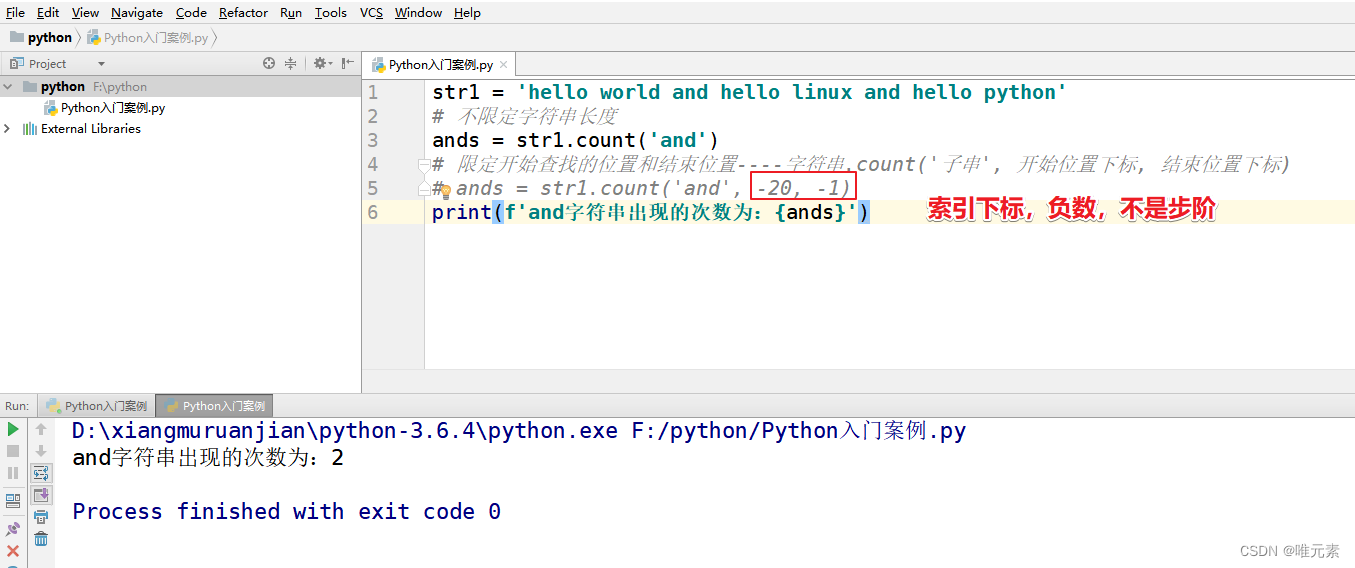
文章目录
- Input partitioning
- input partitioning 的目的
- computational / domain faults
- 等价类(equivalence classes)
- input conditions & valid / invalid inputs
- partitioning and equivalence classes
- 等价类划分的原则
- 白盒 - Domain testing
- 复合谓词 (compound predicates)
- 程序中的循环
- 黑盒 - Equivalence Partitioning
- step1:识别初始的等价类
- guideline1 - Range
- guideline2- 离散集合
- guideline3- 输入数量
- guideline4- zero-one-many
- guideline5 - Must rule
- guideline-6 知觉 + 经验
- step2: 合并并减少等价类
- step3:选择 test cases
- 实例
- Test Template Trees
- start:从 testable input domain 开始
- repeat
- End
- Result
- 缓解 tree 爆炸的问题
- Combining partition 组合分区
- All Combinations
- Each Choice Combinations
- Pair-Wise Combinations
- 简单总结
Input partitioning
input partitioning 的目的
-
在之前的章节中提到 input domain 是 program / function 的所有可能的输入
-
但是这些输入中有一些是没有意义的,而且如果全部测量的话也是非常耗时的
-
因此如何筛选出一部分 input test cases 能够又快又好地找出
failures就是 testing 中关注的重点 -
这部分 input partitioning
- 我们可以将很多 test case 划分成相同的类别 (equivalence class 等价类) 从而用一个 test case 就能代替一群,这样也可以提高 test 效率而且还有助于更快发现 failure
-
使用 input partitioning 相当于使用一个分类器,将所有的 input 划分成不同的类别 (input class),每个类别经过相同的代码段和处理
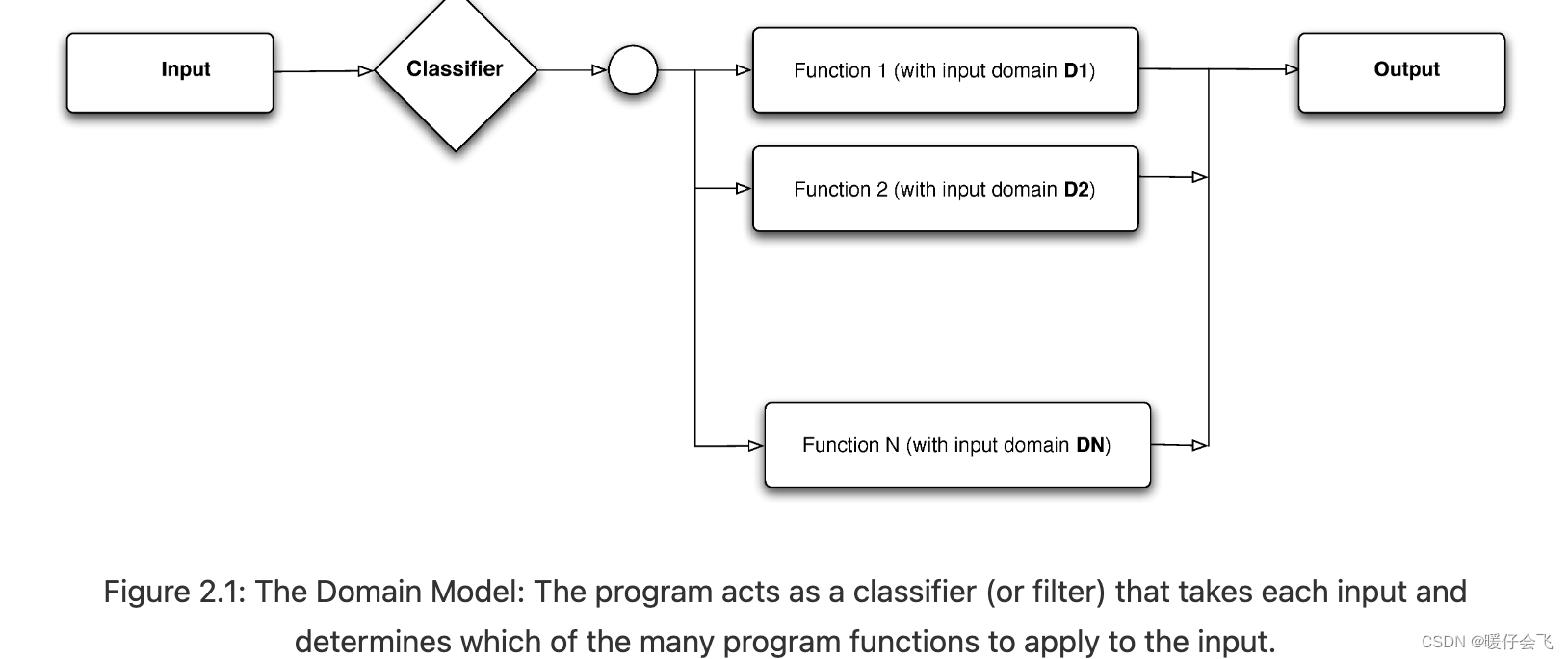

