我们回顾下,Hologres是一款实时HSAP产品,隶属阿里自研大数据品牌MaxCompute,兼容 PostgreSQL 生态、支持MaxCompute数据直接查询,支持实时写入实时查询,实时离线联邦分析,低成本、高时效、快速构筑企业实时数据仓库(Real-Time Data Warehouse)。具备如下优势:
| 说明 | |
| 分析服务一体化 |
|
| 以实时为中心设计 |
|
| 计算存储分离 |
|
| 丰富生态 |
|
接下来,我们介绍下Hologres的使用。
1. Hologres 相关概念
- 实例∶使用和管理数据库存储服务的实体,一个实例可以看作是多个数据库的合集
- 数据库︰一个模式的合集,用户所有的操作,包括表、函数等都是在数据库里完成。系统会在用户完成实例申请后默认创建一个"postgres"的数据库,该 DB 仅用于运维管理,实际业务需要新建DB
- 表∶表是数据存储单元。它在逻辑上是由行和列组成的二维结构,列的数量和顺序是固定的,并且每一列拥有一个名字。行的数目是变化的,它反映了在一个给定时刻表中存储的数据量。
- 外表:外表是数据实际存储在其他系统里,但是通过 Hologres 来访问的一类表。Hologres 完全兼容 postgres 的 foreign data wrapper。目前内部支持直接访问 MaxComputer 中的数据
2. 连接开发工具
支持如下方式:
1、DataWorks数仓开发
2、HoloWeb
3、PSQL客户端
4、JDBC
5、Python(使用psycopg2模块访问Hologres)
6、其他工具(Navicat、DBeaver、DataGrip等)
2.1. DataWorks集成Holo
基于Dataworks开发,参考:如何在DataWorks上使用Hologres、如何绑定Hologres引擎,细节:
DataWorks绑定hologres引擎 ==> 独享资源组、依赖独享调度资源组。
Dataworks绑定后,即可在DataStudio开发相关任务流程,详情请参见绑定Hologres实例。如下:
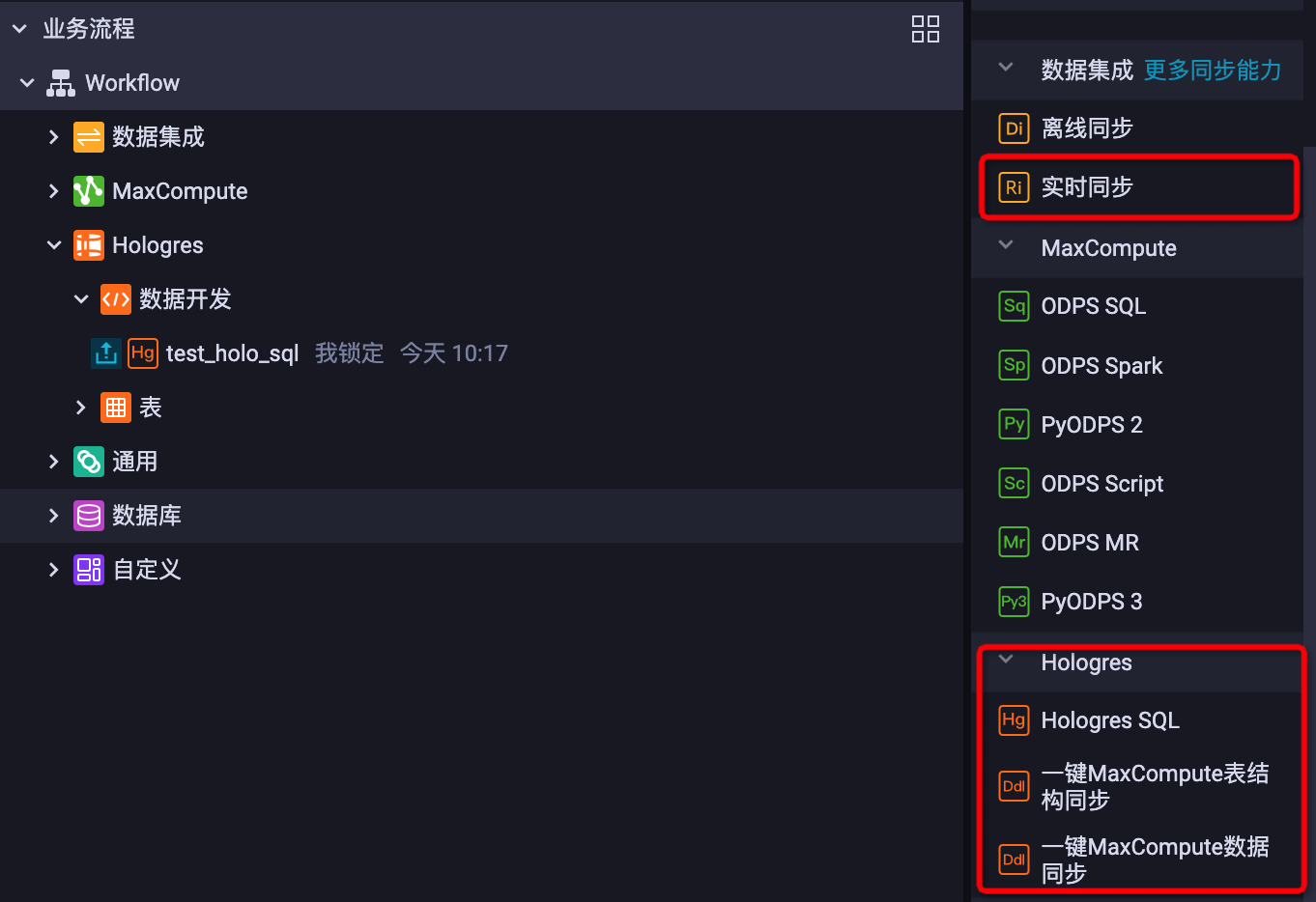
功能介绍:
1、DI离线同步:数据源数据 <--> Holo
2、RI实时同步:数据源数据 <--> Holo
3、Hologres SQL
4、一键MaxCompute表结构同步:批量创建Hologres外部表
5、一键MaxCompute数据同步:导入MaxCompute数据至Hologres
其他:dataworks可以连接hologres,并操作hologres外表方法:
1、holo创建内部表
2、mc创建外部表 关联DataWorks
问题:大数据计算MaxCompute的计算资源还是holo的?
在MaxCompute中创建Hologres外部表,在MaxCompute中做计算,用的是MaxCompute计算资源。
2.2. HoloWeb
功能介绍:
1、元数据管理:数据管理模块提供对Hologres引擎对象(包括实例、数据库、schema、表、视图等)的管理功能
2、SQL编辑器:提供标准SQL开发界面。
- 可用PostgreSQL语句开发、
- 查看SQL的执行计划和运行分析、诊断优化
- 支持交互式分析(Ad Hoc分析,不支持执行时间超过60分钟的长运行SQL)
3、诊断与优化:提供实例级别的运维管控能力。
- 查看慢Query日志、活跃Query、连接管理
- 可结合管理控制台监控指标,对实例异常进行诊断
4、数据方案:提供数据接入能力。
- 本地文件上传
- 外表数据导入操作
5、安全中心:提供用户管理、DB管理、资源组管理
2.3. DBeaver
属于同一网络可以连通。

2.4. 永洪BI
参考:如何通过YonghongBI工具连接Hologres并进行数据分析
2.5. dataworks集成
1、数据地图(Beta)集成,参考:如何在数据地图中配置Hologres元数据采集器
2、数据血缘,参考:如何在DataWorks的数据地图中查看数据血缘信息
3. 开发规范
参考:Hologres开发规范
4. Hologres开发
4.1. 对象层级与模式(Schema)
hologres兼容PostgreSQL生态,因此也有模式相关概念如下图所示:
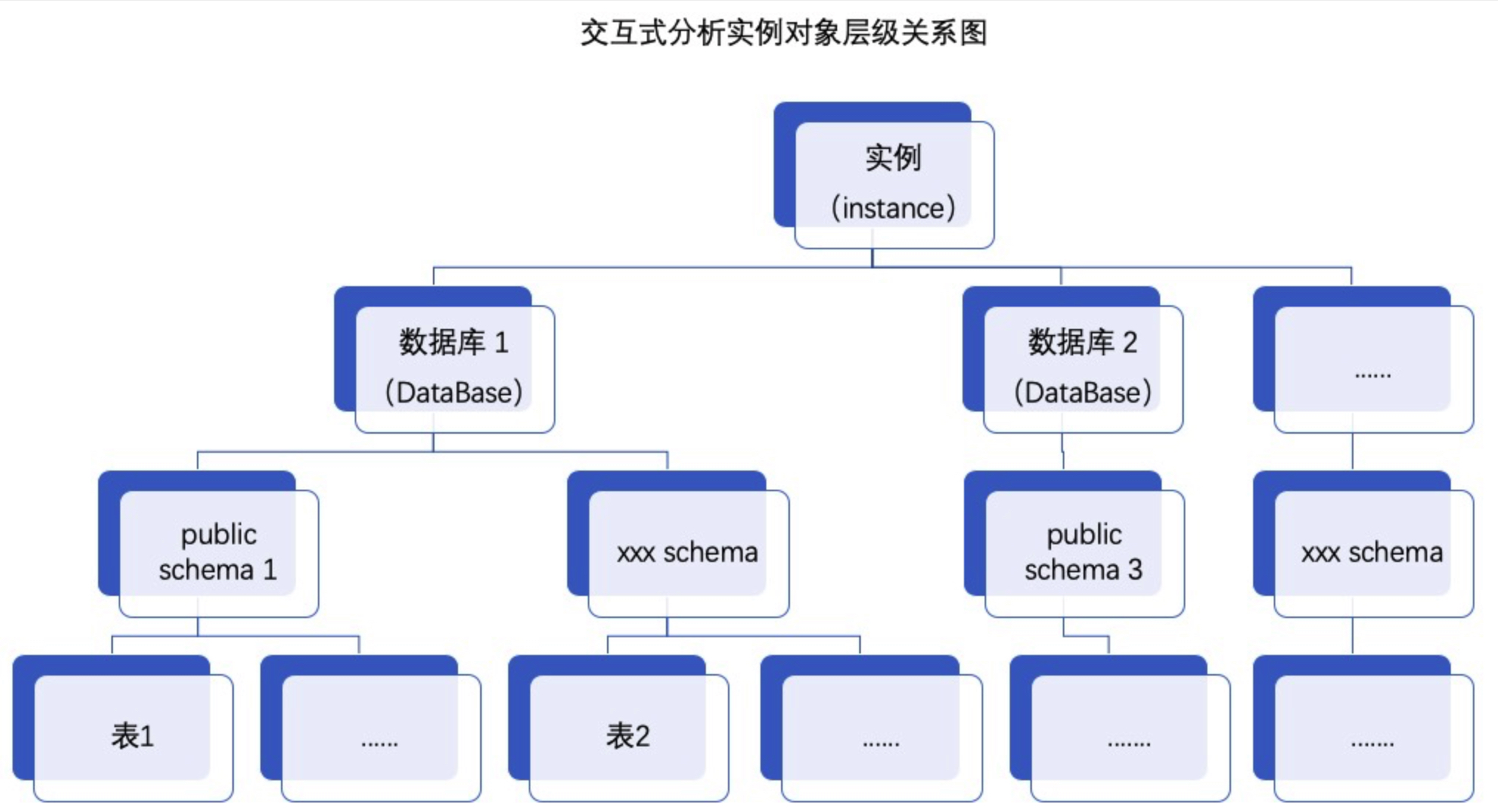
Hologres的Schema功能:
- 新增Schema,表存储结构由database.table变为database.schema.table。
- 创建数据库时,默认创建public Schema
如何理解Schema?
