
mysql> SELECT * FROM t_emp LEFT JOIN t_dept ON t_emp. deptId = t_dept. id WHERE t_dept. id IS NULL ;
+
| id | name | age | deptId | empno | id | deptName | address |
+
| 10 | 韦小宝 | 18 | NULL | 100010 | NULL | NULL | NULL |
+
1 row in set ( 0.00 sec)
mysql> SELECT * FROM t_emp RIGHT JOIN t_dept ON t_emp. deptId = t_dept. id WHERE t_emp. id IS NULL ;
+
| id | name | age | deptId | empno | id | deptName | address |
+
| NULL | NULL | NULL | NULL | NULL | 6 | 少林 | 少林寺 |
+
1 row in set ( 0.00 sec)
mysql> SELECT * FROM t_emp LEFT JOIN t_dept ON t_emp. deptId = t_dept. id
UNION
SELECT * FROM t_emp RIGHT JOIN t_dept ON t_emp. deptId = t_dept. id;
+
| id | name | age | deptId | empno | id | deptName | address |
+
| 1 | 风清扬 | 90 | 1 | 100001 | 1 | 华山 | 华山 |
| 2 | 岳不群 | 50 | 1 | 100002 | 1 | 华山 | 华山 |
| 3 | 令狐冲 | 24 | 1 | 100003 | 1 | 华山 | 华山 |
| 4 | 洪七公 | 70 | 2 | 100004 | 2 | 丐帮 | 洛阳 |
| 5 | 乔峰 | 35 | 2 | 100005 | 2 | 丐帮 | 洛阳 |
| 6 | 灭绝师太 | 70 | 3 | 100006 | 3 | 峨眉 | 峨眉山 |
| 7 | 周芷若 | 20 | 3 | 100007 | 3 | 峨眉 | 峨眉山 |
| 8 | 张三丰 | 100 | 4 | 100008 | 4 | 武当 | 武当山 |
| 9 | 张无忌 | 25 | 5 | 100009 | 5 | 明教 | 光明顶 |
| 10 | 韦小宝 | 18 | NULL | 100010 | NULL | NULL | NULL |
| NULL | NULL | NULL | NULL | NULL | 6 | 少林 | 少林寺 |
+
11 rows in set ( 0.00 sec)
mysql> SELECT * FROM t_emp LEFT JOIN t_dept ON t_emp. deptId = t_dept. id WHERE t_dept. id IS NULL
UNION
SELECT * FROM t_emp RIGHT JOIN t_dept ON t_emp. deptId = t_dept. id WHERE t_emp. id IS NULL ;
+
| id | name | age | deptId | empno | id | deptName | address |
+
| 10 | 韦小宝 | 18 | NULL | 100010 | NULL | NULL | NULL |
| NULL | NULL | NULL | NULL | NULL | 6 | 少林 | 少林寺 |
+
2 rows in set ( 0.00 sec)