-
这个 D i D_i Di 代表的就是所有 input 切分成多个类别中的第 i i i 个输入类; F i F_i Fi 表示就是这一类的输入经过的都是同一个函数

computational / domain faults
-
上述代码中可以认为分成了两个 F 1 F_1 F1 和 F 2 F_2 F2 其中 F 1 F_1 F1 包含
3, 4, 5, and 7行, F 2 F_2 F2 包含3, 4, and 7行 -
根据对程序的这种观点,存在两种可能的故障类型 (types of faults):
-
计算故障:(computational faults) 在选择了正确路径但沿该路径发生了错误计算;以及
-
领域故障:(domain faults): 在每个路径上计算都是正确的,但选择了错误的路径。
-
导致选择错误路径的可能原因有:(1)输入领域执行了错误路径;(2)构成路径选择的决策可能包含故障;以及(3)正确路径(或用于计算所必需的部分路径片段)可能被简单地遗漏。
输入划分的目标是派生测试输入,至少能够执行程序中每个函数一次。在本章中,我们介绍了两种将输入划分为等价类别的方法。
等价类(equivalence classes)

- 例如在前面的 2.1 图中, D i D_i Di 就是第 i i i 个等价类,其中的测试用例都是等价的
if / else / while这些条件可以天然地划分等价类
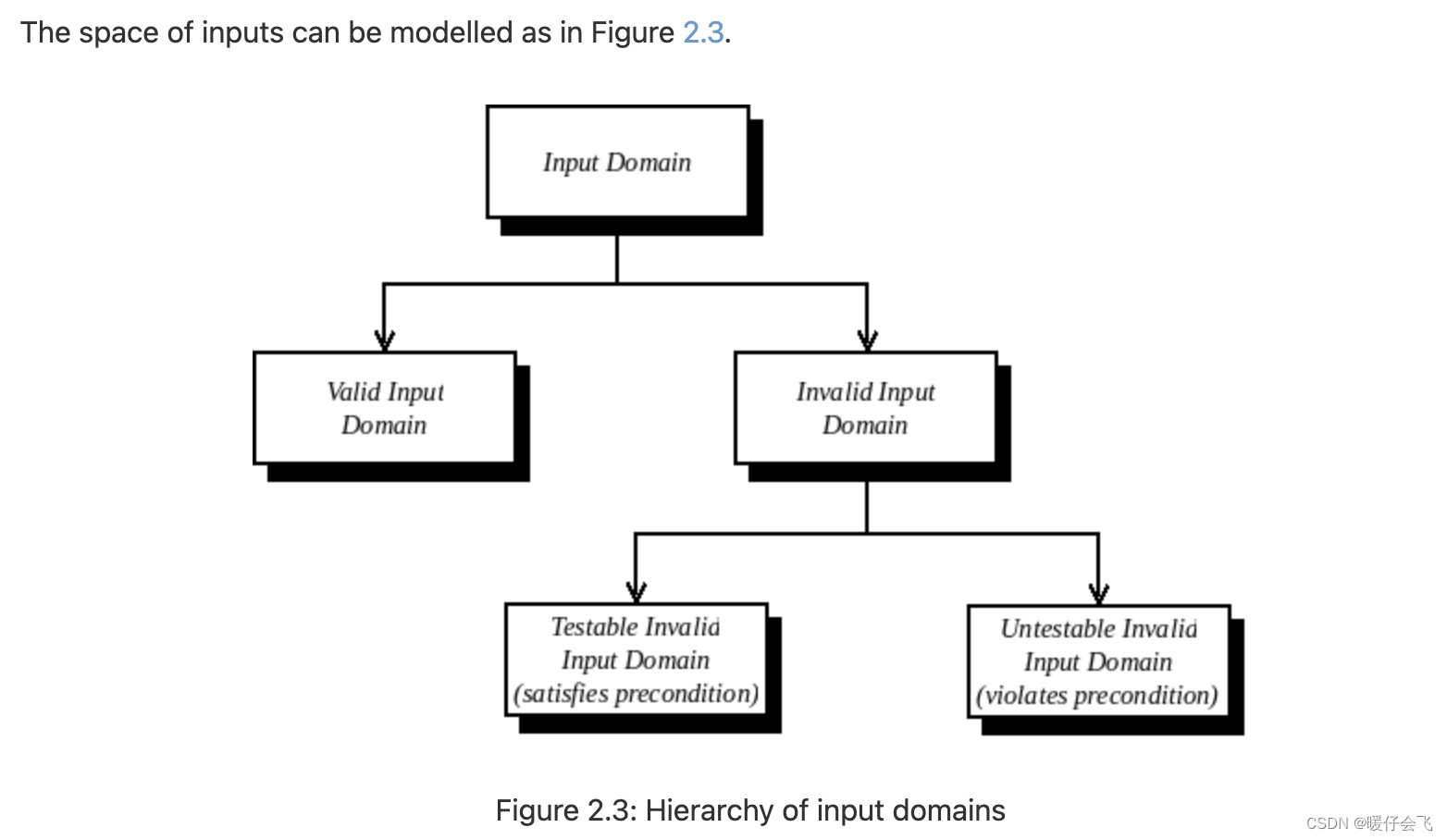
input conditions & valid / invalid inputs

- input domain 上的输入条件 (input condition) 是对输入域中单个变量值 single variable 的谓词 (predicate)。当我们需要考虑输入域中多个变量的值时,我们称之为输入条件的组合。
- valid input 指的是符合 specification 的 input case,例如根据程序的 specification 能够不触发错误,如果 function 传入的参数是 divide 的分母,那么
0就是一个 invalid 的输入,除了 0 以外的其他值都是 valid - invalid input 是输入域中不被期望或由程序规范给出的错误值的元素。换句话说,无效输入是指在输入域中不是有效输入的值。invalid 还包括 testable 和 non testable 的 input
- non testable 的输入是 违反程序前置条件的输入。前置条件是对程序输入变量的一种假设,即在执行该程序时假定满足该条件。这意味着程序员明确假设前置条件在程序开始时成立,并且因此,对于任何违反前置条件的输入,程序的行为是 undefined。 如果行为未定义,则我们不进行测试。比如如果程序要求是 有序的列表(在 binary search 中),这是一个前置条件,硬性要求,不满足就直接没有测试的必要,因此是
non-testable - testable 但 invalid 输入是指不违反前置条件但仍然无效的输入。 通常情况下,这些指代返回错误代码或抛出异常的输入。
- non testable 的输入是 违反程序前置条件的输入。前置条件是对程序输入变量的一种假设,即在执行该程序时假定满足该条件。这意味着程序员明确假设前置条件在程序开始时成立,并且因此,对于任何违反前置条件的输入,程序的行为是 undefined。 如果行为未定义,则我们不进行测试。比如如果程序要求是 有序的列表(在 binary search 中),这是一个前置条件,硬性要求,不满足就直接没有测试的必要,因此是
partitioning and equivalence classes
- 等价类划分基于的假设是,等价划分背后的假设是,类的所有成员在故障方面表现出相同的方式,因此选择等价类中的任何一个成员与其他成员相比,在检测到故障的可能性上是相同的。

