文章目录
- 一、环境搭键
- 二、基本CRUD
- 2.1 BaseMapper
- 2.2 插入
- 2.3 删除
- 2.4 修改
- 2.5 查询
- 三、通用Service
- 四、常用注解
- 4.1 雪花算法
- 4.2 注解@TableLogic
- 五、条件构造器和常用接口
- 5.1 Wrapper介绍
- 5.2 QueryWrapper
- 5.3 UpdateWrapper
- 5.4 condition
- 5.5 LambdaQueryWrapper
- 5.6 LambdaUpdateWrapper
一、环境搭键
这些配置可以当做模版,快速搭键MybatisPlus环境。
1、pom.xml:
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<lombok>1.18.20</lombok>
<druid>1.2.1</druid>
<pagehelper>1.4.1</pagehelper>
<mybatisPlus>3.5.1</mybatisPlus>
</properties>
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok}</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>${druid}</version>
</dependency>
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>${pagehelper}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatisPlus}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>
2、启动类:
@SpringBootApplication
@MapperScan("com.cabbage.mybatisplus.mapper")
public class MybatisplusStudyApplication {
public static void main(String[] args) {
SpringApplication.run(MybatisplusStudyApplication.class, args);
}
}
3、创建实体类和mapper接口:
public interface UserMapper extends BaseMapper<User> {
}
4、配置数据库:
server:
port: 8080
spring:
profiles:
active: dev
datasource:
druid:
driver-class-name: ${sht.datasource.driver-class-name}
url: jdbc:mysql://${sht.datasource.host}:${sht.datasource.port}/${sht.datasource.database}?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true
username: ${sht.datasource.username}
