CVPR2018
人脸识别 脸部特效
张翔宇

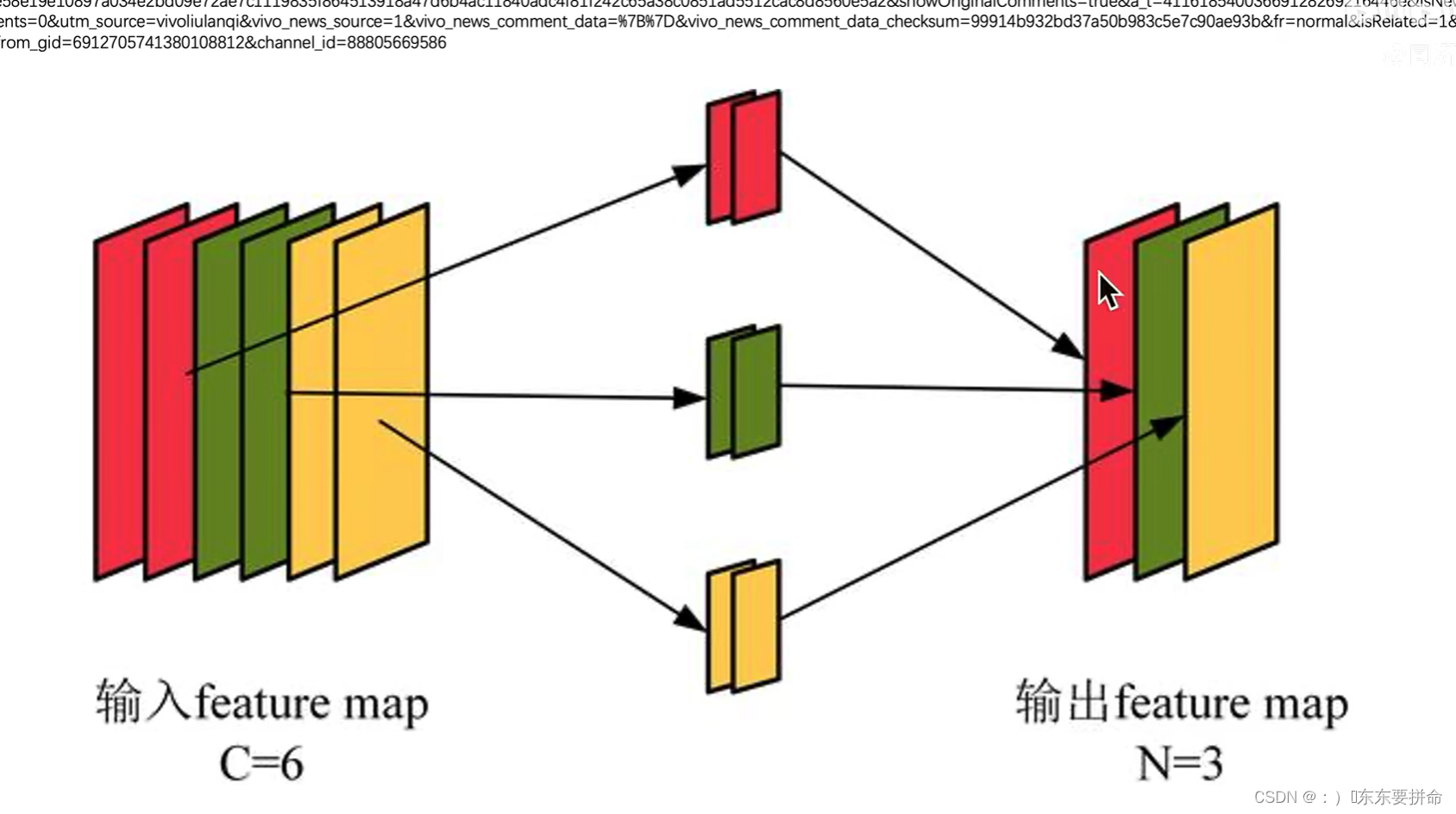
什么是分组卷积
我们可以回忆一下 普通卷积
feature map有几个 我们的对应的卷积核就需要几个channel
然后我们学习这个 分组卷积
如图所示,前两个channel 有一个2个channel的卷积核负责,两个与两个对应
