🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客
🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。
🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频
目录
背景
问题复原
问题排查和定位
问题思考
问题解决
... ...
最近公司ES集群一些节点挂掉,致使一些索引的分片一直是unassigned状态,导致ES集群状态为RED,等待许久也不见好转,非常影响集群UI观感。想想什么原因,解决解决。
先复原一波 ES集群中出现 分片 unassigned 的现象。
背景
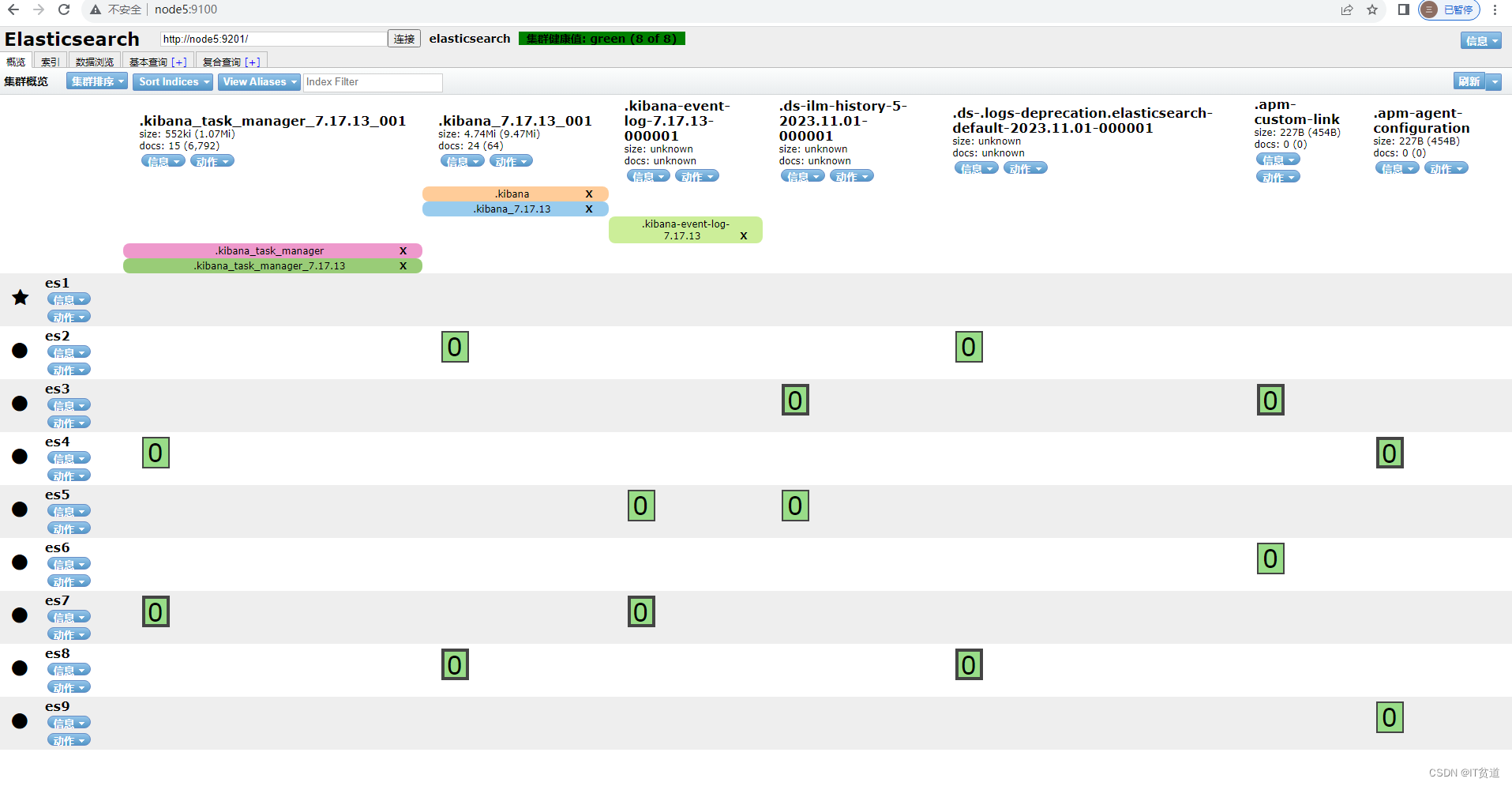
现有9台节点组成的Elastic集群,集群详细信息如下:
问题复原
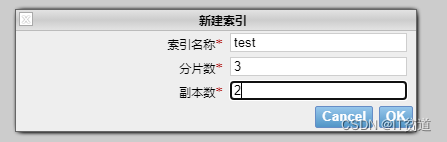
1.新建test索引,指定3分片,每个分片2个副本
2.test索引创建完成后,分片在集群中的分布如下
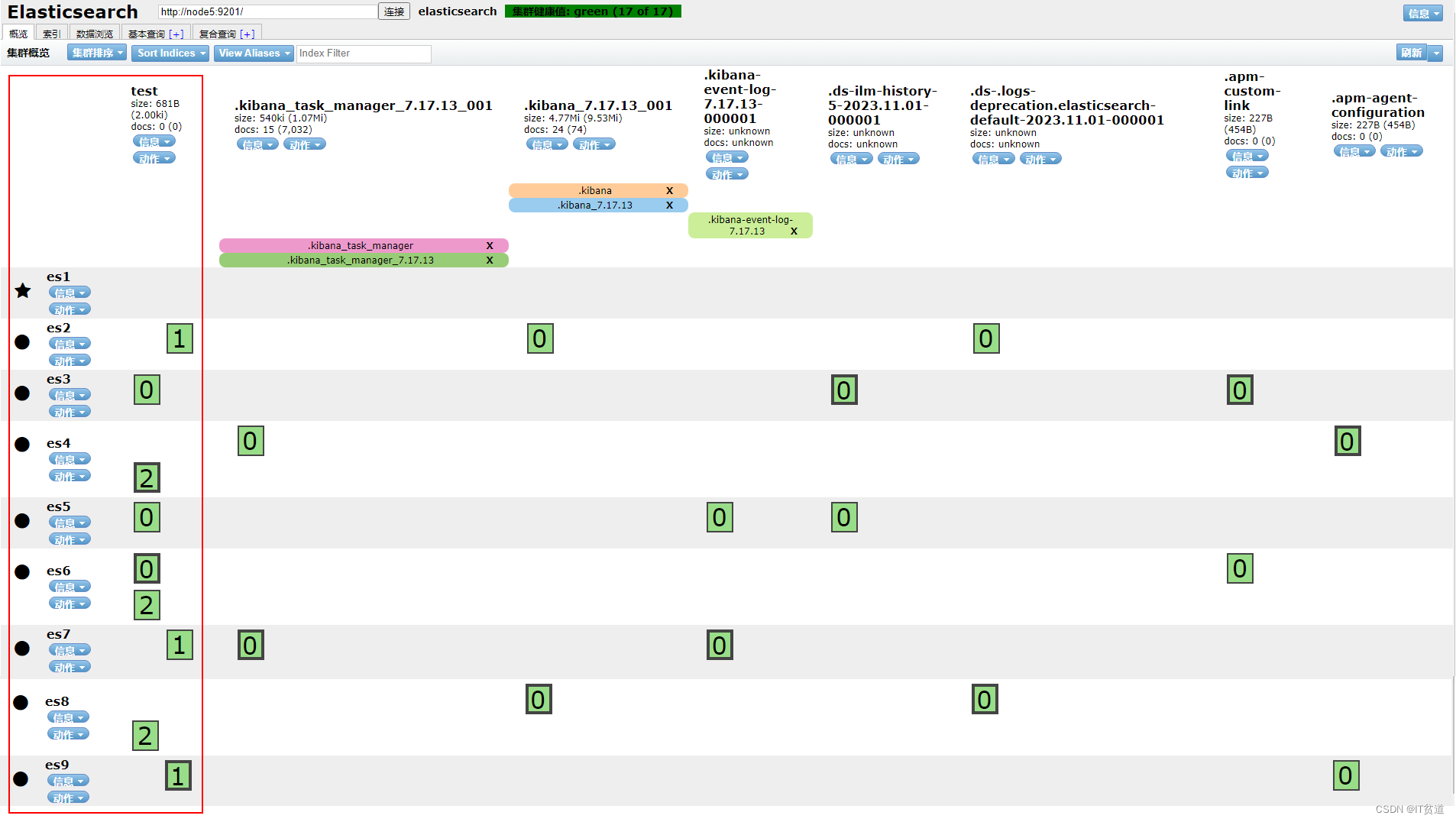
3.现在将test索引,0号主分片和0号副本分片所在的节点都kill掉
如上图所示,0号主分片和0号副本分片所在的节点分别为es3、es5、es6节点,将对应这些节点上的es进程进行kill
4.再次查看es集群情况,出现RED情况
略微一等,发现test索引的2号分片会自动在es集群中自动均衡分布。此刻如果一些主分片就算在被kill的es3、es5、es6节点,也不用担心,因为这些分片也会寻找集群中该分片副本所在节点,自动升为改分片的主分片。
但是,你会发现,等来等去,test索引的0号分片就是不会自动分配,还是一直是 Unassigned 状态!这就是我要说的问题。

问题排查和定位
ES集群中出现分片 Unassigned 状态的原因非常多,可以参考es 官网解释,我这里使用的ES版本为7.17版本:cat shards API | Elasticsearch Guide [7.17] | Elastic
按照ES官网方式排查出现以上我演示的这种分片未分配的原因,方式如下。
1)执行如下命令查看分片未分配原因
