接着上篇《Python库学习(十一):数据分析Pandas[上篇]》,继续学习Pandas
1.数据过滤
在数据处理中,我们经常会对数据进行过滤,为此Pandas中提供mask()和where()两个函数;
-
mask(): 在 满足条件的情况下替换数据,而不满足条件的部分则保留原始数据; -
where(): 在 不满足条件的情况下替换数据,而满足条件的部分则保留原始数据;
from datetime import datetime, timedelta
import random
import pandas as pd
def getDate() -> str:
"""
用来生成日期
:return:
"""
# 随机减去天数
tmp = datetime.now() - timedelta(days=random.randint(1, 100))
# 格式化时间
return tmp.strftime("%Y-%m-%d")
if __name__ == '__main__':
# 准备数据 水果
fruits = ["苹果", "香蕉", "橘子", "榴莲", "葡萄"]
rows = 3
today = datetime.now()
data_dict = {
"fruit": [random.choice(fruits) for _ in range(rows)],
"date": [getDate() for _ in range(rows)],
"price": [round(random.uniform(1, 5), 2) for _ in range(rows)], # 随机生成售价,并保留两位小数
}
data = pd.DataFrame(data_dict)
# 复制数据,方便后续演示
data_tmp = data.copy()
print("-------------- 生成数据预览 ------------------")
print(data)
print("-------------- 普通条件:列出价格大于3.0的水果 ------------------")
condition = data["price"] > 3.0
# 列出价格大于3.0的水果
fruit_res = data[condition]["fruit"]
print("价格大于3.0的水果:", fruit_res.to_numpy())
print("-------------- 使用mask:把价格大于3.0设置成0元 ------------------")
# 把价格大于3.0设置成0元
data["price"] = data["price"].mask(data["price"] > 3.0, other=0)
print(data)
print("-------------- 使用where:把价格不大于3.0设置成0元 ------------------")
# 把价格不大于3.0设置成0元
data_tmp["price"] = data_tmp["price"].where(data_tmp["price"] > 3.0, other=0)
print(data_tmp)
"""
-------------- 生成数据预览 ------------------
fruit date price
0 橘子 2023-10-16 3.52
1 苹果 2023-09-08 1.07
2 葡萄 2023-09-27 2.69
-------------- 普通条件:列出价格大于3.0的水果 ------------------
价格大于3.0的水果: ['橘子']
-------------- 使用mask:把价格大于3.0设置成0元 ------------------
fruit date price
0 橘子 2023-10-16 0.00
1 苹果 2023-09-08 1.07
2 葡萄 2023-09-27 2.69
-------------- 使用where:把价格不大于3.0设置成0元 ------------------
fruit date price
0 橘子 2023-10-16 3.52
