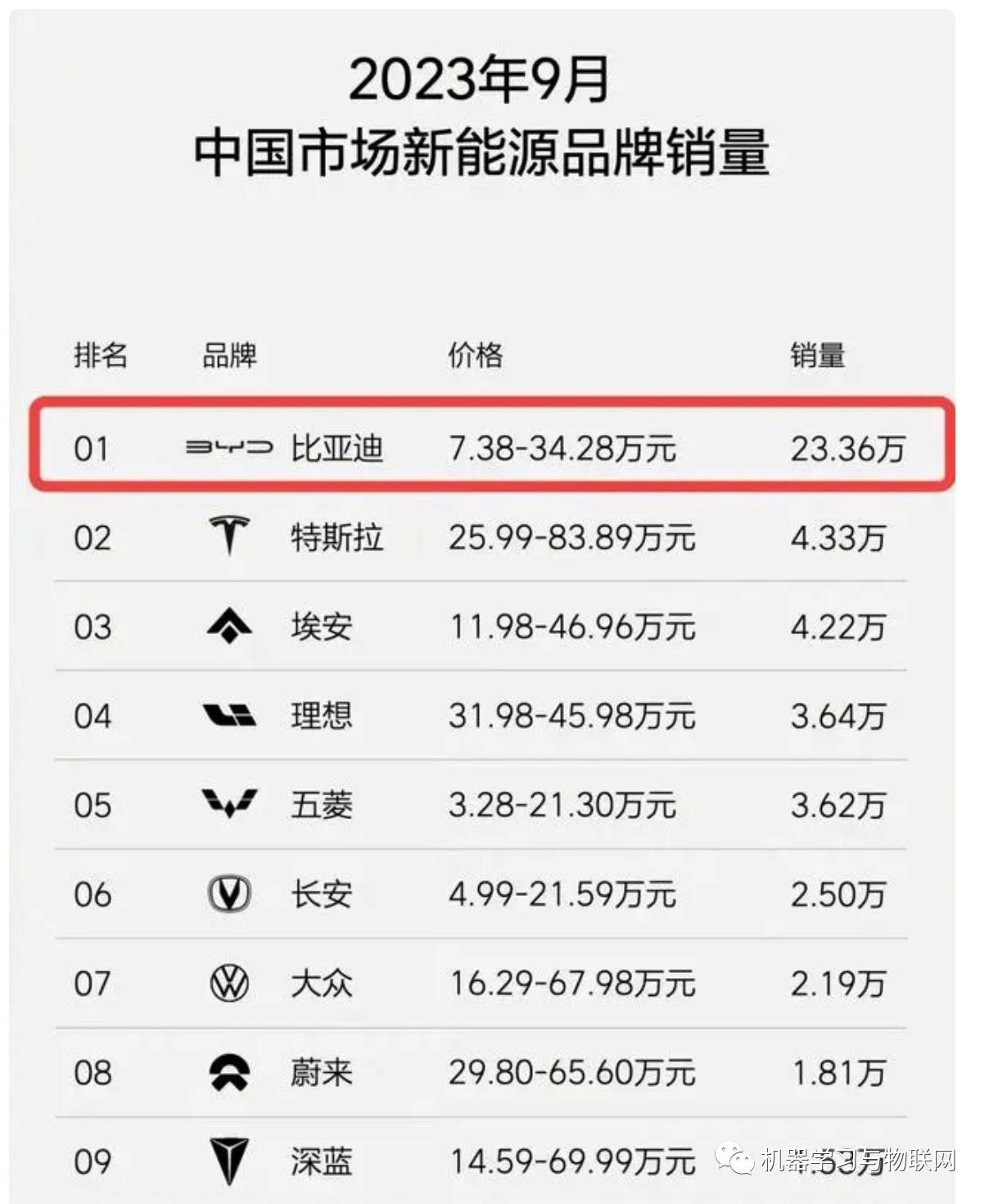
1、题目要求
(1) 读取给定的交易数据库test3.txt,将整个交易数据库表示为一个矩阵,每个元组表示成一个行向量,向量长度为4。其中,一个项目出现在这个元组中,则相应位置设为1,否则为0。如第1个交易{1,2}表示为
向量[ 1 1 0 0]。
(2)根据给定的最小支持度阈值(本题为3),确定频繁1项集。
(3)计算其余长度的频繁项集,直到Lk为空。
(4)尝试用Apriori算法实现
text3.txt数据
1 2
2 3 4
1 2 3 4
1 2 4
1 2 3 4
2、解题代码和步骤
clear
clc
%fopen以读的方式打开一个文件
ffid=fopen('text3.txt','r')
i=0;
MAXn=4;
data=[];
%读取给定的交易数据库text3.txt将整个交易数据库表示为一个矩阵,将元祖表示成一个行向量
%向量的长度为项目的个数,其中一个项目初夏你在这个元组中,响应位置设为1,否则为0
%检查流文件ffid是否已经达到末尾
while feof(ffid)==0
i=i+1;
%读取文件流ffid中一行数据,并将其存储到变量tline{i,1}中
tline{i,1}=fgetl(ffid);
%显示值
disp(tline{i,1})
%创建一个长度为MAXn的全0向量
newdata=zeros(1,MAXn);
%str2num将字符串转换为数值
line=str2num(tline{i,1});
disp(line)
newdata(line)=1;
disp(newdata)
%将newdata向量添加到data向量末尾
data=[data;newdata];
end
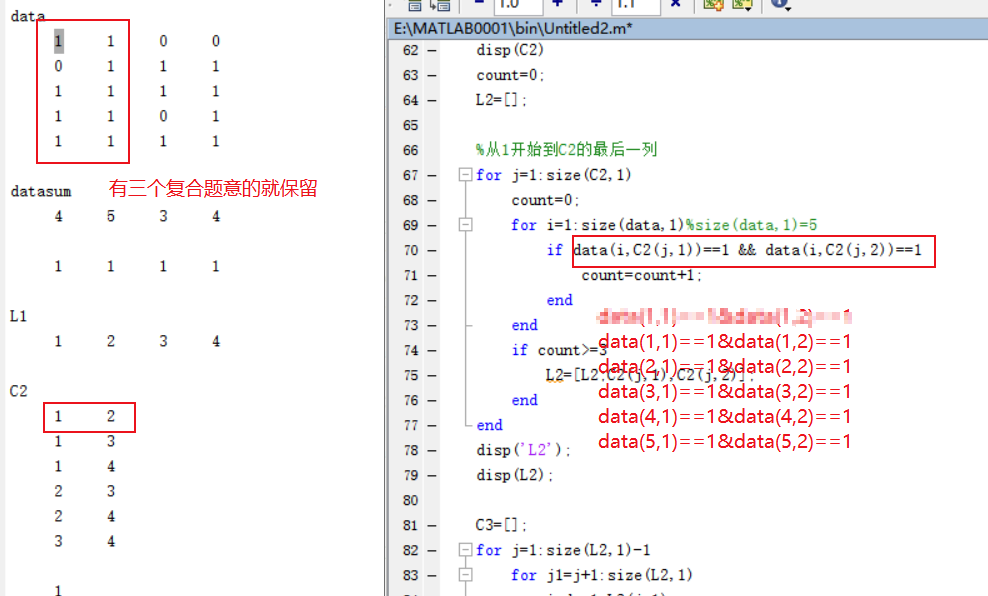
disp('data')
disp(data)
%最小支持度为3
%用datasum统计每个项目的支持度,将datasum中支持度小于3的位置等于0
%标记datasum中为0的序列号,将data矩阵中相应的序列号的位置等于0
