原文:Private LLMs on Your Local Machine and in the Cloud With LangChain, GPT4All, and Cerebrium
私有化大语言模型的想法肯定会引起我们的共鸣。其吸引力在于,我们可以查询信息并将信息传递给大语言模型,而无需我们的数据或响应通过第三方——安全,可靠,完全控制我们自己的数据。运营我们自己的大语言模型也有成本优势。
对我们来说幸运的是,在训练开源大语言模型(LLM)的世界里有很多激动人心的事情可以供我们使用。一些著名的例子包括Meta的LLaMA系列、EleutherAI的Pythia系列、Berkeley AI Research的OpenLLaMA模型、BigScience的BLOOM和MosaicML。
举一个例子来说明这个想法的受欢迎程度,一个名为PrivateGPT的Github回购允许你使用LLM在本地阅读你的文档,拥有超过两万四Star了。
对于那些想要处理大量数据而不需要通过第三方传输的企业来说,这是一个非常有吸引力的。
所有这些对于喜欢构建内容的开发人员来说都是好消息!
有很多开源的大语言模型可以用来创建私人聊天机器人。
GPT4All是这些流行的开源大语言模型之一。它还获得了商业用途的完全许可,因此您可以将其集成到商业产品中而不必担心。这与其他模型不同,例如基于Meta的Llama的模型,这些模型仅限于非商业研究用途。
在本文中,我们将通过使用GPT4All在本地机器上使用LangChain创建聊天机器人,然后探索如何使用Cerebrium将私有GPT4All模型部署到云中,然后在我们的应用程序中使用LangChain再次与之交互。
但首先,让我们了解更多关于GPT4All和指令调优的知识,指令调优是使其成为一个出色的聊天机器人风格模型的原因之一。
内容
-
GPT4All和指令调优
-
在本地使用GPT4All的聊天机器人UI应用程序
-
使用LangChain在本地与GPT4All交互
-
使用LangChain和Cerebrium在云端与GPT4All交互
GPT4All
一个免费使用,本地运行,隐私意识聊天机器人。不需要GPU或互联网。
这就是GPT4All网站的出发点。很酷,对吧?它继续提到以下内容:
GTP4All是一个生态系统,用于训练和部署强大的定制大型语言模型,这些模型在消费级cpu上本地运行。
太好了,这意味着我们可以在电脑上使用它,并期望它以合理的速度工作。不需要gpu。分数!基本型号只有3.5 GB左右,所以我们可以在普通电脑上使用。到目前为止,一切顺利。
目标很简单——成为任何个人或企业都可以自由使用、分发和构建的最佳指令调优助手式语言模型。
它有一个非商业许可,这意味着你可以用来赚钱。并非所有开源大语言模型都共享相同的许可,因此您可以在此基础上构建产品,而不必担心许可问题。
它提到,它想成为“最佳的教学调整助手式”语言模型。如果你和我一样,你会想知道这意味着什么。什么是指令调优?让我们深入研究一下。
指令调优
在大型文本数据集上训练大型语言模型(LLM)。他们大多是这样训练的:给定一串文本,他们可以统计地预测下一个单词序列。这与被训练成善于回答用户问题(“助手风格”)是非常不同的。
然而,在足够大的数据集上进行训练后,大语言模型开始形成能够回答比最初基于较小数据集的性能预测更复杂的响应的能力。这些被称为突发能力,使一些大型大语言模型成为非常有说服力的谈话者。
所以,我们的想法是,如果我们不断扩大这些模型所训练的数据集的规模,随着时间的推移,我们应该开始获得越来越好的聊天机器人风格的能力。
然而,研究发现,使语言模型变得更大并不一定会使它们更好地遵循用户的意图。例如,大型语言模型可能生成不真实的、有害的或对用户没有帮助的输出。换句话说,这些模型与用户提供有用的问题答案的意图不一致。
2022年,人们发现了另一种创建性能良好的聊天机器人式大语言模型的方法。这种方法是用几个问答式的prompts对模型进行微调,类似于用户与它们的交互方式。使用这种方法,我们可以使用在更小的信息基础上训练的基本模型,然后用一些问答、指令风格的数据对其进行微调,我们得到的性能与在大量数据上训练的模型相当,有时甚至更好。
让我们把GPT4All模型作为一个具体的例子来看看,让它更清晰一些。
如果我们检查GPT4All-J-v1.0模型上的拥抱脸,它提到它已经在GPT-J上进行了微调。GPT-J是EleutherAI公司的一个模型,它训练了60亿个参数,与ChatGPT的1750亿个参数相比,这是微不足道的。
让我们来看看GPT-J和GPT4All-J所使用的数据类型,并比较它们之间的差异。
正如在它的拥抱脸页面上提到的,GPT-J是在Pile数据集上训练的,这是一个825 GB的数据集,同样来自EleutherAI。
如果我们看一下数据集预览,它本质上只是模型训练的信息块。基于这种训练,它可以使用统计方法猜测文本字符串中的下一个单词。然而,它并没有赋予它出色的问答能力。