1 苹果 2023-09-08 0.00
2 葡萄 2023-09-27 0.00
"""
@注:从功能上可以看出,mask()和where()是正好两个相反的函数
2. 数据遍历
if __name__ == '__main__':
# 数据生成参考上面
print("-------------- 生成数据预览 ------------------")
print(data)
print("-------------- 遍历dataframe数据 ------------------")
for index, row in data.iterrows():
print("index:{} 水果:{} 日期:{} 售价:{}".format(index, row["fruit"], row["date"], row["price"]))
print("-------------- 遍历Series数据 ------------------")
series_data = pd.Series({"name": "张三", "age": 20, "height": 185})
for k, v in series_data.items():
print("key:{} value:{}".format(k, v))
"""
-------------- 生成数据预览 ------------------
fruit date price
0 橘子 2023-10-14 3.71
1 橘子 2023-10-03 3.74
2 香蕉 2023-09-06 1.17
3 葡萄 2023-08-30 1.16
4 榴莲 2023-10-21 1.47
-------------- 遍历dataframe数据 ------------------
index:0 水果:橘子 日期:2023-10-14 售价:3.71
index:1 水果:橘子 日期:2023-10-03 售价:3.74
index:2 水果:香蕉 日期:2023-09-06 售价:1.17
index:3 水果:葡萄 日期:2023-08-30 售价:1.16
index:4 水果:榴莲 日期:2023-10-21 售价:1.47
-------------- 遍历Series数据 ------------------
key:name value:张三
key:age value:20
key:height value:185
"""
3. 分层索引
分层索引(MultiIndex)是Pandas 中一种允许在一个轴上拥有多个(两个或更多)级别的索引方式。这种索引方式适用于多维数据和具有多个层次结构的数据。
3.1 使用set_index
from datetime import datetime, timedelta
import random
import pandas as pd
if __name__ == '__main__':
# 创建一个示例 DataFrame
fruits = ["苹果", "苹果", "橘子", "橘子", "橘子", "百香果"]
rows = len(fruits)
today = datetime.now()
dict_var = {
'fruit': fruits,
'date': [(today - timedelta(days=i)).strftime("%Y-%m-%d") for i in range(rows)],
'price': [round(random.uniform(1, 5), 2) for _ in range(rows)],
'num': [round(random.uniform(10, 500), 2) for _ in range(rows)]
}
sale_data = pd.DataFrame(dict_var)
# 设置多层次索引
sale_data.set_index(['fruit', 'date'], inplace=True)
print("----------------------------- 创建多层次索引-----------------------------------")
