实体框架中的 BulkInsert 扩展方法
安装 Z.EntityFramework.Extensions:
现在,我将向您展示如何使用 Z.EntityFramework.Extensions 包,以及如何通过 Entity Framework 执行批量插入、更新和删除操作。首先,打开“NuGet 包管理器控制台”窗口并搜索 Z.EntityFramework.Extensions 包。选择“Z.EntityFramework.Extensions”,然后选择“项目”并选择最新版本,最后单击“安装”按钮,如下图所示。
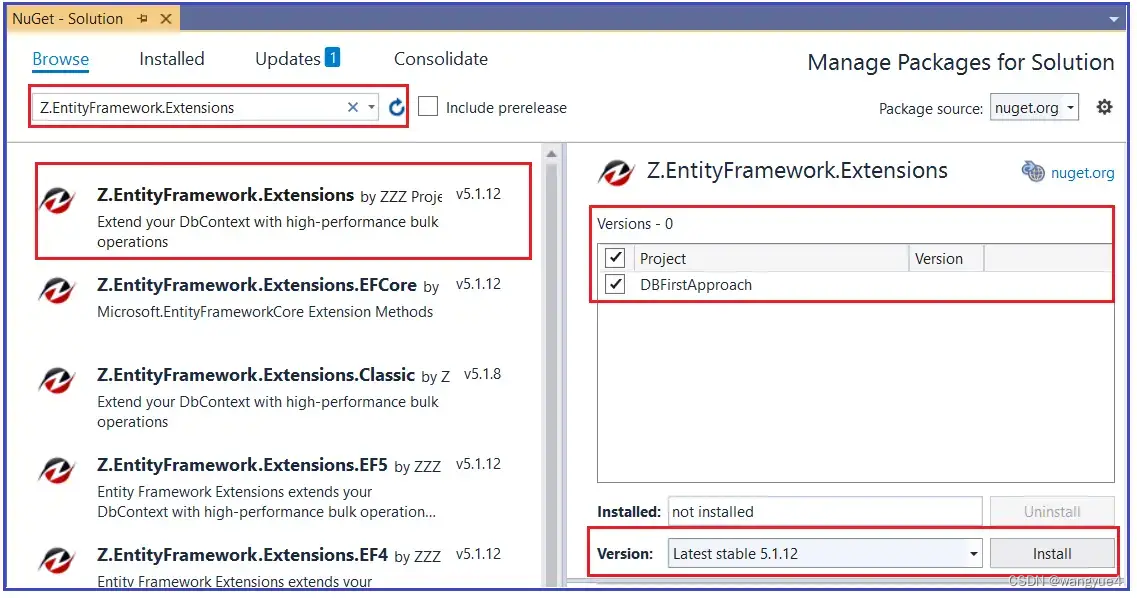
单击“安装”按钮后,将需要一些时间并将 Z.EntityFramework.Extensions DLL 安装到您的项目中。
注意:此 Z.EntityFramework.Extensions 使用高性能批量操作(如 BulkSaveChanges、BulkInsert、BulkUpdate、BulkDelete、BulkMerge 等)扩展了我们的 DbContext 对象。它支持 SQL Server、MySQL、Oracle、PostgreSQL、SQLite 等!
