
文 | 智能相对论
作者 | 沈浪
全球人工智能产业正被限制在了名为“算力”的瓶颈中,一侧是供不应求的高端芯片,另一侧则是激战正酣的“百模大战”,市场的供求两端已然失衡。
然而,大多数人的关注点仍旧还是在以英伟达为主导的高端芯片领域。
半导体的创新固然关键,但是从现实处境来讲,芯片从造出来到用起来,是一个庞大的系统工程,市场更需要一条能暂时绕开半导体创新的系统创新的技术路径,来同步释放算力,以满足现阶段爆发性的算力需求以及后期可持续的常态发展。
遵循着这一思路,就不难发现,以浪潮信息为代表的本土厂商已经开始了另一条释放算力的创新路径,即对服务器等硬件的基础架构进行创新,在硬件层面“拓荒”,“压榨”更多的硬件性能,打破算力桎梏。
只是这样的路径,似乎没有想象中的那么简单、轻松。
01 向底层“拓荒”,激活“牛鞭效应”
以服务器为例,一台服务器有超过10000个零部件,同时还涉及30多个技术领域,包括材料学、热力学、电池技术、流体力学、化学等一系列学科。此外,一台服务器里还会应用超过100种传输协议。其制造过程更是需要经历30多道流程,使用100多种加工和制造工艺等等。
若要对这样的高精密硬件的基础架构进行创新,绝非易事。
在四五年前,一些大规模数据中心用户几乎都遇到过一个相似的问题:风扇转速越快,硬盘越有可能出现性能波动,严重时还会直接掉线,非常影响硬盘的读写性能。
浪潮信息的工程师团队做了大量实验,最终锁定原因:风扇产生的噪音一旦达到120分贝,就非常容易造成硬盘磁头偏移、读写效率下降,进而导致扇区失效乃至硬盘报废、服务器宕机。
尽管这样的问题看起来很小,却对服务器的性能有着严重制约。如何解决服务器内部的风噪问题,成为了一个业内共同探索的议题。国际开放计算社区OCP组织成员包括FaceBook(现为Meta公司)、微软、浪潮信息、戴尔等企业,共同发起Storage Vibration(存储设备振动)项目,旨在解决相关的问题。