print(sale_data)
print("----------------------------- 打印索引信息-----------------------------------")
index_info = sale_data.index
print(index_info)
print("----------------------------- 使用loc 访问多层次索引-----------------------------------")
search_price = sale_data.loc[('苹果', '2023-11-02'), 'price']
print(search_price)
print("----------------------------- 使用xs 访问多层次索引-----------------------------------")
search_xs = sale_data.xs(key=('苹果', '2023-11-02'), level=['fruit', 'date'])
print(search_xs)
"""
----------------------------- 创建多层次索引-----------------------------------
price num
fruit date
苹果 2023-11-02 1.08 211.31
2023-11-01 1.35 308.87
橘子 2023-10-31 3.25 180.84
2023-10-30 2.53 115.14
2023-10-29 2.61 146.49
百香果 2023-10-28 1.36 246.01
----------------------------- 打印索引信息-----------------------------------
MultiIndex([( '苹果', '2023-11-02'),
( '苹果', '2023-11-01'),
( '橘子', '2023-10-31'),
( '橘子', '2023-10-30'),
( '橘子', '2023-10-29'),
('百香果', '2023-10-28')],
names=['fruit', 'date'])
----------------------------- 使用loc 访问多层次索引-----------------------------------
1.08
----------------------------- 使用xs 访问多层次索引-----------------------------------
price num
fruit date
苹果 2023-11-02 1.08 211.31
"""
3.2 使用**MultiIndex**
if __name__ == '__main__':
fruits = ["苹果", "香蕉", "橘子", "榴莲", "葡萄", "雪花梨", "百香果"]
date_list = ['2023-03-11', '2023-03-13', '2023-03-15']
cols = pd.MultiIndex.from_product([date_list, ["售卖价", "成交量"]], names=["日期", "水果"])
list_var = []
for i in range(len(fruits)):
tmp = [
round(random.uniform(1, 5), 2), round(random.uniform(1, 100), 2),
round(random.uniform(1, 5), 2), round(random.uniform(1, 100), 2),
round(random.uniform(1, 5), 2), round(random.uniform(1, 100), 2),
]
list_var.append(tmp)
print("--------------------------------创建多层次索引--------------------------------")