使用实体框架扩展的优点:
- 易于使用。
- 灵活。
- 提高性能。
- 提高应用程序响应能力。
- 通过减少数据库往返次数来减少数据库负载。
BulkInsert 扩展方法:
Z.EntityFramework.Extensions 提供了两种方法,即 BulkInsert 和 BulkInsertAync,它们允许我们一次性将大量实体插入数据库。使用批量插入扩展方法的语法如下:
context.BulkInsert(listStudents);
context.BulkInsertAsync(listStudents, cancellationToken);
了解使用实体框架扩展的 BulkInsert 方法的示例
在下面的示例中,我们将使用 BulkInsert 扩展方法将学生列表(即 newStudents)插入数据库。在这里,我们不需要在执行大容量插入操作时调用 SaveChanges 方法。在本例中,使用单次往返,上下文类将执行 INSERT 操作。
using System;
using System.Collections.Generic;
using System.Linq;
namespace DBFirstApproach
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("BulkInsert Method Started");
IList<Student> newStudents = new List<Student>() {
new Student() { FirstName = "John", LastName = "Taylor", StandardId = 1 },
new Student() { FirstName = "Sara", LastName = "Taylor", StandardId = 1 },
new Student() { FirstName = "Pam", LastName= "Taylor", StandardId = 1 },
};
using (var context = new EF_Demo_DBEntities())
{
context.Database.Log = Console.Write;
// Easy to use
context.BulkInsert(newStudents);
}
Console.WriteLine("BulkInsert Method Completed");
GetStudents("Taylor");
Console.Read();
}
public static void GetStudents(string LastName)
{
using (var context = new EF_Demo_DBEntities())
{
var studentsList = context.Students.Where(std => std.LastName.Equals(LastName, StringComparison.InvariantCultureIgnoreCase));
foreach (var std in studentsList)
{
Console.WriteLine($"FirstName : {std.FirstName}, LastName : {std.LastName}, StandardId : {std.StandardId}");
}
}
}
}
}运行上述代码时,将获得以下输出。请仔细观察 SQL 查询,您将看到它正在使用 SQL Merge 来执行 BULK 操作。由于它减少了与数据库服务器的往返次数,因此大大提高了应用程序性能。
BulkInsert Method Started
Opened connection at 12-12-2022 19:45:45 +05:30
-- Executing Command:
/* SELECT server information */
SELECT @@VERSION
/* SELECT table information */
SELECT DestinationTable.Name AS DestinationName ,
( SELECT 1
WHERE EXISTS ( SELECT 1
FROM sys.triggers AS X
WHERE X.parent_id = A.object_id
AND X.is_disabled = 0
AND OBJECTPROPERTY(X.object_id,
'ExecIsInsertTrigger') = 1 )
) AS HasInsertTrigger ,
( SELECT 1
WHERE EXISTS ( SELECT 1
FROM sys.triggers AS X
WHERE X.parent_id = A.object_id
AND X.is_disabled = 0
AND OBJECTPROPERTY(X.object_id,
'ExecIsUpdateTrigger') = 1 )
) AS HasUpdateTrigger ,
( SELECT 1
WHERE EXISTS ( SELECT 1
FROM sys.triggers AS X
WHERE X.parent_id = A.object_id
AND X.is_disabled = 0
AND OBJECTPROPERTY(X.object_id,
'ExecIsDeleteTrigger') = 1 )
) AS HasDeleteTrigger
FROM (SELECT @Table_0 AS Name) AS DestinationTable
LEFT JOIN sys.synonyms AS B ON B.object_id = OBJECT_ID(DestinationTable.Name)
AND COALESCE(PARSENAME(base_object_name,4), @@SERVERNAME) = @@SERVERNAME
AND COALESCE(PARSENAME(base_object_name,3), DB_NAME(DB_ID())) = DB_NAME(DB_ID())
INNER JOIN sys.tables AS A ON A.object_id = OBJECT_ID(DestinationTable.Name)
OR A.object_id = OBJECT_ID(B.base_object_name)
ORDER BY DestinationName
/* SELECT column information */
SELECT DestinationTable.Name AS DestinationName ,
C.name AS ColumnName ,
C.column_id AS ColumnOrder ,
C.precision AS Precision ,
C.scale AS Scale ,
C.max_length AS MaxLength ,