password: ${sht.datasource.password}
# 配置MyBatis日志
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
sht:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
host: localhost
port: 3306
database: ssm
username: root
password: root
二、基本CRUD
2.1 BaseMapper
MyBatis-Plus中的基本CRUD在内置的BaseMapper中都已得到了实现,我们可以直接使用,接口如下(具体内容可查看源码):
public interface BaseMapper<T> extends Mapper<T> {
/**
* 插入一条记录
* @param entity 实体对象
*/
int insert(T entity);
/**
* 根据 ID 删除
* @param id 主键ID
*/
int deleteById(Serializable id);
/**
* 根据实体(ID)删除
* @param entity 实体对象
* @since 3.4.4
*/
int deleteById(T entity);
/**
* 根据 columnMap 条件,删除记录
* @param columnMap 表字段 map 对象
*/
int deleteByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
/**
* 根据 entity 条件,删除记录
* @param queryWrapper 实体对象封装操作类(可以为 null,里面的 entity 用于生成 where 语句)
*/
int delete(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
}
2.2 插入
@Test
void t2() {
User user = new User(null, "one", 18, "one@qq.com");
int res = userMapper.insert(user);
log.info("影响的行数:{},user.id:{}", res, user.getId());
//会默认基于雪花算法的策略生成id
}

2.3 删除
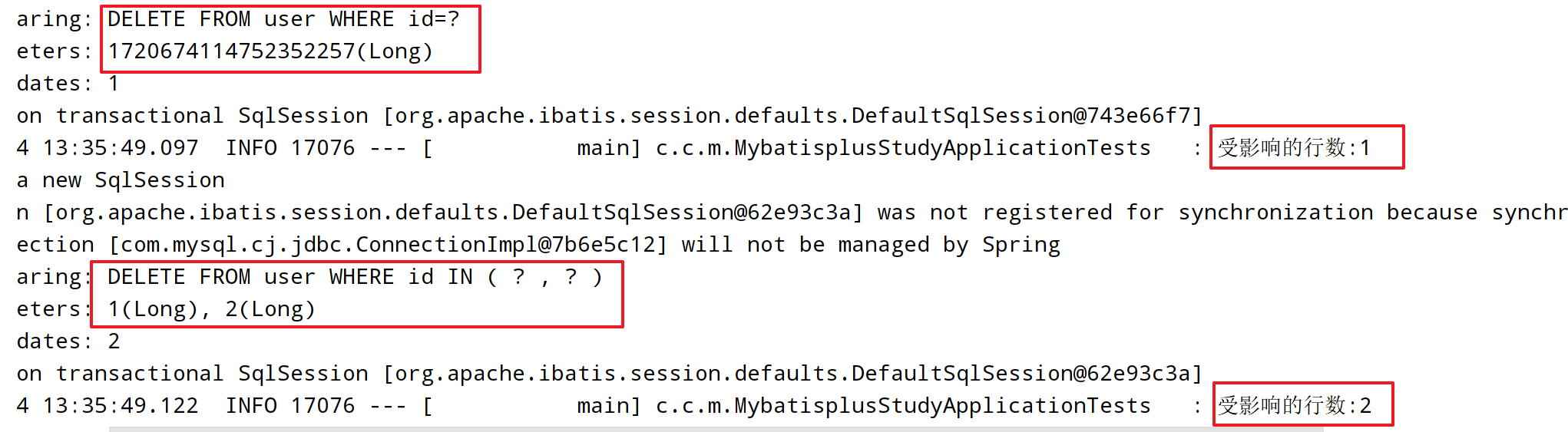
@Test
void t3() {
int res1 = userMapper.deleteById(1720674114752352257L);
log.info("受影响的行数:{}",res1);
List<User> list = Arrays.asList(new User(1L, null, null, null), new User(2L, null, null, null));
int res2 = userMapper.deleteBatchIds(list);
log.info("受影响的行数:{}",res2);
}
@Test
void t4() {
Map<String, Object> map = new HashMap<>();