GET _cluster/allocation/explain结果如下,也附上截图:
{
"note" : "No shard was specified in the explain API request, so this response explains a randomly chosen unassigned shard. There may be other unassigned shards in this cluster which cannot be assigned for different reasons. It may not be possible to assign this shard until one of the other shards is assigned correctly. To explain the allocation of other shards (whether assigned or unassigned) you must specify the target shard in the request to this API.",
"index" : ".ds-ilm-history-5-2023.11.01-000001",
"shard" : 0,
"primary" : true,
"current_state" : "unassigned",
"unassigned_info" : {
"reason" : "NODE_LEFT",
"at" : "2023-11-01T12:40:49.352Z",
"details" : "node_left [GQ5oVVTiQeSGbWsv7OAptw]",
"last_allocation_status" : "no_valid_shard_copy"
},
"can_allocate" : "no_valid_shard_copy",
"allocate_explanation" : "cannot allocate because a previous copy of the primary shard existed but can no longer be found on the nodes in the cluster",
"node_allocation_decisions" : [
{
"node_id" : "-InsxrJ0RNOVMgEl0Nv2Xg",
"node_name" : "es9",
"transport_address" : "192.168.179.8:9309",
"node_attributes" : {
"xpack.installed" : "true",
"transform.node" : "false"
},
"node_decision" : "no",
"store" : {
"found" : false
}
},
{
"node_id" : "2IUrp8zYQDa9pG6j0z59wQ",
"node_name" : "es4",
"transport_address" : "192.168.179.8:9304",
"node_attributes" : {
"xpack.installed" : "true",
"transform.node" : "false"
},
"node_decision" : "no",
"store" : {
"found" : false
}
},
{
"node_id" : "Ll0UgYKSTIGMii5OdB4Kvg",
"node_name" : "es2",
"transport_address" : "192.168.179.8:9302",
"node_attributes" : {
"xpack.installed" : "true",
"transform.node" : "false"
},
"node_decision" : "no",
"store" : {
"found" : false
}
},
{
"node_id" : "YDisZ0KVTyuu1CfojY5Iyw",
"node_name" : "es7",
"transport_address" : "192.168.179.8:9307",
"node_attributes" : {
"xpack.installed" : "true",
"transform.node" : "false"
},
"node_decision" : "no",
"store" : {
"found" : false
}
},
{