- PostgreSQL 模式(SCHEMA)可以看着是一个表的集合。
- 一个模式可以包含视图、索引、数据类型、函数和操作符等。
- 模式类似于操作系统层的目录,但是模式不能嵌套。
使用模式的优势:
- 允许多个用户使用一个数据库并且不会互相干扰。
- 将数据库对象组织成逻辑组以便更容易管理。
- 第三方应用的对象可以放在独立的模式中,这样它们就不会与其他对象的名称发生冲突。即相同的对象名称可以被用于不同的模式中而不会出现冲突,例如 schema1 和 myschema 都可以包含名为 mytable 的表。
提示:
1、可以用于 OLAP表权限管理
如果其他用户想访问某个schema下的对象,则该schema的owner必须赋予其他用户的usage权限,如果需要做其他操作也需要赋予相应的权限在默认情况下,所有人都拥有在public模式上的CREATE和USAGE权限。
2、业务线隔离
3、数仓分层隔离
4.2. 表
- 创建表--CREATE TABLE
- 创建表--CREATE TABLE AS
- 创建表--CREATE TABLE LIKE
- 修改表--ALTER TABLE(重命名、增加列和修改表数据生存时间)
- 删除表--DROP TABLE
- 创建类型转换--CAST(删除、创建)
- 视图--物化视图、视图
begin;
create table [if not exists] [schema_name.]table_name ([
{
column_name column_type [column_constraints, [...]]
| table_constraints
[, ...]
}
]);
call set_table_property('<table_name>', property, value);
comment on column <tablename.column> is 'value';
comment on table <tablename> is 'value';
commit;
-- 给表增加注释
COMMENT ON TABLE table_name IS 'my comments on table table_name.';
-- 给列增加注释
COMMENT ON COLUMN table_name.col1 IS 'This my first col1';
-- 给外部表增加注释
COMMENT ON FOREIGN TABLE foreign_table IS ' comments on my foreign table';设置默认值
smallint_col smallint DEFAULT 0, 4.2.1. 表分类及使用场景
1、内部表
内部表数据存储在Hologres数据库中,支持设置:
- 表数据生命周期(秒):默认生命周期为永久。
- Binlog:表是否开启Binlog。Binlog生命周期
- 各类索引等,后面介绍
相关语法:
-- 建表时开启
call set_table_property('test_message_src', 'binlog.level', 'replica');--设置表属性开启Binlog功能
call set_table_property('test_message_src', 'binlog.ttl', '86400');--binlog.ttl,Binlog的TTL,单位为秒
查询binlog
select hg_binlog_lsn,hg_binlog_event_type,hg_binlog_timestamp_us,* from test_message_src;场景:各类高性能要求的OLAP分析、点查询、实时链路
2、分区表
Hologres的分区表必须提前创建好分区,不能用查询语句的值动态生成分区表。
Partition Table,也叫分区表。父表按分区键(Partition Key)的值划分为不同的子表,子表对外可见。
语法:
- 创建分区表--CREATE TABLE
- 修改分区表--ALTER TABLE (重命名、绑定分区、卸载分区)
- 删除分区表--DROP TABLE
使用:
- Hologres暂不支持插入数据至分区表父表,只支持插入数据至具体的分区表子表。
- 若是表有主键,分区键必须是主键的一个子集。
- 动态分区是自动调度创建,仅支持以time_unit作为分区
性能:
- 如果单日分区数据小于1亿条,不建议使用日作为分区条件,或创建分区表。分区表太小,查询加速效果不明显,可以选择较大粒度的分区。
- 分区表的任何一个子表在元数据存储上等同于一个非分区表,因此分区多会造成一定程度的元数据膨胀,以及小文件碎片。
场景:
- 如果您需要经常对某分区数据进行整体替换,包括执行truncate操作或者drop操作,建议使用分区表。
- 如果您的数据来源于数据库,不建议使用分区表。过多的分区表会引起额外的IO资源浪费,为改善此问题并实现索引过滤加速查询的效果,您可以将常用分区条件作为segment_key。
3、外部表
支持创建MaxCompute、OSS、DLF、Hologres类型的外部表,使用限制如下:
- 使用Hologres创建外部表查询数据时,当MaxCompute表增加字段后,Hologres不会自动更新Schema,需要您在Hologres中手动增加列。
- Hologres仅支持为外部表重命名、增加列及删除列等修改外部表操作。
语法:
- 批量创建外部表--IMPORT FOREIGN SCHEMA
- 修改外部表--ALTER FOREIGN TABLE (重命名、增加列、删除列)
- 删除表--DROP FOREIGN TABLE
-
- CASCADE 删除表时,级联删除依赖于表的对象,例如视图。
- RESTRICT 如果目标表存在依赖对象,则系统拒绝删除该表。
场景:
- 数据同步:①holo中通过创建外部表关联MC表;②holo中通过查询外部表导入holo内部表
- maxcompute加速查询-- Hologres揭秘:高性能原生加速MaxCompute核心原理
4.2.2. 表设置
1、表存储格式--行、列
Hologres支持三种表存储格式,分别为:行存、列存和行列共存。通过如下进行设置:
call set_table_property('<table_name>', 'orientation', '[column | row | row,column]');建表时默认为列存(column storage)形式。
使用建议:

各类存储格式总结:
1、列存(OLAP查询场景)
- 数据按列存存储,ORC格式
- 主键:系统会为每张表在底层存储一个主键索引文件,列存表如果设置了主键PK,系统会自动生成一个Row Identifier(RID),用于快速定位整行数据
- 索引:查询的列设置合适的索引(如Distribution Key、Clustering Key等),可通过索引快速定位到数据所在的分片和文件,从而提升查询性能
2、行存(点查询)
- 数据按行存存储,SST格式
- 主键:推荐设置主键,基于主键查询的场景上,只需要扫描一个主键就能快速拿到所有列的全行数据。