map.put("age", 28);
map.put("name", "Tom");
int res = userMapper.deleteByMap(map);
log.info("受影响的行数:{}",res);
}

2.4 修改
@Test
void t5() {
int res = userMapper.updateById(new User(4L, "cabbage", 21, "cabbage@qq.com"));
log.info("受影响的行数:{}",res);
}

2.5 查询
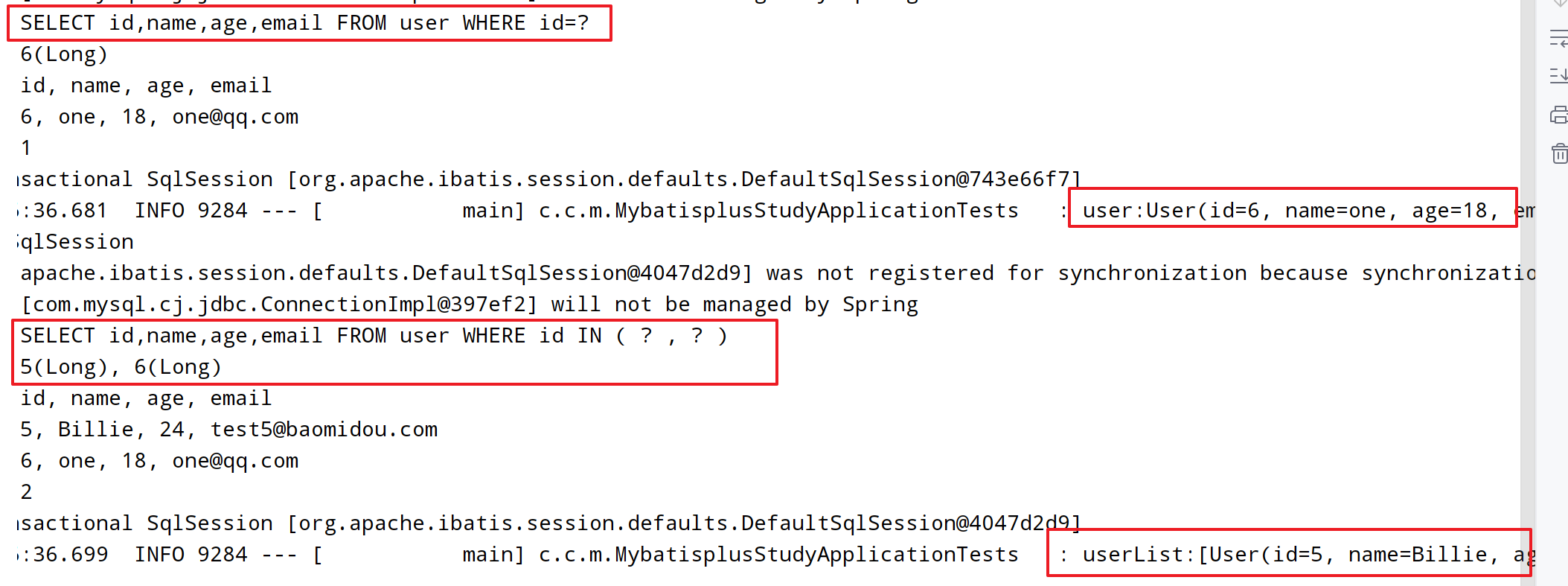
@Test
void t6() {
User user = userMapper.selectById(6L);
log.info("user:{}", user);
List<Long> list = Arrays.asList(5L, 6L);
List<User> userList = userMapper.selectBatchIds(list);
log.info("userList:{}",userList);
}
@Test
void t7() {
Map<String, Object> map = new HashMap<>();
map.put("name", "one");
map.put("age", 18);
List<User> userList = userMapper.selectByMap(map);
log.info("userList:{}", userList);
}

三、通用Service
通用 Service CRUD 封装IService接口,进一步封装 CRUD 采用 get查询单行、remove删除、list查询集合、page分页、save插入 前缀命名方式区分 Mapper 层避免混淆。
public interface UserService extends IService<User> {
}
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
}

测试查询记录数:
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
@GetMapping
public String test() {
long count = userService.count();
return String.valueOf(count);
}
}

测试批量插入:
@GetMapping
public String test() {
List<User> list = Arrays.asList(new User(7L, "two", 22, "two@qq.com"),
new User(8L, "three", 25, "three@qq.com"));
boolean res = userService.saveBatch(list);
return String.valueOf(res);
}

四、常用注解
可以看之前写过的文章,介绍的比较详细:https://cabbage.blog.csdn.net/article/details/123300666
4.1 雪花算法