- 虽然这个假设是错误的,但是依然是价值的
等价类划分的原则
- 任何两个等价类不重叠(disjoint)
- 等价类的总和要覆盖所有的 input domain
白盒 - Domain testing

- 首先将输入空间划分为一组互斥的等价类。每个等价类对应一个程序路径。
- 其思想是基于 domain 边界选择测试用例,并探索 domain 边界以确定 sub-domains 是否正确。 (Domain Testing 不仅关注等价类,而且特别关注边界值,因为历史数据和经验告诉我们大部分的错误发生在输入或输出范围的边界上。)更准确地说,从以下两个方面选择测试用例:
- 领域边界;
- 靠近领域边界的点。


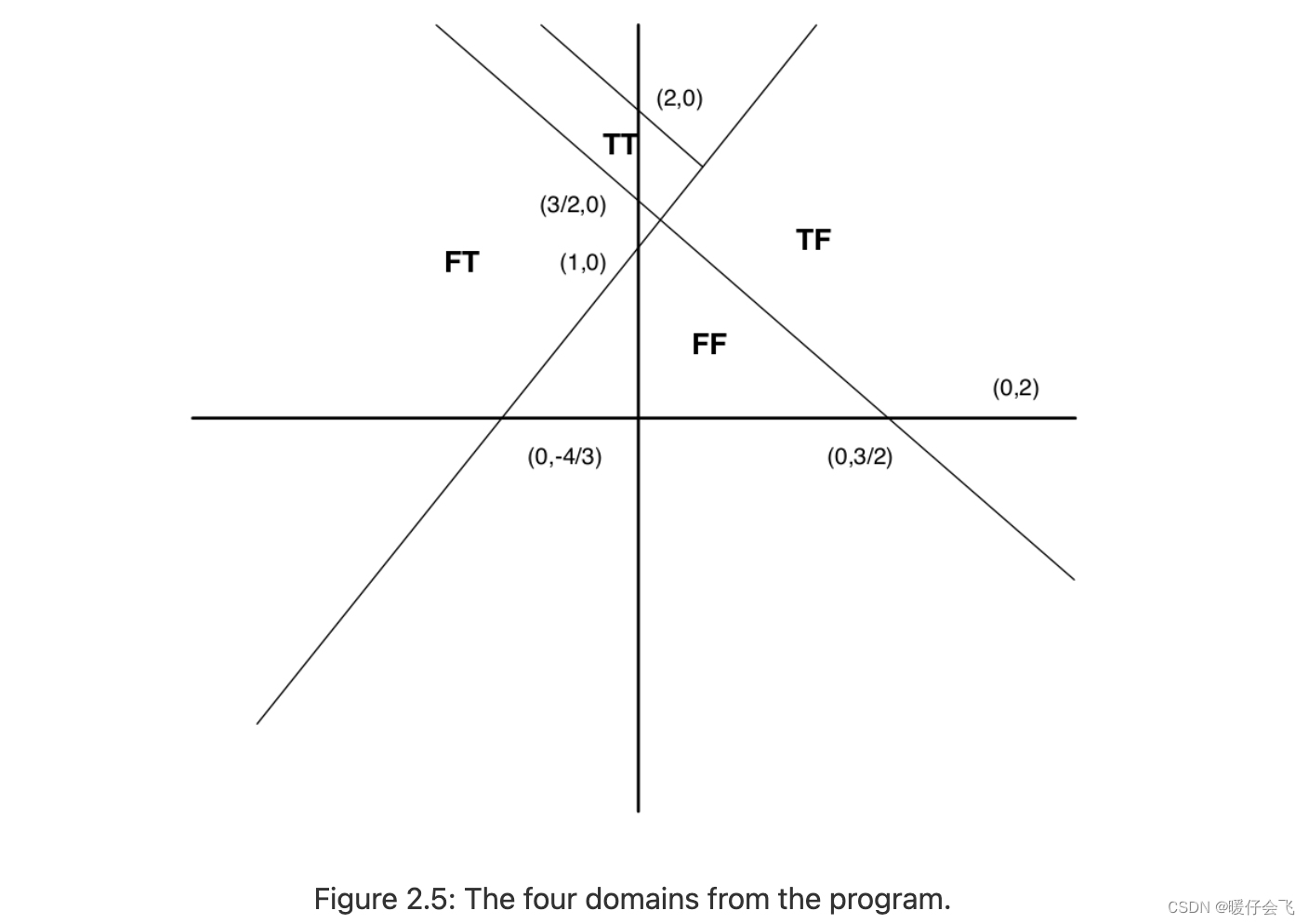
- 上述内容有 4 条path,因此有 4 个 input domain
- 每个域都由一个线性边界定义。这些在图2.5中显示。在这个图中,TT指的是程序中两个分支都评估为真的域。TF、TF和FF与其他可能的评估类似地被定义。

- 如果程序的分支使得某些路径不可行,则该路径的域为空。

- 但 domain testing 假设程序是线性域的组合
- 线性边界需要更少的测试点来进行检查,并且可以以更高的确定性进行检查。如果一个程序违反了这个假设,那么使用这种策略进行测试可能不如在程序满足假设的情况下发现错误有效,因为解决非线性等式和不等式比解决线性等式和不等式要困难得多。 在非线性情况下,一个点可能位于一个域中,但计算上过于昂贵而无法准确检查;例如,一个多项式:
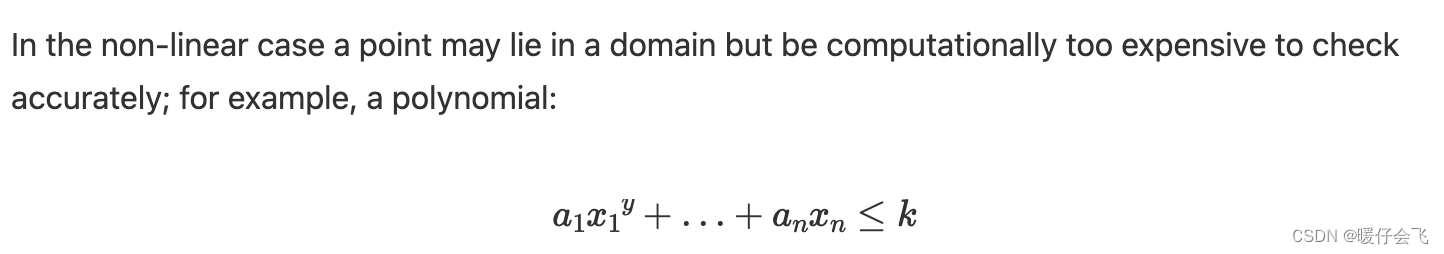
复合谓词 (compound predicates)
-
简单谓词决定简单的边界情况
-
复合谓词导致复杂的边界情况,甚至定义一个突边界( A N D AND AND);而通过 O R OR OR 构建的复合谓词,则导致了不连续的、不重叠的边界