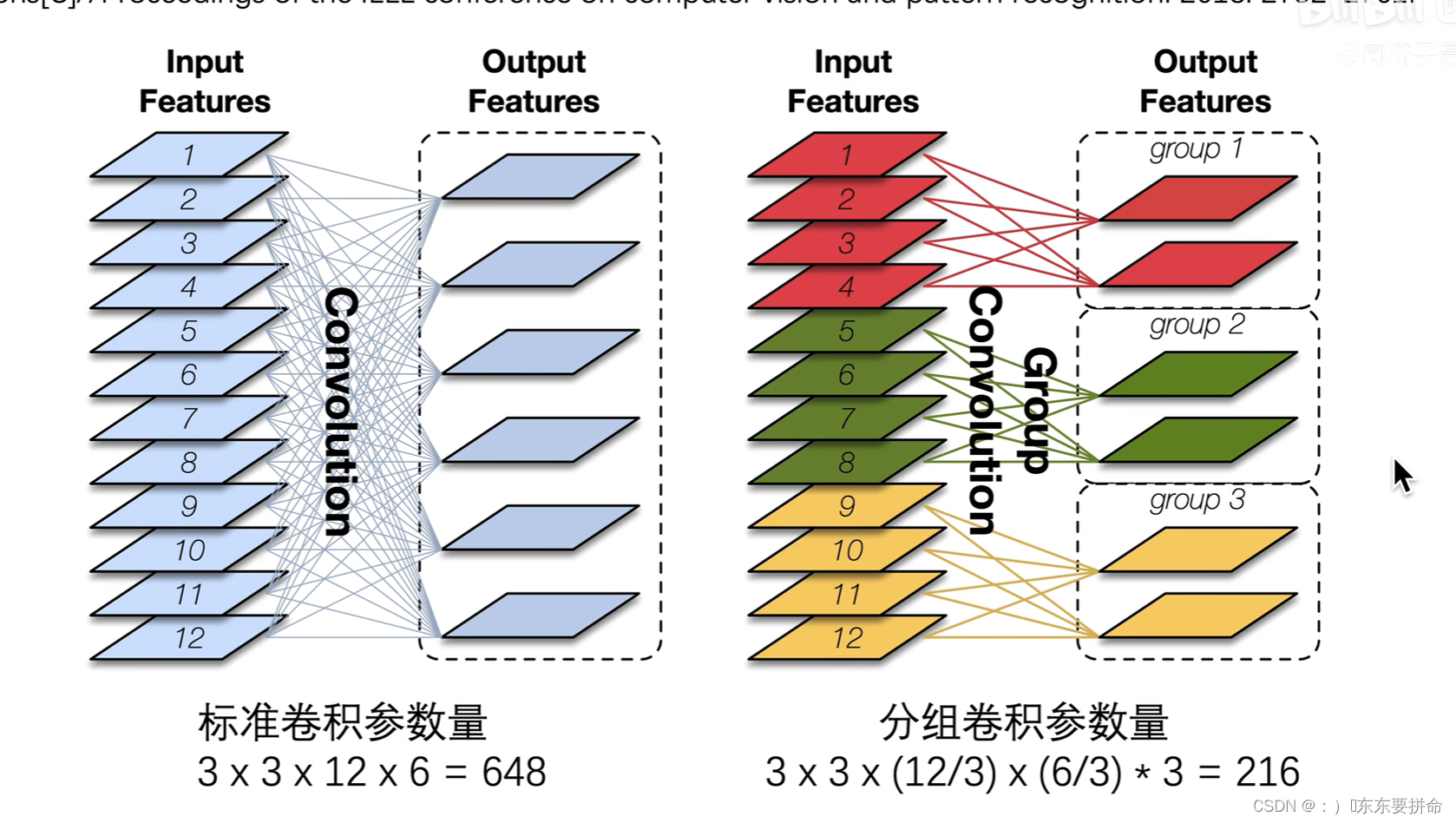
![]() 来自这篇论文
来自这篇论文
在解释一遍 一个卷积核 处理featuremap的所有通道
而 分组卷积 则是 红对红 绿对绿 黄对黄 分别处理featuremap的四个通道
最后 我们看到 这个参数量 少了接近三倍