背景:
需要选择合适的方案去应对数据规模的增长,以应对逐渐增长的访问压力和数据量。数据库的扩展方式主要包括:业务分库、主从复制,数据库分表。
数据库分表:
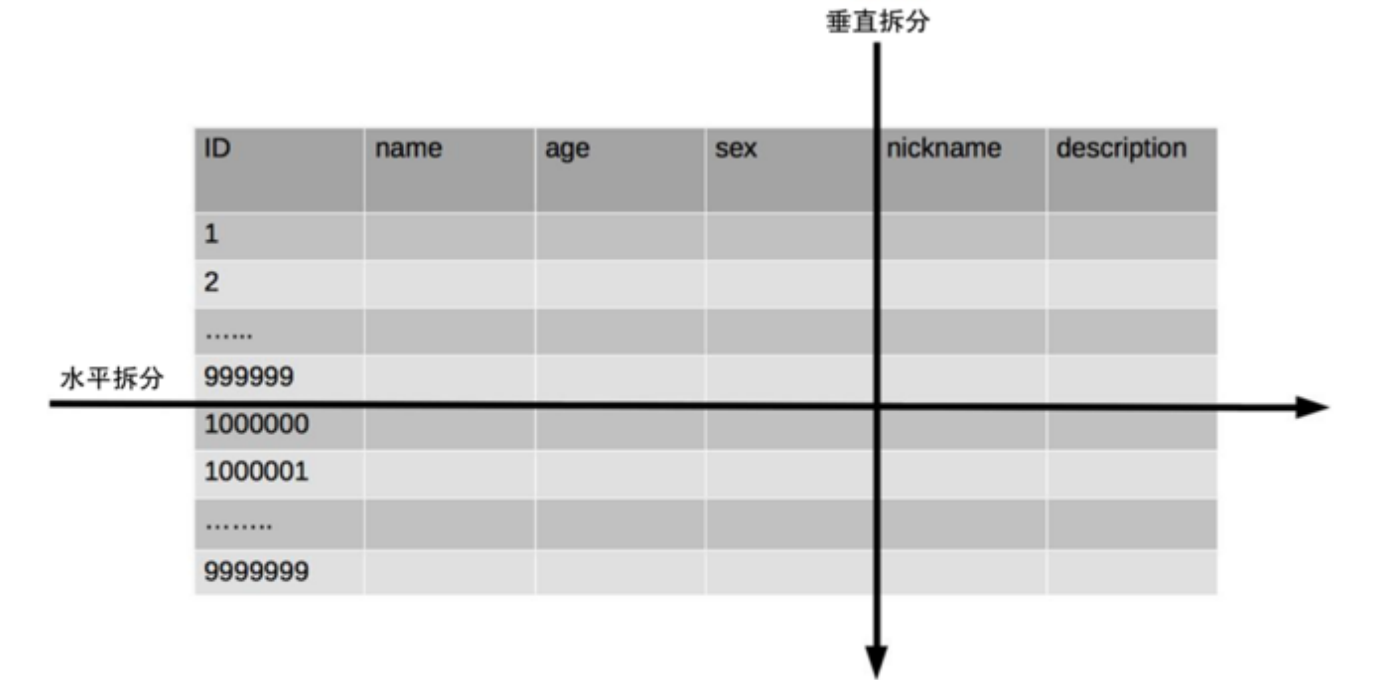
将不同业务数据分散存储到不同的数据库服务器,能够支撑百万甚至千万用户规模的业务,但如果业务继续发展,同一业务的单表数据也会达到单台数据库服务器的处理瓶颈。例如,淘宝的几亿用户数据,如果全部存放在一台数据库服务器的一张表中,肯定是无法满足性能要求的,此时就需要对单表数据进行拆分。单表数据拆分有两种方式:
垂直分表和水平分表。示意图如下:
- 垂直分表
垂直分表适合将表中某些不常用且占了大量空间的列拆分出去。例如,前面示意图中的 nickname 和 description字段,假设我们是一个婚恋网站,用户在筛选其他用户的时候,主要是用 age 和 sex 两个字段进行查询,而 nickname 和description 两个字段主要用于展 示,一般不会在业务查询中用到。description本身又比较长,因此我们可以将这两个字段独立到另外一张表中,这样在查询 age 和 sex 时,就能带来一定的性能提升。
- 水平分表
水平分表适合表行数特别大的表,有的公司要求单表行数超过 5000万就必须进行分表,这个数字可以作为参考,但并不是绝对标准,关键还是要看表的访问性能。对于一些比较复杂的表,可能超过1000万就要分表了;而对于一些简单的表,即使存储数据超过1亿行,也可以不分表。水平分表相比垂直分表,会引入更多的复杂性,例如要求全局唯一的数据id该如何处理。
方式一:主键自增
- 以最常见的用户 ID 为例,可以按照1000000的范围大小进行分段,1 ~ 999999 放到表 1中,1000000 ~ 1999999 放到表2中,以此类推。
- 复杂点:分段大小的选取。分段太小会导致切分后子表数量过多,增加维护复杂度;分段太大可能会导致单表依然存在性能问题,一般建议分段大小在 100 万至 2000 万之间,具体需要根据业务选取合适的分段大小。
- 优点:可以随着数据的增加平滑地扩充新的表。例如,现在的用户是 100 万,如果增加到1000万,只需要增加新的表就可以了,原有的数据不需要动。
- 缺点:分布不均匀。假如按照1000万来进行分表,有可能某个分段实际存储的数据量只有 1 条,而另外一个分段实际存储的数据量有1000万条。
方式二:取模
- 同样以用户 ID 为例,假如我们一开始就规划了 10 个数据库表,可以简单地用 user_id % 10 的值来表示数据所属的数据库表编号,ID 为 985 的用户放到编号为 5 的子表中,ID 为 10086 的用户放到编号为 6 的子表中。
- 复杂点:初始表数量的确定。表数量太多维护比较麻烦,表数量太少又可能导致单表性能存在问题。
- 优点:表分布比较均匀。
- 缺点:扩充新的表很麻烦,所有数据都要重分布。
方式三:雪花算法
- 雪花算法是由Twitter公布的分布式主键生成算法,它能够保证不同表的主键的不重复性,以及相同表的主键的有序性。
- 核心思想:
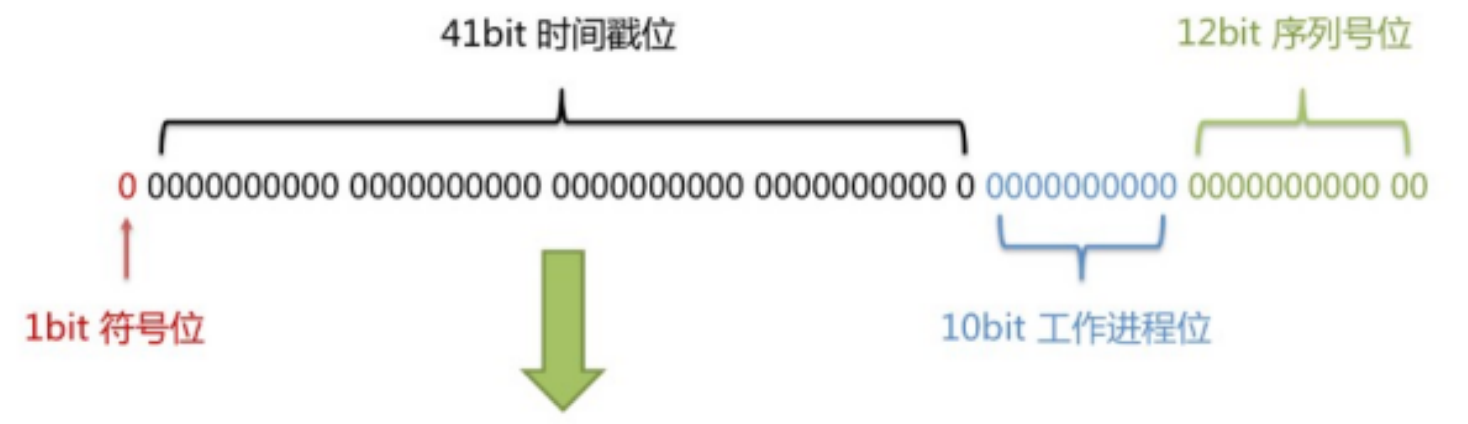
长度共64bit(一个long型)。
首先是一个符号位,1bit标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0。