最终,浪潮信息的工程师们基于大量机理性研究和测试,发现了硬盘性能损失与声压强度间的数学规律,并构建出业界首个硬盘敏感度模型,量化出不同硬盘受到各类噪声影响后的性能表现。
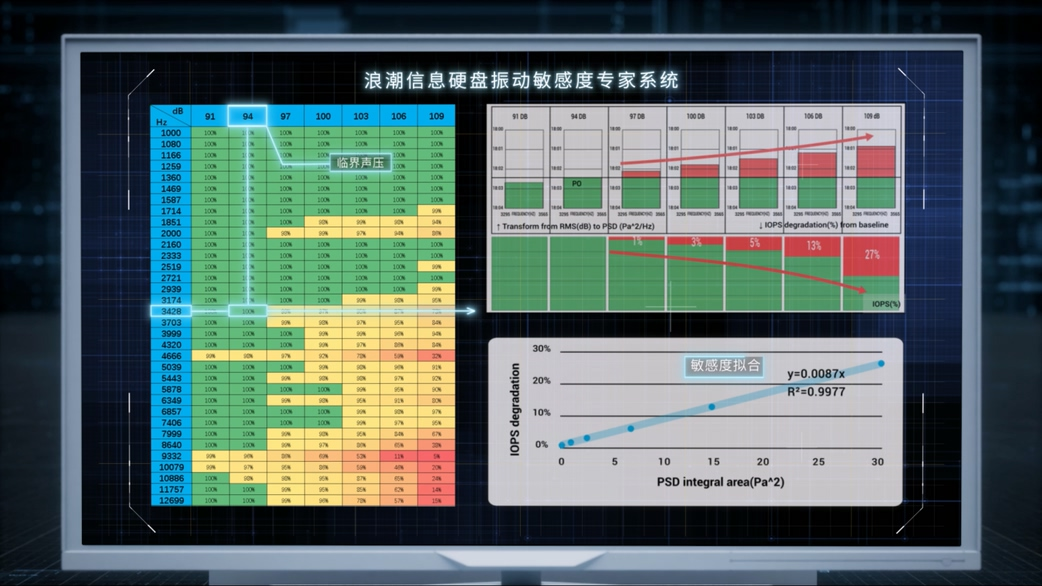
以此为依据,浪潮信息也得以对最新G7服务器系统进行了全方位的优化设计,譬如通过CFD流体动力学仿真改进·不同机箱布局下的风扇的叶片形态,抑制扇叶表面因涡流脱落形成的高频噪音,提升硬盘读写效率50%;或是在机箱内通过设计40多种歌院式的消音结构,消除特定的高频噪声等等。
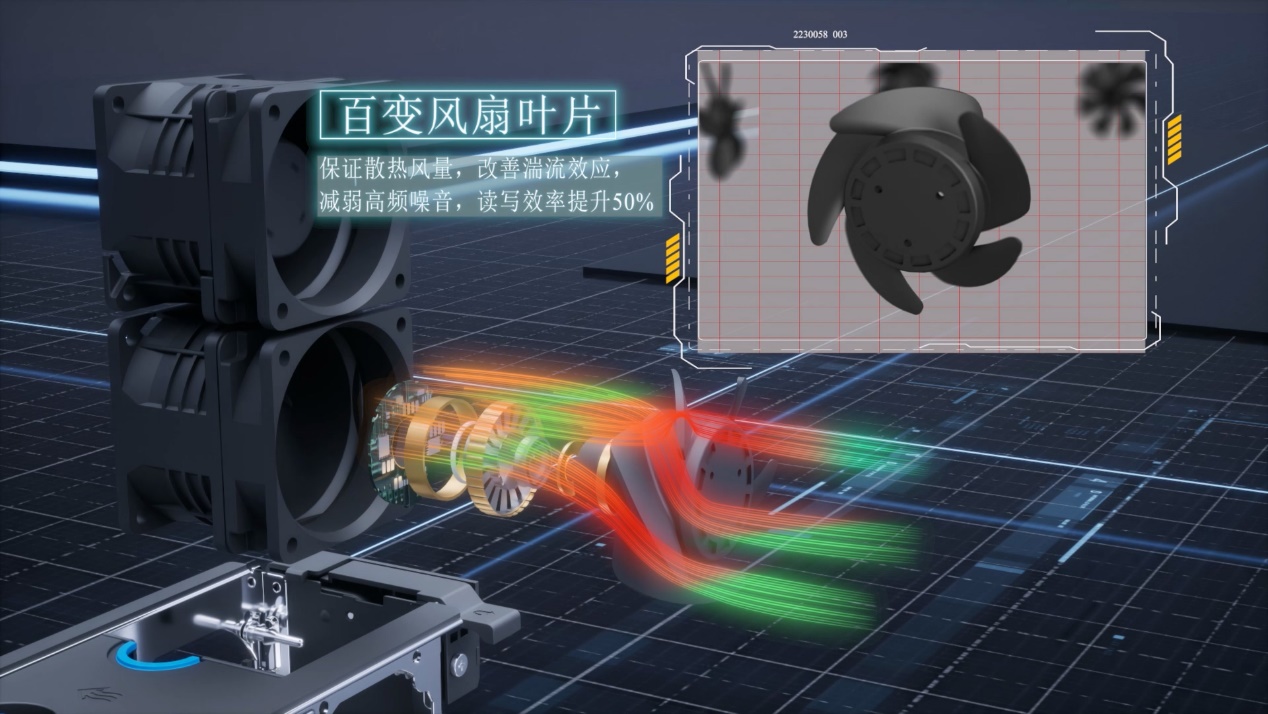
这些“绣花针”功夫是创新底层架构的关键,而看似很微小的基础改良,却是提升服务器性能、保障硬件平稳运行的重要因素。在经济学领域,有一个专业术语叫作“牛鞭效应”,指一端微小的摆动被不断放大,到了另一端将演变为大幅摆动的趋势。
从硬件的应用来看,基础部件的改良也将激活“牛鞭效应”——从一张硬盘到一个服务器,再到一个数据中心,随着硬件不断叠加应用,底层的改良价值将被逐步放大,向上层传递,成为服务器安全运作、释放算力、促进人工智能产业发展的重要保障。
类似的,现阶段备受关注的芯片互联技术,也是支撑大模型大规模算力场景的关键技术,尤其是单个服务器内部芯片高速直连,是实现大规模算力集群高效协同工作的基础。作为全球领先的服务器厂商,浪潮信息在高速互连领域定义了业界第一个符合OAM(开放加速模块)规范的8卡互连硬件系统,解决了高速信号的速率提升和信号失真问题,实现开放加速规范下芯片互连的最高速率,助力着人工智能产业的持续突破。

02 一场对性能的极限“压榨”
在人工智能行业,算力的巨大需求和供给紧张已然是摆上台面的事实。为什么业内厂商想要不断地改进传统的硬件架构去释放算力,哪怕只是一点细微的声噪优化,都不遗余力地花上四五年的时间去研究、探索和创新。
细究来说,算力的供应大抵可以归结为两条路径,一是“增量拓展”,比如接入更多的服务器、建更多的数据中心,通过“堆量”的方式来提供更多的算力。二是“存量优化”,对原有架构、原有机器进行优化升级,通过“提质”的方式来把性能和效率提升起来。
其中,在这两条路径之下,“存量优化”又是必然的一条。无关乎未来算力是否紧张或宽裕,如何对现有的机器和架构进行升级优化,是行业发展的一个重要阶段,只是时间早晚的问题。
值得一提的是,现阶段,服务器行业已经有着充分的理由去推进“存量优化”这一路径。
一方面,算力领域正在面临着高端芯片紧张的问题,“增量拓展”被限制,那么业内厂商就不得不考虑“存量优化”的事情。
另一方面,源于服务器的特殊性,在服务器概念上的简单的“堆量”只能堆出各种形态和规格的服务器,但对数据中心计算能力的提升并没有什么实质性的帮助。
对此,在2014年,浪潮信息提出了“融合架构”的技术理念,旨在创造一种新的体系架构,将硬件设备中的同类资源整合成一个资源池,即便是不同的设备也能够任意地整合,再通过软件动态感知业务的资源需求,从而利用硬件重组的能力来满足各类应用的性能需求。