%频繁1项级为datasum中大于0的项
%data向量中所有元素的和
datasum=sum(data);
disp('datasum')
disp(datasum)
%小于3的元素设置为0
datasum(datasum<3)=0;
%datasum元素等于0的索引
[,col]=find(datasum==0);
%第col列的元素设置为0
data(:,col)=0;
%找到第一行大于0的元素
disp(datasum(1,:)>0)
L1=find(datasum(1,:)>0);
disp('L1');
disp(L1);
C2=[];
%从1开始到L1最后一列的前一列
for j=1:size(L1,2)-1
%从j+1开始到L1矩阵最后一列
for j1=j+1:size(L1,2)
C2=[C2;L1(j),L1(j1)];
end
end
disp('C2')
disp(C2)
count=0;
L2=[];
%从1开始到C2的最后一列
for j=1:size(C2,1)
count=0;
for i=1:size(data,1)%size(data,1)=5
if data(i,C2(j,1))==1 && data(i,C2(j,2))==1
count=count+1;
end
end
if count>=3
L2=[L2;C2(j,1),C2(j,2)];
end
end
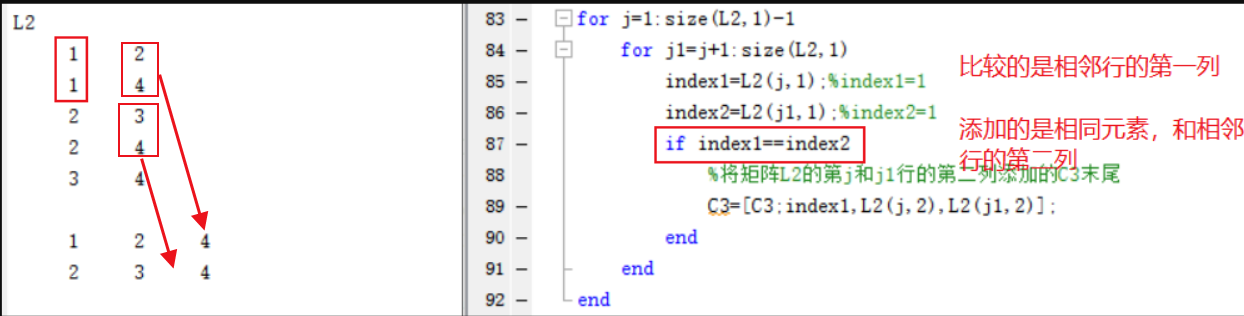
disp('L2');
disp(L2);
C3=[];
%size(L2,1)=5
for j=1:size(L2,1)-1
for j1=j+1:size(L2,1)
index1=L2(j,1);%index1=1
index2=L2(j1,1);%index2=1
if index1==index2
%将矩阵L2的第j和j1行的第二列添加的C3末尾
C3=[C3;index1,L2(j,2),L2(j1,2)];
end
end
end
disp('C3')