- 索引:设置PK后,系统也会将PK设置为Distribution Key和Clustering Key
说明:
1、行存,数据按照Key有序分块压缩存储,并且通过Block Index、Bloom Filter等索引,以及后台Compaction机制对文件进行整理,优化点查查询效率。
2、行存表非常适用于基于PK的点查场景,能够实现高QPS的点查。同时建表时建议只设置PK,系统会自动将PK设置为Distribution Key和Clustering Key,以提升查询性能。不建议将PK和Clustering Key设置为不同的字段,设置为不同的字段会有一定的性能牺牲。
3、行列共存(同时用于主键点查、OLAP查询)
- 数据在底层存储时会存储两份,一份按照行存格式存储,一份按照列存格式存储,因此会带来更多的存储开销。
- 写入时,因为需要存储2份数据,保证数据原子性
- 数据查询,优化器会根据SQL,解析出对应的执行计划,判断走行还是列。含主键的过滤条件走点查询,其他情况走列查询
2、生命周期
time_to_live_in_seconds 指定了表数据的生存时间,单位为秒,必须是非负数字类型
表数据的TTL并不是精确的时间,当超过设置的 TTL 后,系统会在某一个时间自动删除表数据,所以业务逻辑不能强依赖 TTL
begin;
create table tbl ( a int not null,b text not null) ;
call set_table_property( 'tbl', 'time_to_live_in_seconds ', '3.14159');commit;4.2.3. 表索引设置
1、Primary Key
主键Primary Key(简称PK)与传统数据库主键特性一致,是表中记录的唯一标识,代表了表数据的唯一性。语法:
PRIMARY KEY (id,age)原理:
- 保存一个主键索引文件,采用行存结构存储,提供高速的KV(key- value)服务 PK:RID。主键索引文件能够实现高效的主键冲突判定并辅助数据文件定位
- RID每次UPSERT自动生成,单调递增。
- 通过PK在主键索引文件中快速定位到RID和Clustering Key,再通过RID和Clustering Key定位到数据所在的文件。
💡总结:
1、主键用于文件间或内数据记录排序(行表、行列表)。
2、行存表必须设置主键,行列共存表必须设置主键,列存表不要求有主键。场景:
- 支持高性能的UPSERT或DELETE。
- 支持高QPS的基于主键查询。
3、尽量选择含有实际业务意义的字段,不建议将Serial类型的字段设置为主键,因为Serial类型在写入的时候是表锁,导致写入性能有损失,且随着数据的增长,长度容易溢出。
2、Distribution Key
Distribution Key属性指定了表数据的分布策略,系统会保证Distribution Key相同的记录被分配到同一个Shard上。
call set_table_property('<table_name>', 'distribution_key', '[<columnName>[,...]]');原理:
- 为表设置了Distribution Key之后,数据会根据Distribution Key被分配到各个Shard上,算法为Hash(distribution_key)%shard_count,结果为对应的Shard。
- 系统会保证Distribution Key相同的记录会被分配到同一个Shard上。
💡总结:
1、分布键作用于文件数据分配。
2、如何设置使用:
- Distribution Key尽量选择分布均匀的字段,否则容易因为数据倾斜导致负载倾斜,使得查询效率变低
- 选择Group By频繁的字段作为Distribution Key。
- Join场景中,设置Join字段为Distribution Key,实现Local Join,避免数据Shuffle。
- 不建议为一个表设置多个Distribution Key,建议设置的Distribution Key不超过两个字段。设置多字段为Distribution Key,查询时若没有全部命中,容易出现数据Shuffle。
3、要求:
- 设置Distribution Key需要在建表时设置,建表后如需修改Distribution Key需要重新建表并导入数据。
- (不能为空,即不指定任何列),因为要求同一记录的数据只能属于一个Shard。如果没有额外指定Distribution Key,默认将PK设置为Distribution Key。
- Distribution Key列的值中有null时,当作“”(空串)看待,即Distribution Key为空。
4、技巧:
- 通过查看执行计划(explain SQL)中没有redistribution算子,说明数据没有重分布。
3、Segment Key
Event Time Column -- Segment Key 指定文件排序,语法如下:
call set_table_property('<table_name>', 'event_time_column', '[<columnName> [,...]]');原理:设置了Event_time_column(Segment Key),系统将文件基于Segment Key范围排序后,选择Segment Key范围相邻的文件进行合并,减少文件之间的重叠,这样就使得查询时能够过滤掉尽可能多的文件,从而提升查询效率。
💡总结:
1、作用于文件排序(列表)
2、如何设置使用:
- Event_time_column适用于数据为单调递增或单调递减的有序字段。如时间戳字段
- Event_time_column具备左匹配原则,建议选择设置两个或者两个以内字段设置为Event_time_column。
3、对以下场景进行加速:
- 含范围过滤条件(包括等值条件)的查询场景。
- 基于主键的UPDATE。Hologres的UPDATE命令原理是由DELETE命令和INSERT命令组合实现。先查找再删除。
4、Clustering Key
Hologres会按照聚簇索引在文件内对数据进行排序,建立聚簇索引能够加速在索引列上的范围和过滤查询,语法:
call set_table_property('<tablename>', 'clustering_key', '[<columnName>{:asc} [,...]]');对于行存表,Clustering Key默认为主键
💡总结:
1、作用于文件内的数据排序(列表)
2、场景:
适用于点查以及范围查询的场景,对于过滤操作有比较好的性能提升,如where a = 1或者where a > 1 and a < 5的场景加速效果比较好
3、如何设置使用:
- 左匹配原则,一般不建议设置Clustering Key超过两个字段,否则适用场景受限。
- 组合设置时,排在前面列的排序优先级高于后面的列
- Clustering Key默认为升序(asc),设置升序可以提升性能
3、技巧:
- 计划结果中有Cluster Filter算子
5、Bitmap