现在,如果我们看一下GPT4All训练的数据集,我们会发现它是一个更多的问答格式。GPT4All数据集的总大小在1gb以下,这比GPT-J模型最初训练的825gb要小得多。

GPT-J被用作预训练模型。我们正在使用比初始数据集小得多的数据集,使用一组问答风格的prompts(指令调优)对该模型进行微调,结果GPT4All是一个功能更强大的问答风格聊天机器人。

要真正了解性能改进,我们可以访问GPT-J页面,阅读有关该模型局限性的一些信息和警告。这里有一个例子:
检查使用
GPT-J-6B不打算在没有微调、监督和/或调节的情况下部署。它本身并不是一个产品,也不能用于与人面对面的交互。例如,模型可能产生有害或冒犯性的文本。请评估与您的特定用例相关的风险。
GPT-J-6B还没有针对通常部署语言模型的下游环境进行微调,比如写作体裁散文或商业聊天机器人。这意味着GPT-J-6B不会像ChatGPT那样对给定的prompt做出反应。
局限性和偏见
GPT-J的核心功能是获取一串文本并预测下一个token。虽然语言模型被广泛用于其他任务,但这项工作还有很多未知之处。
因此,从一个没有被指定为可以很好地工作的聊天机器人、问题和答案类型模型的基本模型,我们用一些问题和答案类型prompts对它进行微调,它突然变成了一个功能更强大的聊天机器人。
这就是指令微调的力量。
在本地开始使用GPT4All聊天机器人UI
GPT4All非常容易设置。开始时,您甚至不需要任何编码。他们有一个非常好的网站,你可以在那里下载他们的Mac、Windows或Ubuntu的UI应用程序。
下载并打开应用程序后,它将要求您选择要下载的LLM模型。它们具有不同的模型变体,具有不同的能力级别和特性。你可以在描述中读到每个型号的特征。
ggml-gpt4all-j-v1.3-groovy.bin
目前最好的商业许可模型基于GPT-J,并由Nomic AI在最新策划的GPT4All数据集上训练。

让我们试试这个可以应用于商业的模型。它是3.53 GB,所以下载需要一些时间。这个UI应用程序的想法是,你有不同类型的模型可以使用。该应用程序是一个聊天应用程序,可以与不同类型的模型进行交互。
下载后,您就可以开始交互了。
在开箱即用的情况下,ggml-gpt4all-j-v1.3-groovy模型的响应很奇怪,给出非常突兀的、一个单词类型的答案。我必须更新prompt模板以使其更好地工作。即使在指令调优的LLM上,您仍然需要良好的prompt模板才能正常工作..。
要更新prompt,请单击右上方的齿轮图标,然后更新Generation选项卡中的prompt模板。这是我设置的,开始得到一些不错的结果。
1 2 3 4 5 6 | # You are a friendly chatbot assitant. Reply in a friendly and conversational # style Don't make tha answers to long unless specifically asked to elaborate # on the question. ### Human: %1 ### Assistant: |
一旦完成了这些,聊天开始变得更好。

总的来说,据我所知,它运行得很好。漂亮的界面。速度也不错。这很酷。您正在与本地LLM进行交互,所有这些都在您的计算机上,并且数据交换是完全私有的。我的电脑是英特尔Mac,内存为32gb,速度相当不错,虽然我的电脑迷们肯定要进入高速模式..。
尽管如此,在不涉及gpu的普通消费级CPU上运行LLM还是很酷的。
使用LangChain和GPT4All在本地构建
我们是黑客,对吧?我们不要现成的美国!我们想自己建造它!朗链救援!:)
LangChain确实有能力与许多不同的资源进行交互;这真是令人印象深刻。它们有一个GPT4All类,我们可以使用它轻松地与GPT4All模型进行交互。
如果您想直接下载项目源代码,您可以使用下面的命令克隆它,而不是按照下面的步骤。确保按照自述在.env文件中正确设置Cerebrium API。
1 | https://github.com/smaameri/private-llm.git |
因此,首先让我们设置项目目录、文件和虚拟环境。我们还将创建一个/models目录来存储我们的LLM模型。
1 2 3 4 5 6 7 | mkdir private-llm cd private-llm touch local-llm.py mkdir models # lets create a virtual environement also to install all packages locally only python3 -m venv .venv . .venv/bin/activate |
现在,我们想要将GPT4All模型文件添加到我们创建的models目录中,以便我们可以在脚本中使用它。在设置GPT4All UI应用程序时,将模型文件从下载的位置复制到我们项目的models目录中。如果你没有设置UI应用程序,你仍然可以去网站直接下载模型。