disp(C3)
mC3=[];
%遍历C3的每一行
for j=1:size(C3,1)
%将每行第一列元素赋值
index=C3(j,1);
index1=C3(j,2);
index2=C3(j,3);
for j1=1:size(L2,1)
index3=L2(j1,1);
index4=L2(j1,2);
if index1==index3&&index2==index4
mC3=[mC3;index,index3,index4];
end
end
end
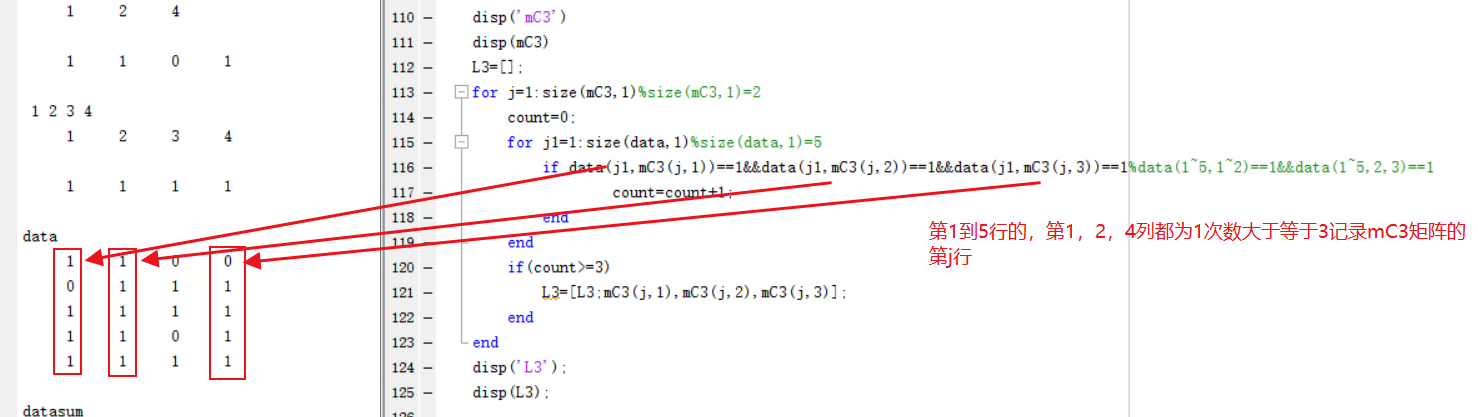
disp('mC3')
disp(mC3)
L3=[];
for j=1:size(mC3,1)%size(mC3,1)=2
count=0;
for j1=1:size(data,1)%size(data,1)=5
if data(j1,mC3(j,1))==1&&data(j1,mC3(j,2))==1&&data(j1,mC3(j,3))==1%data(1~5,1~2)==1&&data(1~5,2,3)==1
count=count+1;
end
end
if(count>=3)
L3=[L3;mC3(j,1),mC3(j,2),mC3(j,3)];
end
end
disp('L3');
disp(L3);
3、代码和图解释
L1:

L2:

4、输出的结果
ffid =
83
1 2
1 2
1 1 0 0
2 3 4
2 3 4
0 1 1 1
1 2 3 4
1 2 3 4
1 1 1 1
1 2 4
1 2 4
1 1 0 1
1 2 3 4
1 2 3 4
1 1 1 1
data
1 1 0 0
0 1 1 1
1 1 1 1
1 1 0 1
1 1 1 1
datasum
4 5 3 4
1 1 1 1
L1
1 2 3 4
C2
1 2
1 3
1 4
2 3
2 4
3 4
L2
1 2
1 4
2 3
2 4
3 4
C3
1 2 4
2 3 4
mC3
1 2 4
2 3 4
L3
1 2 4
2 3 4
>>