"node_id" : "smY0M3lETju-eWmw2b5lqA",
"node_name" : "es8",
"transport_address" : "192.168.179.8:9308",
"node_attributes" : {
"xpack.installed" : "true",
"transform.node" : "false"
},
"node_decision" : "no",
"store" : {
"found" : false
}
}
]
}
查询结果截图如下
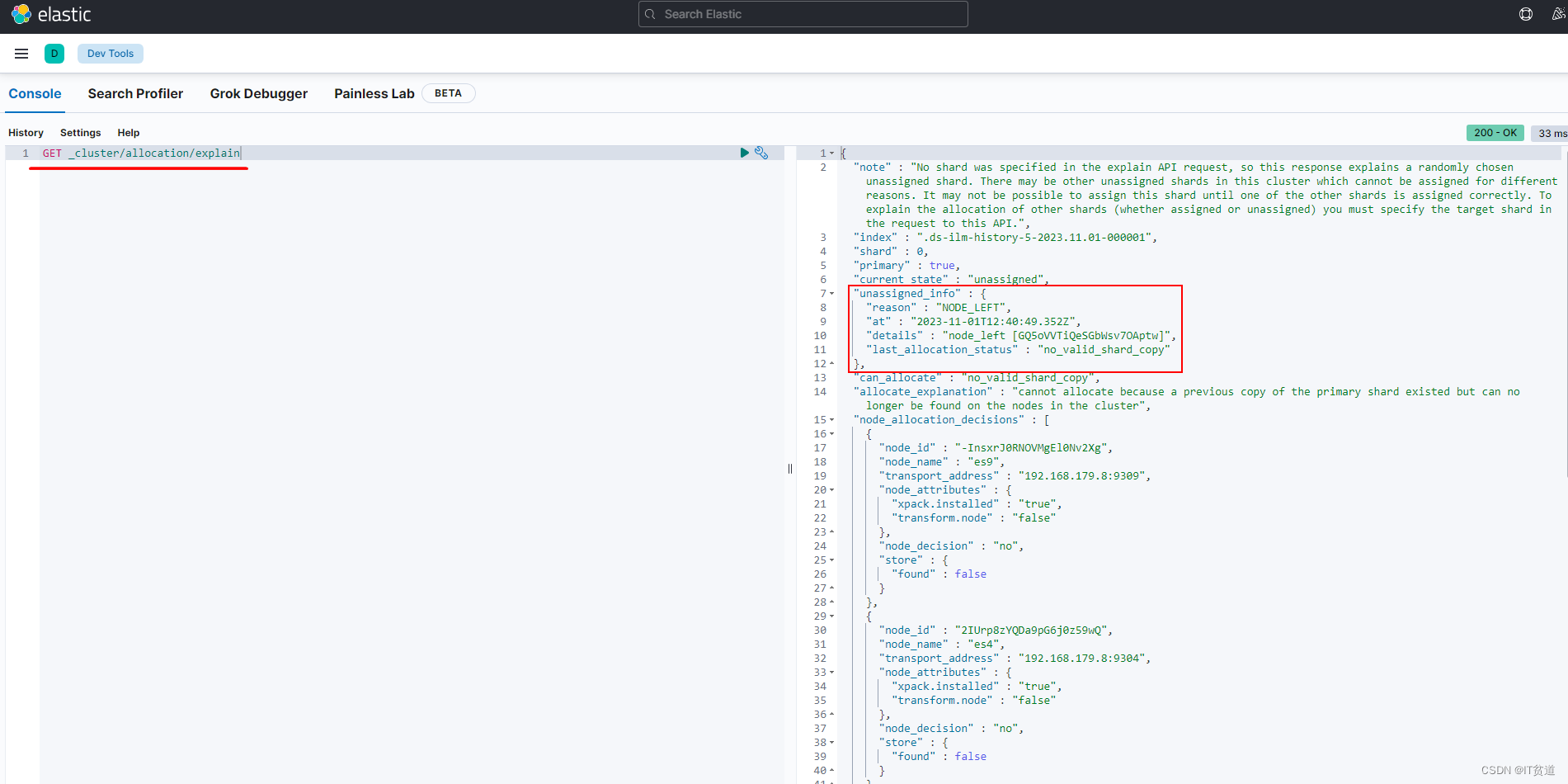
注意关键的一段:
"unassigned_info" : {
"reason" : "NODE_LEFT",
"at" : "2023-11-01T12:40:49.352Z",
"details" : "node_left [GQ5oVVTiQeSGbWsv7OAptw]",
"last_allocation_status" : "no_valid_shard_copy"
},
这里的 reason 为 NODE_LEFT ,查询官网说的意思就是分片所在的节点下线了。也就是说0号分片主分片和副本分片所在的节点都挂掉了。
官方说明如下:cat shards API | Elasticsearch Guide [7.17] | Elastic
NODE_LEFT: Unassigned as a result of the node hosting it leaving the cluster.
现在已经大体清楚了为什么ES集群中出现分片一直 Unassigned 的原因了:索引的某个分片对应的主分片和副本分片所在的节点都挂掉了,导致该分片一直没办法分配,ES集群状态为Red,再怎么等也是这么个状态。
问题思考
让老夫先总结一波,不然忘记了:
1. ES集群中,如果集群节点超过es索引分片副本数量并且索引副本不为1,那么当该分片所在的主节点挂掉后,会自动将该分片副本所在的节点升为主分片,不会导致ES集群出现Red。
2.如果某分片对应的主分片和副本分片所在的节点都挂掉(就是前面还原的这个情况),这种情况下可以手动将该分片强制分配到正常的节点上,如果这样操作表示将该分片置为空,不建议这样做,因为数据极大概率会丢失,如果数据不重要,可以这么操作。