41bit时间截(毫秒级),存储的是时间截的差值(当前时间截 - 开始时间截)。
10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID,可以部署在1024个节点)。
12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID)。 - 优点:整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞,并且效率较高。
4.2 注解@TableLogic
再来看看逻辑删除的具体使用,数据库中is_delete默认值都是0,代表着未删除。

我们给数据库对应的实体类添加@TableLogic注解:
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class User implements Serializable {
@TableId(type = IdType.AUTO)
private Long id;
private String name;
private Integer age;
private String email;
@TableLogic
@TableField(value = "is_delete")
private Integer isDelete;
}
执行删除代码:
@Test
void t1() {
List<Long> list = Arrays.asList(4L, 5L);
int res = userMapper.deleteBatchIds(list);
log.info("共删除了{}条数据", res);
}
通过控制台可以发现,执行删除语句,实际上是执行的修改操作。

数据库并未删除任何数据,只是把is_delete的值改为了1。

五、条件构造器和常用接口
5.1 Wrapper介绍
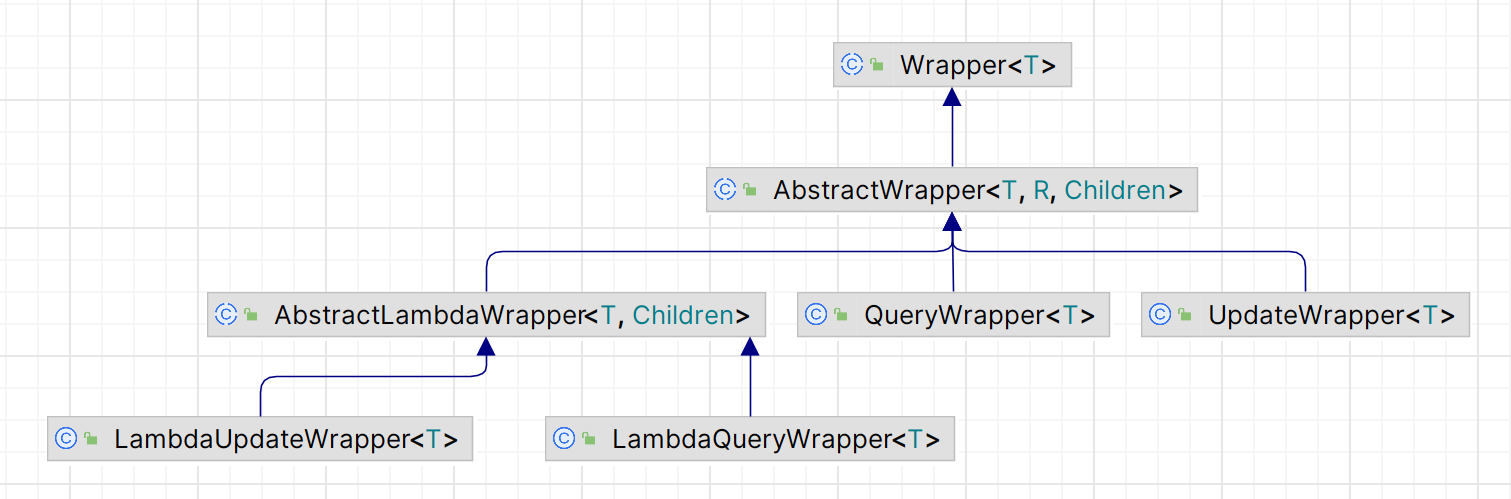
- Wrapper :条件构造抽象类,最顶端父类
- AbstractWrapper :用于查询条件封装,生成 sql 的 where 条件
- QueryWrapper :查询条件封装
UpdateWrapper :Update 条件封装 - AbstractLambdaWrapper :使用Lambda 语法
- LambdaQueryWrapper :用于Lambda语法使用的查询Wrapper
LambdaUpdateWrapper :Lambda 更新封装Wrapper
5.2 QueryWrapper
组装查询条件:
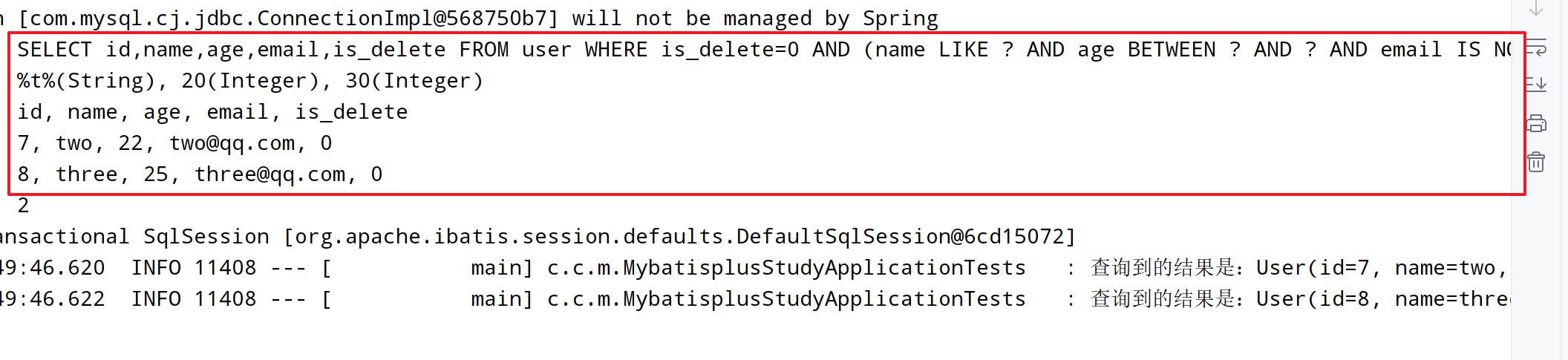
@Test
void t2() {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.like("name", "t")
.between("age", 20, 30)
.isNotNull("email");
List<User> userList = userMapper.selectList(queryWrapper);
userList.forEach(user -> {