multi_data = pd.DataFrame(list_var, index=fruits, columns=cols)
print(multi_data)
print("--------------------------------打印多层次索引--------------------------------")
print(multi_data.index)
print(multi_data.columns)
# 搜行
print("----------------------------- 使用filter-- 行搜索-----------------------------------")
print(multi_data.filter(like='苹果', axis=0))
print("----------------------------- 使用filter-- 列搜索-----------------------------------")
# 搜列
print(multi_data.filter(like='2023-03-11', axis=1))
"""
--------------------------------创建多层次索引--------------------------------
日期 2023-03-11 2023-03-13 2023-03-15
水果 售卖价 成交量 售卖价 成交量 售卖价 成交量
苹果 2.54 69.40 3.27 18.89 1.93 3.37
香蕉 1.99 53.33 1.88 92.77 3.64 26.60
橘子 2.48 27.81 3.20 8.71 2.58 85.44
榴莲 3.15 47.89 1.09 93.15 2.51 85.30
葡萄 4.59 35.58 4.88 77.02 3.08 64.96
雪花梨 3.17 9.58 4.48 44.17 4.15 88.94
百香果 3.05 7.65 3.51 82.03 3.97 52.06
--------------------------------打印多层次索引--------------------------------
Index(['苹果', '香蕉', '橘子', '榴莲', '葡萄', '雪花梨', '百香果'], dtype='object')
MultiIndex([('2023-03-11', '售卖价'),
('2023-03-11', '成交量'),
('2023-03-13', '售卖价'),
('2023-03-13', '成交量'),
('2023-03-15', '售卖价'),
('2023-03-15', '成交量')],
names=['日期', '水果'])
----------------------------- 使用filter-- 行搜索-----------------------------------
日期 2023-03-11 2023-03-13 2023-03-15
水果 售卖价 成交量 售卖价 成交量 售卖价 成交量
苹果 2.54 69.4 3.27 18.89 1.93 3.37
----------------------------- 使用filter-- 列搜索-----------------------------------
日期 2023-03-11
水果 售卖价 成交量
苹果 2.54 69.40
香蕉 1.99 53.33
橘子 2.48 27.81
榴莲 3.15 47.89
葡萄 4.59 35.58
雪花梨 3.17 9.58
百香果 3.05 7.65
"""
4. 数据读写
4.1 写入表格
from datetime import datetime, timedelta
import random
import pandas as pd
if __name__ == '__main__':
fruits = ["苹果", "香蕉", "橘子", "榴莲", "葡萄", "雪花梨", "百香果"]
rows = 20
today = datetime.now()
print(today.strftime("%Y-%m-%d %H:%M:%S.%f")[:-3])
