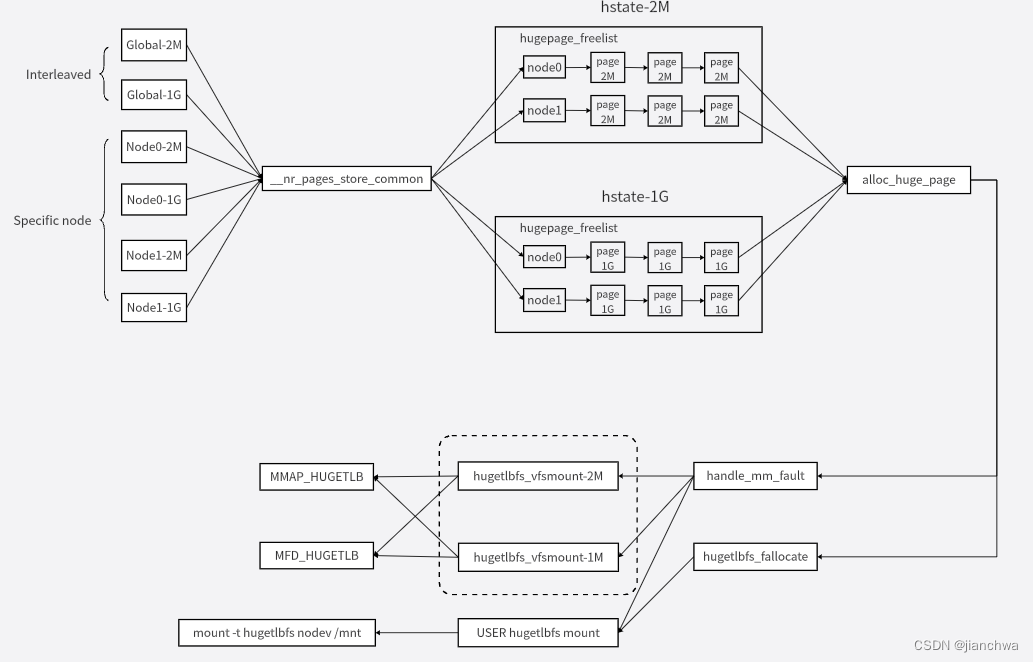
PyQuery库是一个基于jQuery语法的Python库,它可以方便地对HTML/XML文档进行解析和操作。使用PyQuery库可以快速地获取网页中的数据,进行数据清洗和分析。PyQuery库的基本用法包括字符串初始化、打开网页、css属性、标签内容等获取、DOM基本操作等相关技巧与使用注意事项。此外,PyQuery库还支持伪类选择器,可以方便地进行节点的筛选和操作。如果结合requests库使用,可以方便地进行网页抓取和数据分析。

我可以为您编写一个使用PyQuery库的爬虫程序,该爬虫程序可以爬取https://cloud.tencent.com/的内容。
# 导入所需的库
import requests
from pyquery import PyQuery as pq
# 设置爬虫IP
proxy = {'http': 'http://www.duoip.cn:8000', 'https': 'http://www.duoip.cn:8000'}
# 发送GET请求
response = requests.get('https://cloud.tencent.com/', proxies=proxy)
# 使用PyQuery解析返回的HTML内容
doc = pq(response.text)
# 找到想要爬取的内容,这里以标题为例
titles = doc('h2')
# 打印结果
for title in titles:
print(title.text())
以上代码会使用爬虫IP从https://cloud.tencent.com/上爬取标题内容,并打印出来。
注意:在使用爬虫IP时,需要确保爬虫IP是可用的,并且符合相关法律法规。同时,爬虫程序的使用也应遵守网站的robots.txt协议,尊重网站的权益。


![[计算机提升] Windows系统软件:娱乐类](https://img-blog.csdnimg.cn/c20ee553600d401c94c476568deafcac.png)