问题解决
再强调一遍:如果你的ES集群节点数量还可以并且索引分片数不为1,一般出现分片所在节点都挂掉的概率较小。所以,如果你的情况是我还原的这种情况,建议重点排查ES节点挂掉原因,从这个角度根本解决问题。不建议直接强制分配分片到其他节点,还是老老实实的等待主分片或者副本分片所在节点正常加入集群,否则会丢失数据。
那么,如果该索引数据不重要,我就是要强制将分片分配到其他正常es节点怎么做???
直接上命令:
POST /_cluster/reroute
{
"commands": [
{
"allocate_empty_primary": {
"index": "test", #索引名称
"shard": 0, #操作的分片id
"node": "es2", #空分片要分配到的节点
"accept_data_loss": true #接收数据可能丢失
}
}
]
}关于以上命令详细解释可以参考es官网解释:Cluster reroute API | Elasticsearch Guide [7.17] | Elastic
尤其是对 allocate_empty_primary 的解释:
allocate_empty_primaryAllocate an empty primary shard to a node. Accepts the
indexandshardfor index name and shard number, andnodeto allocate the shard to. Using this command leads to a complete loss of all data that was indexed into this shard, if it was previously started. If a node which has a copy of the data rejoins the cluster later on, that data will be deleted. To ensure that these implications are well-understood, this command requires the flagaccept_data_lossto be explicitly set totrue.
