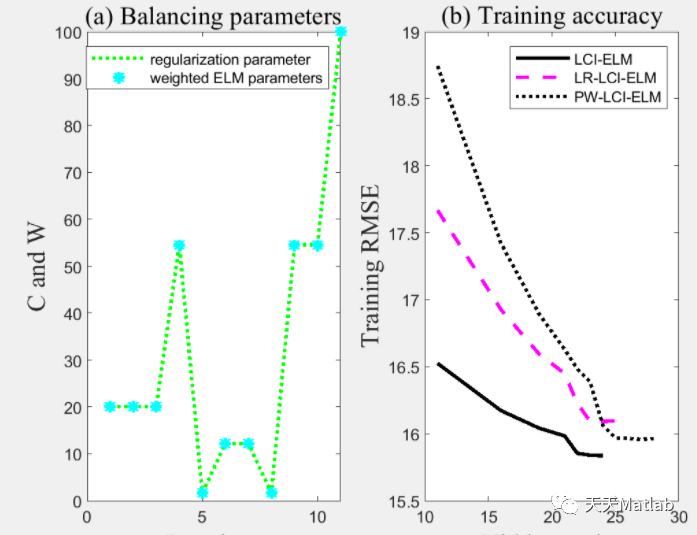
前言
众所周知,事务的一大特点是原子性,即同一事务的SQL要同时成功或者失败。那大家有没有想过在MySQL的innoDB存储引擎中是如何保证这样的原子性操作的?实际上它是利用事务执行过程中生成的日志undo log来实现的,那么undo log究竟是怎么一回事呢?
undo log介绍
大家不妨先思考下,如果事务中的SQL执行到一半,遇到报错,需要把前面已经执行过的SQL撤销以达到原子性的目的,这个过程也叫做"回滚",该怎么实现呢?
每当我们要对一条记录做改动时(这里的改动可以指INSERT、DELETE、UPDATE),把回滚时所需的东西记下来。比如:
- 你插入一条记录时,至少要把这条记录的主键值记下来,之后回滚的时候只需要把这个主键值对应的记录删
掉就好了
- 你删除了一条记录,至少要把这条记录中的内容都记下来,这样之后回滚时再把由这些内容组成的记录插入
到表中就好了
- 你修改了一条记录,至少要把修改这条记录前的旧值都记录下来,这样之后回滚时再把这条记录更新为旧值
MySQL把这些为了回滚而记录的这些内容称之为撤销日志或者回滚日志, 即undo log 。
undo log存储形式
undo log的日志内容是逻辑日志,非物理日志。
- 物理日志的意思是指具体的把具体某个数据页上的某个偏移量的指改为什么,是具体到物理结构上了,比如
redo log就是物理日志。 - 而逻辑日志只是记录了某条数据的信息是怎么样的,没有到具体的物理磁盘上
InnoDB对undo log的管理采用段的方式,也就是回滚段(rollback segment) 。每个回滚段记录了 1024 个 undo log segment ,每个事务只会使用一个回滚段,当一个事务开始的时候,会制定一个回滚段,在事务进行的过程中,当数据被修改时,原始的数据会被复制到回滚段。
在MySQL5.5的时候,只有一个回滚段,那么最大同时支持的事务数量为1024个。在MySQL 5.6开始,InnoDB支持最大 128个回滚段,故其支持同时在线的事务限制提高到了 128*1024 。
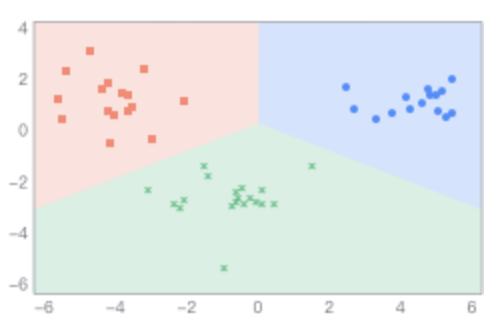
- insert undo log格式
记录的是insert 语句对应的undo log,它生成的undo log记录格式如下图:

- update undo log格式
记录的是update、delete 语句对应的undo log,它生成的undo log记录格式如下图:
那么上面这些生成undo log日志文件最终是存储在哪的呢?