log.info("查询到的结果是:{}", user);
});
}
从控制台可以看到,框架自动的为我们查询逻辑上存在的数据。
组装排序条件:
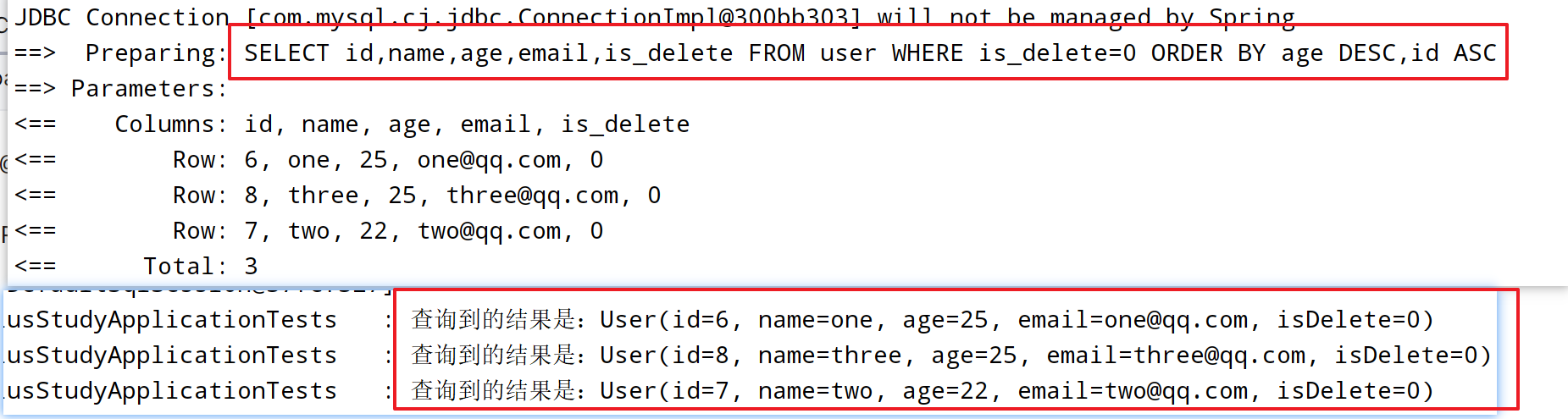
@Test
void t3() {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.orderByDesc("age")
.orderByAsc("id");
List<User> userList = userMapper.selectList(queryWrapper);
userList.forEach(user -> {
log.info("查询到的结果是:{}", user);
});
}
组装删除条件:
@Test
void t4() {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.isNull("email");
int res = userMapper.delete(queryWrapper);
log.info("共删除了{}条数据", res);
}

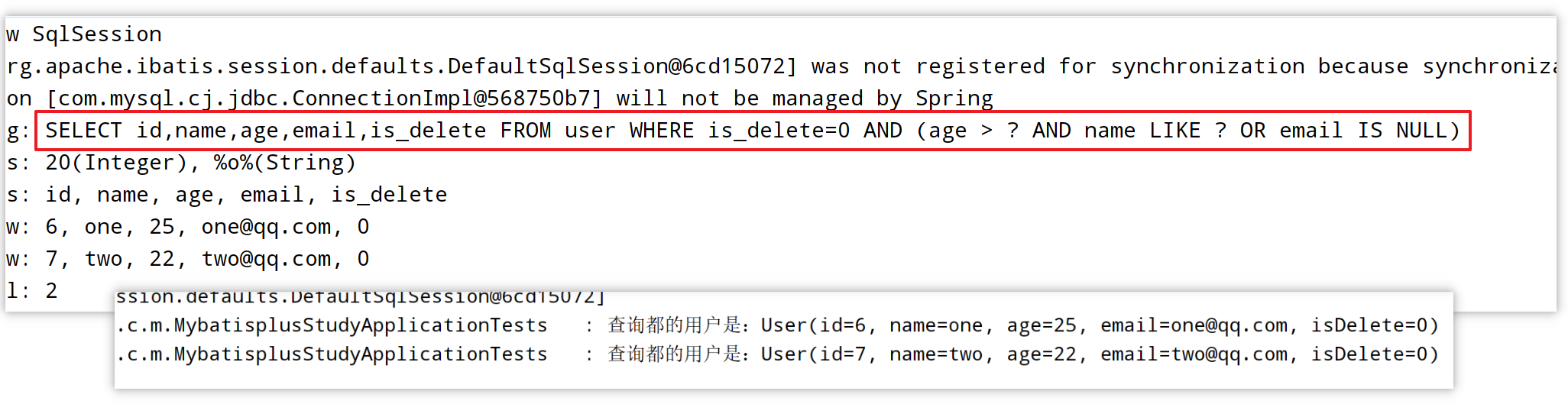
条件的优先级:
@Test
void t4() {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
//查询年龄大于20,并且名字中含有'o',或者邮箱是空的用户
queryWrapper.gt("age", 20)
.like("name", "o")
.or()
.isNull("email");
List<User> userList = userMapper.selectList(queryWrapper);
userList.forEach(user -> {
log.info("查询都的用户是:{}", user);
});
}
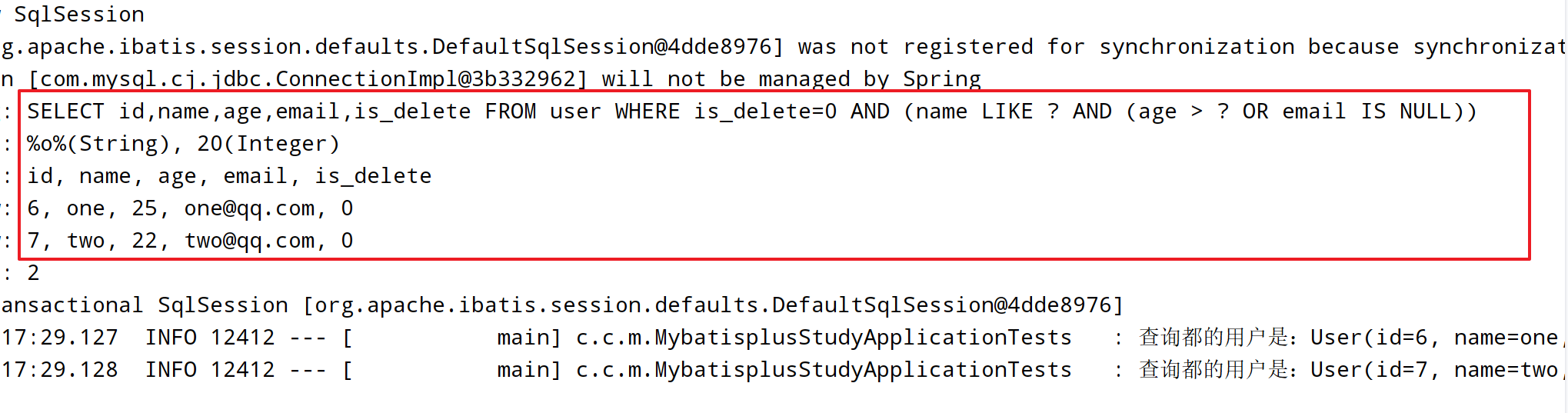
@Test
void t4() {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
//查询名字中含有'o',并且年龄大于20或者邮箱是空的用户
queryWrapper.like("name", 'o')
.and(i -> {
i.gt("age", 20).or().isNull("email");
});
List<User> userList = userMapper.selectList(queryWrapper);
userList.forEach(user -> {
log.info("查询都的用户是:{}", user);
});
}
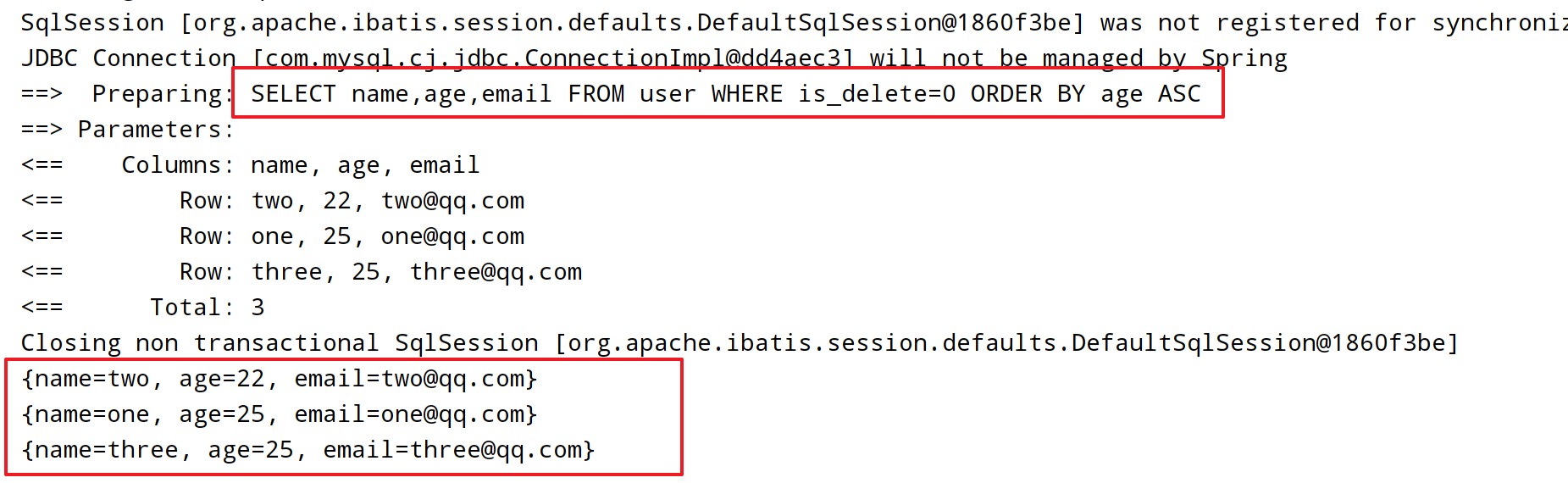
组装select子句:
@Test
void t5() {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.select("name", "age", "email")
.orderByAsc("age");
List<Map<String, Object>> mapList = userMapper.selectMaps(queryWrapper);
