前言
其实由来很简单,我们用了一个第三方的开源平台,这个平台基于 ruoyi 3.8.1 开发,我想后续同步到ruoyi的最新版
今天看的是 一个字典查询的commit,我们下来看下这次提交是如何优化的
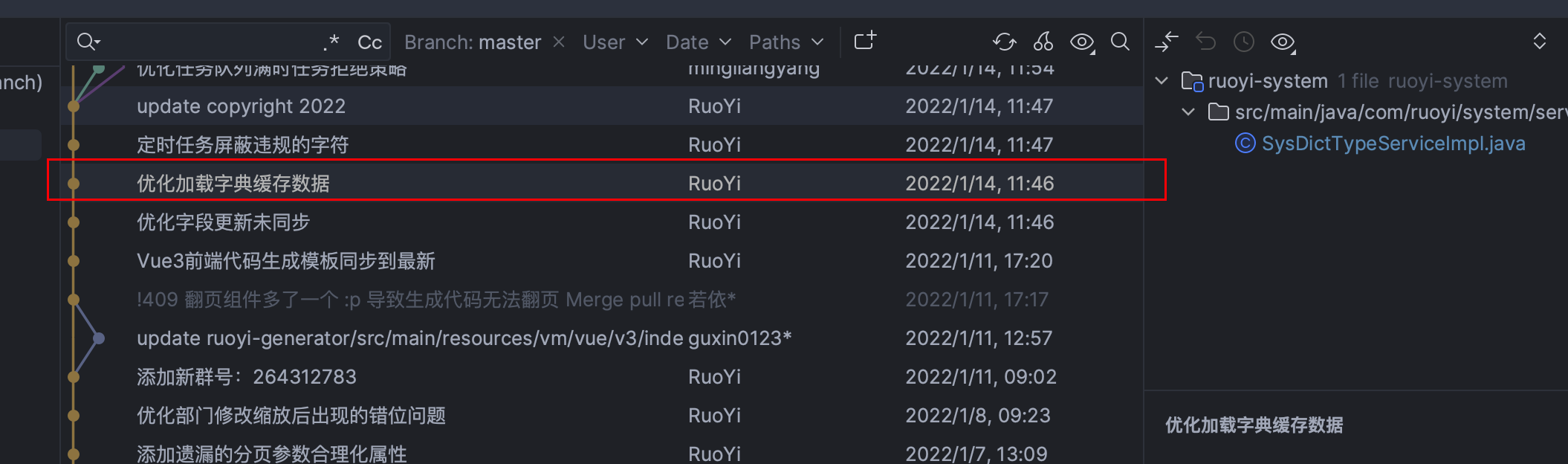
分析
开门见山,我们看下代码
先放下之前的实现
/**
* 加载字典缓存数据
*/
@Override
public void loadingDictCache()
{
// 1. 取出 dictType 中所有数据
List<SysDictType> dictTypeList = dictTypeMapper.selectDictTypeAll();
for (SysDictType dictType : dictTypeList)
{
// 2.根据 dictType 循环遍历从 dictData 中查询
List<SysDictData> dictDatas = dictDataMapper.selectDictDataByType(dictType.getDictType());
DictUtils.setDictCache(dictType.getDictType(), dictDatas);
}
}
看下更新后的实现
/**
* 加载字典缓存数据
*/
@Override
public void loadingDictCache()
{
SysDictData dictData = new SysDictData();
dictData.setStatus("0");
// 1. 一次取出dictData表所有数据,用 stream 表达式组装成一个 map(因为其实 dictData 中就有 key 数据,不需要再去查询 dictType 表,见下图)