下面解释一下这个 参数量怎么看
原来的卷积 3*3 是卷积核的大小 要12个通道 有6个卷积核
则是 3*3*12*6
但是现在的分组卷积就不一样了
卷积核大小不变 但是每组的卷积核掌握的通道数不一样
一个卷积核掌握4个通道 每组两个 也是6个
3*3*4*6
从原来的648减少到 216 可谓是一大进步
显著的降低参数量 进而降低计算量
这也带来了 一些缺点 虽然 做了相应的轻量化,但是也引出了 近亲繁殖的 缺点
分组卷积 提取的特征没有很好的 全局性 也是这个结构所引起的 组与组之间
不能相互通信
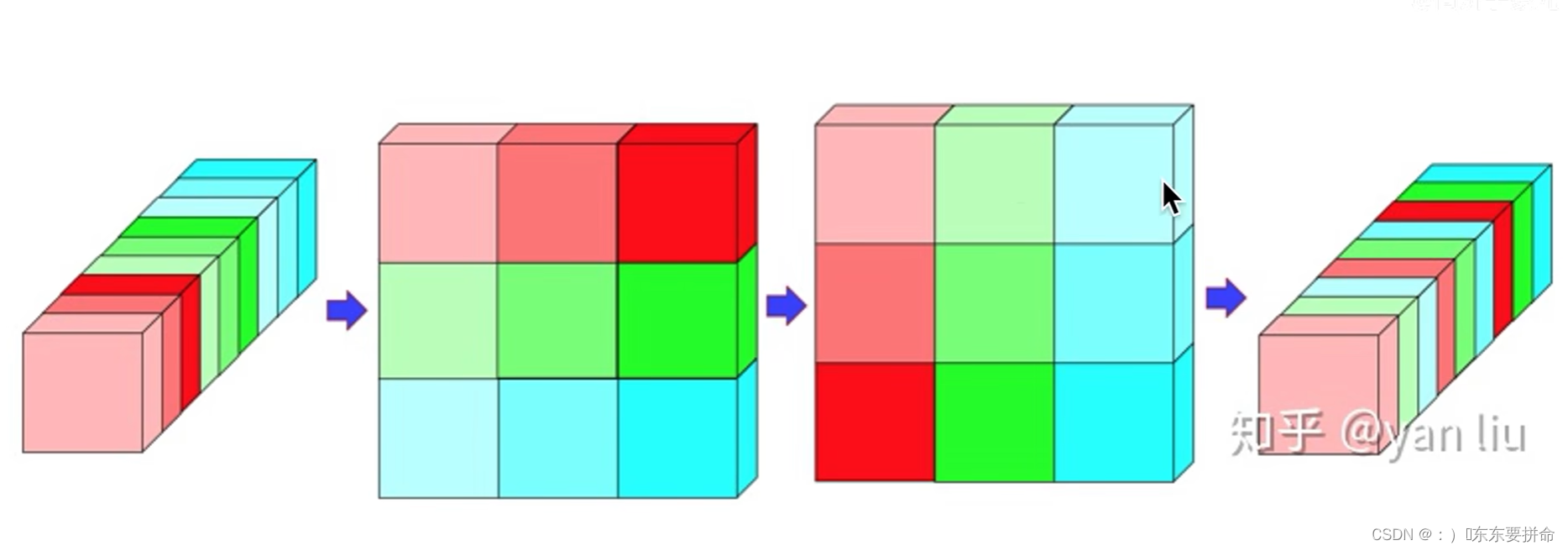
所以 为了解决这个问题 引入了 channel shuffle 通道重排