这种“融合架构”看似是“增量拓展”,但核心则是“存量优化”。直到融合架构3.0的发布,就可以清晰地看到,这一技术理念打破了现有服务器的逻辑架构和应用模式,实现了整机柜级别的计算、内存、存储与互联等各种IT资源的池化,形成了以系统设计为中心的新架构模式,对构建高速高性能的互联网络起到了重要作用。
简单来说,基于“池化”的概念,融合架构3.0将服务器内的计算资源、存储资源、内存资源、异构加速资源等核心IT资源重新细化,并做了“重组”,从而能使其发挥出更高的性能和应用价值。

这相当于对现有的服务器性能做了一次极限地“压榨”。众所周知,传统服务器的性能利用率是无法达到100%,两台服务器相连得到大多是1+1<2结果,而基于融合架构3.0的支持,就有可能实现1+1>2的情况。
当然,这只是一个便于理解的理想化公式,现实大抵是达不到这个效果的。但是,其中的进步也是看得见的,特别是随着服务器的增加,当我们再来估算1+1+1+...+N的效果时,在融合架构3.0下的服务器便能发挥出远超传统架构的性能和价值。
这是融合架构3.0的价值展望,同时也是“存量优化”这一路径在服务器行业的价值呈现。正如上文提及的“牛鞭效应”,当底层细微的创新不断被放大到一个硬件、一个计算集群、一个产业生态,那么其发挥出来的作用将远超过往。
03 在算力之外
当前,在服务器行业,就能看到类似的信号。
继续以融合架构3.0为例,其打破了以往“以CPU为中心”的设计理念,从整体出发,以系统为中心,通过硬件解耦将异构计算、内存、存储等资源转变为可独立扩展的资源池。
在这个过程中,不仅实现了亚微秒级远端内存访问,并且还构建出了一种逻辑上可远端共享的内存资源池,让多台主机访问同一个内存池,从而大大提高了数据交换的效率,让Spark、Hadoop和机器学习等使用分布式数据框架的应用,能够更顺畅地实现框架内各节点间的数据交换与协作。
也就是说,融合架构3.0解决的不仅仅是服务器性能、算力释放等问题,实际上还继续向上层拓展,解决了系统应用的问题——服务器的架构创新在算力之外,带来了全新的价值呈现。
类似的,放眼全球市场,微软与英伟达合作推出的虚拟机Azure ND H100 v5 VM系列,正基于强大的硬件能力支持结合Quantum-2InfiniBand网络互连,从而帮助企业更好、更高效地处理生成式AI任务。
现阶段,大多数硬件升级并非单线的,而是考虑到上层的应用需求,如大模型训练、生成式AI任务等,结合软件系统、网络服务等进行融合创新,从而为应用场景服务。
纵观当前人工智能产业在算力层面的困顿处境,以算力牵动整个人工智能产业的发展是必然的趋势。而业内厂商在解决算力供给问题的过程,也将同步带动其他模块的升级。换句话说,解决算力问题就不能局限在高端芯片领域,更要从其他的路径寻求多元化的发展。
在这个阶段,以英伟达为主导的高端芯片领域和以浪潮信息为代表的服务器硬件升级,都将站在市场的聚光灯下。今天的市场,需要更多元、更勇敢、更执着的探索者、创新者。
*本文图片均来源于网络
#智能相对论 Focusing on智能新产业新服务,这是智能的服务NO.247深度解读
此内容为【智能相对论】原创,
仅代表个人观点,未经授权,任何人不得以任何方式使用,包括转载、摘编、复制或建立镜像。
部分图片来自网络,且未核实版权归属,不作为商业用途,如有侵犯,请作者与我们联系。
•AI产业新媒体;
•澎湃新闻科技榜单月度top5;
•文章长期“霸占”钛媒体热门文章排行榜TOP10;
•著有《人工智能 十万个为什么》
•【重点关注领域】智能家电(含白电、黑电、智能手机、无人机等AIoT设备)、智能驾驶、AI+医疗、机器人、物联网、AI+金融、AI+教育、AR/VR、云计算、开发者以及背后的芯片、算法等。









![[计算机提升] Windows系统软件:娱乐类](https://img-blog.csdnimg.cn/c20ee553600d401c94c476568deafcac.png)