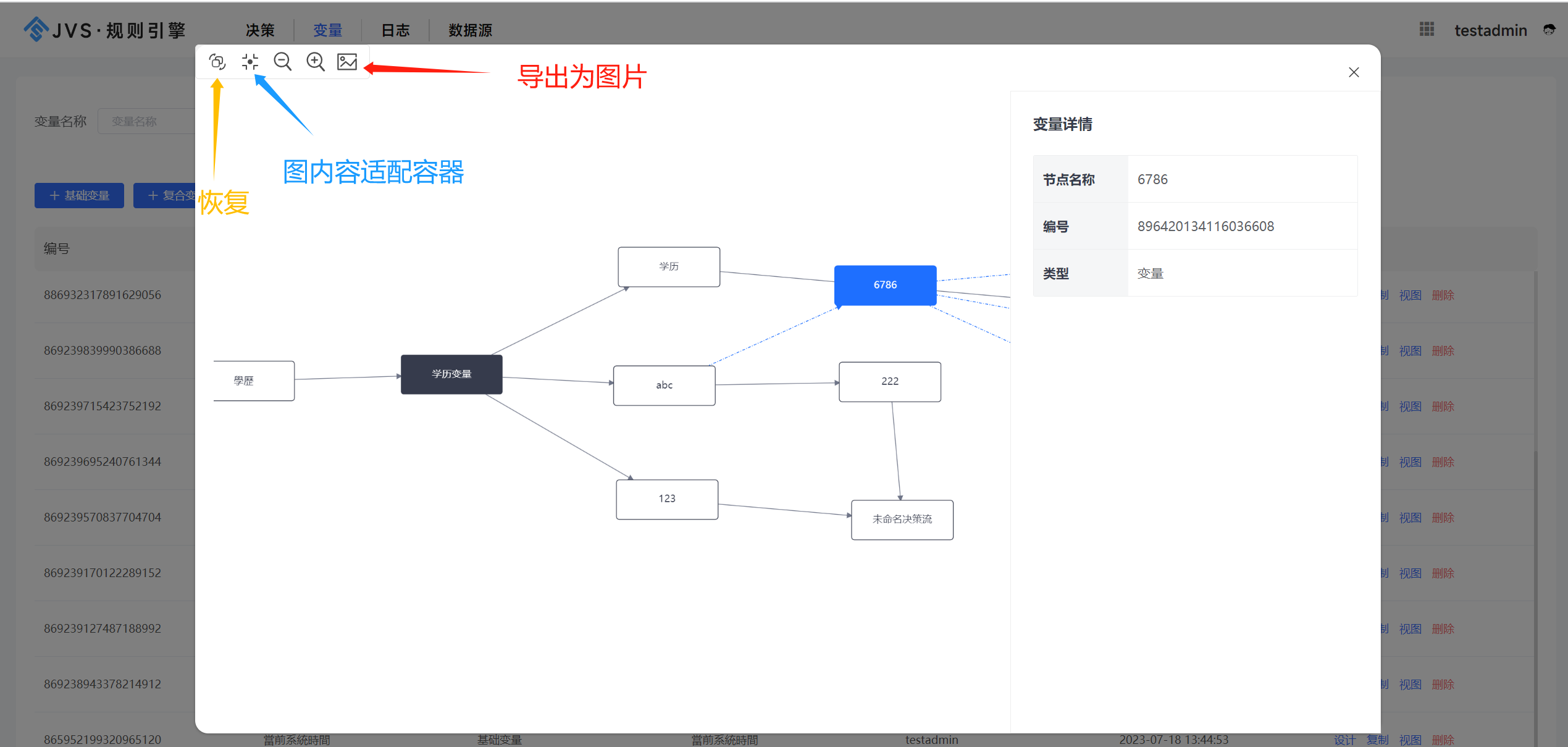
编译乱序
现代的高性能编译器在目标码优化上都具备对指令进行乱序优化的能力。编译器可以对访存的指令进行乱序,减少逻辑上不必要的访存,以及尽量提高Cache命中率和CPU的Load/Store单元的工作效率。
因此在打开编译器优化以后,看到生成的汇编码并没有严格按照代码的逻辑顺序,这是正常的。
解决办法
解决编译乱序问题,需要通过barrier()编译屏障进行。我们可以在代码中设置barrier()屏障,这个屏障可以阻挡编译器的优化。对于编译器来说,设置编译屏障可以保证屏障前的语句和屏障后的语句不乱“串门”。
如__asm____volatile__
volatile
C语言volatile关键字的作用较弱,它更多的只是避免内存访问行为的合并,对C编译器而言,volatile是暗示除了当前的执行线索以外,其他的执行线索也可能改变某内存,所以它的含义是“易变的”。
如果线程A读取var这个内存中的变量两次而没有修改var,编译器可能觉得读一次就行了,第2次直接取第1次的结果。但是如果加了volatile关键字来形容var,则就是告诉编译器线程B、线程C或者其他执行实体可能把var改掉了,因此编译器就不会再把线程A代码的第2次内存读取优化掉了。
另外,volatile也不具备保护临界资源的作用。
总之,Linux内核明显不太喜欢volatile,
执行乱序(后面的执行到前面)
执行乱序则是处理器运行时的行为。这是处理器的“乱序执行(Out-of-Order Execution)”策略。高级的CPU可以根据自己缓存的组织特性,将访存指令重新排序执行。连续地址的访问可能会先执行,因为这样缓存命中率高。有的还允许访存的非阻塞,即如果前面一条访存指令因为缓存不命中,造成长延时的存储访问时,后面的访存指令可以先执行,以便从缓存中取数。因此,即使是从汇编上看顺序正确的指令,其执行的顺序也是不可预知的。
SMP上的乱序执行
对于大多数体系结构而言,尽管每个CPU都是乱序执行,但是这一乱序对于单核的程序执行是不可见的,因为单个CPU在碰到依赖点(后面的指令依赖于前面指令的执行结果)的时候会等待,所以程序员可能感觉不到这个乱序过程。