-
为了解决这个问题,将用 O R OR OR 构建的复合谓词转化为两个条件:
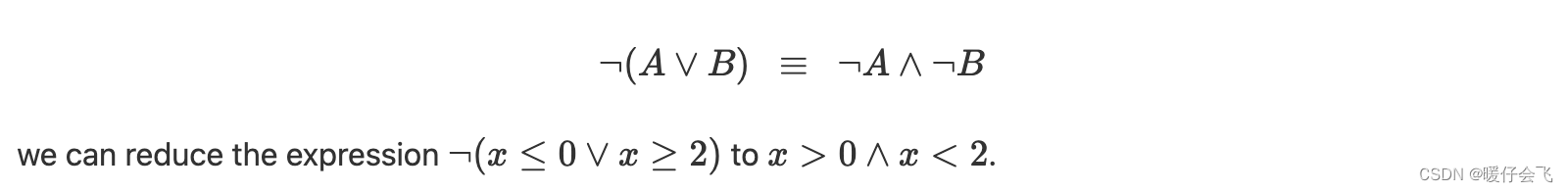
程序中的循环
- 对于一些包含循环的程序,我们有 无限多个路径,因此也有 无限多个等价类。为每个等价类选择测试输入显然是不可能的,所以我们需要一种技术来使其变得有限。
一个典型的解决方法是应用 zero-to-many 规则。即某段程序可以执行的最小次数是零, 因此这是一条路径。 同样地,**某些循环具有上界,所以将其视为一条路径。**关于循环的一个通用准则是选择能够执行该循环的测试输入:

对于循环次数有上限的程序,让
N
+
1
N+1
N+1 等于运行次数的上限。


- 第一个 predicate 是个复合谓词,在这里简写为 v a l i d ( x , y , z ) valid(x,y,z) valid(x,y,z)
- 针对 isosceles case (等腰三角形的情况),有三种等价类:
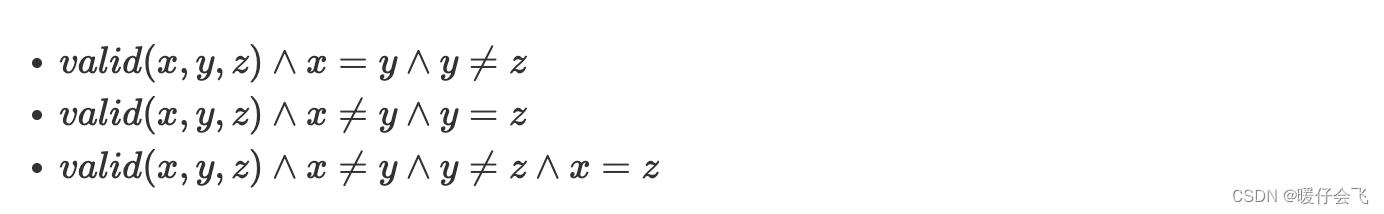
- 对于普通的三角形,有一种等价类:

- 对于等边三角形有一种等价类:
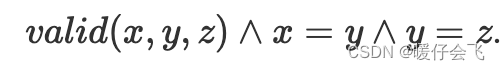
- 对于 invalid 的三角形,有一种等价类:
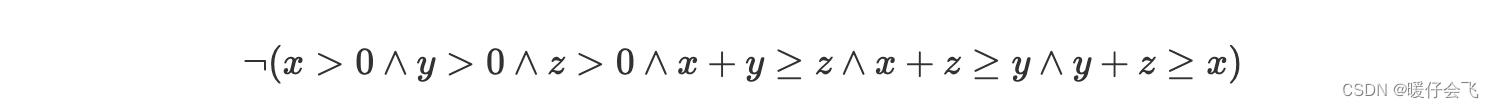
黑盒 - Equivalence Partitioning
- 目标是尽量减少所需的测试用例数量,以覆盖您已经确定的所有等价类。通常方法只需要三个步骤:
- 识别初始的等价类
- 识别 overlap 的等价类,并且将重叠部分划分成新的等价类
- 从每个等价类中选择一个元素作为测试输入,并计算出该测试输入的预期结果。

step1:识别初始的等价类
有 6 个原则:
guideline1 - Range
- 如果输入条件指定了一个值范围,请为该范围内的值集合确定 一个有效等价类,以及两个无效等价类;一个用于范围下方的值集合,另一个用于范围上方的值集合。

guideline2- 离散集合
- 集合中的每个元素确定一个有效等价类,以及对于不在该集合中的元素确定一个无效等价类。

guideline3- 输入数量

- 规定输入数量为一个定值(例如 3),那么将输入 3 个值为有效等价类, < 3 <3 <3 和 > 3 >3 >3 个值分别作为无效的等价类
guideline4- zero-one-many
- 如果输入条件指定输入是一组项目,并且该集合的大小可以变化;例如,一个元素列表或集合;为大小为 0 0 0 的集合定义一个有效等价类,为大小为 1 1 1 的集合定义一个有效等价类,并为大小 > 1 >1 >1 的集合定义为一个有效的等价类
- 如果同时有上界的话,那么 > 1 >1 >1 的集合应该变成 > 1 a n d < u p p e r b o u n d >1 and < upper~ bound >1and<upper bound 的集合
guideline5 - Must rule
- 应用在
must be的场景中,例如下面要求第一个字母是数字,那么这种情况将第一个字母是数字的看成是有效等价类,而其他的是无效的等价类