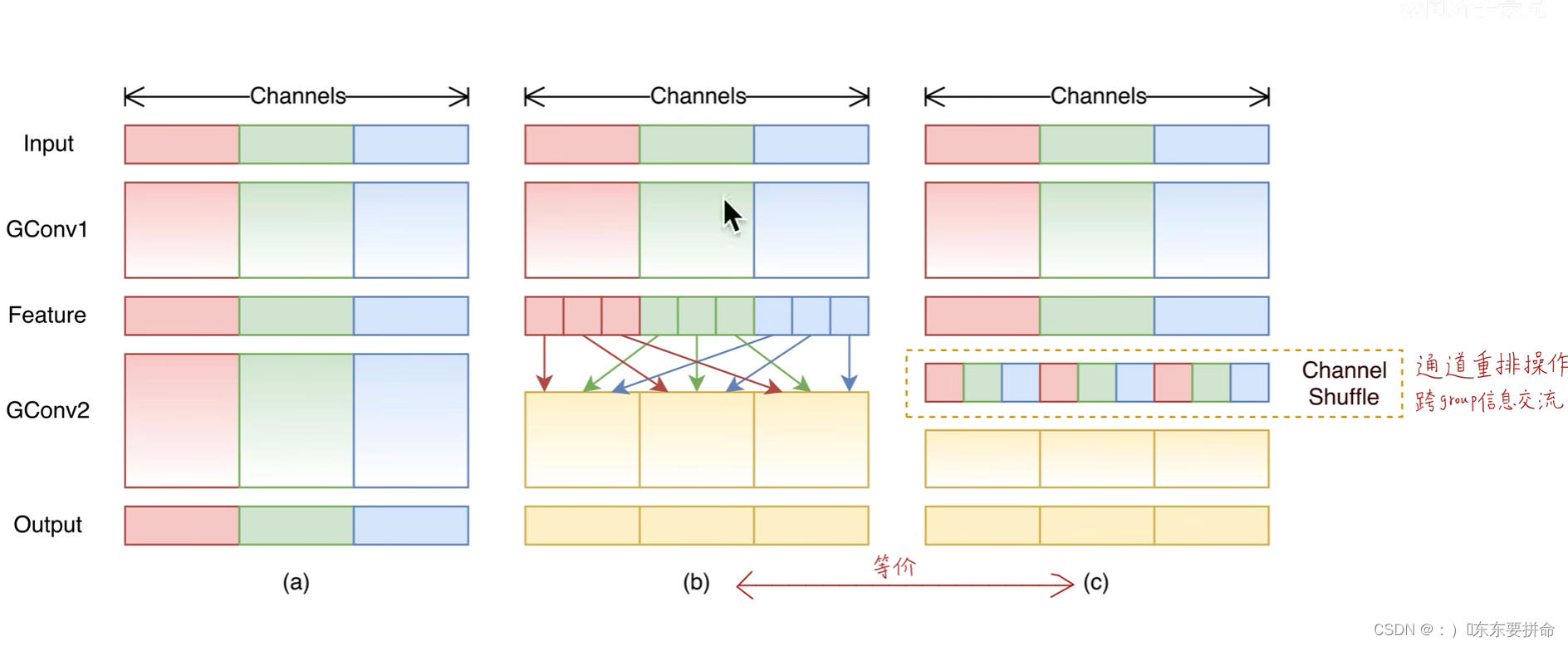
b c 为同一个图 的不同表现形式
从原来的近亲繁殖 变成混血 把不同的基因混合起来
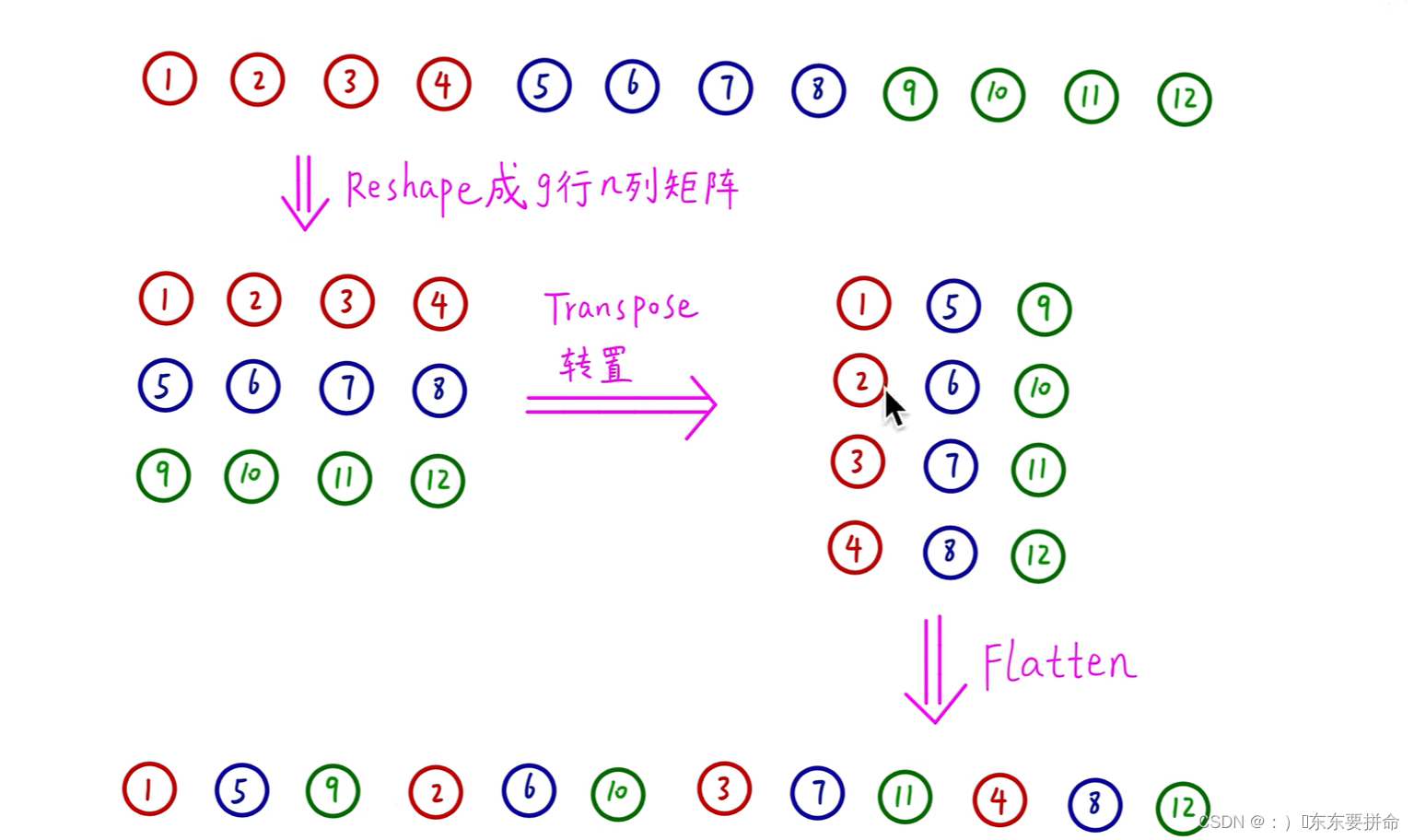
这是通道重排的过程
可以通过pytorch的api实现
