-
项目实现功能
- 在admin后台自定义添加上传文档。
- 对展示在首页的文章分页显示。
- 在首页点击文章的阅读全文按钮可进入该文章全文详情页进行浏览。
- 对文章实现了内容分类何以发布时间进行归档分类。
- 使用django的whoose搜索引擎对全文实现内容的搜索。
-
项目涉及技术
Mysql Django Python redis
-
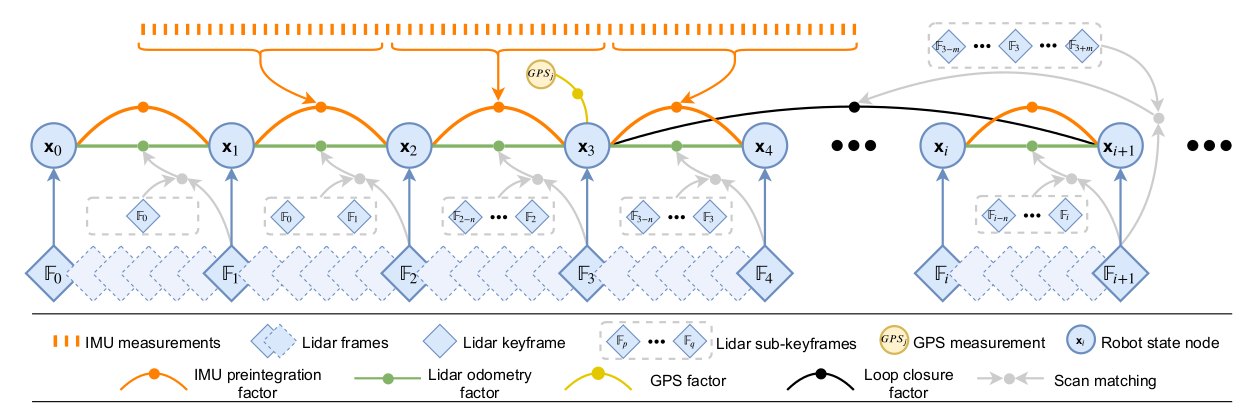
项目核心实现流程
- 确定索要发布的文章展示的样式排版(时间,作者,标签,分类,简介等等),在django的models确定对应的字段形式(注意表与表之间,字段与字段之间的对应关系,一对多OR多对多,比如文章和分类可以实现多对一(一个分类包含多篇文章类型),文章与标签之间是多对多的关系)
- object.get.all()获取数据库的对象内容,在首页的前端页面循环遍历显示即可,至于点击阅读全文按钮进入详情页面在url给定路由后path('page/<int:num>',views.queryAll),我们这里根据点击识别的不同文章的id来获取该文章的内容,
postid = int(postid)
# 根据postid查询帖子的详情信息
post = Post.objects.get(id=postid)然后再详情内容页面讲该文章post.各种字段(分类,简介,内容,时间等等)放在页面对应的变迁文本里即可。 -
分页:使用Django的自带的Pagintor,技术步骤如下结合自己的项目中需要展示的数据库里的数据即可1.导入Paginator类和EmptyPage、PageNotAnInteger异常类; 2.获取需要分页的数据列表; 3.创建Paginator对象,指定每页显示的数据条数; 4.获取当前页码数,如果没有获取到则默认为第一页; 5.获取当前页的数据,如果页码数不是整数或者超出范围则抛出异常; 6.根据总页数决定显示的页码范围; 7.将分页后的数据传递给模板进行渲染
-
对文章的归档(按照类别,时间),
#1.获取分类信息
r_catepost =Post.objects.values('category__cname','category').annotate(c=Count('*')).order_by('-c')
#2.近期文章
r_recpost = Post.objects.all().order_by('-created')[:3]
#3.获取日期归档信息
from django.db import connection
cursor = connection.cursor()
cursor.execute("select created,count('*') c from t_post GROUP BY DATE_FORMAT(created,'%Y-%m') ORDER BY c desc,created desc")
r_filepost = cursor.fetchall()
以上代码用来获取以不同划分特点来获取数据库中的指定内容对象,
分类url:
<a class="category-list-link"
href="/post/category/{{ cp.category }}">{{ cp.category__cname }}</a>
归档url:
<a class="archive-list-link"
href="/post/archive/{{ fp.0|date:'Y' }}/{{ fp.0|date:'m' }}">{{ fp.0|date:'Y年m月' }}</a>
最近文章url(同阅读全文链接地址):<a href="/post/post/{{ rp.id }}" target="_blank">{{ rp.title|truncatechars:10 }}</a>
5.分享,直接调用百度分享的api接口即可:代码如下:
<div class="bdsharebuttonbox"><a href="#" class="bds_more" data-cmd="more"></a><a href="#" class="bds_qzone" data-cmd="qzone"></a><a href="#" class="bds_tsina" data-cmd="tsina"></a><a href="#" class="bds_tqq" data-cmd="tqq"></a><a href="#" class="bds_renren" data-cmd="renren"></a><a href="#" class="bds_weixin" data-cmd="weixin"></a></div>
<script>window._bd_share_config={"common":{"bdSnsKey":{},"bdText":"","bdMini":"2","bdPic":"","bdStyle":"0","bdSize":"16"},"share":{},"image":{"viewList":["qzone","tsina","tqq","renren","weixin"],"viewText":"分享到:","viewSize":"16"},"selectShare":{"bdContainerClass":null,"bdSelectMiniList":["qzone","tsina","tqq","renren","weixin"]}};with(document)0[(getElementsByTagName('head')[0]||body).appendChild(createElement('script')).src='http://bdimg.share.baidu.com/static/api/js/share.js?v=89860593.js?cdnversion='+~(-new Date()/36e5)];</script>