guideline-6 知觉 + 经验

step2: 合并并减少等价类
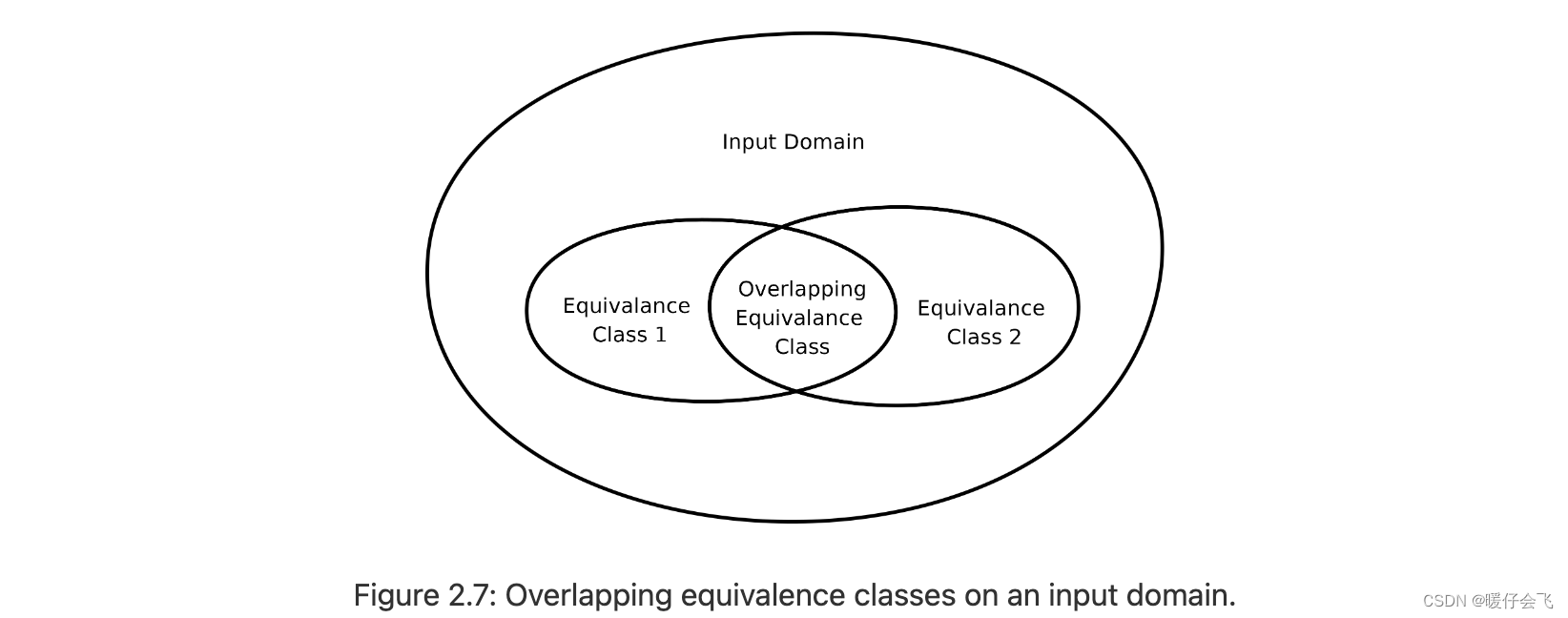
- 很多等价类中有重合的部分

- 消除重叠之后:

step3:选择 test cases
- 一旦等价类被确定,选择测试用例就很简单了。等价类中的任何一个值都被认为与该类中的其他任何值一样可能导致失败,因此该类的任何元素都可以作为测试输入,并且从该类中选择任意元素即可。
实例

- 这个程序需要三个输入 (x,y,z)
- 程序会根据 x,y,z 的值打印其是什么类型的三角形
-
一个潜在的 specification 是:x,y,z 的值都要 > 0 > 0 >0 因此根据
must rule原则,我们可以定义 > 0 >0 >0 的是 valid 的等价类,而 < = 0 <=0 <=0 的是无效等价类

-
然而这三个条件本就是互不重叠的,因此我们其实可以将这三个条件写成一个等价类:
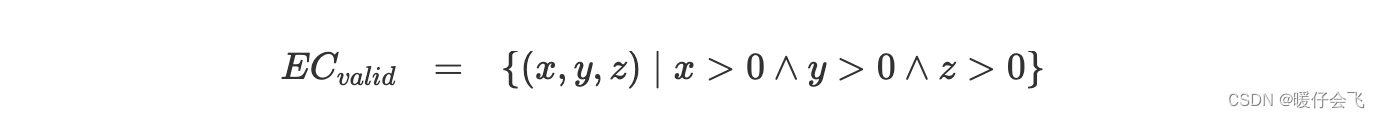
-
同样的,我们可以继续将这个条件丰富为:三边都 > 0 且任意两边之和大于第三边,因此等价类可以进一步被丰富为:
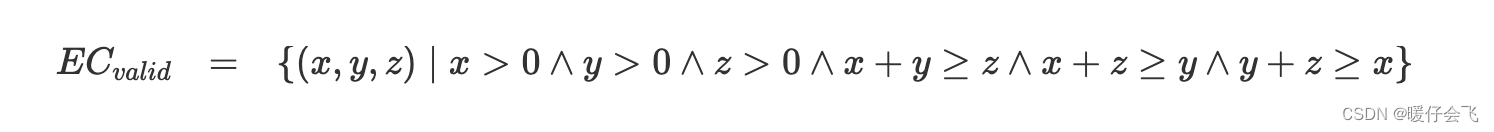
-
接下来就是按照不同的三角形种类来划分等价类了,这非常直觉:
- 对于等边三角形:
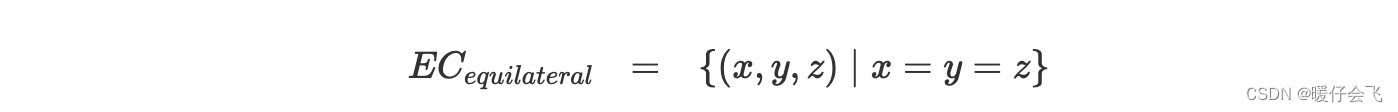
- 对于等腰三角形应该有 3 个不同的等价类(其实相当于一种,因此可以写成一个等价类): x = y ≠ z O R x = z ≠ y O R z = y ≠ x x=y≠z ~OR ~x=z≠y ~OR ~z=y≠x x=y=z OR x=z=y OR z=y=x
- 对于其他类型的三角形则是三边都不等 x ≠ y ≠ z x≠y≠z x=y=z
- 对于等边三角形:
-
对于 invalid 的三角形,应该是以下六类:

-
当然上面的等价类都有重叠:
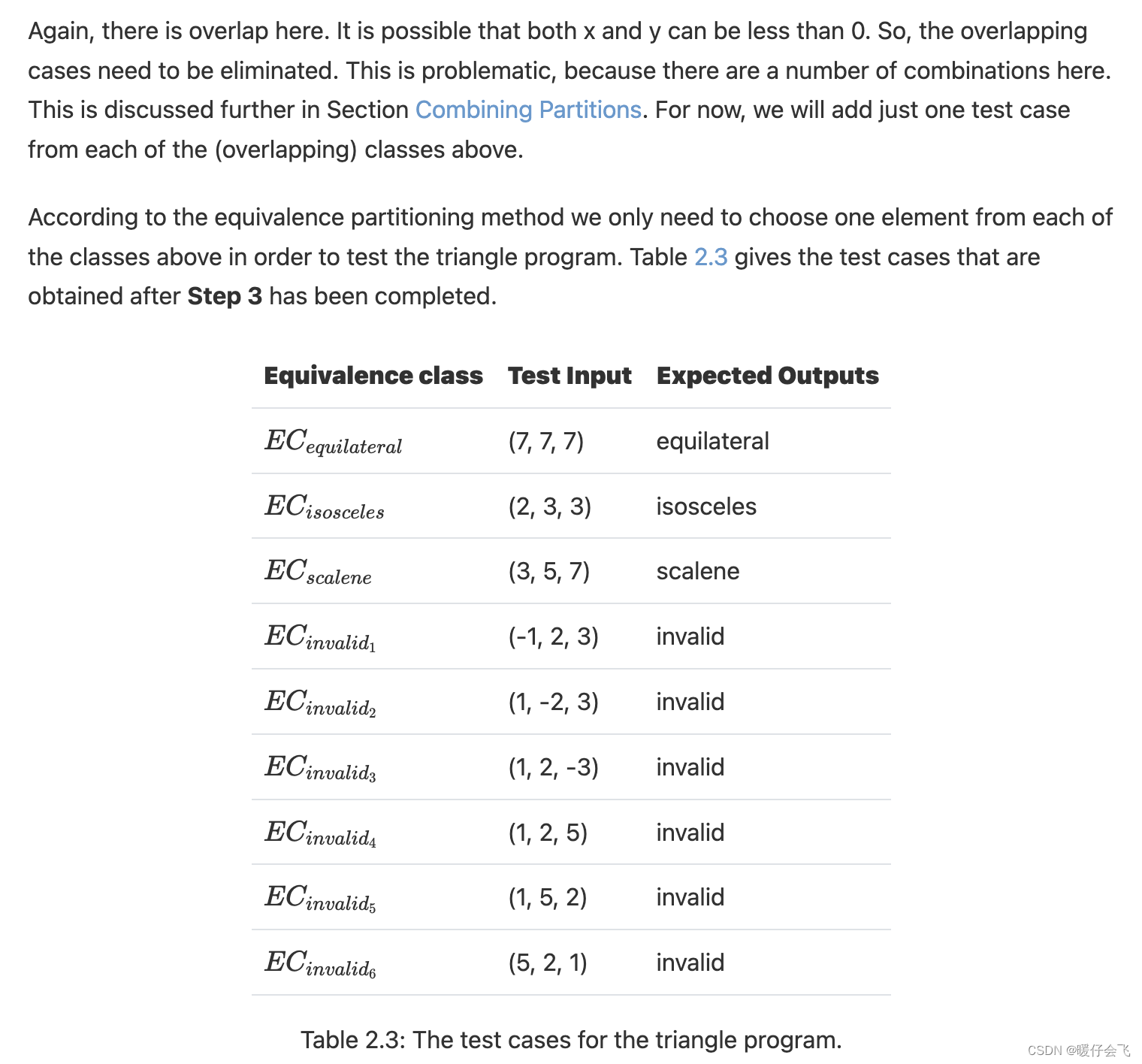
-
对于每一个不同的等价类都找一个 test case
-
但这样随机从等价类中选一个值并不是最优的方法,因为很有可能存在那种 coincidental correct,但是测试人员对此并不知情
-
很直觉的方法是从一个等价类中选择多个 test cases,但这会让 test suites 的规模变大
-
boundary value analysis 是一种比 equivalence partitioning 更好的办法,但对 平方函数 中的那种 coincidental correct 也无效

-
GetWord函数必须接受一个字符串,并返回两个项目:
- (1)字符串中的第一个单词;
- 和(2)删除了第一个单词后的字符串。
-
单词被认为是不包含空白字符的一串字符。
-
单词之间的空白字符可以是空格、制表符或换行符。
-
字符串长度最长为200个字符。

-
等价划分只需要指定程序来推导测试用例。这使得它非常适合 系统级测试和集成级测试。
-
由于此函数只能接受 200 个字符以内的输入,因此可以使用 range guideline :

-
由于输入是一个字符串,而且 specification 中提到,切分完的字符串要具备一系列条件,因此我们可以将字符串的 EC 进行细分:

-
同样的,等价类之间也存在重叠,因此最后三个是可以一定程度合并的,所以可以有下面的测试用例:
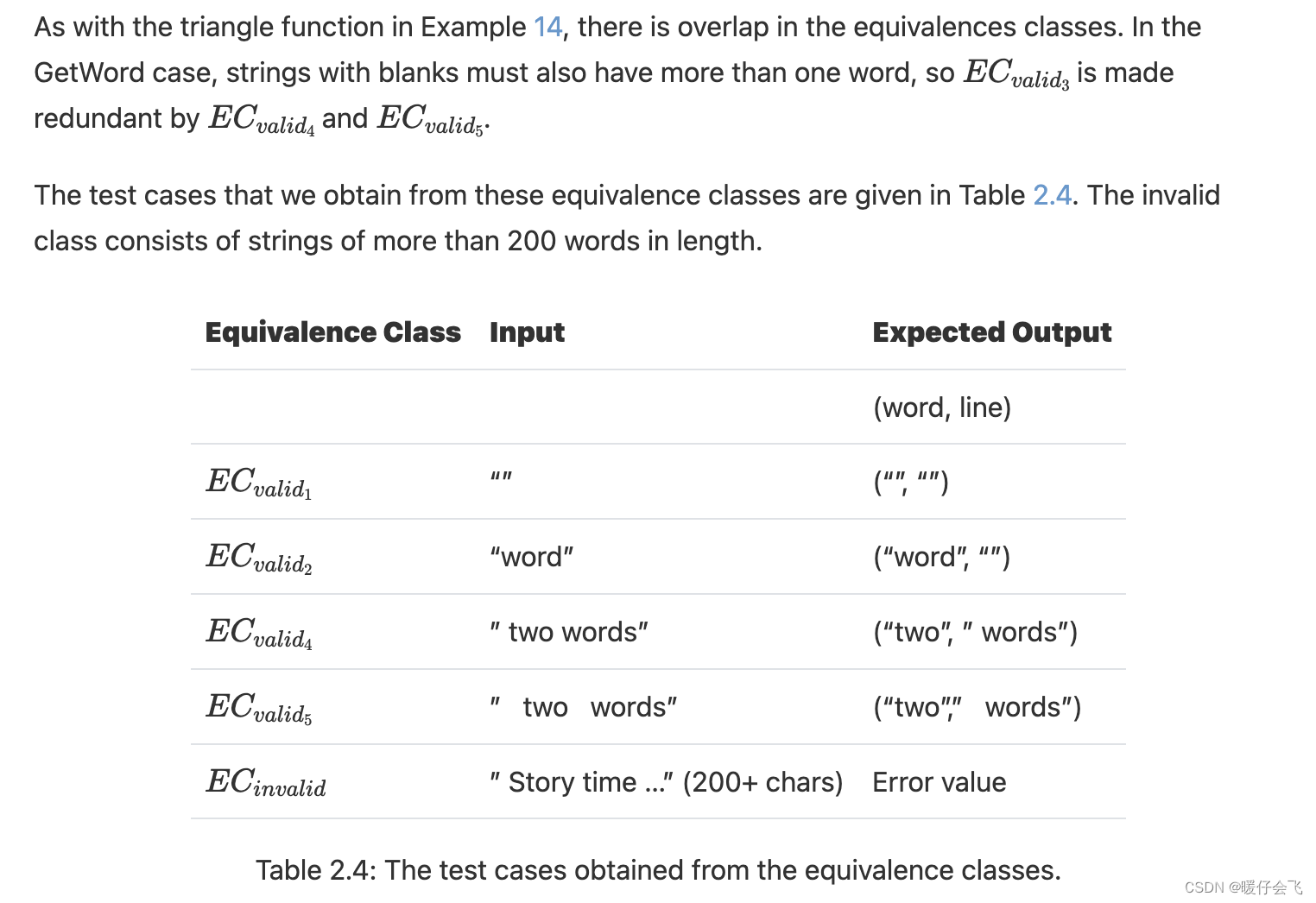
Test Template Trees
- 相比于 等价类划分,使用这种树的方式是一种更加结构化的方法,可以在开始的时候就避免引入 overlapping

start:从 testable input domain 开始
- 从可测试的输入域开始,并旨在将其分解为更小的等价类,以便进行良好的测试。
repeat
- 每个步骤中,我们选择一个等价划分准则来应用于测试模板树中的一个或多个叶节点,将叶节点分解为多个新的叶节点,每个新的叶节点比其父节点更具体,并且不再是一个叶节点。