Map<String, List<SysDictData>> dictDataMap = dictDataMapper.selectDictDataList(dictData).stream().collect(Collectors.groupingBy(SysDictData::getDictType));
for (Map.Entry<String, List<SysDictData>> entry : dictDataMap.entrySet())
{
// 2.遍历这个组装出来的 map ,注意这里遍历map的方式,加上 sort 排序
DictUtils.setDictCache(entry.getKey(), entry.getValue().stream().sorted(Comparator.comparing(SysDictData::getDictSort)).collect(Collectors.toList()));
}
}
这段代码的功能很简单,就是取出字典表中的数据组合成 key value,用来存放到 redis ,不清楚若依缓存这块的可以看下我上一篇文章 (4条消息) 若依缓存使用浅析_周周写不完的代码的博客-CSDN博客_若依缓存
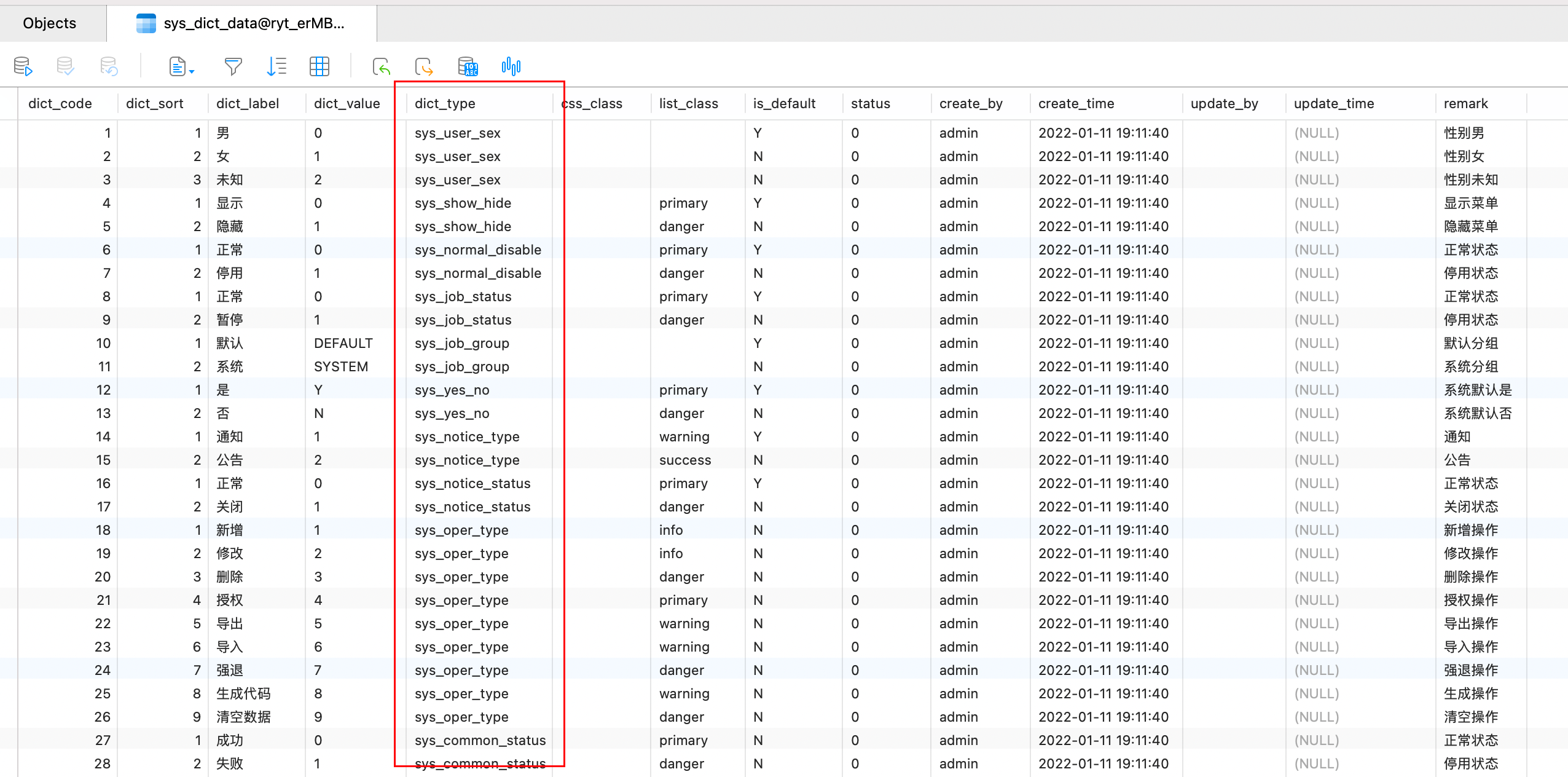
- 这块巧妙的避开了多次数据库查询带来的io损耗,一次性取出所有数据,在内存中进行拼接
- 还需要注意 stream 表达式的使用,这里主要用了两个
- Collectors.groupingBy() 聚集
- .sorted()排序
-
注意遍历 map 的写法
for (Map.Entry<String, List<SysDictData>> entry : dictDataMap.entrySet()) { // entry.getKey() entry.getValue() }
小结
总的看来,这块实现的场景还是很通用的,比如分类这块的实现,也是需要拼接,因为数据库中存放的都是扁平化的数据,但是用的话需要拼装成各种数据结构,方便使用,比如 map,比如 tree