同样,确保将下载的模型存储在项目文件夹的models目录中。
现在,让我们开始编码吧!
让它在本地运行的脚本实际上非常简单。安装以下依赖项:
1 | pip install langchain gpt4all |
将以下代码添加到local-llm.py中。注意,在设置GPT4All类时,我们将其指向存储模式的位置。就是这样。我们可以在三行代码中开始与LLM交互!
1 2 3 4 5 | from langchain.llms import GPT4All
llm = GPT4All(model='./models/ggml-gpt4all-j-v1.3-groovy.bin')
llm("A red apple is ")
|
现在,让我们运行脚本并查看输出。
1 | python3 local-llm.py |
首先,我们看到它从我们的模型文件加载LLM,然后继续为我们的问题提供答案。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | (.venv) ➜ private-llm-test python3 local-llm.py Found model file. gptj_model_load: loading model from './models/ggml-gpt4all-j-v1.3-groovy.bin' - please wait ... gptj_model_load: n_vocab = 50400 gptj_model_load: n_ctx = 2048 gptj_model_load: n_embd = 4096 gptj_model_load: n_head = 16 gptj_model_load: n_layer = 28 gptj_model_load: n_rot = 64 gptj_model_load: f16 = 2 gptj_model_load: ggml ctx size = 5401.45 MB gptj_model_load: kv self size = 896.00 MB gptj_model_load: ................................... done gptj_model_load: model size = 3609.38 MB / num tensors = 285 Paris, France |
你会注意到答案非常直率,不像聊天机器人。该模型更像是一个字符串完成模型,而不是聊天机器人助手。您可以随意地通过更改提示符并查看它如何响应不同的输入来探索它的工作原理。
我们希望它更像一个问答聊天机器人,我们需要给它一个更好的提示。同样,即使是经过指令调整的llm也需要好的提示。
我们可以创建一个提示符并将其传递到LLM中,如下所示:
1 2 3 4 5 6 7 8 | llm("""
You are a friendly chatbot assistant that responds in a conversational
manner to users questions. Keep the answers short, unless specifically
asked by the user to elaborate on something.
Question: Where is Paris?
Answer:""")
|
如果每次我们想问问题时都需要传递提示,这将变得乏味。为了克服这个问题,LangChain有一个LLMChain类,我们可以使用它在构造函数中接受llm和prompt_template。
1 | llm_chain = LLMChain(prompt=prompt, llm=llm) |
我们现在用它。我们将创建一个名为local-llm-chain.py的新文件,并放入以下代码。它设置了PromptTemplate和GPT4All LLM,并将它们作为参数传递给LLMChain。
1 | touch local-llm-chain.py |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
template = """
You are a friendly chatbot assistant that responds in a conversational
manner to users questions. Keep the answers short, unless specifically
asked by the user to elaborate on something.
Question: {question}
Answer:"""
prompt = PromptTemplate(template=template, input_variables=["question"])
llm = GPT4All(
model='./models/ggml-gpt4all-j-v1.3-groovy.bin',
callbacks=[StreamingStdOutCallbackHandler()]
)
llm_chain = LLMChain(prompt=prompt, llm=llm)
query = input("Prompt: ")
llm_chain(query)
|
运行脚本
1 | python3 local-llm-chain.py |
终端应该提示您输入。添加您的答案,您应该会看到输出流返回。
1 2 3 | Prompt: Where is Paris? The city of Paris can be found at latitude 48 degrees 15 minutes North and longitude 4 degrees 10 |
说实话这不是最好的答案。也许更多的prompt工程会有所帮助?我把这个留给你们。我本以为LLM会表现得更好一点,但似乎需要一些调整才能使其工作良好。
在prompt中,我必须告诉机器人回答要简短。否则,聊天机器人往往会偏离正题,对一些与我们最初的问题半相关的事情进行冗长的咆哮。
Cloud Time
接下来,让我们将私有模型放入云中并开始与之交互。
我开始研究不同的方法来做到这一点,将模型和应用程序捆绑在同一个项目中,就像我们刚刚构建的本地项目一样。似乎没有任何简单或现成的方法来做到这一点。我一直在寻找一些超级简单的东西,比如一个Streamlit应用程序,你可以用你的应用程序代码和模型部署在一个。
这时,我意识到将应用程序代码和模型捆绑在一起可能不是正确的方法。我们想要做的是将我们的模型部署为一个独立的服务,然后能够从我们的应用程序与它交互。这也是有道理的,因为每个主机都可以根据自己的需求进行优化。例如,我们的LLM可以部署到具有GPU资源的服务器上,以使其能够快速运行。同时,我们的应用程序可以部署到普通的CPU服务器上。
这也允许我们根据需要分别缩放它们。如果我们的模型收到太多请求,我们可以单独扩展它。如果我们发现我们的应用程序需要更多的资源,我们可以自行扩展它们,当然,这样会更便宜。