在Hologres中,bitmap_columns属性指定位图索引,是数据存储之外的独立索引结构,以位图向量结构加速等值比较场景,能够对文件块内的数据进行快速的等值过滤,适用于等值过滤查询的场景。语法:
call set_table_property('<table_name>', 'bitmap_columns', '[<columnName>{:[on|off]}[,...]]');原理:
系统会将列对应的数值生成一个二进制字符串,用于表示取值所在位置的Bitmap,当查询命中Bitmap时,会快速定位到数据所在的行号(Row Number),从而快速过滤出数据,对于以下场景需要注意事项如下:
- 列的基数较高(重复数据较少)场景:假如列的基数较高,那么就会为每一个值生成一个Bitmap,当非重复值很多的时候,就会形成稀疏数组,占用存储较多。
- 大宽表的每一列都设置为Bitmap场景:如果为大宽表的每一列都设置为Bitmap,那么在写入时每个值都需要构建成Bitmap,会有一定的系统开销,从而影响写入性能。
💡总结:
1、作用于文件内定位(行列共存表)
2、场景:
适用于等值过滤查询的场景
3、如何设置使用:
- 适合将等值查询的列设置为Bitmap,能够快速定位到符合条件的数据所在的行号。但需要注意的是Bitmap对于基数比较高(重复数据较少)的列会有比较大的额外存储开销。
- 不建议为每一列都设置Bitmap,不仅会有额外存储开销,也会影响写入性能(因为要为每一列构造Bitmap)。
- 不建议为实际内容为JSON,但保存为text类型的列设置Bitmap。
4、技巧:
执行计划结果中有Bitmap Filter算子,说明命中Bitmap索引。
5、Bitmap和Clustering Key的区别:
- 相同点:Bitmap和Clustering Key都是文件内的数据过滤。
- 不同点:Bitmap更适合等值查询,通过文件号定位到数据;Clustering Key是文件内的排序,因此更适合范围查询。Clustering Key的优先级会比Bitmap更高,即如果为同一个字段设置了Clustering Key和Bitmap,那么优化器会优先使用Clustering Key去匹配文件
6、Dictionary Encoding
字典编码可以将字符串的比较转成数字的比较,加速Group By、Filter等查询。语法
call set_table_property('<table_name>', 'dictionary_encoding_columns', '[<columnName>{:[on|off|auto]}[,...]]');原理:Dictionary Encoding是一种压缩存储的技术,系统会将原始数据编码为数值类型存储,同时也会维护对应的编码表结构,在数据读取时,会根据编码表进行数据解码操作,因此在字符串比较的场景中,尤其是对基数小的列,有加速作用,常用于Group By、Filter等过滤查询场景中。
Hologres V0.9及之后版本中默认取值auto,当表有数据写入时,如果字段里数值的重复度大于等于90%,那么系统就会对该字段开启字典编码
💡总结:
1、作用于文件内编码存储(列存、行列共存表)
2、场景:
适用于等值过滤查询的场景
3、如何设置使用:
- 将有字符串比较的列设置为字典编码列,并且列的基数较小,即数据重复度较高。
- 不建议将所有的列都设置为字典编码列,因为这样做会带来额外的编码、解码开销。
- 不建议为实际内容为JSON,但保存为text类型的列设置字典编码。
- 可以在建表之后单独使用设置字典编码。表示修改字典编码列,修改之后非立即生效,字典编码构建和删除在后台异步执行
4、技巧:
执行计划结果中有Bitmap Filter算子,说明命中Bitmap索引。
5、Bitmap和Clustering Key的区别:
- 相同点:Bitmap和Clustering Key都是文件内的数据过滤。
- 不同点:Bitmap更适合等值查询,通过文件号定位到数据;Clustering Key是文件内的排序,因此更适合范围查询。Clustering Key的优先级会比Bitmap更高,即如果为同一个字段设置了Clustering Key和Bitmap,那么优化器会优先使用Clustering Key去匹配文件
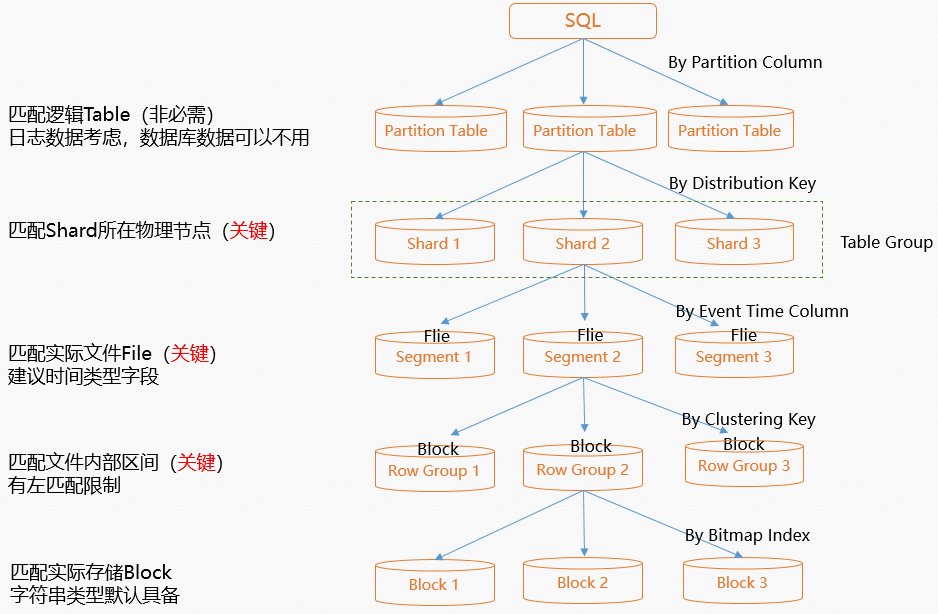
4.2.4. 如何合理的建表索引总结
Hologres是兼容PostgreSQL生态,建表语法与PostgreSQL相同,但是索引与PostgreSQL不同.
| 索引 | 适用场景 | 示例查询语句 |
| Distribution Key | 适合于频繁进行Group By的列或者多表Join时的Join字段设置为Distribution Key,能够减少数据Shuffle,实现Local Join的能力。 | select * from tbl1 join tbl2 on tbl1.a=tbl2.c; |
| Clustering Key | 将范围查询或Filter查询列作为聚簇索引列。索引过滤具备左匹配原则,建议设置聚簇索引列不要超过两列。 | select sum(a) from tb1 where a > 100 and a < 200; |
| Bitmap | 将等值查询列作为Bitmap列。 | select * from tb1 where a =100; |
| Event Time Column(原Segment_Key) | 适用于将日志、流量等和时间强相关的列设置为Segment_Key。 | select sum(a) from tb1 where ts > '2020-01-01' and a < '2020-03-02'; |
设置判断流程图:
4.2.5. 设置表属性和索引总结
在Hologres中,可以通过set_table_property命令为表设置多种属性,合理的表属性设置可以有助于系统高效地组织和查询数据。与数据存储布局有关的参数需要和建表语句同时执行。
call set_table_property('<table_name>', property, value);
总结:
- SQL执行时,如果是分区表,那么会通过分区裁剪,定位到所在分区。
- 通过Distribution Key快速定位到数据所在的数据分片(Shard)。
- 通过Event Time Column(原Segment Key)快速定位到数据所在的文件。--->适用于单调递增或单调递减的有序字段,例如时间戳字段,非常适用于日志、流量等和时间强相关的数据
- Clustering Key为数据在文件内的排序,可以通过Clustering Key快速定位到所在的文件块。 ---> 聚簇索引
- 位图索引Bitmap是文件内的索引,可以通过Bitmap快速定位到符合条件的数据所在的行号。-->适合将等值查询条件的数据设置为位图索引列。默认列存表所有TEXT数据类型的字段都会被隐式地设置为位图索引列
