什么是注意力机制
注意力机制是深度学习常用的一个小技巧,它有多种多样的实现形式,尽管实现方式多样,但是每一种注意力机制的实现的核心都是类似的,就是注意力。
注意力机制的核心重点就是让网络关注到它更需要关注的地方。
当我们使用卷积神经网络去处理图片的时候,我们会更希望卷积神经网络去注意应该注意的地方,而不是什么都关注,我们不可能手动去调节需要注意的地方,这个时候,如何让卷积神经网络去自适应的注意重要的物体变得极为重要。
注意力机制就是实现网络自适应注意的一个方式。
一般而言,注意力机制可以分为通道注意力机制,空间注意力机制,以及二者的结合。
1.SENet介绍
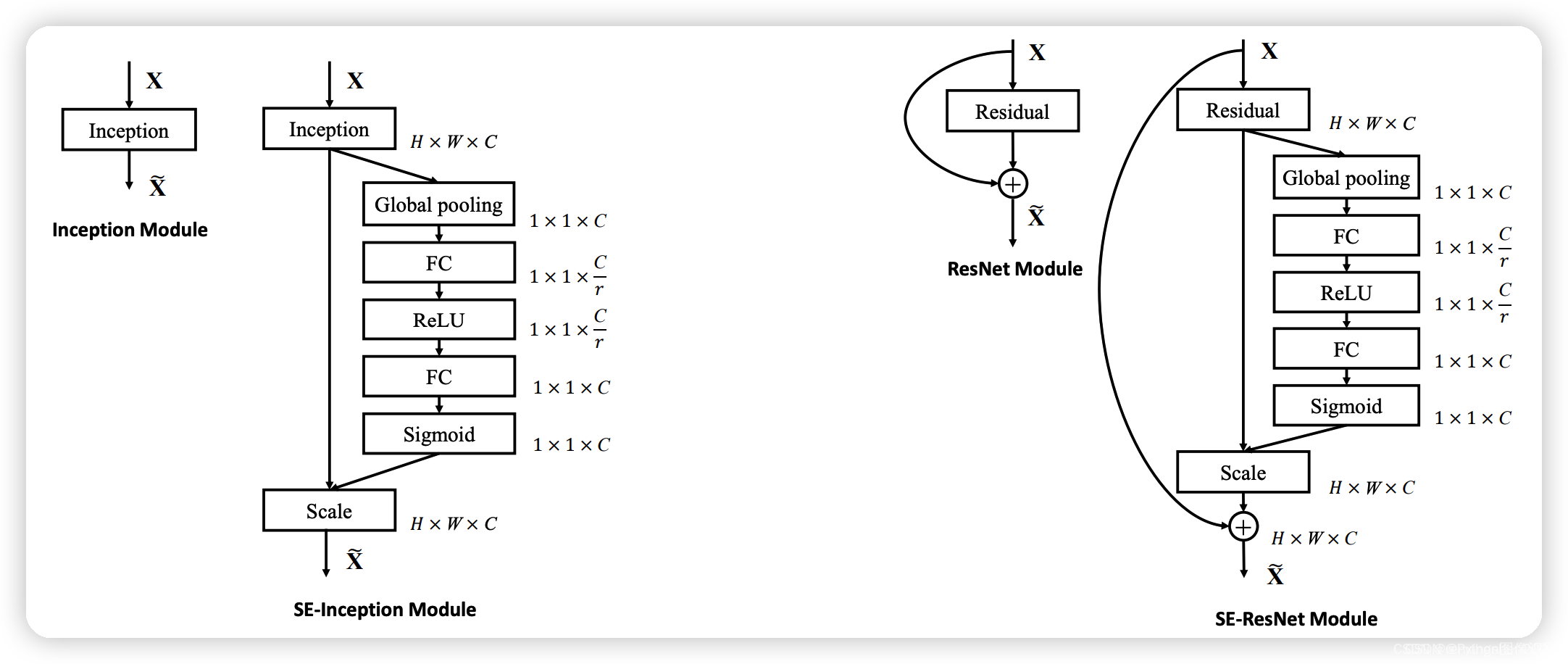
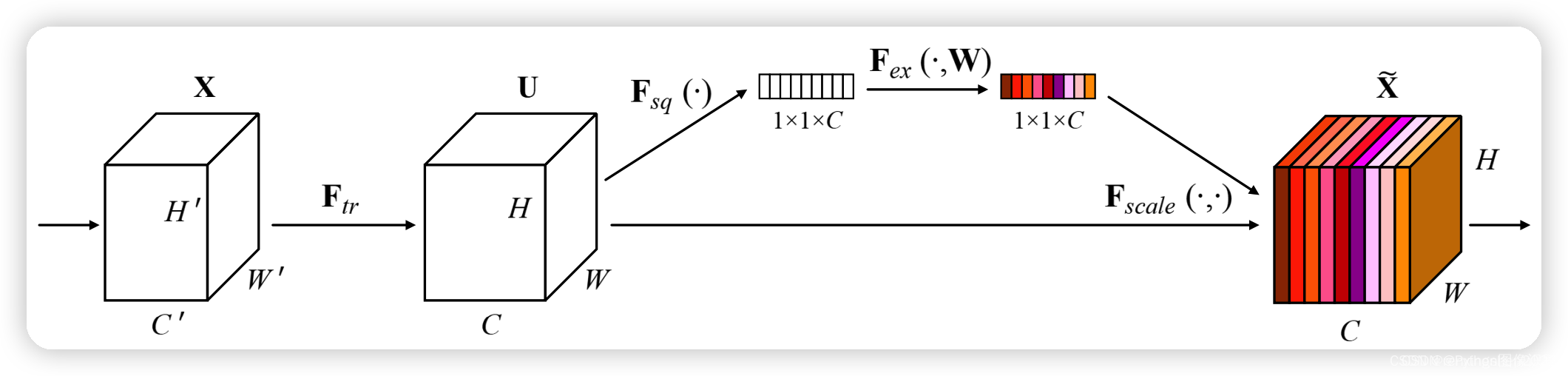
SE注意力模块是一种通道注意力模块,SE模块能对输入特征图进行通道特征加强,且不改变输入特征图的大小。
-
SE模块的S(Squeeze):对输入特征图的空间信息进行压缩
-
SE模块的E(Excitation):学习到的通道注意力信息,与输入特征图进行结合,最终得到具有通道注意力的特征图
-
SE模块的作用是在保留原始特征的基础上,通过学习不同通道之间的关系,提高模型的表现能力。在卷积神经网络中,通过引入SE模块,可以
动态地调整不同通道的权重,从而提高模型的表现能力。
实现方式:
1、对输入进来的特征层进行全局平均池化。
2、然后进行两次全连接,第一次全连接神经元个数较少,第二次全连接神经元个数和输入特征层相同。
3、在完成两次全连接后,我们再取一次Sigmoid将值固定到0-1之间,此时我们获得了输入特征层每一个通道的权值(0-1之间)。
4、在获得这个权值后,我们将这个权值乘上原输入特征层即可。
实现代码
import torch
from torch import nn
class SEAttention(nn.Module):
def __init__(self, channel=512, reduction=16):
super().__init__()
# 对空间信息进行压缩
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# 经过两次全连接层,学习不同通道的重要性
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
# 取出batch size和通道数
b, c, _, _ = x.size()
# b,c,w,h -> b,c,1,1 -> b,c 压缩与通道信息学习
y = self.avg_pool(x).view(b, c)
# b,c->b,c->b,c,1,1
y = self.fc(y).view(b, c, 1, 1)
# 激励操作
return x * y.expand_as(x)
if __name__ == '__main__':
input = torch.randn(50, 512, 7, 7)
se = SEAttention(channel=512, reduction=8)
output = se(input)
print(input.shape)
print(output.shape)
SE模块是一个即插即用的模块,在上图中左边是在一个卷积模块之后直接插入SE模块,右边是在ResNet结构中添加了SE模块。