- 当我们对每个叶节点进行分区时,我们确保分区是:
- (a)不相交的-分区不重叠;和
- (b)它们的父节点被其子节点所覆盖
End
当满足以下条件之一时,该过程结束:
- (a) 没有更多合理的分区可应用;
- 或者 (b) 我们的树变得太大,无法再管理复杂性(尽管我们很快将讨论如何缓解这个问题)。
Result
- 构建等价类时,我们只需取每个叶节点,并从该叶节点到树的根派生出等价关系。
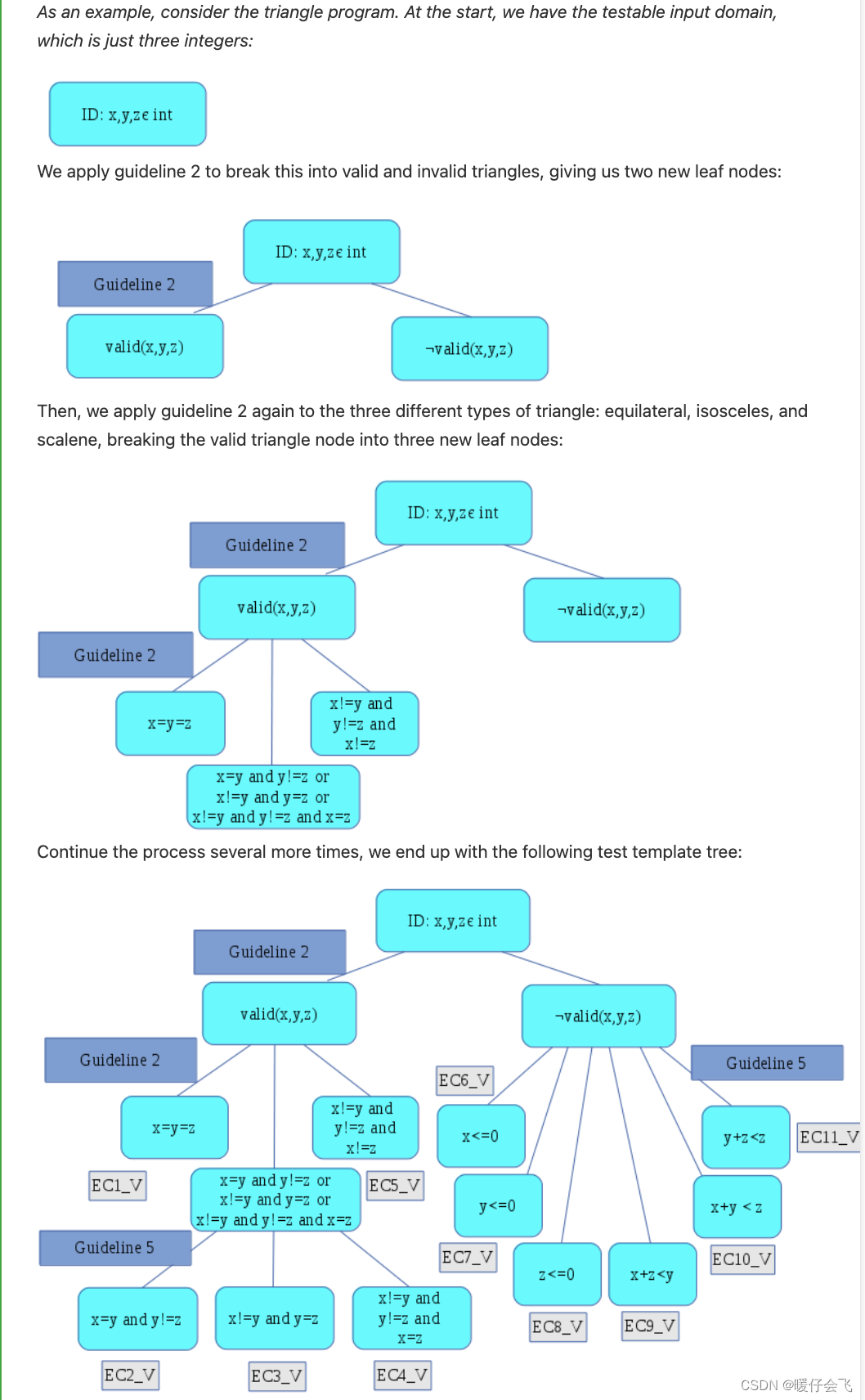