但是这个依赖点等待的过程,在SMP处理器里面对于其他核是不可见的。比如若在CPU0上执行:

我们不能武断地认为CPU0上打印的x一定等于42,因为CPU1上即便“f=1”编译在“x=42”后面,执行时仍然可能先于“x=42”完成,所以这个时候CPU0上打印的x不一定就是42。
解决办法
处理器为了解决多核间一个核的内存行为对另外一个核可见的问题,引入了一些内存屏障的指令。譬如,ARM处理器的屏障指令包括:
- DMB(数据内存屏障):在DMB之后的显式内存访问执行前,保证所有在DMB指令之前的内存访问完成;
- DSB(数据同步屏障):等待所有在DSB指令之前的指令完成(位于此指令前的所有显式内存访问均完成,位于此指令前的所有缓存、跳转预测和TLB维护操作全部完成);
- ISB(指令同步屏障):Flush流水线,使得所有ISB之后执行的指令都是从缓存或内存中获得的。
Linux内核的自旋锁、互斥体等互斥逻辑,需要用到上述指令:在请求获得锁时,调用屏障指令;在解锁时,也需要调用屏障指令。
用处
前面提到每个CPU都是乱序执行,但是单个CPU在碰到依赖点的时候会等待,所以执行乱序对单核不一定可见。但是,当程序在访问外设的寄存器时,这些寄存器的访问顺序在CPU的逻辑上构不成依赖关系,但是从外设的逻辑角度来讲,可能需要固定的寄存器读写顺序,这个时候,也需要使用CPU的内存屏障指令。内核文档Documentation/memory-barriers.txt和Documentation/io_ordering.txt对此进行了描述。
Linux内核的自旋锁、互斥体等互斥逻辑,需要用到上述指令:在请求获得锁时,调用屏障指令;在解锁时,也需要调用屏障指令。
各种内存屏蔽指令
在Linux内核中,定义了读写屏障mb()、读屏障rmb()、写屏障wmb()、以及作用于寄存器读写的__iormb()、__iowmb()这样的屏障API。读写寄存器的readl_relaxed()和readl()、writel_relaxed()和writel()API的区别就体现在有无屏障方面。