dict_var = {
'水果': [random.choice(fruits) for _ in range(rows)],
'进价': [round(random.uniform(1, 5), 4) for _ in range(rows)],
'售价': [round(random.uniform(1, 5), 4) for _ in range(rows)],
'日期': [(today - timedelta(days=i)).strftime("%Y-%m-%d") for i in range(rows)],
'销量': [round(random.uniform(10, 500), 4) for _ in range(rows)]
}
sale_data = pd.DataFrame(dict_var)
print(sale_data)
# 保存,浮点数保留两位小数
sale_data.to_excel("./test.xlsx", float_format="%.2f")
a.主要参数说明:
-
excel_writer:Excel文件名或ExcelWriter对象。如果是文件名,将创建一个ExcelWriter对象,并在退出时自动关闭文件。 -
sheet_name: 字符串,工作表的名称,默认为Sheet1。 -
na_rep: 用于表示缺失值的字符串,默认为空字符串。 -
float_format: 用于设置浮点数列的数据格式。默认为None,表示使用Excel默认的格式,当设置%.2f表示保留两位。 -
columns: 要写入的列的列表,默认为None。如果设置为None,将写入所有列;如果指定列名列表,将只写入指定的列。 -
header: 是否包含列名,默认为True。如果设置为False,将不写入列名。 -
index: 是否包含行索引,默认为True。如果设置为False,将不写入行索引。 -
index_label: 用于指定行索引列的名称。默认为None。 -
startrow: 数据写入的起始行,默认为0。 -
startcol: 数据写入的起始列,默认为0。 -
freeze_panes: 值是一个元组,用于指定要冻结的行和列的位置。例如,(2, 3)表示冻结第 2 行和第 3 列。默认为None,表示不冻结任何行或列。
4.2 读取表格
import pandas as pd
if __name__ == '__main__':
# ------------------------------ 读取表格 ----------------------------------
print("----------------------------- 读取全部数据 -----------------------")
# 读取全部数据
read_all_data = pd.read_excel("./test.xlsx")
print(read_all_data)
print("----------------------------- 只读取第1、2列数据 -----------------------")
# 只读取第1、2列数据
read_column_data = pd.read_excel("./test.xlsx", usecols=[1, 2])
print(read_column_data)
print("----------------------------- 只读取列名为:日期、销量 的数据 -----------------------")
# 读取
read_column_data2 = pd.read_excel("./test.xlsx", usecols=['日期', '销量'])
print(read_column_data2)
"""
----------------------------- 读取全部数据 -----------------------
Unnamed: 0 水果 进价 售价 日期 销量
0 0 榴莲 3.74 2.35 2023-11-03 217.03
1 1 百香果 2.08 3.64 2023-11-02 311.40
