论文标题: Boosting Novel Category Discovery Over Domains with Soft Contrastive Learning and All in One Classifier
论文链接:https://openaccess.thecvf.com/content/ICCV2023/html/Zang_Boosting_Novel_Category_Discovery_Over_Domains_with_Soft_Contrastive_Learning_ICCV_2023_paper.html
代码:暂未开源
引用:Zang Z, Shang L, Yang S, et al. Boosting Novel Category Discovery Over Domains with Soft Contrastive Learning and All in One Classifier[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 11858-11867.
作者解读:https://zhuanlan.zhihu.com/p/660101925

导读
在无监督域自适应(UDA)中,将知识从标签丰富的源域传输到标签稀缺的目标域已经取得了显著的成果。然而,目标域中可能存在额外的新类别,这促使了开放域适应(ODA)和通用域适应(UNDA)的研究。传统的ODA和UNDA方法将所有新类别视为一个统一的未知类别,并试图在训练过程中检测它们。然而,我们发现域差异会导致无监督数据增强中更显著的视图噪声,这会影响对比学习(CL)的有效性,并使模型对新类别的发现过于自信。
为了解决这些问题,本文提出了一种名为"Soft-contrastive All-in-one Network(SAN)"的框架,用于ODA和UNDA任务。SAN包括一种新颖的基于数据增强的软对比学习(SCL)损失,用于微调骨干网络以进行特征传输,还包括一个更具人类直觉的分类器,以提高新类别的发现能力。
SCL损失减弱了数据增强视图噪声问题的不利影响,这一问题在域迁移任务中被放大。全能分类器(All-in-One,AIO)克服了当前主流的封闭集和开放集分类器的过度自信问题。可视化和消融实验证明了所提创新的有效性。此外,在ODA和UNDA的广泛实验结果显示,SAN优于现有的最先进方法。
本文贡献
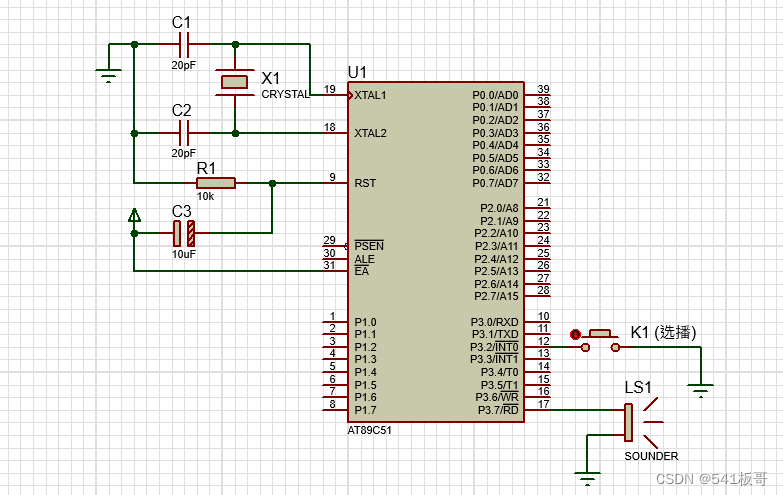
ODA 和 UNDA 任务的两个主要目标是特征迁移和新的类别发现。然而,目前的方法在实现这两个目标方面都有局限性,这阻碍了这些任务的进一步改进。具体问题如图1所示

数据增强过程中的视图-噪声问题影响了特征的传递:图1 (a)-top显示了由跨三个不同域的相同数据增强方案生成的视图。内容风格上的差异导致常规的数据增强产生具有极大不同语义的视图,从而产生噪声对。
分类器(闭集分类器和开集分类器)的过置信问题影响了新的类别识别性能:图1 (b) 新类别分类器的过度自信问题。带有标记/交叉的虚线圈表示测试样本的分类正确。
为了解决上述挑战,我们为UNDA和ODA提出了 Soft-contrastive All-in-one Network(SAN):
针对视图噪声问题,我们引入了一种软对比学习(SCL)损失。与通常使用的对比学习(CL)损失不同,我们的SCL损失考虑了潜在空间中视图的相似性,以评估视图的可靠性。这使我们能够通过融合可靠性来构建更有效的损失函数。在图1(a)中,我们比较了我们的SCL损失与CL损失在处理噪声数据对方面的表现,并证明我们的SCL损失有效减小了噪声数据对对模型的影响。
对于独立分类器的过度自信问题,我们设计了一种全能分类器(AIO),以取代封闭集分类器和开放集分类器。AIO分类器的决策过程更接近于人类的决策方式。AIO分类器假定要识别属于新类别的样本需要确定它不属于任何已知类别。基于这一假设,定义了一个新的损失函数来训练AIO分类器。如图1(b3)和(b4)所示,结果是AIO分类器具有更平滑的分类边界,并通过引入更全面的竞争来减小标签噪声的不良影响。
在实验中,我们在ODA和UNDA基准上广泛评估了我们的方法,并改变未知类别的比例。结果显示,所提出的SAN在ODA和UNDA任务的各种数据集上优于所有基准方法。
本文方法

SAN 框架:该方法包括一个主干网络F(·)、一个投影头网络H(·)和一个 All-in-One 分类器C(·)。骨干网络F(·)和投影头网络H(·)将源域数据xs和目标域数据xt映射到潜在空间中。
符号表示
源域数据集:

目标域数据集:

源和目标的标签空间:

类条件随机噪声模型:


目标:用 Ls 标签或“未知”标签来标记目标样本。我们在Ds∪Dt上训练模型,并在Dt上进行评估。
视觉噪声和软对比性学习损失
基于数据增强的对比学习(CL)涉及对样本对的二元分类。对比学习通过最大化正样本之间的相似性和最小化负样本之间的相似性来学习表示:

典型的对比学习(CL)损失假定有一个正样本和多个负样本。为了设计一个更平滑的CL损失版本,我们将其转换为基于正和负样本标签Hij的形式。

如果Hij = 1,则表示(xi,xj)是一个正对,如果Hij = 0,则表示(xi,xj)是一个负对
一般来说,都是通过随机数据增强得到的正对,这意味着学习过程不可避免地会引入视图噪声。因此,视图噪声引入了错误的梯度,从而破坏了网络的训练。此外,对于显示出巨大域方差的UNDA数据来说,为所有域找到合适的数据增强方案是一个挑战。这种视图-噪声问题限制了在UNDA中使用基于数据增强的CL方法。
为了解决上述的视图噪声问题,我们提出了软对比学习(SCL)。SCL通过对不同的正负样本分配不同的权值来衰减不正确样本的负面影响,这些样本通过其自己的主干网络计算相似度来估计。SCL的损失函数如下:

其中,

其中,超参数 α∈[0,1] 将数据增强关系Hij的先验知识引入到模型训练中。为了将高维嵌入向量(如(yi、yj))映射到一个概率值,我们使用了一个核函数κ(·)。可以使用常用的核函数。
在本文中,我们使用t-分布核函数κν(·),因为它暴露了自由度,并允许我们在降维映射[18,40]中调整分布的接近性。t分布核函数的定义如下:

SCL 损失使用了一个软性优化目标,而不是一个典型的CL损失的硬性目标,同时避免了对噪声标签的强烈错误响应。
过度自信和 AIO 分类器
分类器过度自信问题:

来源:https://zhuanlan.zhihu.com/p/660101925
为了解决上述问题,我们将其原因归因于单个开放集分类器的竞争不足。具体来说,每个开放集分类器只完成二进制分类,而忽略了观察更多样化的标签。因此,在简单的学习任务的指导下,分类器过度拟合并产生异常尖锐的分类边界。另一个重要的原因是,开放集分类器在识别新的类时只考虑一个已知的类与人类的常识是不一致的。人类需要判断新类是否属于已知的类,然后再将它们识别为新类。为此,本文提出了一个AIO分类器来代替封闭集分类器和开放集分类器。AIO分类器为每个已知类别分配两个输出神经元,分别表示样本是否属于该特定类别。


(a) 如果分类器将样本 xi 分配给已知类别 ys,那么它需要确保样本既不属于其他已知类别,即


(b) 如果分类器将样本xi分配给一个未知类,则需要确认该样本不属于所有已知类,即

因此,接下来,我们将这两个原则结合起来,以实现以下目标。对于源域的一个示例:

基于等式 (7),我们将损失函数表示为:

我们结合SCL损失和AIO损失来训练SAN。总体损失为:

实验
实验结果
在四个数据集达到SOTA性能:




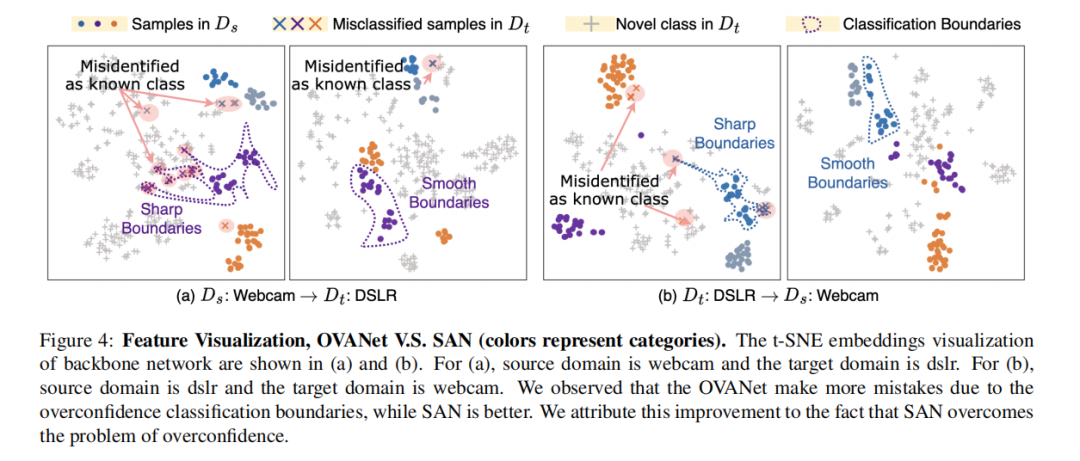
特征可视化:
消融实验


结论
ODA和UNDA任务的目标是将从标签丰富的源域学习到的知识转移到标签稀缺的目标域,而对标签空间没有任何限制。本文为了解决基于数据增强的CL的视图噪声问题和新的类别分类器的过置信问题,提出了一种软对比一体化网络(SAN)框架。SAN包括SCL损失,它可以避免典型的CL损失的过度响应,并使基于数据增强的对比损失成为可能,从而提高ODA和UNDA的性能。此外,SAN还包括一个全能分类器,以提高新的类别发现的鲁棒性。在UNDA和ODA上的大量实验结果表明了SAN相对于现有方法的优势。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