这些回滚段是存储于共享表空间ibdata中。从MySQL5.6版本开始,可通过参数对rollback segment做进一步的设置。这些参数包括:
innodb_undo_directory: 设置rollback segment文件所在的路径。这意味着rollback segment可以存放在共享表空间以外的位置,即可以设置为独立表空间。该参数的默认值为“/”,表示当前noDB存储引擎的目录。innodb_undo_logs: 设置rollback segment的个数,默认值为128。innodb_undo_tablespaces: 设置构成rollback segment文件的数量,这样rollback segment可以较为平均地分布在多个文件中。设置该参数后,会在路径innodb_undo_directory看到undo为前缀的文件,该文件就代表rollback segment文件。
事务回滚机制
对于InnoDB引擎来说,每个行记录除了记录本身的数据之外,还有几个隐藏的列:
DB_ROW_ID:如果没有为表显式的定义主键,并且表中也没有定义唯一索引,那么InnoDB会自动为表添加一个row_id的隐藏列作为主键。DB_TRX_ID:每个事务都会分配一个事务ID,当对某条记录发生变更时,就会将这个事务的事务ID写入tx_id
中。
DB_ROLL_PTR: 回滚指针,本质上就是指向undo log的指针。
- insert数据:
insert into user (name, sex) values('旭阳', '女')
插入的数据都会生成一条insert undo log,并且数据的回滚指针会指向它。undo log会记录undo log的序号、插入主键的列和值…,那么在进行rollback的时候,通过主键直接把对应的数据删除即可。

- update数据
update user set sex = '男' where id = 1;
update user set name = 'alvin' where id = 1;
这时会把老的记录写入新的undo log,让回滚指针指向新的undo log,它的undo no是1,并且新的undo log会指向老的undo log(undo no=0),最终形成undo log版本链,如下图所示:

可以发现每次对数据的变更都会产生一个undo log,当一条记录被变更多次时,那么就会产生多条undo log,undo log记录的是变更前的日志,并且每个undo log的序号是递增的,那么当要回滚的时候,按照序号依次向前推,就可以找到我们的原始数据了。
那么按照上面的例子,事务要进行回滚,最终得到下面的执行流程:
-
通过
undo no=2的日志把id=1的数据的name还原成“旭阳" -
通过
undo no=1的日志把id=1的数据的sex还原成"女" -
通过
undo no=0的日志把id=1的数据根据主键信息删除
undo log生命周期
生成过程
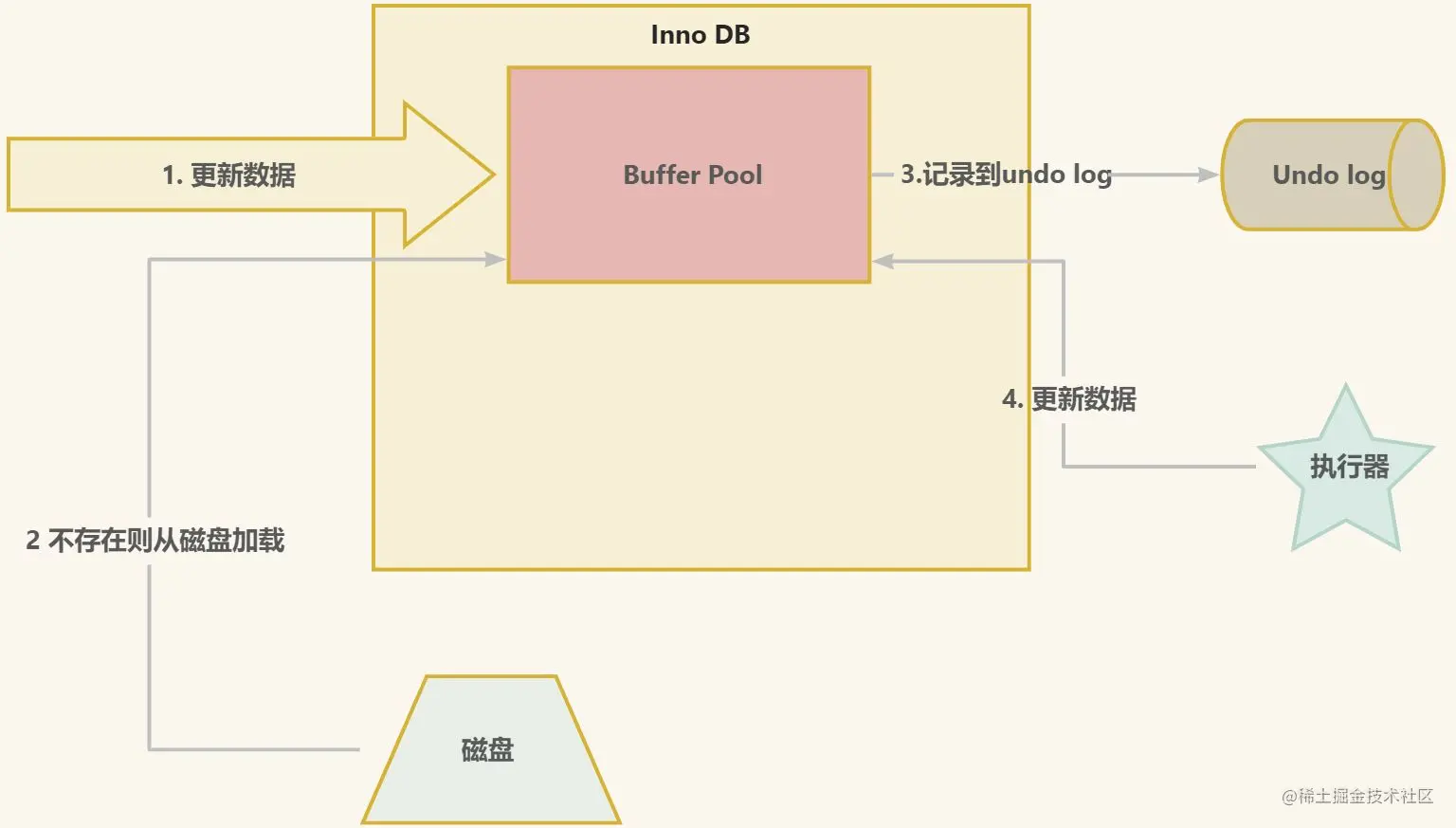
MySQL处于性能考虑,数据会优先从磁盘加载到Buffer Pool中,在更新Buffer Pool中数据之前,会优先将数据记录到undo log中。
记录undo log日志,MySQL不会直接去往磁盘中的xx.ibdata文件写数据,而是会写在undo_log_buffer缓冲区中,因为工作线程直接去写磁盘太影响效率了,写进缓冲区后会由后台线程去刷写磁盘。
删除过程
现在我们已经明白了undo log日志是如何生成,并且作用于事务回滚的,那这些数据是什么时候删除呢?
- 针对于
insert undo log,因为insert操作的记录,只对事务本身可见,对其他事务不可见。故该undo log在事务提交后就没有用,就会直接删除。
● 针对于update undo log,该undo log需要支持MVCC机制,因此不能在事务提交时就进行删除。提交时放入undo log链表,有专门的purge线程进行删除。
总结
本文详细讲解了MySQL中redo log日志的用处,以及它是如何保证事务的原子性。实际上,redo log也还有一个很重要的左右就是还对事务的隔离性实现起到作用,具体的在后面的MVCC机制中详细说明。如果本文对你有帮助的话,请留下一个赞吧。



![[附源码]SSM计算机毕业设计8号体育用品销售及转卖系统JAVA](https://img-blog.csdnimg.cn/40f0eab89c4c4c6b8a9cb272e33750f7.png)