缓解 tree 爆炸的问题
- 只对无效、异常和错误情况进行一次测试: 由于许多程序使用防御性编程,一旦检测到错误或异常输入,程序往往会立即抛出错误或异常,并停止进一步执行。因此,对于引发异常的输入,进一步细分并测试正常情况下的功能是不太可能发现更多错误的,因为异常输入导致的错误或异常往往发生在程序的前端,所以程序的后续部分并不会执行。简而言之,对于会立即引发异常的输入,进行多个正常情况下的功能测试是不必要的,因为它们不会触发程序的其他部分,也就不会发现额外的错误。
- 重点考虑变量之间的相互作用: 在应用等价划分原则时,应当基于经验和直觉,选择那些涉及变量相互作用可能性的当前叶节点进行细分。以图书馆借阅系统为例,系统输入包括借出日期、借阅时长、书籍/DVD名称、作者等。借出日期和借阅时长之间存在明显的相互作用,因为它们共同决定了归还日期。而书名和作者与归还日期(可能)无关。因此,在测试借阅时长的不同值时,应该优先考虑与借出日期相关的节点,而不是书名和作者。**这样做可以减少需要应用的划分数量,**从而避免测试用例数量爆炸性增长的问题。
Combining partition 组合分区
- 当对程序的多个变量应用不同的标准时,很容易生成 重叠的等价类。举例来说,如同在之前例子中提到的三角形程序测试中,通过对三个不同变量应用两种不同标准,生成了六个表示无效三角形的重叠等价类。
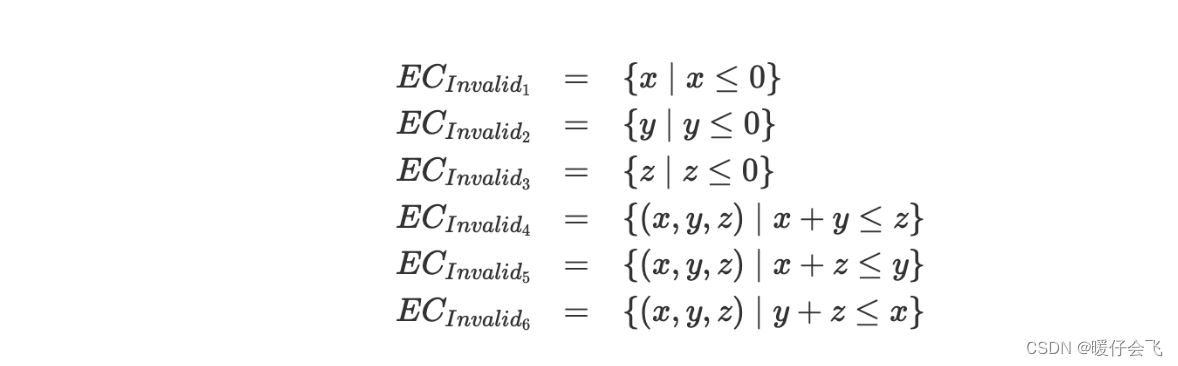
如果尝试移除这些重叠的情况,将产生大量的测试用例(因为我们需要对重叠的等价类进行进一步细分,这个过程产生很多 test cases),其中许多可能并不实用。举例来说,其中的三个测试案例可能如下:
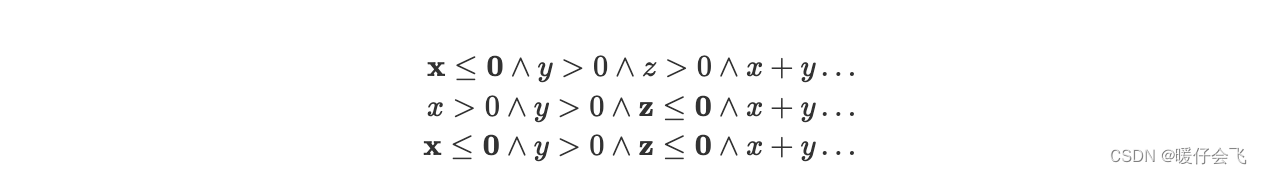
- 这些中的粗体表示使三角形 invalid 的值
- 虽然看起来是三个不同的等价类,但其实有冗余,因为对于第三个 EC 来说,程序顺序执行,当检测到 x < = 0 x<=0 x<=0 其实就已经无效了,这个结果跟 case1 是一样的,所以是冗余的
- 冗余不是唯一的问题。如果我们考虑在三个不同变量上使用分区方法,一个具有非负整数域(变量x),一个具有非正整数域(变量y),以及一个具有字符z域,我们可能会得到以下分区:

- Ammann和Offutt将这些块组合称为**“block combinations”,因为尽管等价类有重叠,但存在着某种不同的独特块**。在上述情况中,这些块是基于变量的,并且每个变量都有对应的等价类。
- 当我们组合变量时,会遇到重叠。问题是如何解决重叠,以免产生过多的测试用例。我们提出了三个不同的准则来解决这个问题:全组合准则 (all combinations)、两两组合准则 (pair-wise combination)和每项选择组合准则 (each choice combination)。
All Combinations
- 全组合准则指定必须使用每个块之间的等价类的所有组合。这类似于集合的笛卡尔积。因此,如果我们考虑具有输入x、y和z的程序,则我们需要18个测试用例:
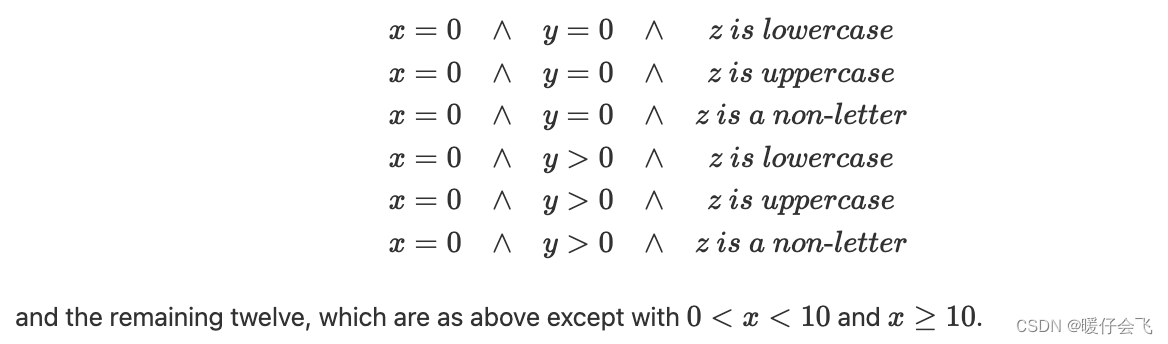
- 测试用例的数量是每个块中的 block 数和 EC 数的乘积。在这种情况下,它与变量的数量以及每个变量的等价类别数有关。因此,如果有两个额外的变量,每个变量都有三个等价类别,则测试用例的数量将为
3
∗
2
∗
3
∗
3
∗
3
=
162
3*2*3*3*3=162
3∗2∗3∗3∗3=162 test cases.

Each Choice Combinations
- 每个选择准则指定只能从每个等价类中选择一个测试用例。这是我们在示例14中对三角形程序进行测试时采取的方法。 以三变量程序为例,每个选择准则可以通过选择满足以下三个等价类的输入来满足

Pair-Wise Combinations
-
配对组合准则旨在将值进行组合,但不是对所有可能的组合进行详尽枚举。顾名思义,每个块中的等价类必须与其他所有块中的每个等价类配对。
-
在我们上面的例子中,这意味着我们必须有测试用例来满足以下21种配对组合:


-
然而,一个单独的测试输入可以涵盖其中多个。例如,测试输入:
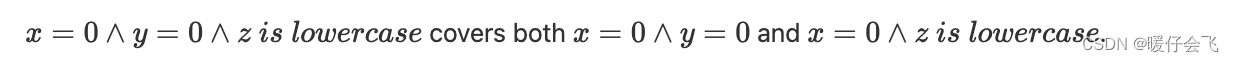
-
考虑到这一点,我们可以选择只满足九个等价类的测试用例;以下是其中三个:

简单总结
- input partitioning 分为 domain testing (白盒测试,主要注重边界情况) 和 equivalence partitioning (黑盒测试方法)
- 当等价类划分有重叠的情况,有两种方法:
- 将重叠的等价类部分单独构建等价类
- 采用 combining partition 的方法
单独将重叠的等价类划分出来通常并不是最好的做法,因为这会导致测试用例的数量急剧增加,许多测试用例可能会对相同的代码路径进行测试,从而浪费资源。相反,更有效的方法是进行合并分区(combining partitioning)。
- 合并分区(三种方法)的好处在于:
- 减少测试用例数量: 通过合并重叠的等价类,可以减少测试用例的总数,因为不必为每个可能组合都创建一个单独的测试用例。
- 增加测试效率: 避免重复测试相同的条件或代码路径,这使得测试过程更加高效。
- 更全面的覆盖: 通过合并,可以确保测试用例涵盖了所有重要的边界条件和异常路径,而不是仅仅因为重叠而多次测试相同的路径。