1. 官网
Apache Kafka
2. akf
X轴拆分: 水平复制,就是讲单体系统多运行几个实例,做集群加负载均衡的模式,主主、主备、主从。解决单点,高可用问题
Y轴拆分: 基于不同的业务拆分
Z轴拆分: 基于数据拆分。分片分治
3. 概念
Apache Kafka是Apache软件基金会的开源的流处理平台,该平台提供了消息的订阅与发布的消息队列,一般用作系统间解耦、异步通信、削峰填谷等作用。同时Kafka又提供了Kafka streaming插件包实现了实时在线流处理。相比较一些专业的流处理框架不同,Kafka Streaming计算是运行在应用端,具有简单、入门要求低、部署方便等优点。
有的kafka消息可以被多个消费者进行消费,有的只能有一个消费者进行消费
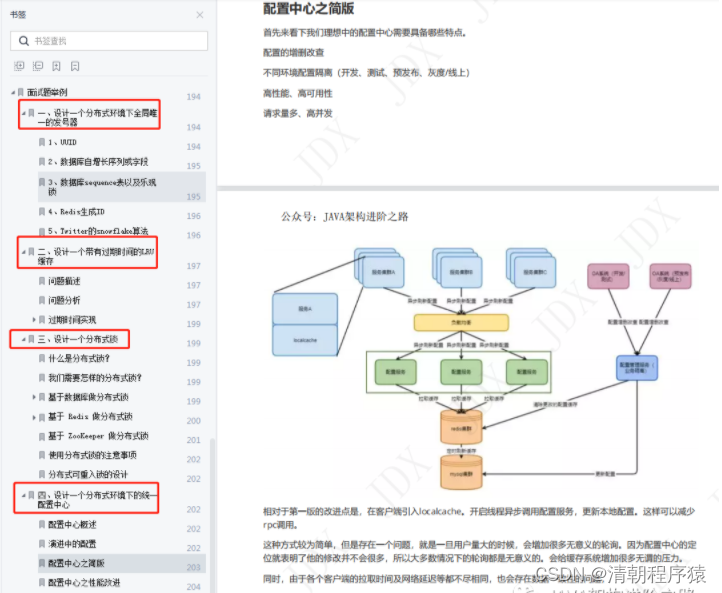
Kafka集群以Topic形式负责分类集群中的Record每一个Record属于一个Topic。每个Topic底层都会
Kafka集群以Topic形式负责分类集群中的Record,每一个Record属于一个Topic。每个Topic底层都会对应一组分区的日志用于持久化Topic中的Record。同时在Kafka集群中,Topic的每一个日志的分区都一定会有1个Borker担当该分区的Leader,其他的Broker担当该分区的follower,Leader负责分区数据的读写操作,follower负责同步改分区的数据。这样如果分区的Leader宕机,该分区的其他follower会选取出新的leader继续负责该分区数据的读写。其中集群的中Leader的监控和Topic的部分元数据是存储在Zookeeper中.
只能保证分区内部的有序性;同一个topic的不同分区,不能保证数据有序
每个消费者可以控制自己的消费偏移量,多个消费者消费消息互不干扰
offset是下一次要读取的位置
kafka的消息消费是以消费组的形式进行消费
同一消费组中的消费者对消息进行均分消费
消费组个数一般要小于topic中的分区数
kafka高吞吐量,即使是普通的服务器,也可以支持每秒百万级的写入,超过了大部分的消息中间件
kafka的消息是以日志的形式存储在磁盘中,为了优化写入速度,采用了顺序写入和MMFile两个技术。顺序写可以减少磁盘寻址时间,MMFile(内存映射文件)可以减少IO,使写入性能逼近内存

kafka的服务将数据往pageCache中写入,由pageCache写入磁盘
4. DMA
常规IO操作会让CPU阻塞,等待从磁盘中读取数据;