mapList.forEach(System.out::println);
}
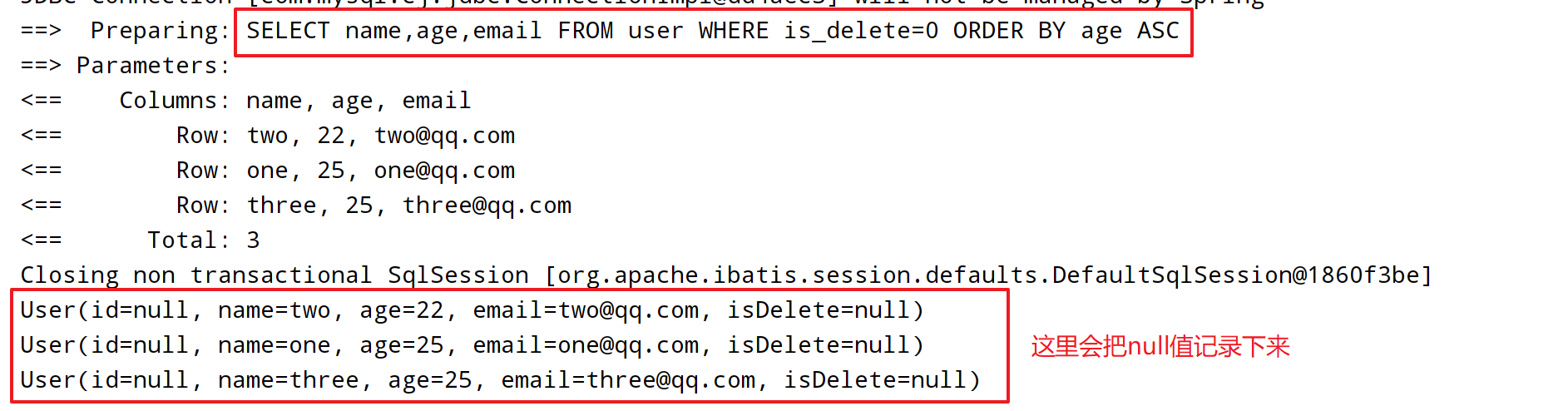
@Test
void t5() {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.select("name", "age", "email")
.orderByAsc("age");
List<User> userList = userMapper.selectList(queryWrapper);
// List<Map<String, Object>> mapList = userMapper.selectMaps(queryWrapper);
userList.forEach(System.out::println);
}
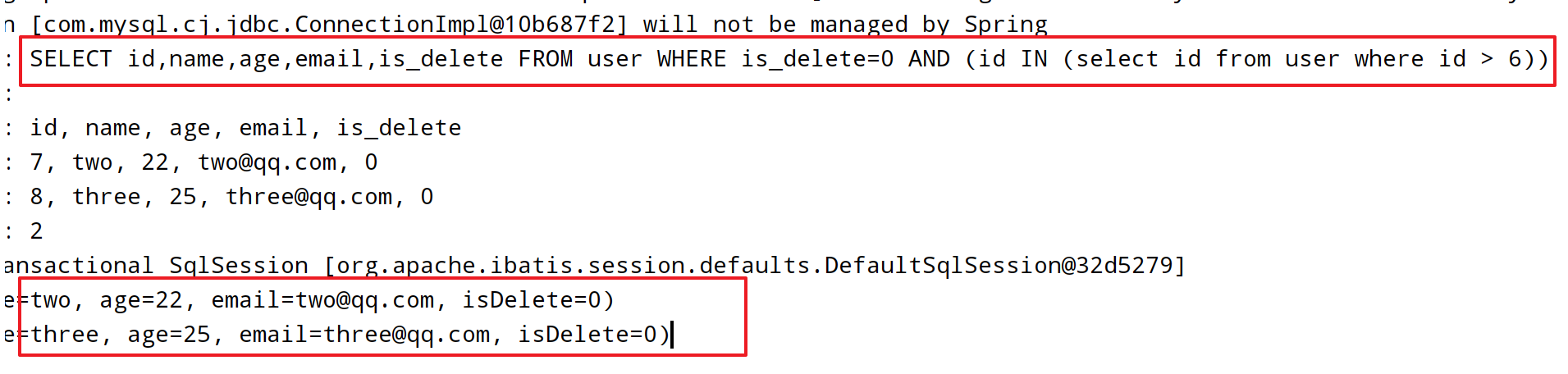
实现子查询:
@Test
void t6() {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.inSql("id", "select id from user where id > 6");
List<User> userList = userMapper.selectList(queryWrapper);
userList.forEach(System.out::println);
}
5.3 UpdateWrapper
@Test
void t7() {
//将(年龄大于25或邮箱为null)并且用户名中包含有t的用户信息修改
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
updateWrapper.like("name", "t")
.and(i -> {
i.gt("age", 25)
.or()
.isNull("email");
});
int res = userMapper.update(new User(9L, "five", 30, "five@qq.com"), updateWrapper);
log.info("影响的结果是:{}", res);
}

5.4 condition
在真正开发的过程中,组装条件是常见的功能,而这些条件数据来源于用户输入,是可选的,因
此我们在组装这些条件时,必须先判断用户是否选择了这些条件,若选择则需要组装该条件,若
没有选择则一定不能组装,以免影响SQL执行的结果
思路一:
@Test
void t8() {
//定义查询条件,有可能为null(用户未输入或未选择)
String username = null;
Integer ageBegin = 10;
Integer ageEnd = 24;
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
//StringUtils.isNotBlank()判断某字符串是否不为空且长度不为0且不由空白符(whitespace)构成
if(StringUtils.isNotBlank(username)){
queryWrapper.like("name","o");
}