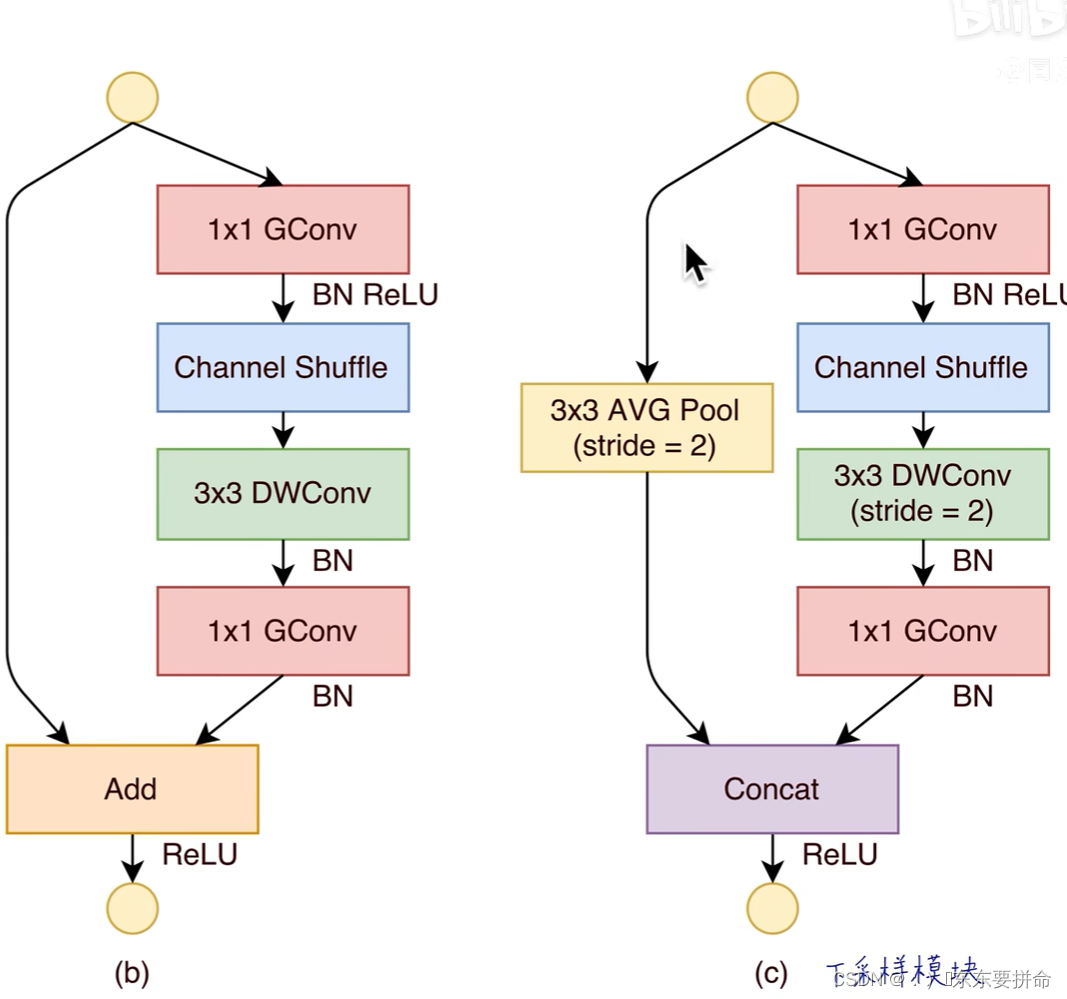
一乘以一卷积降维升维
、
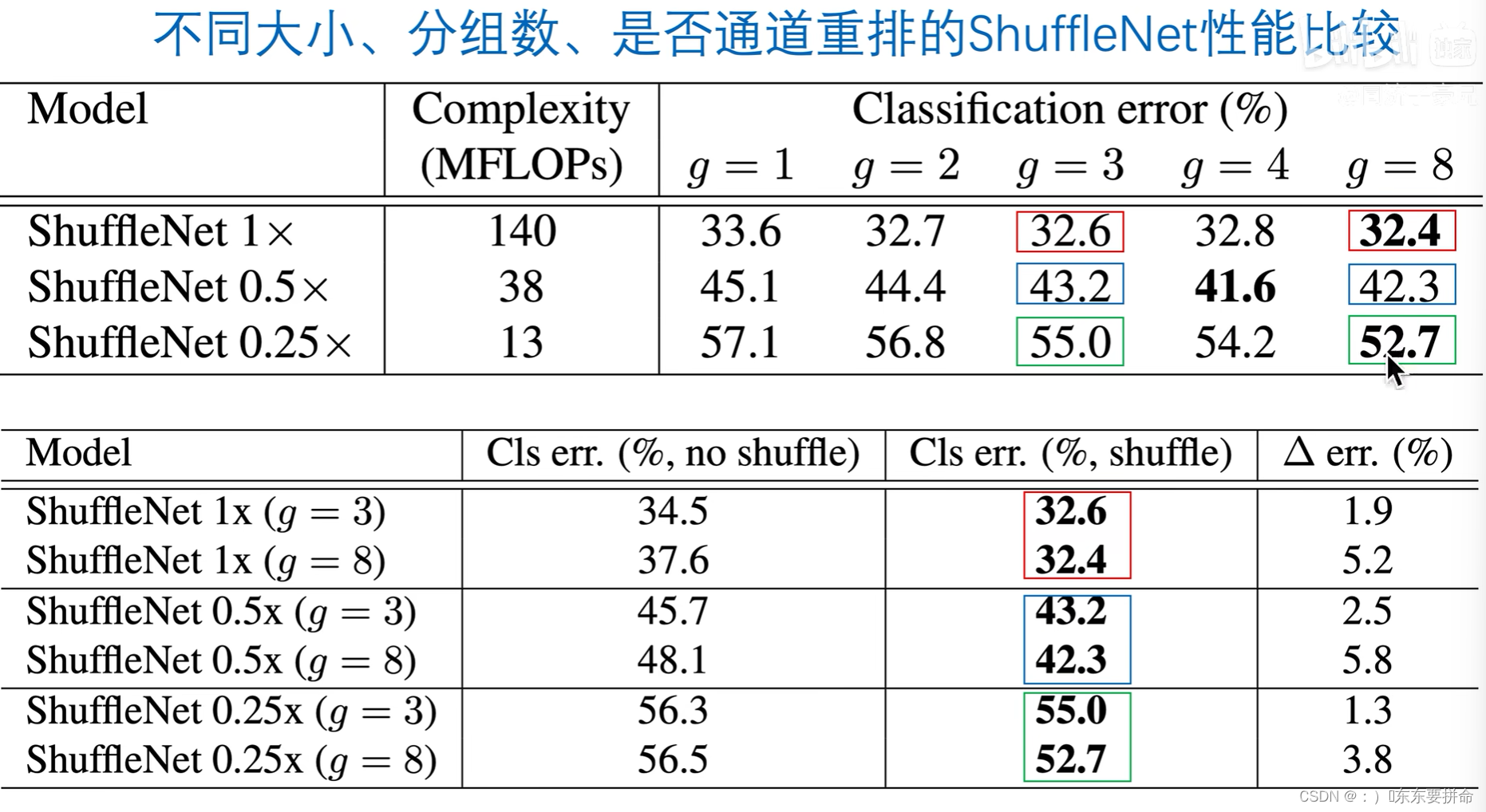
我们发现啊
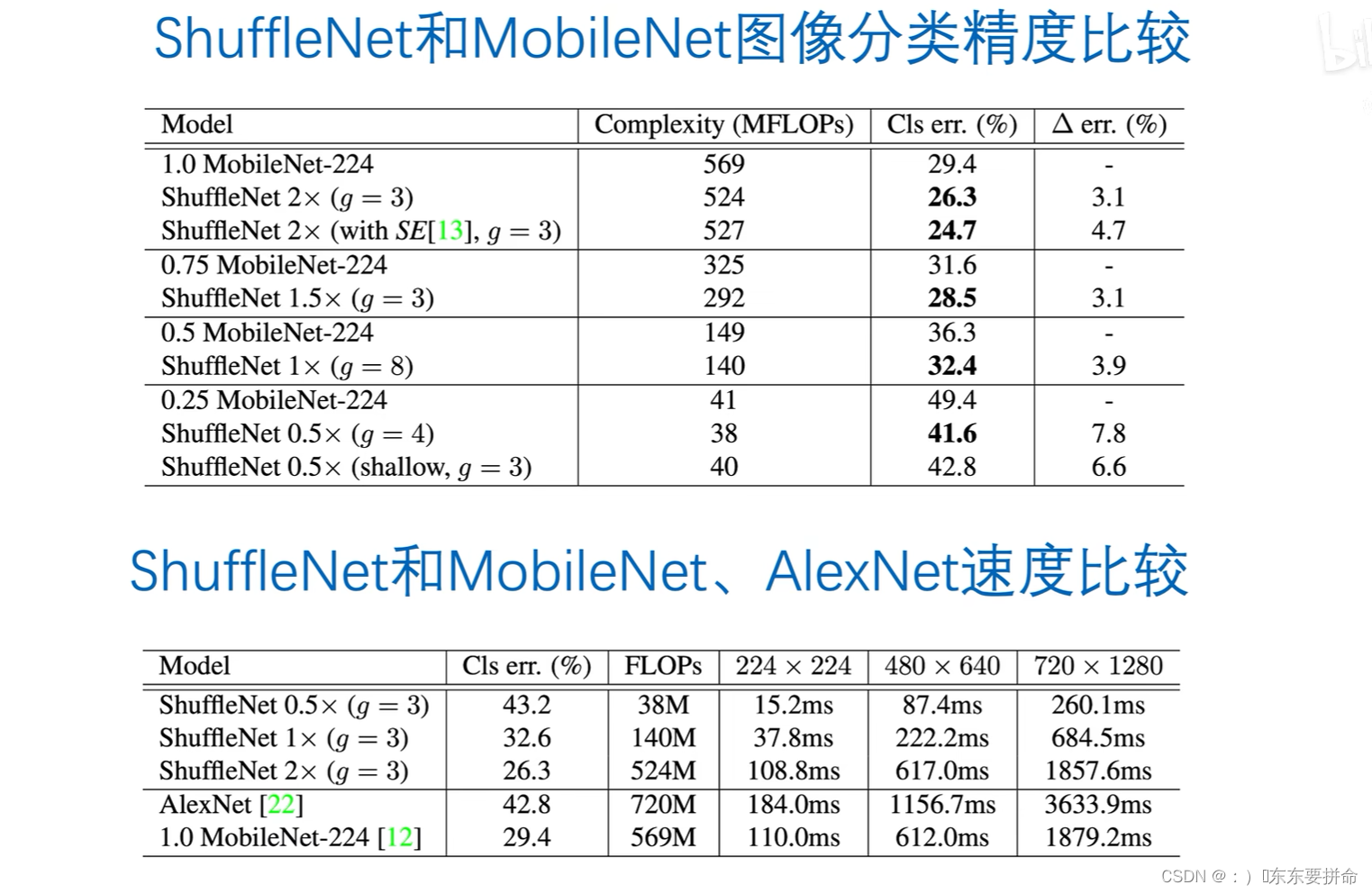
当分的组越多 错误率越低 代表着分类的性能越好
而且对于小模型而言,分组卷积数越大,性能提升越明显