以上命令执行后,test索引的0号分片被置空,并分配到es2节点,es集群恢复正常。ES集群截图如下:
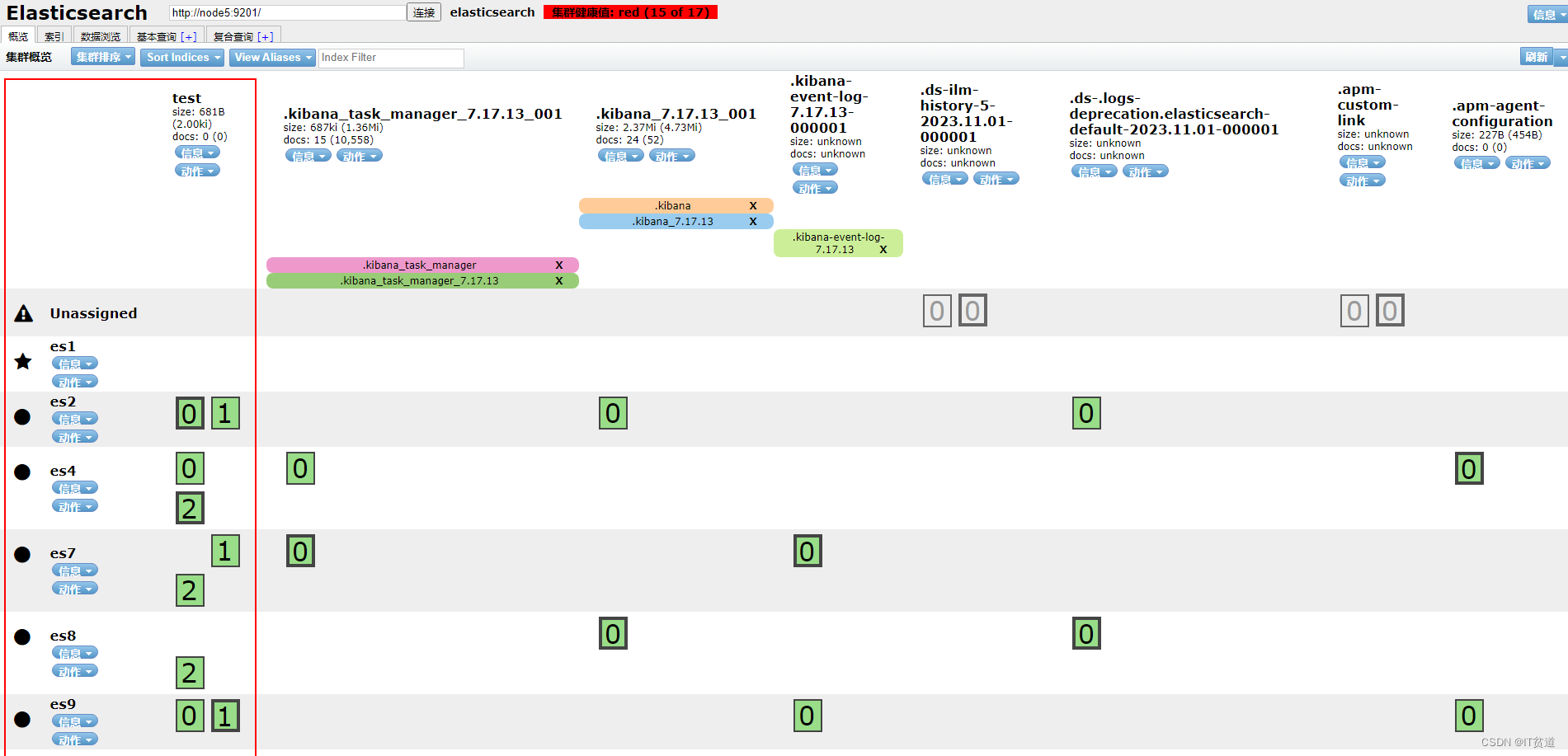
当然,截图中集群不正常的原因是其他索引分片没有强制执行分片置空命令,也可以执行如上命令将其他分片置空,集群就变成green了。至少,刚刚命令将test 索引变成正常可用的索引了。
... ...
卧槽,都看到这儿,给我点个赞吧,不行订阅个我的付费专栏支持以下也不是不可以,咱大数据很专业的。。。哈哈哈哈。。。