DMA(直接内存访问)读取会新增DMA,减少CPU的阻塞
零拷贝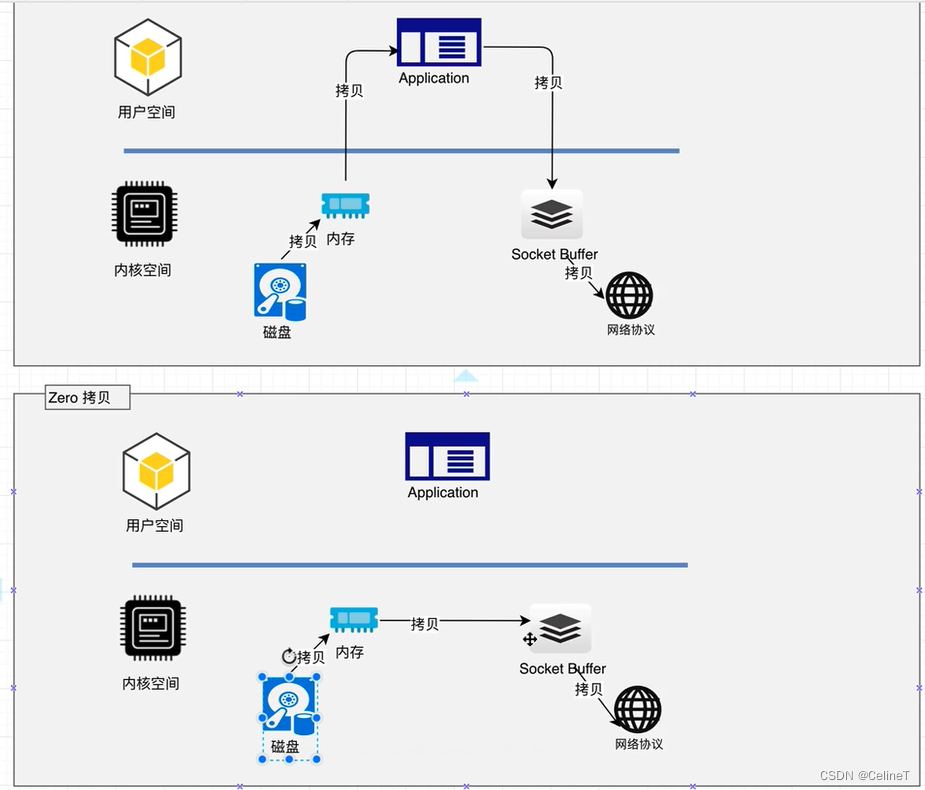
5. 知识点
副本因子的个数不能大于broker的个数
kafka中的分区数只能增,不能减
kafka的操作,默认是异步的
kafka也需要对key、value进行序列化(redis也需要)
生产者发送消息时,对消息进行序列化
消费者消费消息时,要对消息进行反序列化
subscribe消费时,通过消费组实现负载均衡;
assign消费时,可以指定分区、offset进行消费
6. 默认的分区策略
1. 如果指定了分区,使用指定的
2. 如果没有指定分区,key存在,那么分区基于key的hash值
3. 如果没有指定分区,也没有key,那么轮讯
也可以自定义分区策略,实现Partitioner接口
默认没有拦截器,可以自定义拦截器
拦截器可以对发送过来的消息进行修改
当消费者首次消费时(kafka中没有记载offset),默认消费最新的消息,也可以进行设置
可以设置offset自动提交的时间间隔

7. ack
ack可以保证消息可靠性

8. 重复消费
生产者正常发生消息,消费者正常消费消息,但是消费完消息给生产者发送应答失败。生产者会认为消息没有消费成功,会重试,此时会造成消息重复消费
重试次数,不包含第一次发送
怎么避免消息重复消费:
服务端对消息进行校验,看看是否是重复的请求
添加唯一标识,并记录该标识是否消费完成
幂等:
kafka中幂等默认是关闭的,在使用幂等的时候,必须开启retries=true和acks=all

kafka的幂等只能保证一条记录在分区内发送的原子性;要保证多分区的多条记录之间的完整性,需要事务
9. 事务
kafka的事务分为生产者事务、消费者&生产者事务
kafka开启事务后,需要将隔离级别改成read_committed(默认是read_uncommitted)
消费者端开启事务后,需要关闭自动提交offset
事务流程
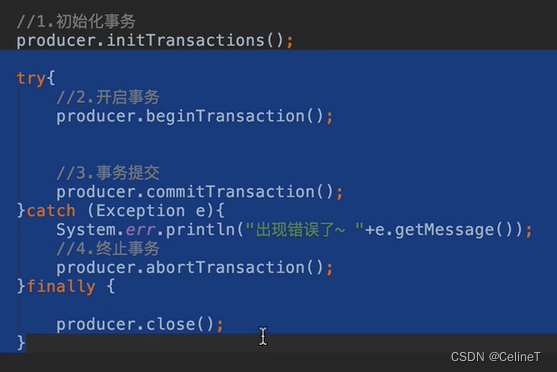
10. 数据同步机制(leader到follower)
partition底层是按照segment(段)对文件进行存储
HW(high watermarker):高水位线,HW之前的数据都已经完成备份。当所有节点都备份成功,leader才会更新HW
LEO(log end offset):标识的是分区中最后一条消息的下一个位置,每个分区副本有自己的LEO
ISR:是leader维护的一份处于同步的副本集合,要是followerf同步很慢,会被踢出isr
OSR:于leader副本同步滞后过多的副本(不包括leader副本)将组成 OSR
AR:分区中的所有副本统称为 AR。AR=ISR+OSR
kafka0.11版本之前,通过高水位(HW)来保持数据同步
缺点:
1. 数据丢失
2. leader和follower数据不一致
kafka0.11之后,引入了Leader Epoch来解决数据同步问题,代替HW作为消息的截断点
11. 监控
kafka eagle可以对kafka进行监控
12. 整合SpringBoot
Springboot中使用@KafkaListeners进行监听,接收消息
使用@SendTo发送消息
也可以使用KafkaTemplate进行操作
kafka的事务也支持@Transactional注解