- dictionary_encoding_columns设置字典编码Dictionary Encoding,命令语法如下所示。Dictionary Encoding指定列的值构建字典映射。字典编码可以将字符串的比较转成数字的比较,加速Group By、Filter等查询。默认列存表所有TEXT数据类型的字段都会被设置为Dictionary Encoding列
- time_to_live_in_seconds(不建议使用)TTL不是精确的时间,即到期了之后数据会在某一段时间(不是固定时间)删除(只删除数据,表还会存在),因此可能会出现PK重复的问题。不设置TTL的时候,默认为100年
orientation、distribution_key、clustering_key、event_time_column属性决定了数据写入后的存储布局,因此建表后不支持更改,如需修改,需要重新建表;bitmap和dictionary属性不影响数据存储布局,可以在建表后按需更改。
4.3. DML & DQL
1、SELECT语法:
- JOIN
- WITH子句
- GROUP BY分组
- HAVING过滤
- GROUP BY CUBE
- GROUP BY ROLLUP
- GROUP BY GROUPING SETS
- ORDER BY
2、insert语法:
- insert into values
- insert into select
- INSERT OVERWRITE语法
- upsert语法
-
- INSERT ON CONFLICT的技术实现原理同UPDATE,模式:InsertOrIgnore、InsertOrReplace、InsertOrUpdate
- 注意性能
3、COPY 文件导入导出
4、DELETE删除数据
- DELETE命令与PostgreSQL的一样,使用标记删除,在下一次Compaction后,存储空间才会被释放。
5、UPDATE
- UPDATE的过程中也是如此,可以通过主键快速过滤出要更新的文件,减少文件扫描;如果没有主键,更新就很容易退化成全表更新,导致性能变差。
- 局部更新在性能上:行存>行列共存>列存。
6、TRUNCATE
- 支持对普通表、分区父表及分区子表执行
7、事务
Hologres支持完整的DDL事务以及部分DML事务,默认支持单条SQL事务。
场景:
- 支持多条DDL语句事务。`begin commit`
- 支持多条DML混合事务。默认关闭
8、函数
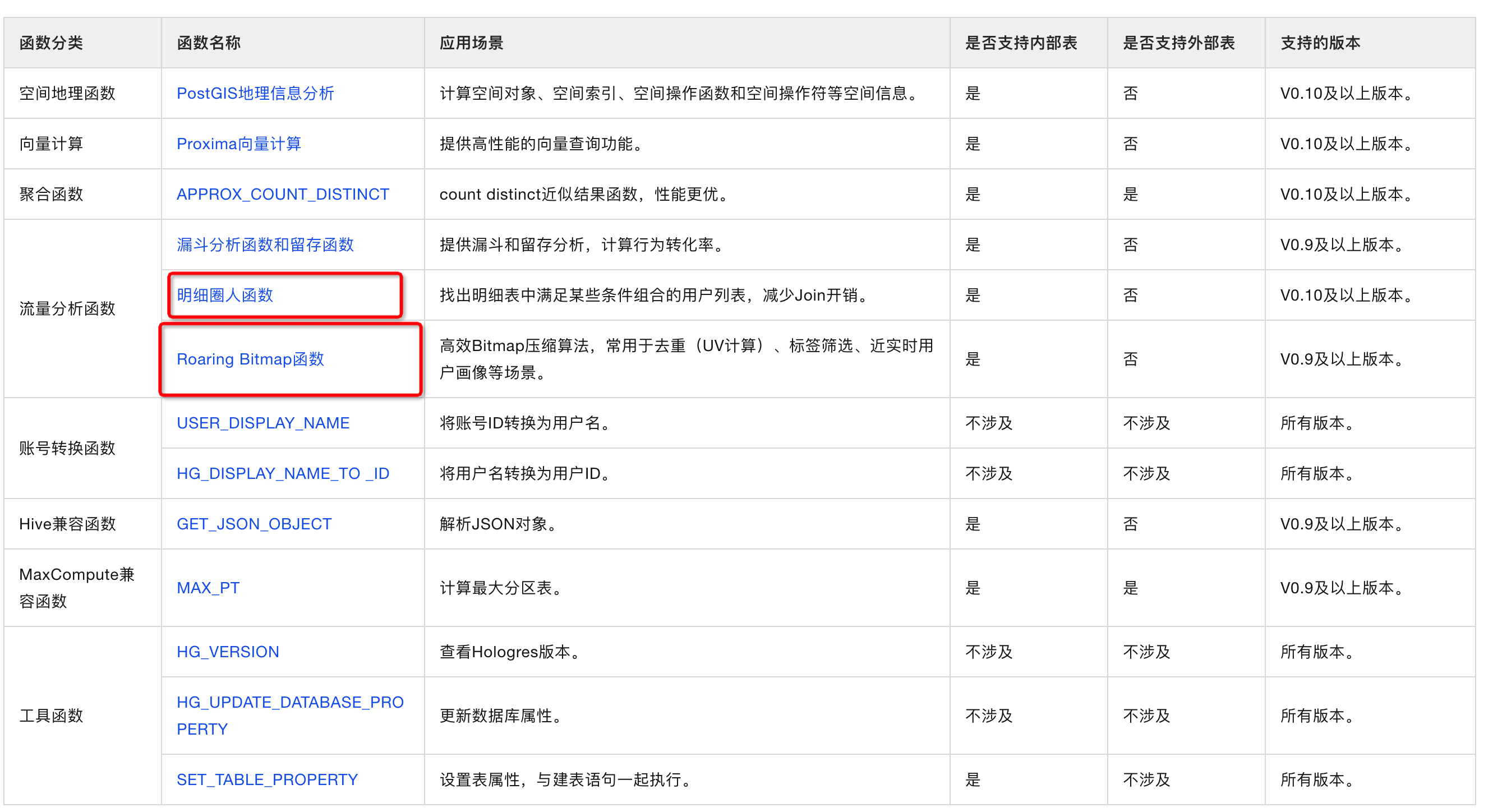
9、跨库查询
使用 JOIN 操作。可以使用 JOIN 操作将两个或多个 Hologres 库连接起来,并在两个库之间进行数据查询。
使用 UNION 操作。可以使用 UNION 操作将两个或多个 Hologres 库中的表进行合并,并形成一个新的表。
使用 CROSS JOIN 操作。可以使用 CROSS JOIN 操作将两个或多个 Hologres 库中的所有表进行笛卡尔积,并形成一个新的表。
5. 数据同步实战
5.1. 实时同步
5.1.1. SLS ---> Holo
1、通过DataWorks数据集成将SLS数据写入Hologres
如何将SLS数据实时写入至Hologres_实时数仓Hologres-阿里云帮助中心
2、LogHub(SLS)实时ETL同步至Hologres
如何使用LogHubSLS实时同步至Hologres任务_大数据开发治理平台 DataWorks-阿里云帮助中心
支持2种方式:
- 数据集成 -> 同步任务 (依赖数据集成独享资源组)
-
- 可配置json解析出时间事件,符合Flink
- 数据集成 单独 运维监控中心
- DataWorks -> RI节点 (依赖数据集成独享资源组、调度独享资源组)
-
- 不可解析字段
- 运维中心运维
推荐:数据集成 -> 同步任务
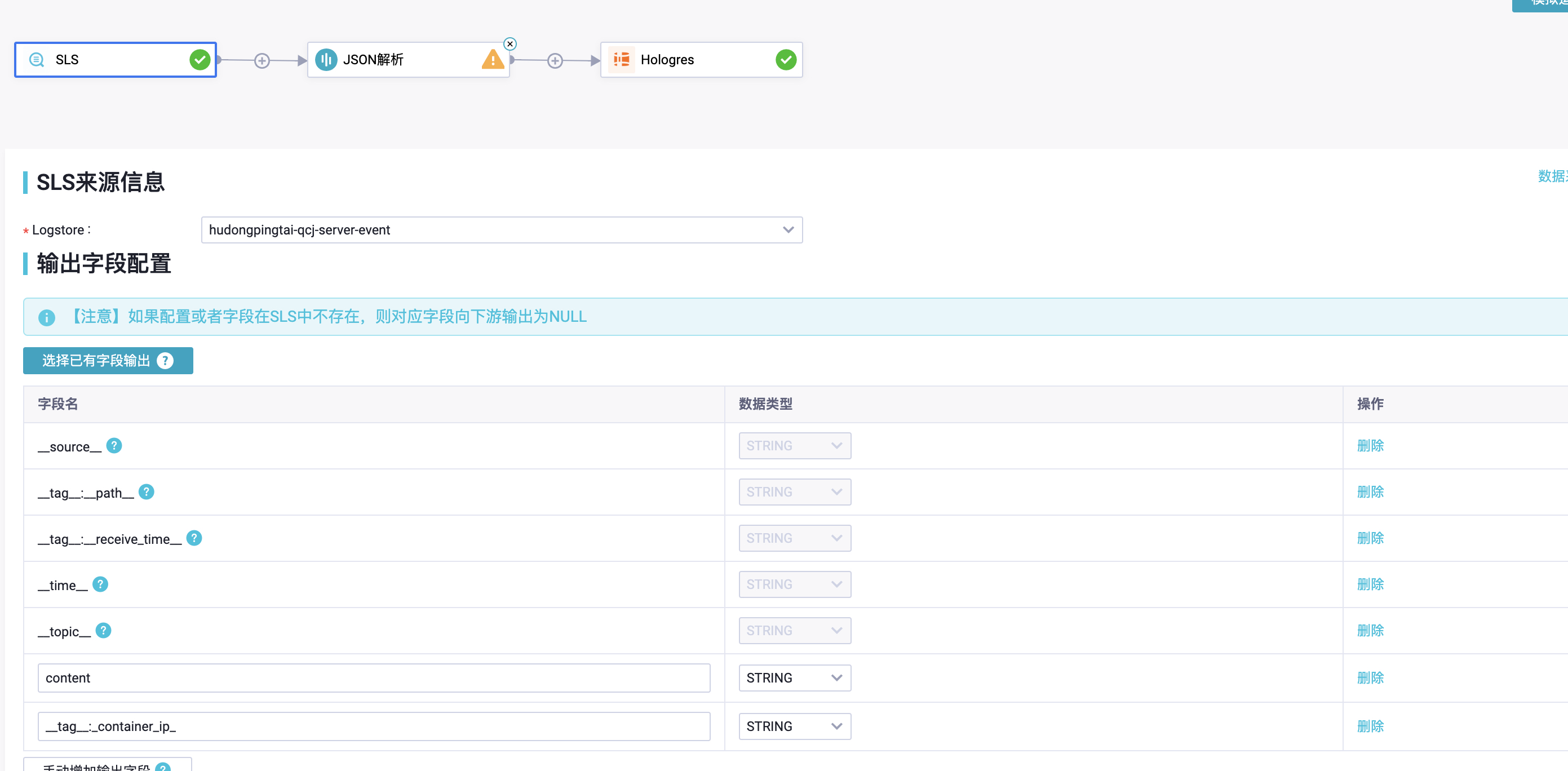
5.1.1.1. 测试数据准备
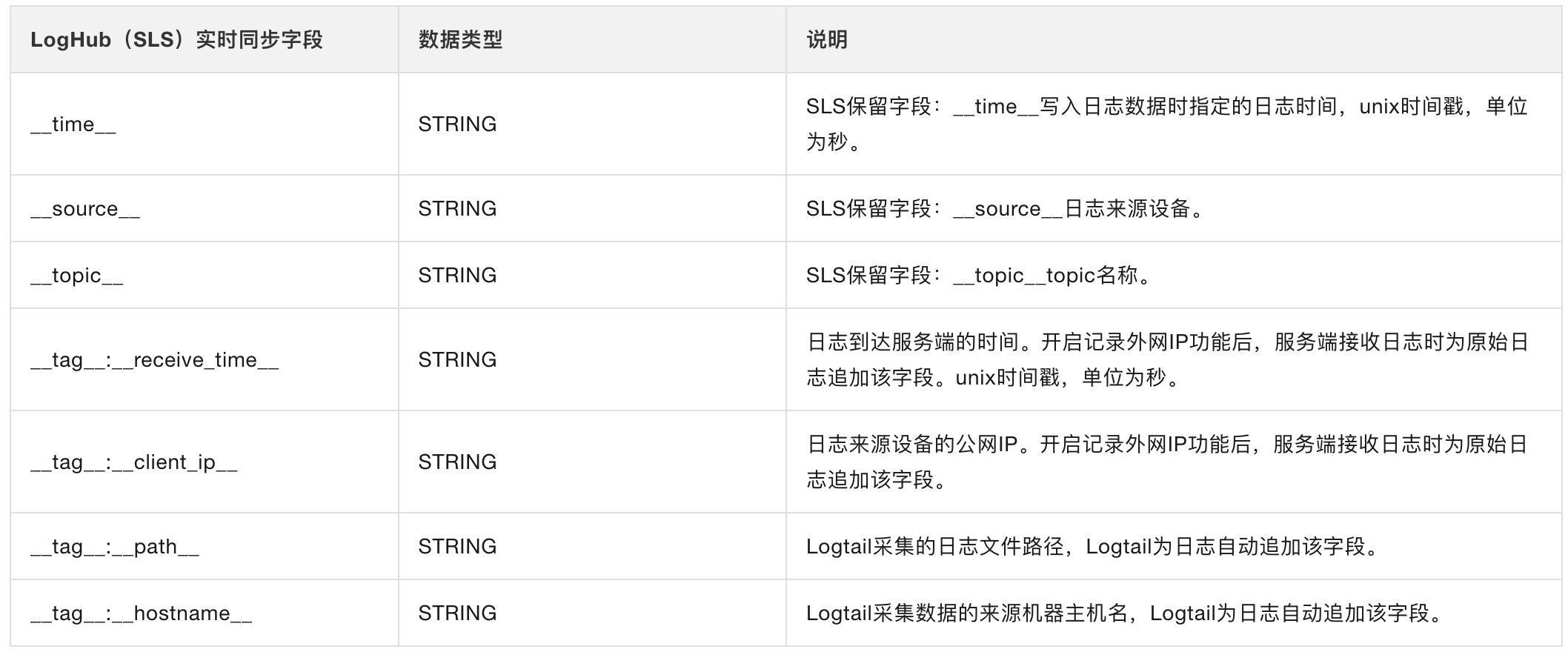
实时读LogHub(SLS),元数据字段
元字段了解:
建表:
BEGIN;
CREATE TABLE dsp_sls_ri (
C_time TEXT,
C_Source TEXT,
C_Recevie_time TEXT NOT NULL,
content TEXT,
dateTime TIMESTAMP NOT NULL,
PRIMARY KEY (content)
);
call set_table_property('dsp_sls_ri', 'orientation', 'column');
call set_table_property('dsp_sls_ri', 'event_time_column', 'dateTime');
-- 存储3天
call set_table_property( 'dsp_sls_ri', 'time_to_live_in_seconds ', '259200');commit;
COMMIT;提示:
1、不加PRIMARY KEY会报错
2、三个时间的差别:

5.1.1.2. 实时同步测试
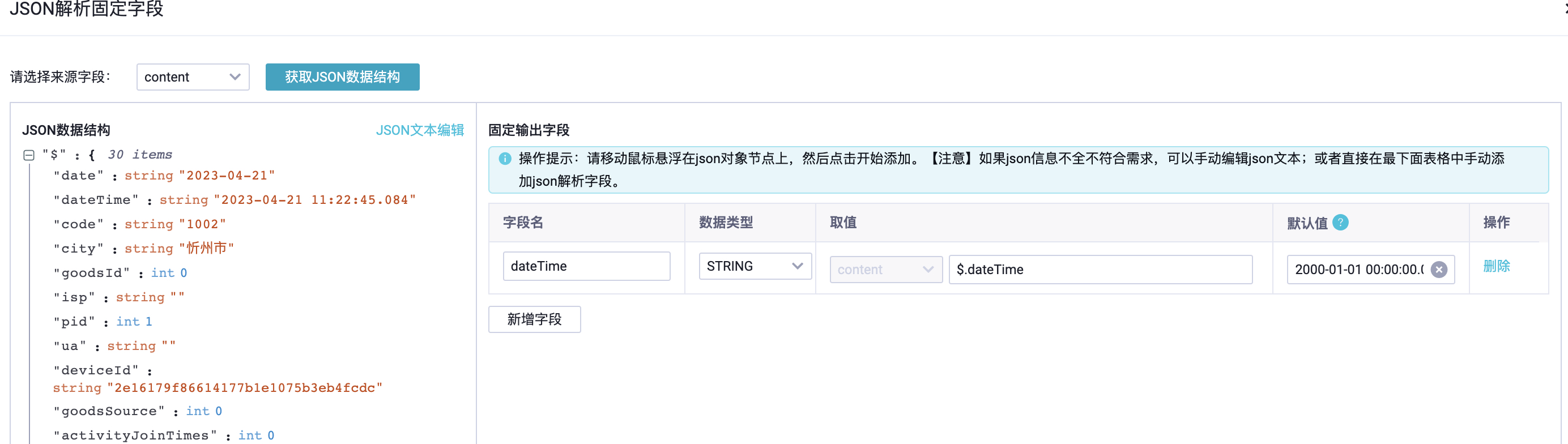
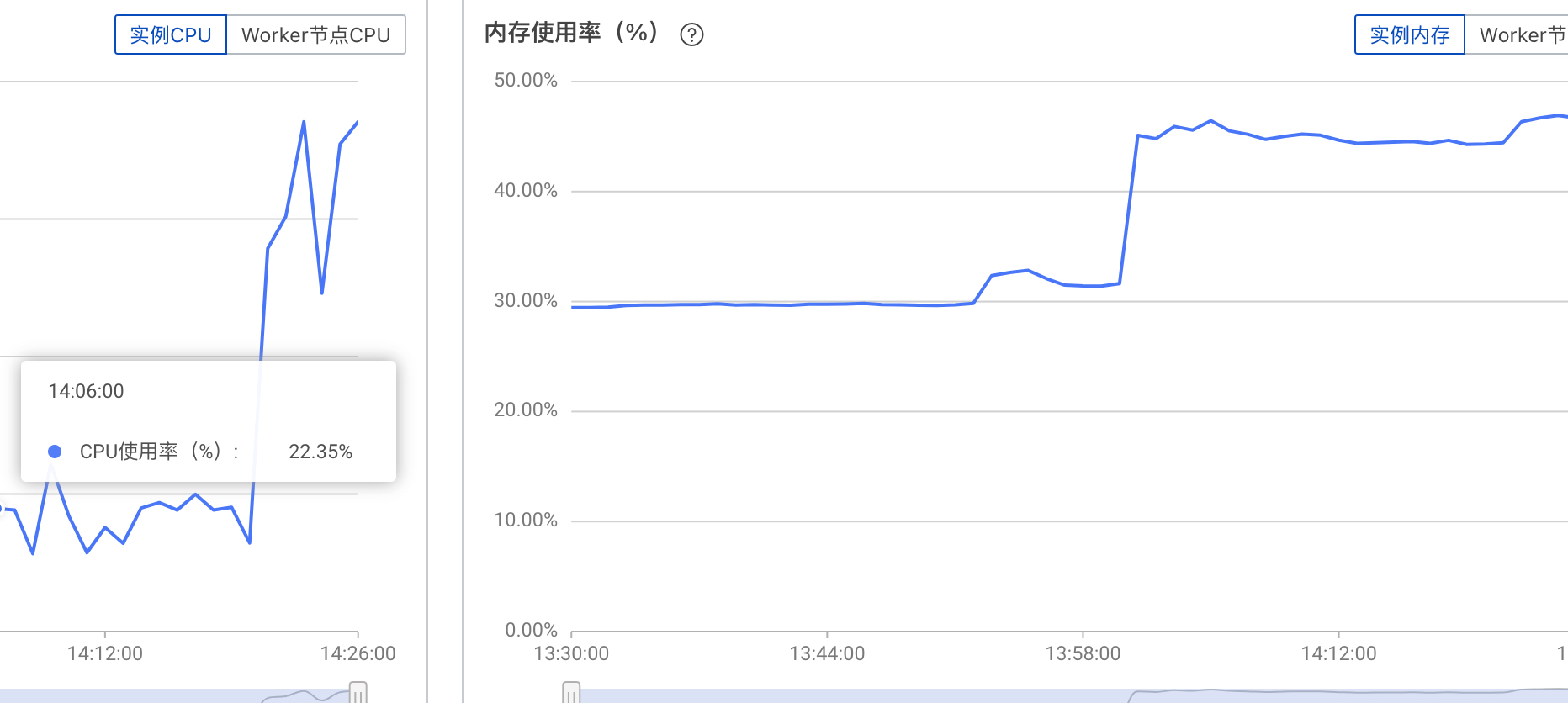
性能观察:
| 类别 | ||
| 数据集成独享资源组 | 资源情况:35% | |
| 同步情况 | 偶尔延迟3.75s,同步字节数:77kb/s |
|
| Holo资源消耗 | CPU:22.35%,内存:30% |
|

5.1.1.3. 功能测试
重新配置,更新应用设置位点。
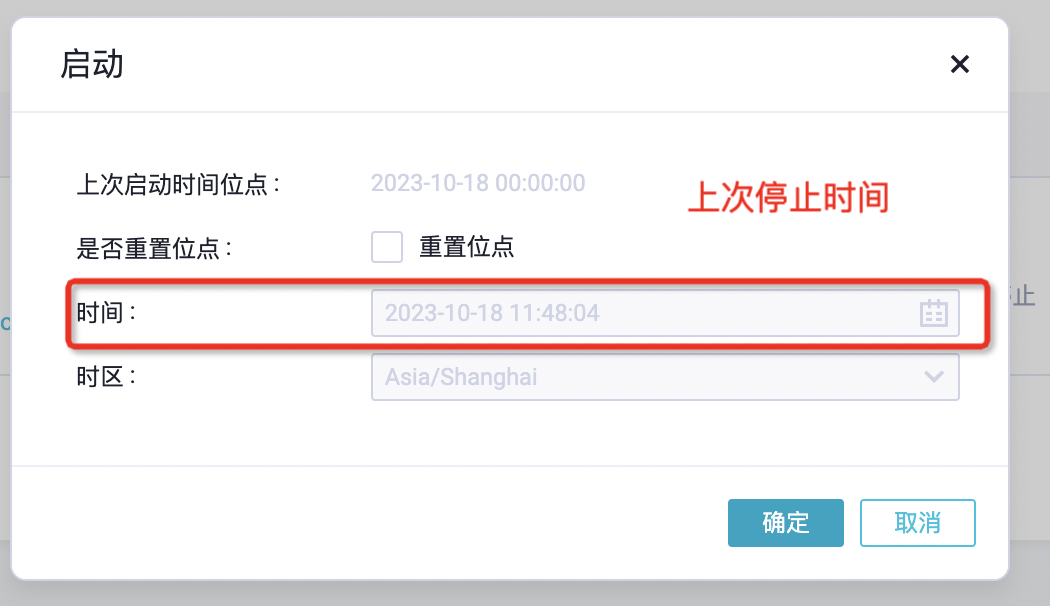
虽然,这里的位点没有到毫秒,但是重新启动时,不会重复拉取。
5.1.2. MySQL <---> Holo

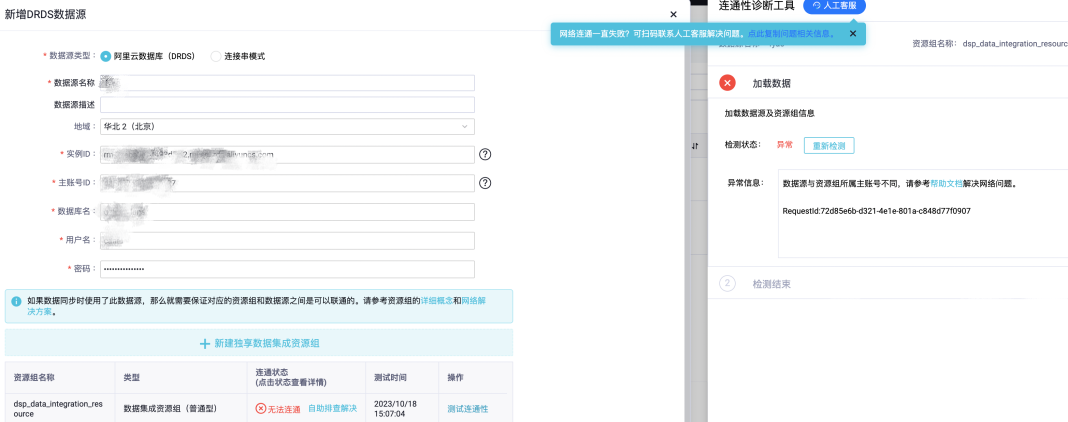
结论:实时不能跨账号,不进行后续测试。
5.2. 离线同步(Holo <--> MC)
两种方式:
1、通过离线节点完成数据同步
2、通过外部表完成
提示:
1、仅支持单表同步
5.2.1. holo --> MC
通过外部表方式:将Holo内部表数据写入 MC内部表
-- 1、MC创建内部表
CREATE TABLE dw_spm_markactivity_detail_di (
...
)PARTITIONED BY (ds STRING)
;
-- 需要提前创建分区,否则会报错
alter table dw_spm_markactivity_detail_di add if not exists partition (ds='20231112');
-- 2、Holo创建内部表
-- 3、Holo创建外部表
BEGIN;
CREATE FOREIGN TABLE public.odps2dw_spm_markactivity_detail_di (
dw_gmt_create timestamp with time zone,
spm_time text,
...