分组卷积变多之后,她的通道数可以加多,保证算力不变的情况下,可以显著提升小网络的表示性能
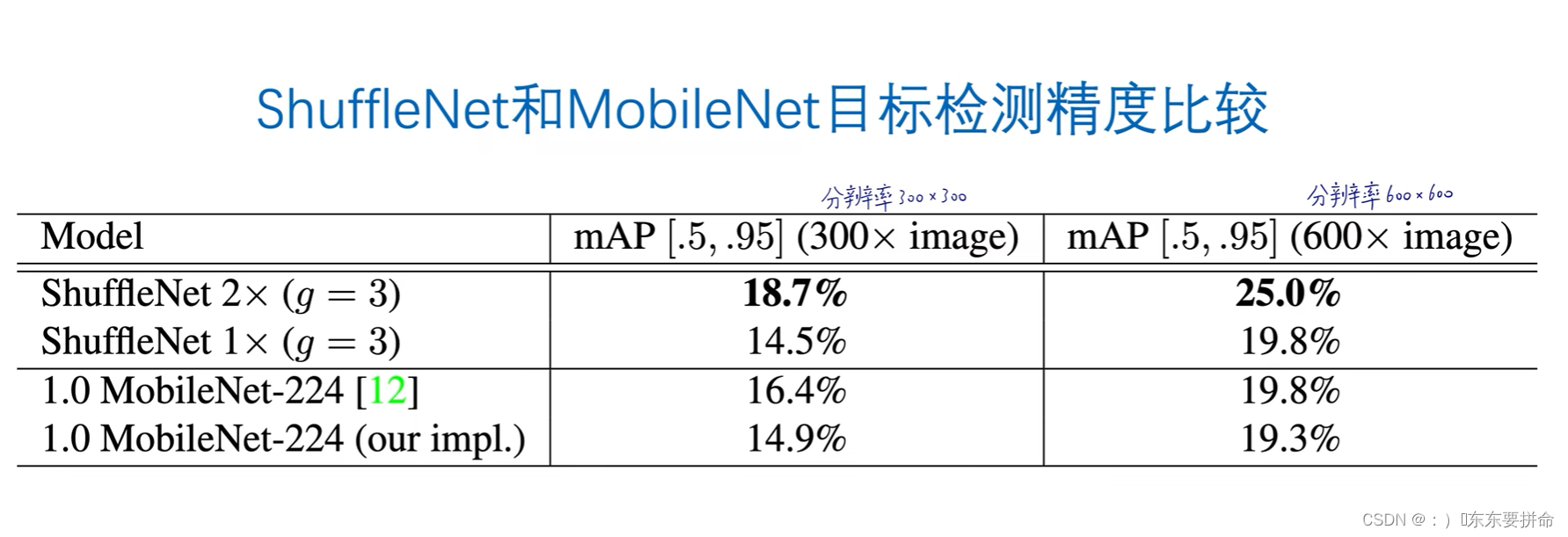
而且从第二个表可以看出 这个通道重排也有效果提升 shuffle还是work的
越是对于0.5*网络而言,shuffle的提升越明显
