如何通俗理解扩散模型? - 知乎泻药。实验室最近人人都在做扩散,从连续到离散,从CV到NLP,基本上都被diffusion洗了一遍。但是观察发现,里面的数学基础并不是模型应用的必须。其实大部分的研究者都不需要理解扩散模型的数学本质,更需要的是对…![]() https://zhuanlan.zhihu.com/p/563543020Stable Diffusion原理解读 - 知乎引言最近大火的AI作画吸引了很多人的目光,AI作画近期取得如此巨大进展的原因个人认为有很大的功劳归属于Stable Diffusion的开源。Stable diffusion是一个基于Latent Diffusion Models(潜在扩散模型,LDMs)的文…
https://zhuanlan.zhihu.com/p/563543020Stable Diffusion原理解读 - 知乎引言最近大火的AI作画吸引了很多人的目光,AI作画近期取得如此巨大进展的原因个人认为有很大的功劳归属于Stable Diffusion的开源。Stable diffusion是一个基于Latent Diffusion Models(潜在扩散模型,LDMs)的文…![]() https://zhuanlan.zhihu.com/p/583124756
https://zhuanlan.zhihu.com/p/583124756
stable diffusion的出现极大的推动了文生图,图生图等领域的进展,我之前也解析过dalle2,文生图领域目前的论文还是非常多的,stable diffusion整体上最大的贡献还是极大的加速了diffusion的落地,扩散模型,是vae的延续,ae中的v其实就是通过kl散度来向ae中添加噪声,扩散则是就这个加噪的过程和马尔科夫过程关联起来,将加噪分步了。stable diffusion基于latent diffusion model,首先需要训练一个自编码器,包括一个编码器和一个解码器,利用编码器对图片进行压缩,然后在潜在表示空间上做diffusion操作,最后利用解码器恢复到原始像素空间即可。称之为感知压缩perceptual compression。在潜在表示空间上做diffusion操作其主要过程和标准的扩散模型没有太大的区别,所用到的扩散模型具体实现为time-conditional unet。论文为diffusion操作引入了条件机制,通过cross-attention的方式来实现多模态训练,使条件图片生成也可以实现。
结合上面的材料稍微解析一些diffusion。
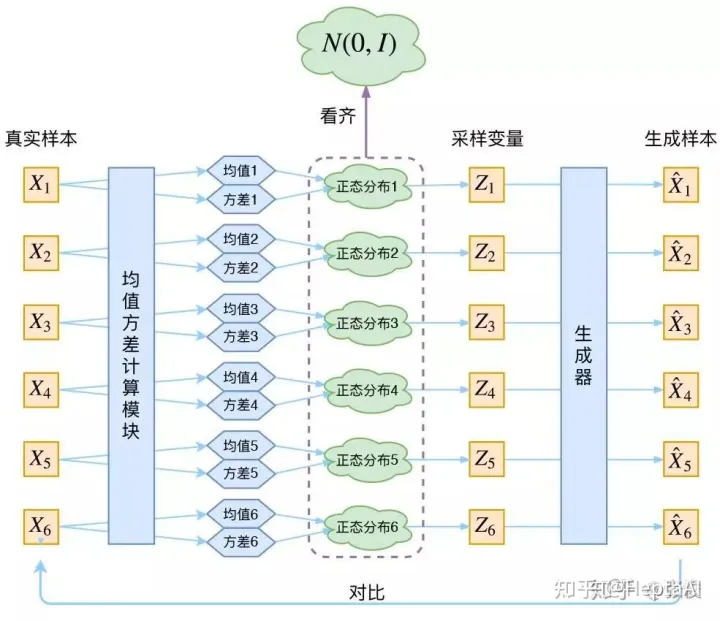
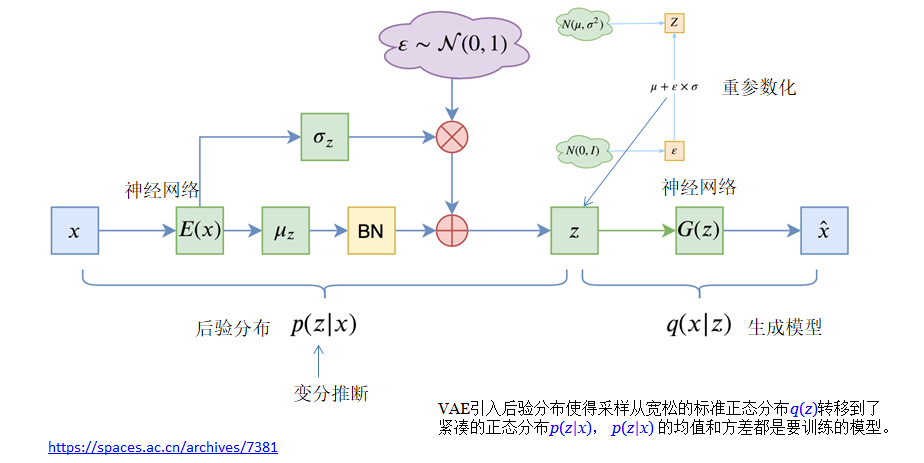