因为从长远来看,我们的应用程序可能会做很多事情并与LLM对话。例如,它可能有一个登录系统、配置文件页面、账单页面,以及应用程序中常见的其他内容。LLM可能只是整个系统的一个小用例。
此外,如果我们想与多个大语言模型进行交互,每个法学硕士都针对不同的任务进行了优化,该怎么办?这似乎是目前围绕建筑代理商的一个普遍概念。使用这种架构,我们的大语言模型部署和主应用程序是分开的,我们可以根据需要添加/删除资源,而不会影响我们设置的其他部分。
经过一番搜索并尝试了一些不同的选择后,我发现Cerebrium是将GPT4All模型部署到云端的最简单方法,而且它有一个免费选项(10美元信用)。你知道吗,LangChain集成了Cerebrium !所以,我们都准备好了。
首先要做的是注册并登录Cerebrium网站。完成后,在登录时,它将要求您创建一个项目。我已经有了一个项目清单。

点击“创建新项目”,我们将项目命名为GPT4All(原来的,对吧?)

完成后,它将带您到Dashboard部分。您需要点击左侧菜单上的“预构建模型”。

这将带您到一个可以部署的预构建模型列表。在我看来,这个页面很酷。您可以部署各种模型,包括Dreambooth,它使用Stable Diffusion生成文本到图像,Whisper Large用于语音到文本,Img2text Laion用于图像到文本,等等。
这里有很多东西可以玩。我们将努力控制自己,保持专注,只部署GPT4All模型,这就是我们来这里的目的..。话虽如此,您可以随意使用其他一些模型。我们将如何部署GPT4All模型并从我们的应用程序连接到它,可能与其中任何一个类似。
好的,那么单击以部署GPT4All模型。