if(ageBegin != null){
queryWrapper.ge("age", ageBegin);
}
if(ageEnd != null){
queryWrapper.le("age", ageEnd);
}
List<User> users = userMapper.selectList(queryWrapper);
users.forEach(System.out::println);
}
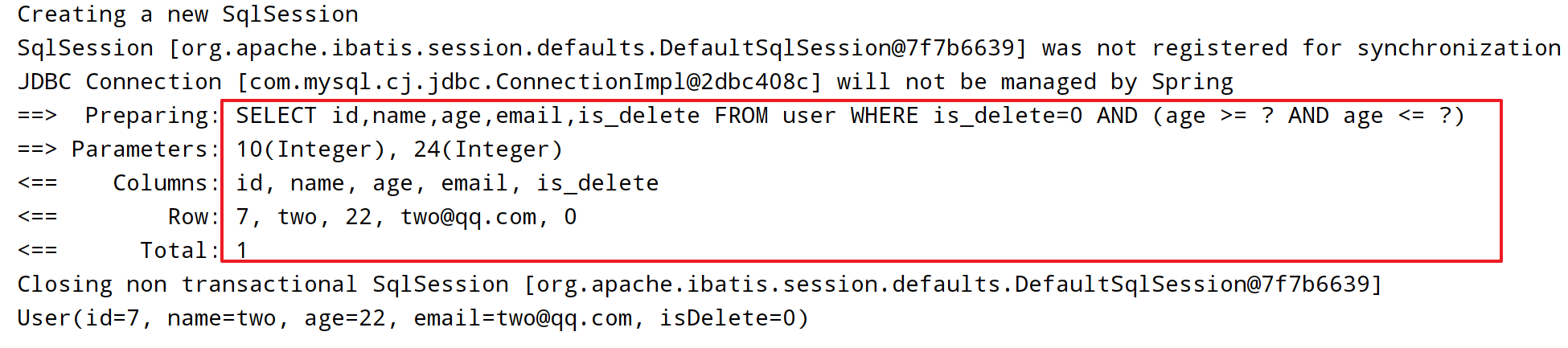
思路二:
@Test
void t9() {
String name = null;
Integer ageBegin = 10;
Integer ageEnd = 24;
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.like(StringUtils.isNotBlank(name), "name", "o")
.gt(ageBegin != null, "age", ageBegin)
.lt(ageEnd != null, "age", ageEnd);
List<User> userList = userMapper.selectList(queryWrapper);
userList.forEach(System.out::println);
}
思路二跟思路一的执行效果一样。
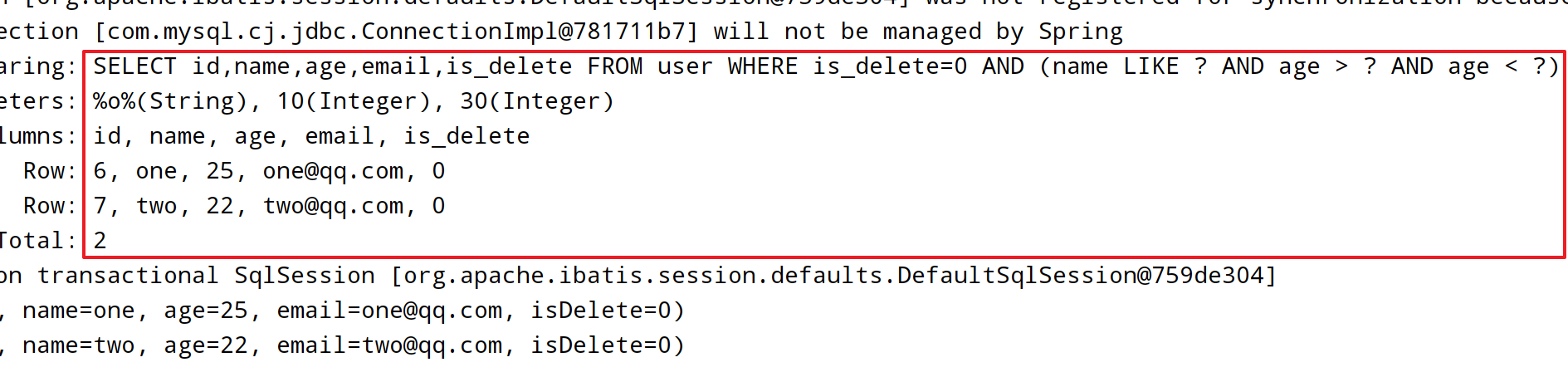
5.5 LambdaQueryWrapper
@Test
void t9() {
String name = "o";
Integer ageBegin = 10;
Integer ageEnd = 30;
LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.like(StringUtils.isNotBlank(name), User::getName, "o")
.gt(ageBegin != null, User::getAge, ageBegin)
.lt(ageEnd != null, User::getAge, ageEnd);
List<User> userList = userMapper.selectList(queryWrapper);
userList.forEach(System.out::println);
}
5.6 LambdaUpdateWrapper
@Test
void t10() {
LambdaUpdateWrapper<User> updateWrapper = new LambdaUpdateWrapper<>();
updateWrapper
.set(User::getAge, 18)
.set(User::getEmail, "user@atguigu.com")
.like(User::getName, "f")
.and(i -> i.gt(User::getAge, 24).or().isNull(User::getEmail));
int result = userMapper.update(null, updateWrapper);
System.out.println("受影响的行数:" + result);
}