2 2 百香果 2.17 4.94 2023-11-01 404.55
3 3 橘子 2.41 2.71 2023-10-31 431.20
4 4 葡萄 2.78 3.99 2023-10-30 323.01
5 5 苹果 4.79 1.68 2023-10-29 161.26
6 6 百香果 1.61 2.78 2023-10-28 407.27
7 7 榴莲 1.56 4.08 2023-10-27 44.74
8 8 雪花梨 1.60 3.02 2023-10-26 119.13
9 9 葡萄 3.03 1.08 2023-10-25 152.87
----------------------------- 只读取第1、2列数据 -----------------------
水果 进价
0 榴莲 3.74
1 百香果 2.08
2 百香果 2.17
3 橘子 2.41
4 葡萄 2.78
5 苹果 4.79
6 百香果 1.61
7 榴莲 1.56
8 雪花梨 1.60
9 葡萄 3.03
----------------------------- 只读取列名为:日期、销量 的数据 -----------------------
日期 销量
0 2023-11-03 217.03
1 2023-11-02 311.40
2 2023-11-01 404.55
3 2023-10-31 431.20
4 2023-10-30 323.01
5 2023-10-29 161.26
6 2023-10-28 407.27
7 2023-10-27 44.74
8 2023-10-26 119.13
9 2023-10-25 152.87
"""
主要参数说明:
-
io: 文件路径、ExcelWriter对象或者类似文件对象的路径/对象。 -
sheet_name: 表示要读取的工作表的名称或索引。默认为 0,表示读取第一个工作表。 -
header: 用作列名的行的行号。默认为 0,表示使用第一行作为列名。 -
names: 覆盖 header 的结果,即指定列名。 -
index_col: 用作行索引的列的列号或列名。 -
usecols: 要读取的列的列表,可以是列名或列的索引。
4.3 更多方法
除了上面的表格读取,还有更多类型的读取方式,方法简单整理如下:

5.数据可视化
Pandas底层对Matplotlib进行了封装,所以可以直接使用Matplotlib的绘图方法;
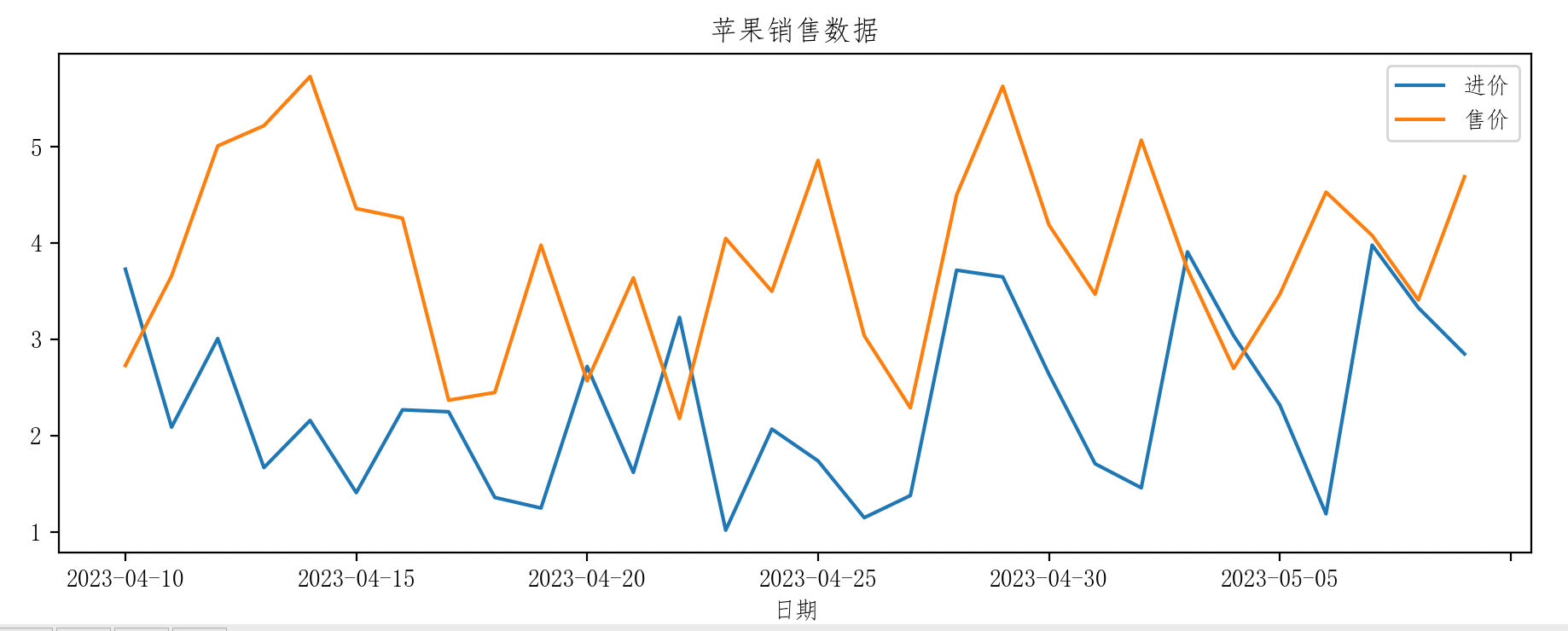
5.1 折线图
from datetime import datetime, timedelta
import random
import pandas as pd
from matplotlib import pyplot as plt
# 设置字体以便正确显示中文
plt.rcParams['font.sans-serif'] = ['FangSong']
# 正确显示连字符
plt.rcParams['axes.unicode_minus'] = False
if __name__ == '__main__':
# ------------------------------ 生成数据 ----------------------------------
rows = 30
beginDate = datetime(2023, 4, 10)
print("beginDate:", beginDate.strftime("%Y-%m-%d"))
dict_var = {
'日期': [(beginDate + timedelta(days=i)).strftime("%Y-%m-%d") for i in range(rows)],
'进价': [round(random.uniform(1, 4), 2) for _ in range(rows)],
'售价': [round(random.uniform(2, 6), 2) for _ in range(rows)],
}
apple_data = pd.DataFrame(dict_var)