上面这个是vae,vae的最大问题是变分后验,在vae中,我们先定义了右边蓝色的生成器,再学一个变分后验来适配这个生成器,先验分布是标准高斯分布。vae的生成器,是将标准高斯映射到数据样本,vae的后验是将数据样本映射到标准高斯(学出来的)。我现在想要设计一种方法A,使得A用一种简单的变分后验将数据样本映射到标准高斯,并且使得A的生成器,将标准高斯映射到数据样本,注意,因为生成器的搜索空间大于变分后验,vae的效率远不及A方法,因为A是学一个生成器(搜索空间大),所以可以直接模仿这个后验分布的一小步,A方法就是括但模型核心思路:定义一个类似于变分后验的从数据样本到高斯分布的映射,然后学一个生成器,这个生成器模仿我们定义的这个映射的每一小步。vae是数据样本->高斯->数据样本,扩散是数据样本->一小步一小步的扩散->高斯->去噪->数据样本。
abstract:通过将图片合成过程分解为顺序去噪自编码器(a sequential application of denosing autoencoders),diffusion models实现了广泛的应用。此外,dms允许一种引导机制来控制图像生成过程无须训练。但是在像素空间中运行对算力要求过高。
1.introduction
高分辨率,复杂自然场景下的图像合成目前是被scaling up likelihood-based models所主导,这些模型可能在自回归transformer中有上亿参数量。对比Gans已被证明主要局限于具有相对有限可变性的数据,他们的对抗学习过程不容易扩展到建模复杂的多模态分布。dms属于基于似然的模型类别。训练一个dms通常需要数百个gpu days,150-1000 V100 days。
任何一个基于似然的模型,学习大致可以分为两个阶段。1.是感知压缩阶段,它会去除高频细节,但仍然学习很少的语义变化,2.实际生成模型学习数据的语义和概念组成(语义压缩)。我们将训练分为两个阶段,首先训练一个自动编码器,它提供一个低维的表示空间,在感知上等同于数据空间,其次在学习的潜在空间上训练dm,将生成模型成为潜在扩散模型ldm。这种方式的优点在于我们只需要训练通用的自动编码器一次,就可以重复用于多次dm训练。
2.methods
2.1 perceptual image compression
由此可知,基于感知压缩的扩散模型的训练本质上是一个两阶段训练的过程,第一阶段需要训练一个自编码器,第二阶段才需要训练扩散模型本身。在第一阶段训练自编码器时,为了避免潜在表示空间出现高度的异化,作者使用了两种正则化方法,一种是KL-reg,另一种是VQ-reg,因此在官方发布的一阶段预训练模型中,会看到KL和VQ两种实现。在Stable Diffusion中主要采用AutoencoderKL这种实现。

2.2 latent diffusion models
扩散模型是一个时序去噪自编码器,其目标是根据输入xt去预测一个对应去噪后的变体,xt是输入x的噪声版本。而潜在扩散模型中引入了预训练的感知压缩模型,它包括一个编码器和一个解码器,这样在训练时就可以用编码器得到zt,从而让模型在潜在表示空间中学习。与高维空间比,降维空间更适合基于似然的生成模型,因为1.可以专注于数据的重要语义,低维空间中高频的细节被抽象掉了,2.在低维空间中可以进行更有效的计算。
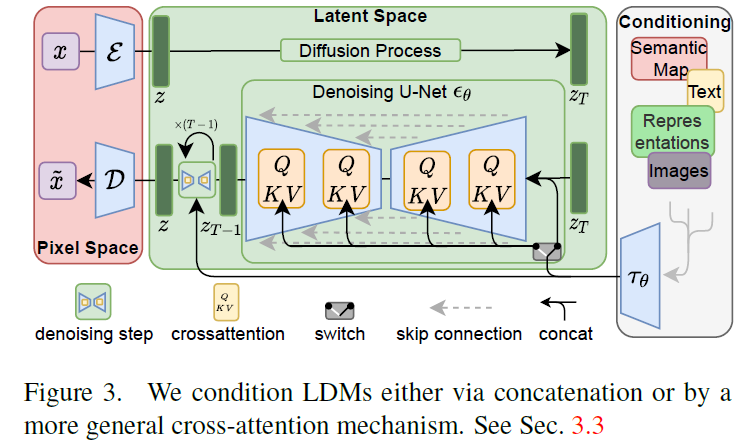
2.3 条件机制

后续就是作者的一系列实验了,整体来说作者基于latent的先验自编码器,训练一个dm,发现这样做的效果也非常好。