ds text,
)
SERVER odps_server OPTIONS (
project_name 'DSP_DW_DEV',
table_name 'dw_spm_markactivity_detail_di'
);
END;
-- 4、写入MC
INSERT INTO odps2dw_spm_markactivity_detail_di
SELECT *,'20231112' FROM dw_spm_markactivity_detail_di;注:
1、需要提前创建MC的分区,才可以导入
2、4语句可以使用DataWorks调度
5.3. 联邦查询(MC + Holo)
注意:不支持跨账号执行
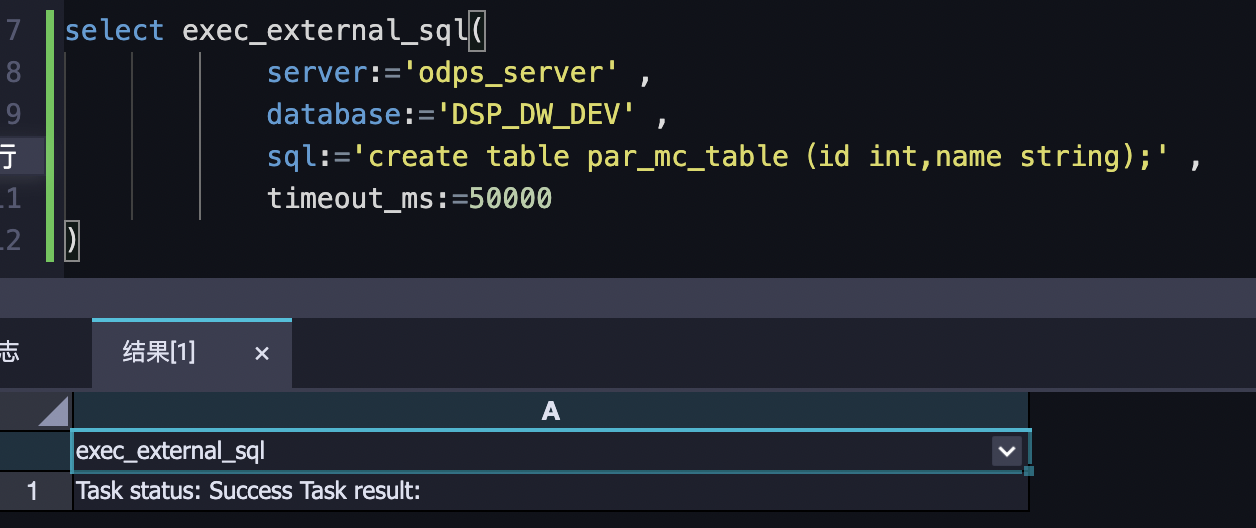
5.3.1. 在Holo执行MC(不实用)
建议只执行DDL,如果需要执行DML语句,请前往MaxCompute进行操作。
5.3.2. 外部表(MC中访问Holo表)
在MaxCompute中,通过外部表访问Hologres的表。
说明:在运行时,MaxCompute会通过JDBC接口,批量拉取Hologres对应表的所有数据到MaxCompute的查询作业中,会占用较多连接和计算资源,应避免在高并发场景使用外表查询。
应用场景:
- Hologres作为加工结果表:在MaxCompute中进行数据加工ETL,将加工后的数据直接写入Hologres外部表
- Hologres作为加工维度表:Hologres具备实时更新的能力,适合作为维度表的统一存储。事实表保存在MaxCompute中,维度表保存在Hologres中,MaxCompute在ETL加工过程中关联维度表数据进行关联分析。
限制:
- MaxCompute不支持对创建的Hologres外部表执行更新(UPDATE)、删除(DELETE)操作。
- 不支持分区表
- 使用并行方式向Hologres外部表写入大量数据,会小概率出现数据重复
案例:
create external table if not exists customer
(
c_custkey bigint NOT NULL,
c_name string NOT NULL,
c_address string NOT NULL
)
stored by 'com.aliyun.odps.jdbc.JdbcStorageHandler'
location 'jdbc:postgresql://hgpostcn-cn-g4t3fc54t007-cn-beijing-internal.hologres.aliyuncs.com:80/holo_tutorial?ApplicationName=MaxCompute¤tSchema=public&preferQueryMode=simple&useSSL=false&table=customer/'
tblproperties (
'mcfed.mapreduce.jdbc.driver.class'='org.postgresql.Driver',
'odps.federation.jdbc.target.db.type'='holo',
'odps.federation.jdbc.colmapping'='c_custkey:c_custkey,c_name:c_name,c_address:c_address'
);
-- 开启直读模式
set odps.table.api.enable.holo.table=true;
select * from customer limit 10;
-- 案例2:Holo外部表与MC内部表联合查询
set odps.table.api.enable.holo.table=true;
SELECT t1.* ,t2.*
FROM (
select * from customer
)t1
FULL JOIN (
select * from test
) t2
on t1.c_custkey = t2.id5.3.3. 外部表(Holo中访问MC表)
创建方法:
1、HoloWeb -> 元数据管理 -> MaxCompute加速

2、Dataworks -> DataStudio -> Hologres一键表结构导入
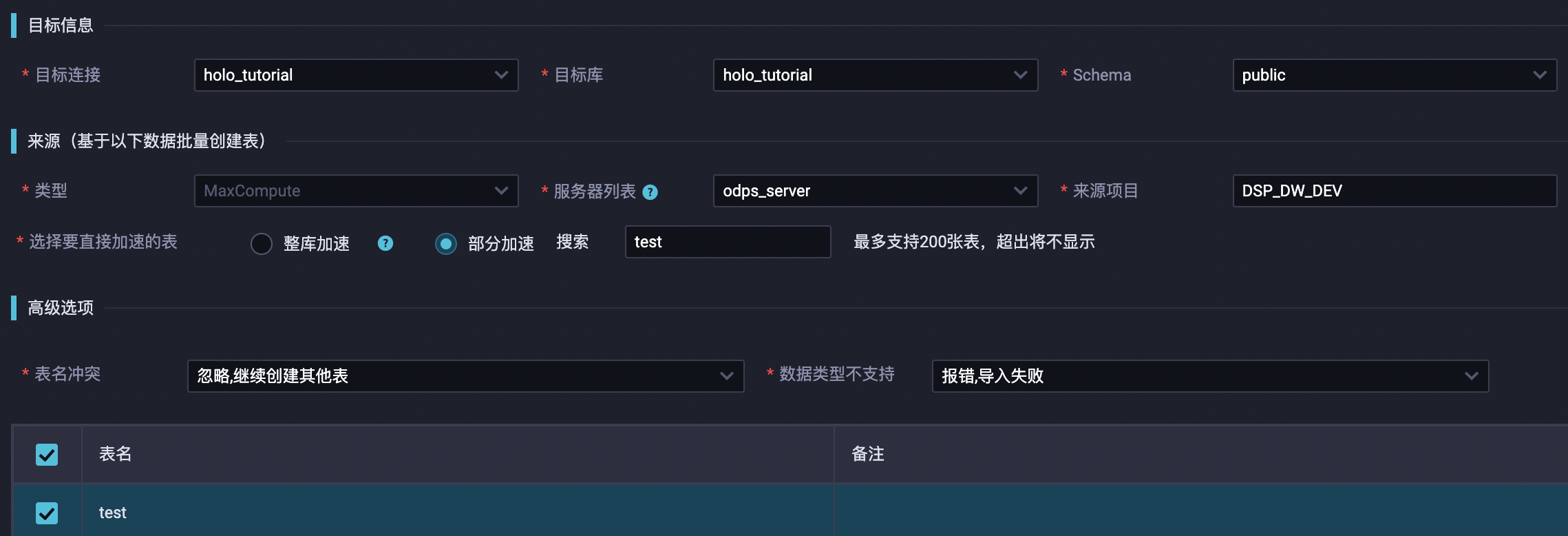
3、Dataworks -> Holo Studio -> 一键MaxCompute表结构同步

4、在Holo中执行建表语句
CREATE FOREIGN TABLE public.spm_log_di (
spm_time text,
app_id text,
app_ver text
)
SERVER odps_server OPTIONS (
project_name 'bigdata_spm_produce',
table_name 'spm_log_di'
);
COMMENT ON FOREIGN TABLE public.spm_log_di IS 'ods-埋点日志-天增量表';
COMMENT ON COLUMN public.spm_log_di.spm_time IS '事件触发时间';
COMMENT ON COLUMN public.spm_log_di.app_id IS '产品id';
COMMENT ON COLUMN public.spm_log_di.app_ver IS '产品版本';6. 性能调优
6.1. VACUUM & Analyze
6.1.1. 使用
-- 清理写入文件
vacuum nation;
-- 收集表的统计信息
analyze nation;
-- 针对非主键的JOIN KEY收集统计信息
analyze lineitem (l_orderkey,l_partkey,l_suppkey);
analyze orders (o_custkey);规格:32CU, 100g,数据量:1500w条,对hologres的性能消耗变化:
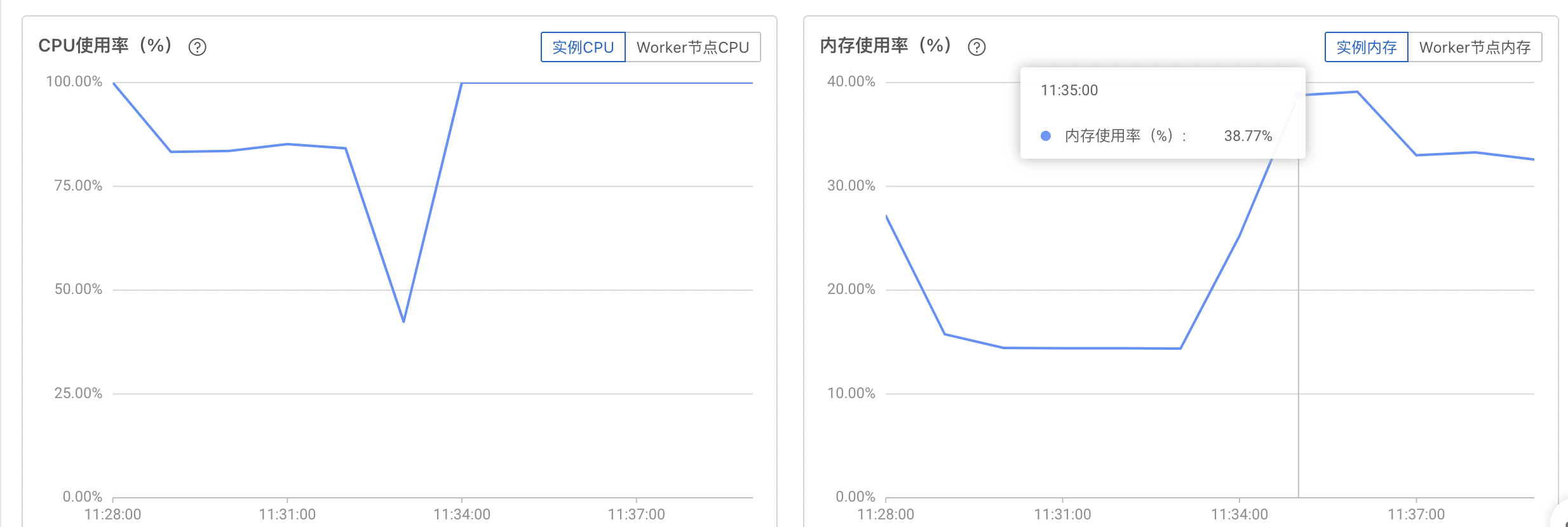
6.1.2. 查看Analyze的统计信息
-- 查最近一次Analyze的信息,根据analyze_timestamp排序即可。
SELECT schema_name, -- 表的Schema
table_name, -- 表名称
schema_version, -- 表的版本
statistic_version, -- 最近一次ANALYZE的统计信息版本
total_rows, -- 最近一次ANALYZE的行数
analyze_timestamp -- 最近一次ANALYZE的结束时间
FROM hologres_statistic.hg_table_statistic
WHERE table_name = '<tablename>'
ORDER BY analyze_timestamp DESC;Fixed Plan是Hologres独有的执行引擎优化方式,实现SQL执行效率的成倍提升,是支持高吞吐实时写入,高并发查询的关键优化方法
在Hologres中,默认走Fixed Plan的场景如下:
- Flink实时写入数据至Hologres。
- DataWorks数据集成实时写入数据至Hologres。
- Holo Client写入Hologres。
6.2. 执行计划
优化器(Query Optimizer,QO)会为每一条SQL生成一个执行计划,执行引擎(Query Engine,QE)会根据该执行计划生成最终的执行计划,然后执行并获取SQL结果。
- Explain:代表优化器QO根据SQL特征预估的SQL执行计划,并非实际的执行计划,对SQL的运行有一定参考意义。
- Explain Analyze:代表SQL真实的运行计划,相比Explain会包含更多的实际运行信息,能准确的反映出SQL的执行算子和算子耗时,可以根据算子耗时去做针对性的SQL优化。