</div>6:全局搜索(whoose);
在Django中使用Whoosh搜索需要使用django-haystack模块。首先需要安装django-haystack和Whoosh,可以使用pip install django-haystack Whoosh命令进行安装。安装完成后,需要在settings.py文件中进行配置,包括搜索引擎的类型、路径等信息。接着需要定义搜索的模型,即在哪些模型中进行搜索。最后需要定义搜索视图和模板,即搜索结果的展示方式。具体的使用方法可以参考django-haystack的官方文档
-
项目部分代码:
- 分页:
def queryAll(request, num=1): num = int(num) postList = Post.objects.all().order_by('-created') # 创建分页器对象 pageObj = Paginator(postList, 2) # 获取当前页的数据 perPageList = pageObj.page(num) # 生成页码数列表 # 每页开始页码 begin = (num - int(math.ceil(10.0 / 2))) if begin < 1: begin = 1 # 每页结束页码 end = begin + 9 if end > pageObj.num_pages: end = pageObj.num_pages if end <= 10: begin = 1 else: begin = end - 9 pageList = range(begin, end + 1) return render(request, 'index.html', {'postList': perPageList, 'pageList': pageList, 'currentNum': num}) - 全局搜索:
#coding=UTF-8 from haystack import indexes from post.models import * import sys # 导入sys模块 sys.setrecursionlimit(3000) # 将默认的递归深度修改为3000 #注意格式(模型类名+Index) class PostIndex(indexes.SearchIndex,indexes.Indexable): text = indexes.CharField(document=True, use_template=True) #给title,content设置索引 title = indexes.NgramField(model_attr='title') content = indexes.NgramField(model_attr='content') def get_model(self): return Post def index_queryset(self, using=None): return self.get_model().objects.order_by('-created')tokenizer.py
#coding=utf-8 import jieba from whoosh.analysis import Tokenizer, Token class ChineseTokenizer(Tokenizer): def __call__(self, value, positions=False, chars=False, keeporiginal=False, removestops=True, start_pos=0, start_char=0, mode='', **kwargs): t = Token(positions, chars, removestops=removestops, mode=mode, **kwargs) seglist = jieba.cut(value, cut_all=False) # (精确模式)使用结巴分词库进行分词 # seglist = jieba.cut_for_search(value) #(搜索引擎模式) 使用结巴分词库进行分词 for w in seglist: # print w t.original = t.text = w t.boost = 1.0 if positions: t.pos = start_pos + value.find(w) if chars: t.startchar = start_char + value.find(w) t.endchar = start_char + value.find(w) + len(w) yield t # 通过生成器返回每个分词的结果token def ChineseAnalyzer(): return ChineseTokenizer()
-
项目部分截图



-
结语:
写的有点急,具体内容没有详细写出来,只是简单提了一下,如Pagintor分页的使用以及whoose全局搜索使用等,下次有时间在针对具体技术讲解,这个小项目当时写出来也就是用来回顾一下django的相关技术内容的,写的不好,在此致歉。