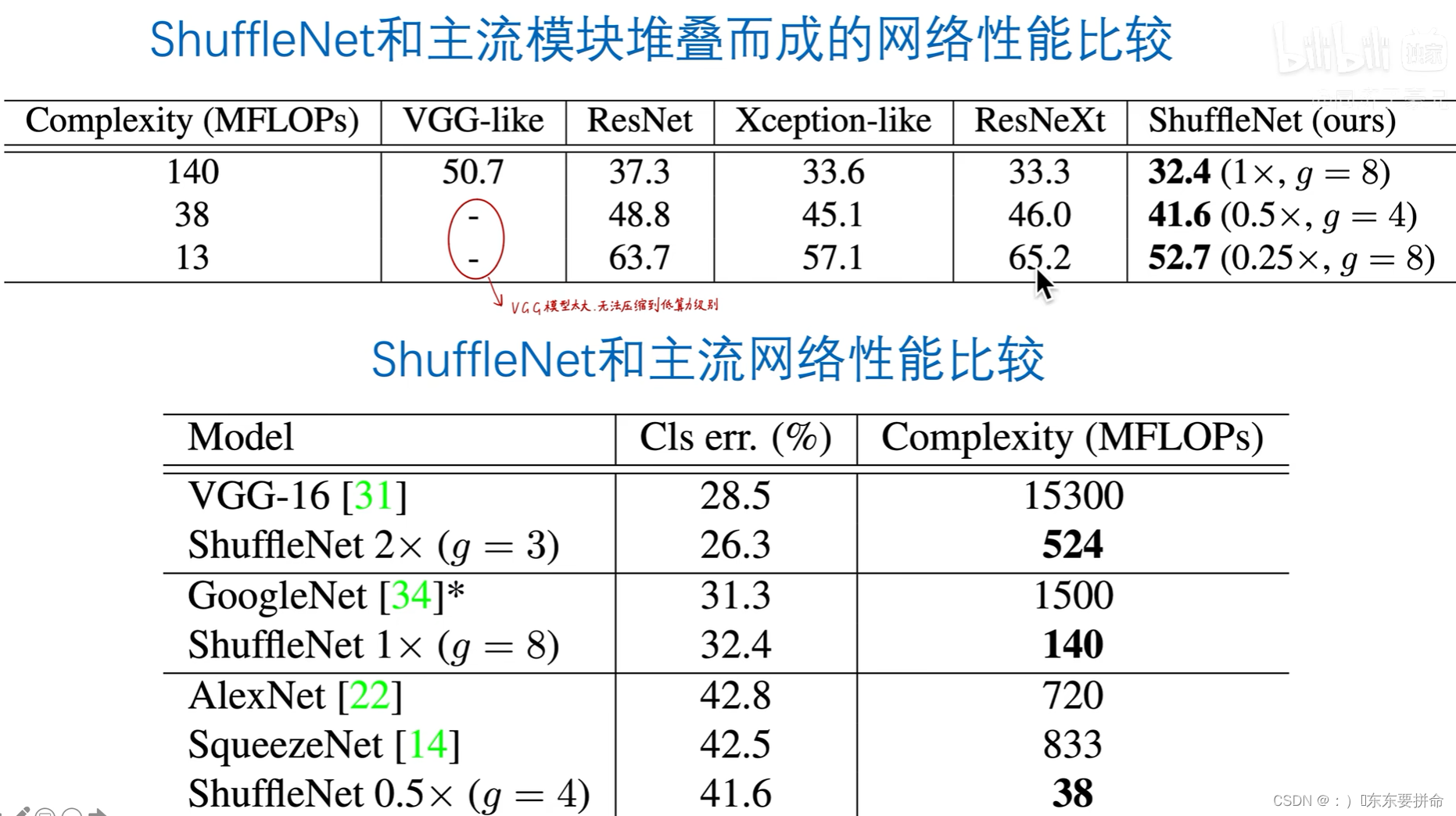
不同的算力消耗级别
学习笔记摘录自 同济子豪兄
![Max Sum Plus Plus(DP 滚动数组优化)[HDU - 1024]](https://img-blog.csdnimg.cn/9f3bba65e932424a9a52920f2534388c.png)