参考:如何在Hologres中查看Explain和ExplainAnalyze
6.3. 自助健康检查常用命令
- 表规划检查
-
- 避免Table Group & Shard过多
- 检查表数量是否合理
- 检查表统计信息是否更新及时
- 避免过多资源组
- 表设计检查
-
- 有限使用行存表:行存表使用场景相对有限,主要用在Flink关联维表场景
- Distribution Key应明确设置,且不建议超过2列
- Dictionary Encoding不建议超过20列
- Bitmap Columns不建议超过30列
- Clustering Key不建议超过2列
- Segment Key最多仅设置一个实时写入时间戳相关列
- 数据TTL不建议小于7天
- 按需使用Binlog:行存表Binlog的开销会远小于列存表
- 避免数据倾斜性
- 运行态检查
-
- 资源使用检查:CPU、内存、连接数使用情况,通过云监控分析
- 查询成功率检查:不同类型Query的占比、成功率、延时、并发同比环比
- 慢查询检查
-
-
- 过去一天耗时最长的重点慢查询检查。
- 消耗资源最多查询的检查。
-
6.4. 性能分析
元仓- 慢Query查询与分析
- 慢Query日志默认保留一个月的数据,但是HoloWeb仅支持查最近7天的数据
- 查看query_log表
- HoloWeb可视化查看慢Query
- Query诊断
-
- 查询query_log总查询数
- 查询每个用户的慢Query情况
- 查询某个慢Query的具体信息
- 查询最近10分钟消耗比较高的Query
- 查看最近3小时内每小时的Query访问量和数据读取总量
- 查看与昨天同一时间对比过去3小时的数据访问量情况
- 查询最近10分钟Query各阶段耗时比较高的Query
- 查询最先失败的Query
- 查询query_log总查询数(默认为近1个月内的数据)。
- 慢Query日志导出
元仓-表统计信息查看与分析
- 表信息
- 授予权限查询
- 查询表统计信息趋势
-
- 查询表的数据的变化趋势
- 查询实例中存储量TOP的表
- 查看占用磁盘空间较大表的近期总访问趋势。
- 查看占用磁盘空间较大表的近期日访问情况与数据量变化。
- 查看占用磁盘空间较大表的近一周访问情况与数据量变化。
- 查看所有表中近一周访问较少表的磁盘占用。
- 查看涉及大表查询且时间较长的Query。
- 查看表最近一次修改表数据当天的行数变化。
- 查询小文件过多而导致占用磁盘空间大的表。
连接与SQL - Query管理
- 使用SQL查看活跃Query:查看SQL运行信息,更好的管理SQL语句。
- HoloWeb可视化活跃Query管理:通过HoloWeb可视化查看和管理活跃Query。
- 排查锁:通过活跃Query排查当前SQL是否有锁或者被锁。
- 终止Query:使用命令语句终止不符合预期的Query。
- 修改活跃Query超时时间:修改活跃Query运行超时时间,防止引发死锁。
- 修改空闲Query超时时间:修改空闲Query运行超时时间,防止引发死锁。
- 查询慢Query日志:通过慢Query的查询可以对慢Query或失败Query进行诊断、分析和采取优化措施。
连接与SQL - 连接数管理
- 查询实例的默认最大连接数:不同的实例规格对应不同的默认连接数,通过命令查询当前实例规格的最大连接数。
- HoloWeb可视化管理连接:通过HoloWeb可视化查看活跃连接,并进行管理如Kill等操作。
- 通过SQL查询连接信息:通过查询实例、DB的连接数、每个连接状态以及终止空闲连接,更好的管理实例。
- 释放连接:通过SQL函数,释放指定连接资源。
- 管理员预留连接:用于在连接数达到最大时对连接进行管理操作。
- 单个用户连接数限制:为单个用户设置连接数上限,以防止某个用户占用过多连接造成资源浪费。
- 自动释放空闲连接(Beta):开启自动释放空闲连接功能自动释放长期不使用连接。
- 连接数使用最佳实践:使用Hologres连接数的最佳实践建议。
连接与SQL - 锁以及排查锁
连接与SQL - 查看Worker倾斜关系
6.5. 性能调优
参考:性能调优
- 场景化建表调优指南
- 优化内部表的性能
- 写入或更新调优指南
- 优化MaxCompute外部表的查询性能
- Runtime Filter
- Key/Value查询场景最佳实践
- OOM常见问题排查指南
7. 运维
7.1. 实例选型及建议

参考:实时数仓Hologres实例规格介绍

7.2. 实例运维(升级\升配\降配)
Hologres版本升级:标准升级和热升级。 ===> 阿里通知
- 标准升级(停服升级):5~10分钟,升级期间服务不可;Flink写入hologres表需要停止任务
- 热升级:5~10分钟,升级期间系统处于只读状态;Flink写入hologres表需要停止任务
| 类别 | 升级支持 | 备注 | 场景 |
| 普通实例 | 支持标准升级(停服升级)、热升级 | ||
| 主从实例 | 支持标准升级(停服升级)、热升级 | 主从实例读写分离(共享存储) | |
| 共享集群 | 支持标准升级(停服升级) | Hologres共享集群(湖仓加速版)是原共享集群(MaxCompute BI加速)的升级版本 | 数据存储于MaxCompute 查询数据频率低、延时要求低的场景。 |
实例升配\降配,==> 自主操作

升配计算资源期间实例不可用,通常需要2-5分钟,请您耐心等待。请尽量在业务低峰期执行,建议应用具备重连机制。
使用技巧:
1、Holo版本升级会造成5~10分钟服务不可用,升配与降配,实例不可用,通常需要2-5分钟
2、小版本可配置自动升级 ---> 一般情况下关闭,防止因升级造成5~10分钟不可用
3、实例(升、降),尽量在业务低峰期执行
7.3. 权限模型
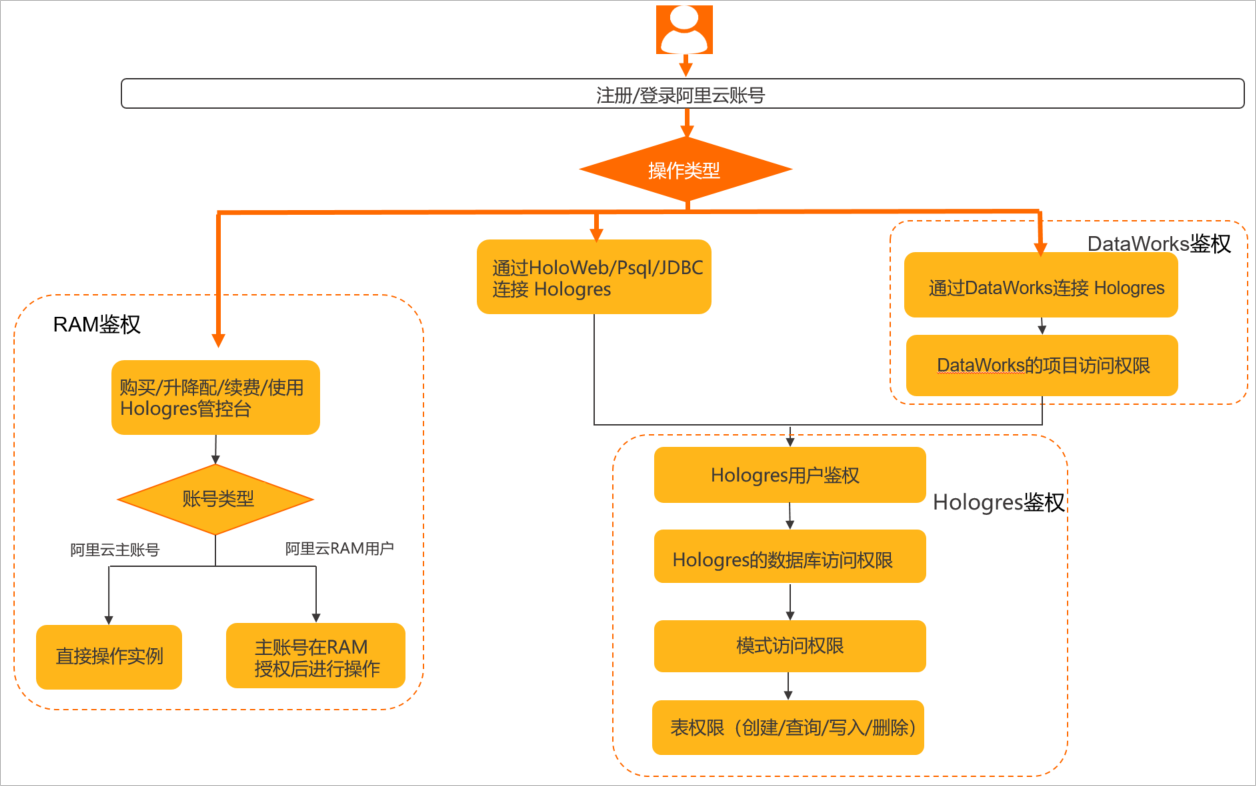
Hologres用户鉴权流程:
RAM鉴权:
授予阿里云提供的权限管理系统。RAM主要的作用是控制账号系统的权限,您可以通过RAM授权为不同的子账号分配不同的权限,包括实例购买、删除、升配、降配、修改网络类型、查看实例信息等权限,从而达到实例管理的目的。
Hologres鉴权
在使用Hologres实例进行开发之前,会经过如下几个层级的鉴权:
1、账号鉴权:(包括阿里云账号和RAM用户)、JDBC连接需要AccessKey ID及AccessKey Secret
2、用户鉴权:管理员执行了create user "xxx"命令,用户才会被创建进实例
3、实例鉴权:用户被创建进实例后,还需要被授予相关的操作权限,才能在权限范围内进行操作。

DataWorks鉴权
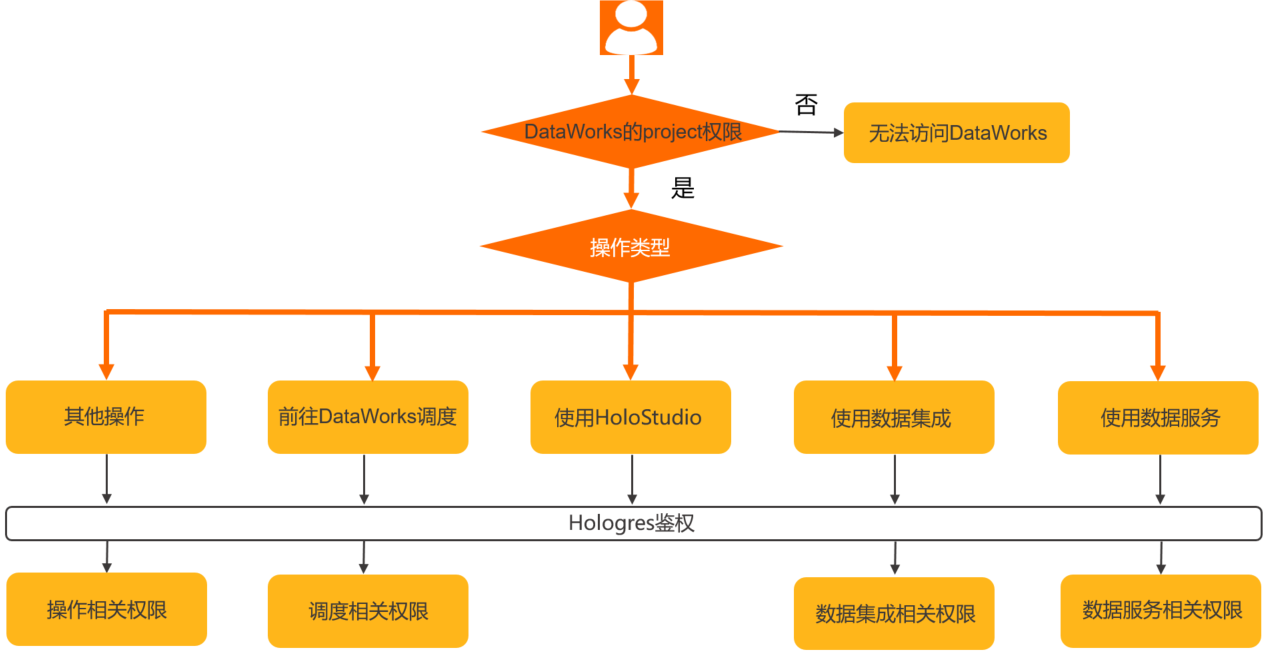
MaxCompute鉴权:

7.3.1. 用户
tips: 可通过执行select * from pg_user;命令查看当前实例的Superuser。
当一个阿里云账号连接Hologres时,需要被创建成为Hologres的用户(管理员需要执行create user "xxx",否则会报错role "xxx" does not exist),才能连接成功。用户属于实例级别,所以添加用户和删除用户相当于把用户创建进实例中或者从实例中删除。
- 超级管理员(Superuser):创建实例的拥有者
- 普通用户(Normal):除去Superuser之外的用户,需要Superuser授权
- 用户组:方便管理普通用户,参考:Postgres 数据库角色。
7.3.2. 权限模型
有三种:
- 专家权限模型(PostgreSQL)
- 简单权限模型(Simple Permission Model,SPM)
- Schema级别的简单权限模型(Schema-level Permission Model,SLPM)
关于RAM用户授权:
- RAM用户需要被主账号授权后才能访问实例。RAM用户也可以被授权为Superuser。
- 即使RAM用户拥有实例的购买权限,也必须经过主账号授予实例的开发权限后,才能在Hologres实例中进行数据开发。
具体参见:主账号如何使用权限模型授予RAM用户权限
建议使用Schema级别的简单权限模型,简单分为:
- 超级管理员:Superuser
- DB管理员:{db}.admin
- 开发者:{db}.{schema}.developer
- 读写者:{db}.{schema}.writer
- 分析师:{db}.{schema}.viewer
具体参见:在Hologres中基于Schema级别的简单权限模型
7.4. 资源隔离
单实例有2种方式:
1、计算组隔离(Beta):通过为不同业务场景分配不同计算组

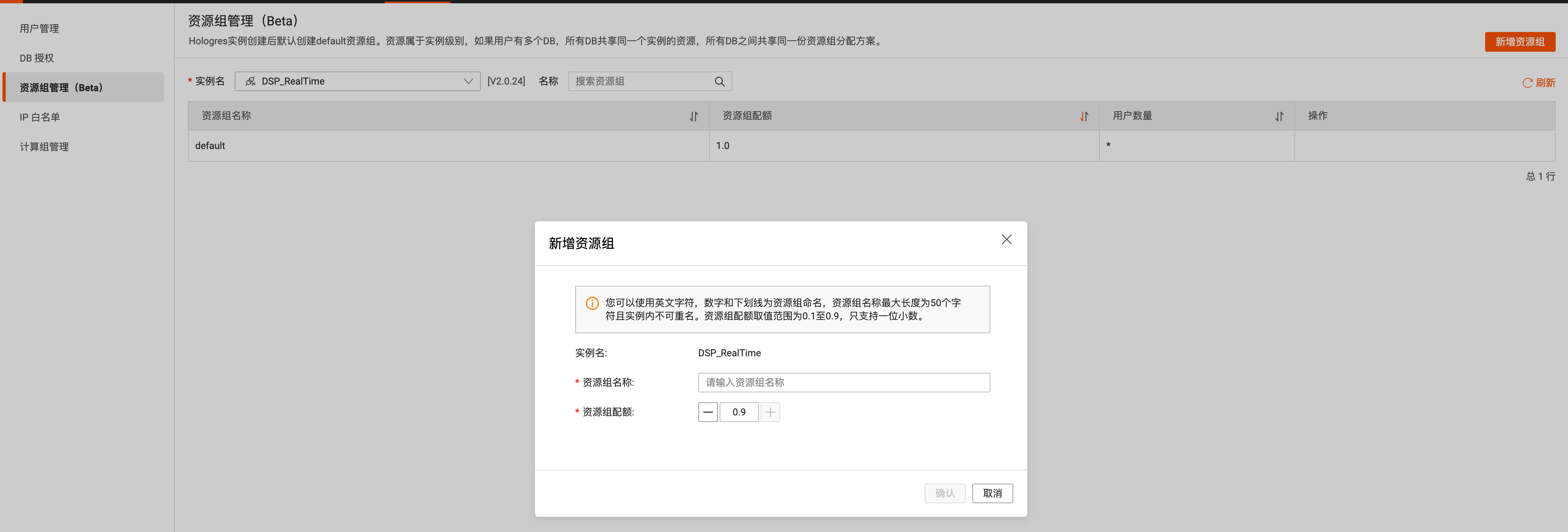
2、资源组隔离(Beta):通过为不同的用户账号分配不同的计算资源(即CU,包括CPU和内存),限制用户使用计算资源的上限,实现单实例多负载的隔离,保证了用户之间、应用之间作业的互不影响。
其他问题:
1、实时数仓 Hologres实例内的多个数据库,资源是抢占的吗?能隔离吗?
抢占的,实例内的多个数据库共享资源
7.5. 数据管理
1、备份与恢复(自动周期性快照、手动快照)
2、数据迁移
- (MySQL -> Hologres)单表、整库的实时离线迁移
- (Hologres -> Hologres)实例间全量、部分表全量迁移
3、存储优化(数据分层存储(冷、热),动态管理)
4、单个实例最多可创建64个数据库。
7.6. 告警监控
1、支持单指标、多指标组合监控模式
2、报警级别:
- 紧急:短信、电话、邮件、钉钉
- 告警:短信、邮件、钉钉
- 普通:邮件、钉钉
3、集成在云监控里面
4、默认建议配置告警:
- 如果连接数使用率(Info)连续3次平均值>=95就报警,通知对象为云账号报警联系人。
- 如果存储水位(Warn)连续3次平均值>90%就报警,通知对象为云账号报警联系人。
- 如果内存水位(Warn)连续3次平均值>=90%就报警,通知对象为云账号报警联系人
- 如果CPU水位(Info)连续3次平均值>=99%就报警,通知对象为云账号报警联系人
7.6.1. 内置告警
支持如下指标及必要性分析:
| 分类 | 指标 | 分析 |
| 实例 | 主从实例同步延迟(毫秒) | 单实例不需要 |
| CPU | CPU水位 | 需要 |
| Work节点CPU使用率 | 32CU有2个work,可以用于调优的告警 建议设置组合(CPU + WorkCPU) | |
| IO | 低频IO读\写 | 不需要 |
| IO读\写 | 需要 | |
| 内存 | 内存水位 | 需要 |
| work节点内存使用率 | 32CU有2个work,可以用于调优的告警 建议设置组合(内存+ WorkCPU) | |
| 存储 | 存储已用容量 | - |
| 存储水位 | 需要 | |
| 连接数 | 连接数 | 需要 |
| 连接数使用率 | ||
| FE连接数 | 需要 | |
| SQL总连接数 | ||
| 数据写入 | 实时写入RPS | |
| 每秒实时写入记录数 | ||
| 数据查询 | 每秒失败查询数 | |
| 正在运行Query持续时长 | ||
| Query延迟 | 非必要 -对重要业务进行监控 | |
| DML | Delete语句QPS | |
| Delete语句响应时间 | ||
| Delete语句响应时间 | 慢SQL处理 | |
| 每秒Delete记录数 | ||
| Insert语句QPS | ||
| Insert语句响应时间 | 慢SQL处理 | |
| 每秒Insert记录数 | ||
| Select语句QPS | 业务并发处理 | |
| Select语句响应时间 | 慢SQL处理 | |
| Update语句QPS | ||
| Update语句响应时间 | ||
| 每秒Update记录数 |
7.6.2. 告警实践总结
需求1:反映了Hologres的资源是否存在瓶颈,也反映了您的资源使用是否充分。
1、CPU水位
规则:CPU水位连续3次>=99% Info(每次间隔5分钟)
2、内存水位
内存水位连续3次>=90% Warning(每次间隔5分钟)
需求2:对无法连接的异常影响业务
1、连接数使用率
说明:一般连接数在总连接数的95%以下都算安全。
规则:连接数使用率(Info)连续3次>=95就报警
需求3:慢SQL性能
1、P99延迟
SQL语句从提交到返回的过程中,Hologres引擎处理99%查询语句的时间。
响应时间异常性变大反映出系统可能有慢Query的趋势,可能会影响下游业务处理。
例如您是持续服务型应用,平常的正常延迟都在1s以内,那么响应时间突然到5s或10s,就不太正常,需要告警出来,偶尔到1.2s,1.5s,则正常。
例如您是分析性应用,根据不同业务人员的需求,查询的大小、响应时间都不尽相同,那么就需要根据自己的场景进行设置。
2、Query QPS
当QPS突然降到很低,或者为0时,如果不是业务有意停止,那么可能意味着系统有异常。
| (推荐)Query QPS明细 | 实例每秒SQL语句执行数。 |
| SELECT语句QPS | 实例每秒SELECT语句数。 |
| INSERT语句QPS | 实例每秒INSERT语句数。 |
| UPDATE语句QPS | 实例每秒UPDATE语句数。 |
| DELETE语句QPS | 实例每秒DELETE语句数。 |
规则设置为:QPS连续3次<=(A*0.8) Warning(每次间隔5分钟)
需求4:实例规格监控
实时写入RPS
有持续的外部数据导入(通过Flink/数据集成等等)时,往往有持续的实时导入RPS(Record Per Second)指标。RPS突然降到很低,或者为0时,如果不是作业有意停止,那么可能意味着系统有异常。
设置告警为:RPS(cmdType=sdk)连续1次<=10 Warning
实例CPU使用率
- 在没有查询的时候,后台常驻进程或者异步执行的Compaction都可能占用CPU,因此实例无查询负载时,有少量CPU使用率是正常现象。
- 当实例CPU使用率长期接近100%时
-
- 1、是否有比较大的离线数据导入(INSERT),且数据规模还在日渐增长。
- 2、是否有高QPS的查询或写入,共同用满了CPU。实例CPU使用率
Worker节点CPU使用率
- 当实例内所有Worker节点CPU使用率都长期接近100%时,说明实例的负载非常高,需要根据业务情况合理的优化资源使用或者扩容。
- 当实例只有部分Worker节点CPU水位比较高,部分Worker节点CPU水位较低,说明Worker资源有倾斜
7.6.3. 指标:内存使用率(%) -- D
计算内存:
Hologres把计算内存分为了三块:
- 一是预留给计算的内存,约占30%,没有计算时,这块几乎为0;
- 二是数据缓存,在诸多情况下,数据缓存可以极大地减少I/O读取,提高SQL的计算效率,约占30%
- 三是实例中所有表、索引等元数据缓存,以及表在内存中的句柄和缓冲区等,约占30%。
实例内存使用率说明:
- Hologres的内存资源采用预留模式,在没有查询的时候,也会有数据表的元数据、索引、数据缓存等加载到内存中,以便加快检索和计算,此时内存使用率不为零是正常情况。理论上,在无查询的情况,内存使用率达到30%-40%左右都属于正常情况。
- 当内存使用率稳定增长,长期接近80%时,通常意味着内存资源可能成为了系统的瓶颈,可能会影响实例的稳定性或性能。
Worker节点内存使用率
- 当实例內所有Worker节点的内存水位都长期接近80%时,说明实例的负载非常高,需要根据业务情况合理的优化资源或者扩容。
- 当实例只有部分Worker节点内存水位比较高,部分Worker节点内存水位较低,说明Worker资源有倾斜