apple_data.plot(x='日期', y=['进价', '售价'], title='苹果销售数据')
plt.show()
5.2 散点图
from datetime import datetime, timedelta
import random
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
# 设置字体以便正确显示中文
plt.rcParams['font.sans-serif'] = ['FangSong']
# 正确显示连字符
plt.rcParams['axes.unicode_minus'] = False
if __name__ == '__main__':
# ------------------------------ 生成数据 ----------------------------------
rows = 30
beginDate = datetime(2023, 4, 1)
print("beginDate:", beginDate.strftime("%Y-%m-%d"))
dict_var = {
'日期': [(beginDate + timedelta(days=i)).strftime("%d") for i in range(rows)],
'进价': [round(random.uniform(1, 4), 2) for _ in range(rows)],
'售价': [round(random.uniform(2, 10), 2) for _ in range(rows)],
'销量': [round(random.uniform(10, 500), 4) for _ in range(rows)]
}
apple_data = pd.DataFrame(dict_var)
# 设置颜色
colorList = 10 * np.random.rand(rows)
# 设置
apple_data.plot(x='日期', y='售价', kind='scatter', title='苹果销售数据', color=colorList, s=dict_var['销量'])
plt.show()
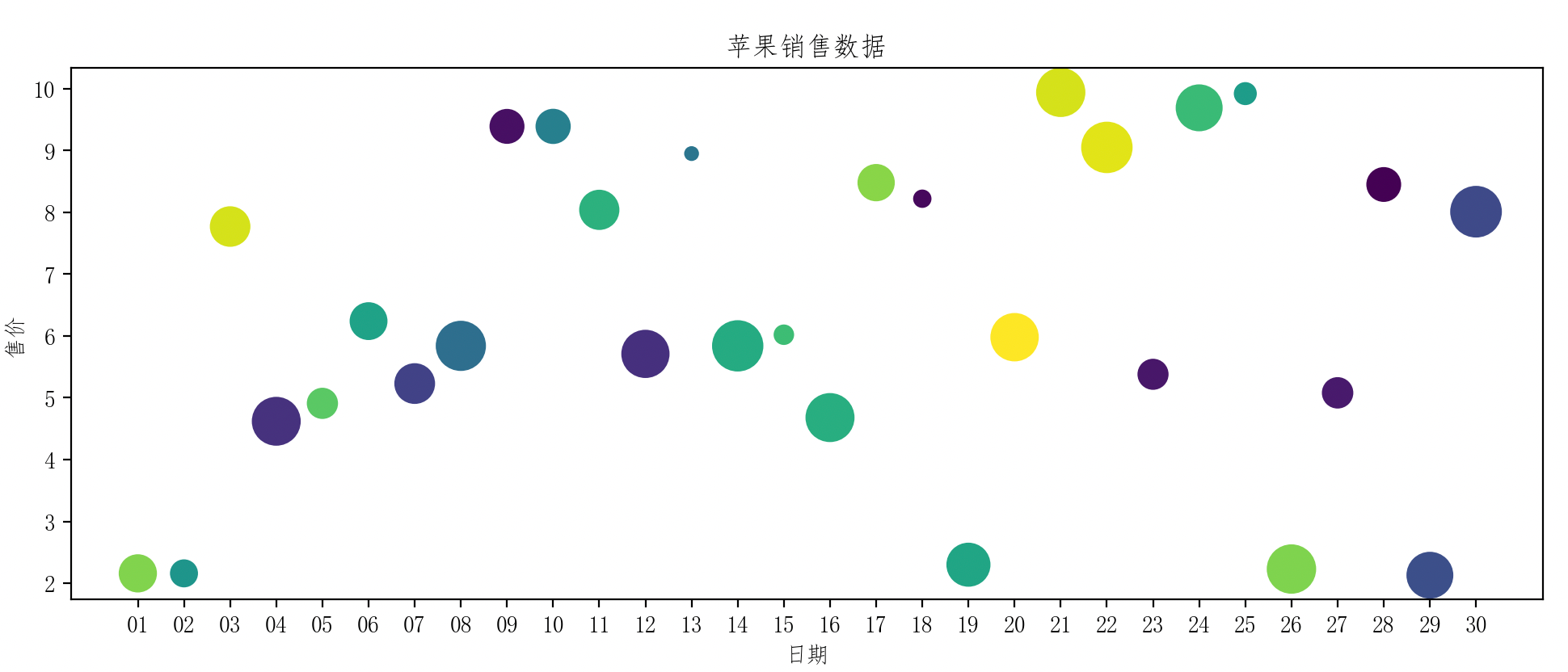
-
color:表示的是颜色,可以使用字符串表示颜色名称,也可以使用十六进制颜色码。 -
s: 散点图特有的属性,表示散点大小。
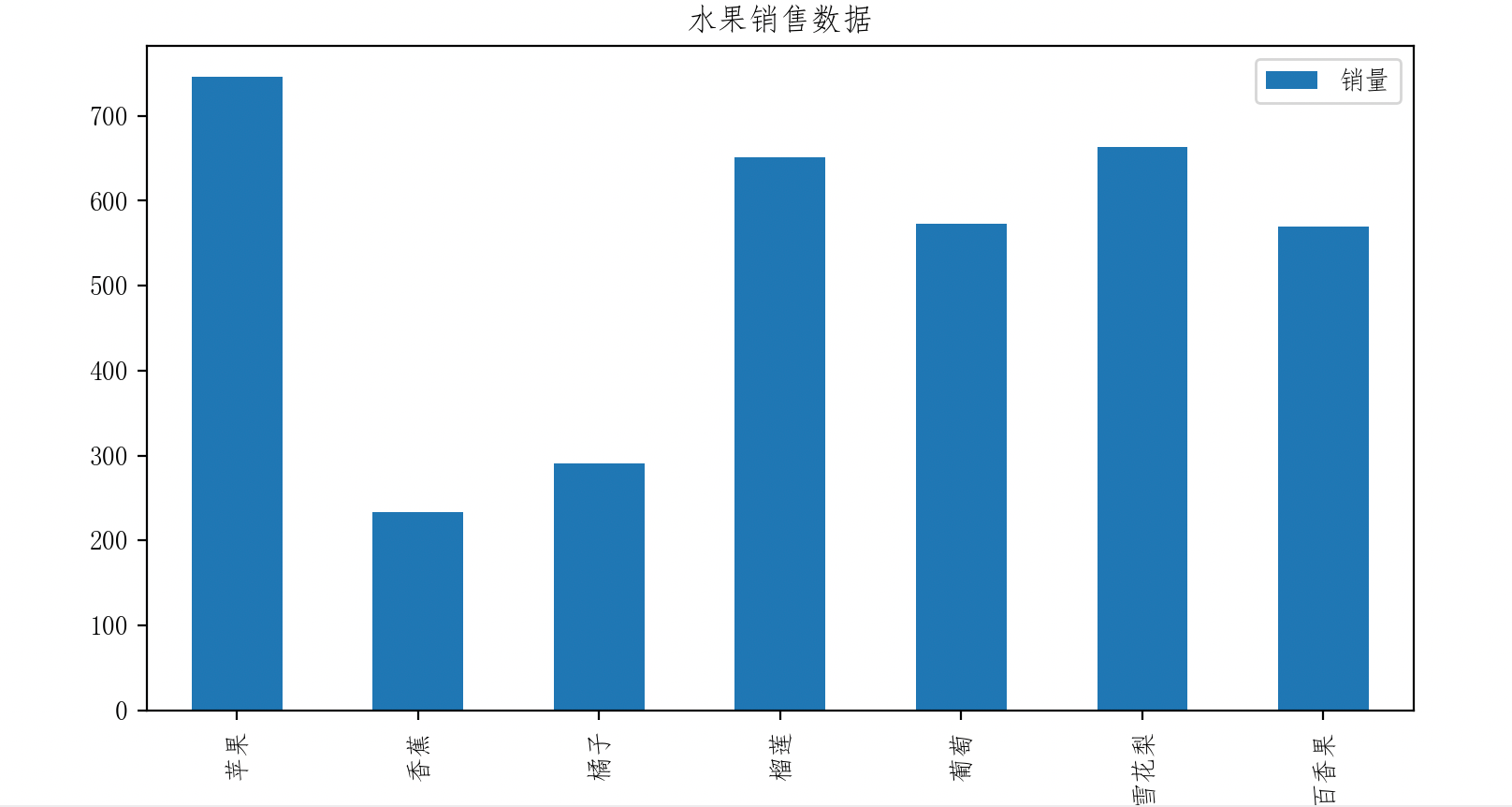
5.3 柱形图
import random
import pandas as pd
from matplotlib import pyplot as plt
# 设置字体以便正确显示中文
plt.rcParams['font.sans-serif'] = ['FangSong']
# 正确显示连字符
plt.rcParams['axes.unicode_minus'] = False
if __name__ == '__main__':
# ------------------------------ 生成数据 ----------------------------------
fruits = ["苹果", "香蕉", "橘子", "榴莲", "葡萄", "雪花梨", "百香果"]
rows = 7
beginDate = datetime(2023, 4, 1)
print("beginDate:", beginDate.strftime("%Y-%m-%d"))
dict_var = {
'水果': ["苹果", "香蕉", "橘子", "榴莲", "葡萄", "雪花梨", "百香果"],
'销量': [round(random.uniform(10, 1000), 2) for _ in range(rows)]
}
apple_data = pd.DataFrame(dict_var)
apple_data.plot(x='水果', y='销量', kind='bar', title='水果销售数据')
plt.show()
本文由 mdnice 多平台发布