C.collation_name AS Collation ,
C.Is_Identity AS IsIdentity ,
( CASE WHEN EXISTS ( SELECT 1
FROM sys.index_columns AS X
WHERE X.index_id = B.index_id
AND X.object_id = B.object_id
AND X.column_id = C.column_id ) THEN 1
ELSE 0
END ) AS IsPrimaryKey ,
C.system_type_id AS System_Type_Id ,
D.Name AS TypeName,
(CASE WHEN E.base_object_name IS NOT NULL THEN 1 ELSE 0 END) AS IsSynonym,
D.is_user_defined,
F.name,
CASE WHEN C.default_object_id = 0 THEN 'ZZZ_NO_DEFAULT' ELSE ISNULL(OBJECT_DEFINITION(C.default_object_id), 'ZZZ_ERROR_DEFAULT_ZZZ') END AS DefaultValueSql,
C.is_nullable
FROM (SELECT @Table_0 AS Name) AS DestinationTable
LEFT JOIN sys.synonyms AS E ON E.object_id = OBJECT_ID(DestinationTable.Name)
AND COALESCE(PARSENAME(base_object_name,4), @@SERVERNAME) = @@SERVERNAME
AND COALESCE(PARSENAME(base_object_name,3), DB_NAME(DB_ID())) = DB_NAME(DB_ID())
INNER JOIN sys.tables AS A ON A.object_id = OBJECT_ID(DestinationTable.Name)
OR A.object_id = OBJECT_ID(E.base_object_name)
LEFT JOIN sys.indexes AS B ON B.object_id = A.object_id
AND B.is_primary_key = 1
INNER JOIN sys.columns AS C ON C.object_id = A.object_id
INNER JOIN sys.types AS D ON D.system_type_id = C.system_type_id
AND D.user_type_id = C.user_type_id
INNER JOIN sys.schemas AS F ON D.schema_id = F.schema_id
ORDER BY DestinationName ,
ColumnOrder
-- @Table_0: [dbo].[Student] (Type = String, Size = 15)
-- CommandTimeout:30
-- Executing at 12-12-2022 19:45:45
-- Completed at 12-12-2022 19:45:45
-- Result: SqlDataReader
-- Executing Command:
MERGE INTO [dbo].[Student] AS DestinationTable
USING
(
SELECT TOP 100 PERCENT * FROM (SELECT @0_0 AS [StudentId], @0_1 AS [FirstName], @0_2 AS [LastName], @0_3 AS [StandardId], @0_4 AS ZZZ_Index
UNION ALL SELECT @1_0 AS [StudentId], @1_1 AS [FirstName], @1_2 AS [LastName], @1_3 AS [StandardId], @1_4 AS ZZZ_Index
UNION ALL SELECT @2_0 AS [StudentId], @2_1 AS [FirstName], @2_2 AS [LastName], @2_3 AS [StandardId], @2_4 AS ZZZ_Index) AS StagingTable ORDER BY ZZZ_Index
) AS StagingTable
ON 1 = 2
WHEN NOT MATCHED THEN
INSERT ( [FirstName], [LastName], [StandardId] )
VALUES ( [FirstName], [LastName], [StandardId] )
OUTPUT
$action,
StagingTable.ZZZ_Index,
INSERTED.[StudentId] AS [StudentId_zzzinserted]
;
-- @0_0: 0 (Type = Int32, Size = 4)
-- @0_1: John (Type = AnsiString, Size = 100)
-- @0_2: Taylor (Type = AnsiString, Size = 100)
-- @0_3: 1 (Type = Int32, Size = 4)
-- @0_4: 0 (Type = Int32, Size = 0)
-- @1_0: 0 (Type = Int32, Size = 4)
-- @1_1: Sara (Type = AnsiString, Size = 100)
-- @1_2: Taylor (Type = AnsiString, Size = 100)
-- @1_3: 1 (Type = Int32, Size = 4)
-- @1_4: 1 (Type = Int32, Size = 0)
-- @2_0: 0 (Type = Int32, Size = 4)
-- @2_1: Pam (Type = AnsiString, Size = 100)
-- @2_2: Taylor (Type = AnsiString, Size = 100)
-- @2_3: 1 (Type = Int32, Size = 4)
-- @2_4: 2 (Type = Int32, Size = 0)
-- CommandTimeout:120
-- Executing at 12-12-2022 19:45:45
-- Completed at 12-12-2022 19:45:46
-- Result: 3 rows
Closed connection at 12-12-2022 19:45:46 +05:30
BulkInsert Method Completed