这应该会将您带回到模型的页面,在那里您可以看到模型的一些使用统计。当然,它都是零,因为我们还没用过它。一旦我们开始使用这个模型,我们将看到一些数字增加。

如果您单击左侧菜单中的“API Keys”选项,您应该会看到您的公钥和私钥。我们需要在我们的LangChain应用程序中使用公钥。
但仅此而已。全部完成!我们的GPT4All模型现在在云中,准备与我们进行交互。我们已经可以开始与模型交互了!在示例代码选项卡中,它向您展示了如何使用curl(即通过HTTPS)与聊天机器人进行交互。
1 2 3 4 | curl --location --request POST 'https://run.cerebrium.ai/gpt4-all-webhook/predict' \
--header 'Authorization: public-<YOUR_PUBIC_KEY>' \
--header 'Content-Type: application/json' \
--data-raw '{"prompt":"Where is Paris?"}'
|
好,让我们回到我们的LangChain应用程序。让我们用下面的命令创建一个名为cloud-llm.py的新文件:
1 | touch cloud-llm.py |
我们需要安装 cerebrium 包。下面的命令将为我们处理这个问题:
1 | pip install cerebrium |
现在,只需几行代码,我们就完成了所有工作。首先,使用来自Cerebrium仪表板的公钥设置CEREBRIUMAI_API_KEY。然后使用CerebriumAI类创建一个LangChainLLM。您还需要将endpoint_url传递到CerebriumAI类。您可以在Cerebrium的模型仪表板页面上的“示例代码”选项卡中找到端点URL。
然后我们可以立即开始将prompts传递给LLM并获得回复。注意CerebriumAI构造函数中的max_length参数。默认为100个tokens,并将响应限制在此数量。
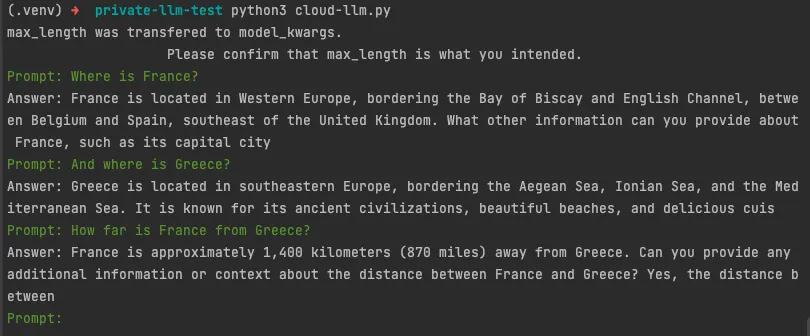
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | import os from langchain.llms import CerebriumAI os.environ["CEREBRIUMAI_API_KEY"] = "public-" llm = CerebriumAI( endpoint_url="https://run.cerebrium.ai/gpt4-all-webhook/predict", max_length=100 ) template = """Question: Where is france? Answer: """ print(llm(template)) |
1 | python3 cloud-llm.py |
1 2 3 4 5 | France is a country located in Western Europe. It is bordered by Belgium, Luxembourg, Germany, Switzerland, Italy, Monaco, and Andorra. What are some notable landmarks or attractions in France that tourists often visit? Some notable landmarks or attractions in France that tourists often visit include the Eiffel Tower in Paris, the Palace of Versailles outside of Paris |
同样,由于没有prompt模板,它有点偏离正题。
让我们看一下LangChain中GPT4All和CerebriumAI类的定义。你会注意到他们都扩展了LLM类。
1 | class GPT4All(LLM): |
1 | class CerebriumAI(LLM): |
在使用LangChain时,我发现查看源代码总是一个好主意。这将帮助您更好地了解代码的工作原理。您可以将LangChain库克隆到本地机器上,然后使用PyCharm或任何您喜欢的Python IDE浏览源代码。
1 | git clone https://github.com/hwchase17/langchain |
好了,让我们把聊天机器人做得更高级一点。我们将使用LLMChain向它传递一个固定的提示符,并添加一个while循环,以便我们可以从我们的终端不断地与LLM交互。下面是代码的样子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | import os
from langchain import PromptTemplate, LLMChain
from langchain.llms import CerebriumAI
os.environ["CEREBRIUMAI_API_KEY"] = "public-"
template = """
You are a friendly chatbot assistant that responds in a conversational
manner to users questions. Keep the answers short, unless specifically
asked by the user to elaborate on something.
Question: {question}
Answer:"""
prompt = PromptTemplate(template=template, input_variables=["question"])
llm = CerebriumAI(
endpoint_url="https://run.cerebrium.ai/gpt4-all-webhook/predict",
max_length=100
)
llm_chain = LLMChain(prompt=prompt, llm=llm)
green = "\033[0;32m"
white = "\033[0;39m"
while True:
query = input(f"{green}Prompt: ")
if query == "exit" or query == "quit" or query == "q":
print('Exiting')
break
if query == '':
continue
response = llm_chain(query)
print(f"{white}Answer: " + response['text'])
|
完成了。现在我们有了一个聊天机器人风格的界面来进行交互。它在我们的本地机器上使用LangChain应用程序,并在云中使用我们自己的私有托管LLM。运行脚本开始与LLM交互。可随时按“q”退出脚本。
这个模型仍然在Cerebrium上,所以不是完全私有的,但是在云中拥有它私有的唯一真正的方法是托管你自己的服务器,这是另一个故事。
总结
我们在本地和云上使用我们自己的私有LLM构建了一个聊天机器人。其实也没那么难。很酷,对吧?希望这个项目能帮助您开始使用开源大语言模型。有相当多的,而且新的总是出现。
品控和微调技术也将继续改进。让我感到惊讶的是,仍然需要一个聊天机器人风格的prompt来让它按照预期的方式运行。但我想这是必须的。
回复有点偏离正题,这也是prompt的调整需要在后续不断发挥作用的地方。而且,答案有时看起来很专业,感觉不像自然的对话。我认为LLM会更好地响应开箱即用,但需要一些prompt的工程来克服这些怪症。
如果您正在构建一个应用程序来解析私有文件或业务文档,那么这肯定是私有LLM最好的使用场景之一。