FirstName : John, LastName : Taylor, StandardId : 1
FirstName : Sara, LastName : Taylor, StandardId : 1
FirstName : Pam, LastName : Taylor, StandardId : 1Entity Framework 中 SaveChanges 和 BulkInsert 的性能比较:
让我们通过一个示例来查看 Entity Framework SaveChanges 方法和 BulkInsert 扩展方法之间的性能基准。众所周知,Entity Framework SaveChanges 方法将为每个实体生成并执行单独的 SQL 查询,即多个数据库行程,而 BulkInsert 扩展方法使用单个数据库行程执行相同的任务。
我们将使用两种方法(即 AddRange 方法和 BulkInsert 扩展方法)批量插入 1000 名学生,并将测量两种方法完成任务所需的时间。为了更好地理解,请看以下示例。在下面的示例中,不要考虑使用FirstTimeExecution方法进行性能测试,因为我们知道,当我们第一次执行某些操作时,将花费更多时间。
using System;
using System.Collections.Generic;
using System.Diagnostics;
namespace DBFirstApproach
{
class Program
{
static void Main(string[] args)
{
//Don't consider below for performance Testing
//This warmup
FirstTimeExecution();
// Generate 1000 Students
List<Student> studentList = GenerateStudents(1000);
Stopwatch SaveChangesStopwatch = new Stopwatch();
Stopwatch BulkInsertStopwatch = new Stopwatch();
using (EF_Demo_DBEntities context1 = new EF_Demo_DBEntities())
{
// Add the Student Collection using the AddRange Method
context1.Students.AddRange(studentList);
SaveChangesStopwatch.Start();
context1.SaveChanges();
SaveChangesStopwatch.Stop();
Console.WriteLine($"SaveChanges, Entities : {studentList.Count}, Time Taken : {SaveChangesStopwatch.ElapsedMilliseconds} MS");
}
using (EF_Demo_DBEntities context2 = new EF_Demo_DBEntities())
{
// BulkInsert
BulkInsertStopwatch.Start();
context2.BulkInsert(studentList, options => options.AutoMapOutputDirection = false); // performance can be improved with options
BulkInsertStopwatch.Stop();
Console.WriteLine($"BulkInsert, Entities : {studentList.Count}, Time Taken : {BulkInsertStopwatch.ElapsedMilliseconds} MS");
}
Console.Read();
}
public static void FirstTimeExecution()
{
List<Student> stduentsList = GenerateStudents(20);
// SaveChanges
using (var context = new EF_Demo_DBEntities())
{
context.Students.AddRange(stduentsList);
//Call the SaveChanges Method to INSERT the data into the database
context.SaveChanges();
// Delete the Newly Inserted Data
context.BulkDelete(stduentsList);
}
// BulkInsert
using (var context = new EF_Demo_DBEntities())
{
context.BulkInsert(stduentsList, options => options.AutoMapOutputDirection = false);
// Delete the Newly Inserted Data
context.BulkDelete(stduentsList);
}
}
public static List<Student> GenerateStudents(int count)
{
var listOfStudents = new List<Student>();
for (int i = 0; i < count; i++)
{
listOfStudents.Add(new Student() { FirstName = "FirstName_" + i, LastName = "LastName_" + i, StandardId = 1 });
}
return listOfStudents;
}
}
}现在,运行上面的代码,你将获得以下输出。如您所见,SaveChanges 方法将 1000 个实体插入数据库需要 490 毫秒,而 BulkInsert Extension 方法只需 20 毫秒即可将相同的 1000 个实体插入数据库。因此,可以想象,当考虑性能时,实体框架 AddRange 方法有多危险。
![]()
注意: 需要考虑许多影响基准时间的因素,例如索引、列类型、延迟、限制等。
为什么 BulkInsert 扩展方法比 SaveChanges 更快?
插入 1000 个实体进行初始加载或文件导入是典型的方案。由于需要往返的数据库数量,SaveChanges 方法使处理这种情况变得非常缓慢/不可能。SaveChanges 对要插入的每个实体执行一次数据库往返。因此,如果需要插入 10,000 个实体,将执行 10,000 次数据库往返,这会使其变慢。
对应项中的 BulkInsert 需要尽可能少的数据库往返次数。例如,在 SQL Server 的后台,执行 SqlBulkCopy 以插入 10,000 个实体,这是最快的可用方法。