目录
一、什么是归并排序?
二、归并排序的实现
三、归并排序非递归
一、什么是归并排序?
归并排序是建立在归并操作上的一种有效,稳定 的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。 ————百度百科
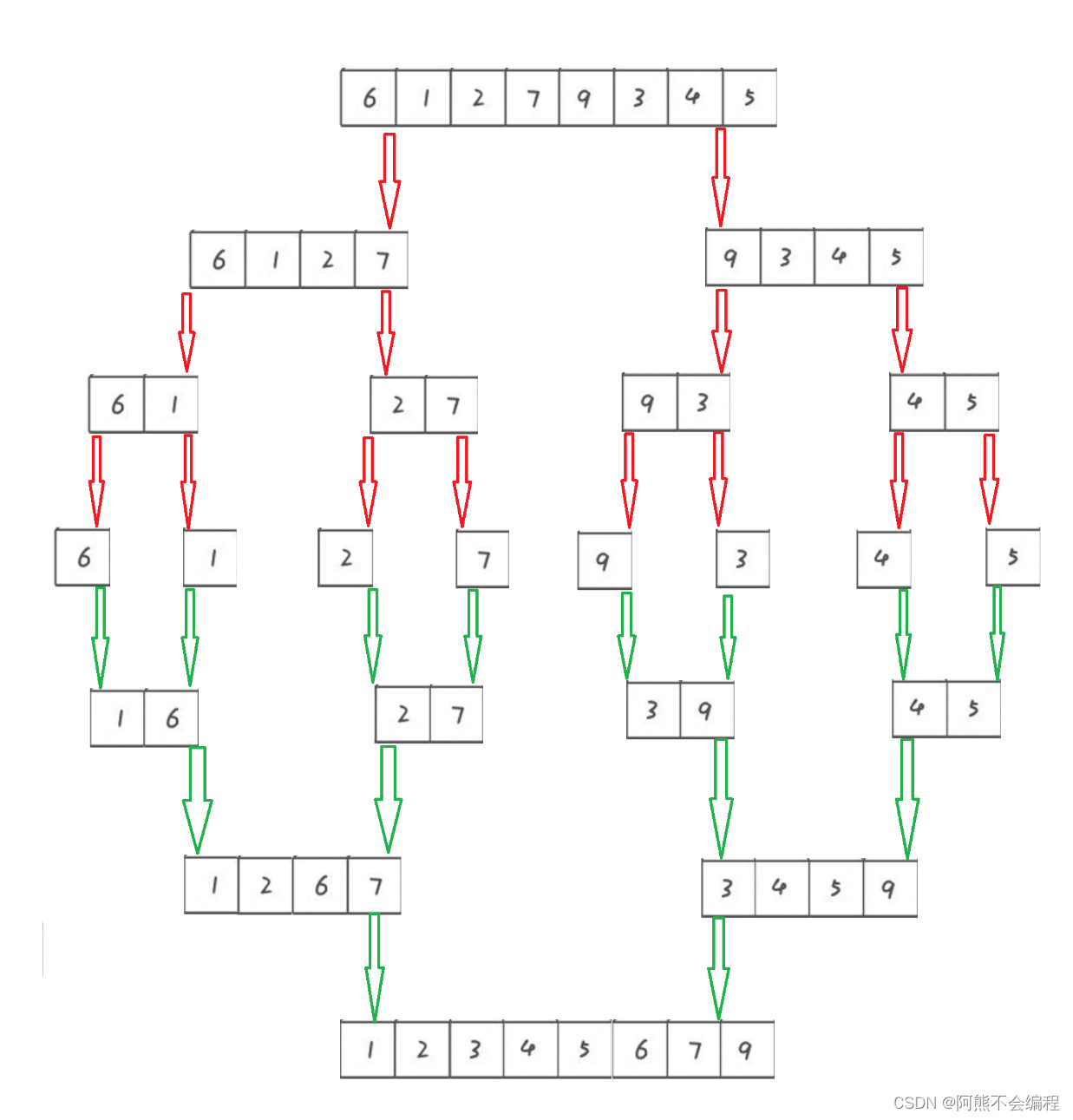
实际上 归并排序(MergeSort)是建立在归并操作上的一种排序算法,利用 分治 的思想来,将要排序的数据进行 逐层分组,一组分两组,两组分四组...直到分到只有一个元素,这个时候在和并元素的同时对元素进行排序,按照之前的元素分组在一一排序合并到新数组,最后拷贝回原数组的操作。操作如下图:
归并排序动图演示:

二、归并排序的实现
归并排序虽然我们展示的是线性结构,但是我们经常以树形结构来看,先将数组进行分组,进行对半分(并不要求一定要对半分),假设我们拿上图的八个数据,先将8个数据进行44分,如果有区间还是属于无序状态就进行22分,直到分到只剩一个元素。
之后将元素排序再按照22归拷贝到新数组tmp,22归完进行44归,这样就有序了。其实这种排序方式是树形结构的一种便利方式——后序遍历 方式(如果对二叉树不了解可以看看我的这篇文章:二叉树详解)。
首先我们可以在进行排序之前先开辟一个tmp数组来记录归并的值:
void MergeSort(int* a, int len)//传入要排序的数组,以及数组的长度
{
int* tmp = new int[len];//开辟与数组长度相同的归并用的数组
_MergeSort(a, 0, len - 1, tmp);//真正进行归并排序,传入要排序的左区间与右区间和数组长度与两个数组
}接下来进入归并排序,首先是先将数据递到最深,前面说了,归并排序也就相当于二叉树的后序遍历(先向左右子树递归,递归到最深处):
void _MergeSort(int* a, int left, int right, int *tmp)
{
if (left >= right)//注意,当左区间要等于右区间表示此时已经递归到只剩一个元素,大于右区间显然不能在继续递归下去了
return;
int mid = (left + right) / 2; //首先选取排序的区间,将区间分为左右区间,在对左右区间分别递归,在对半分在递归...
_MergeSort(a, left, mid, tmp);//后序遍历顺序:left——right——root,这里先遍历左子树
_MergeSort(a, mid + 1, right, tmp);//在遍历右子树
//..
} 这里我画出递归展开图帮助大家理解一下: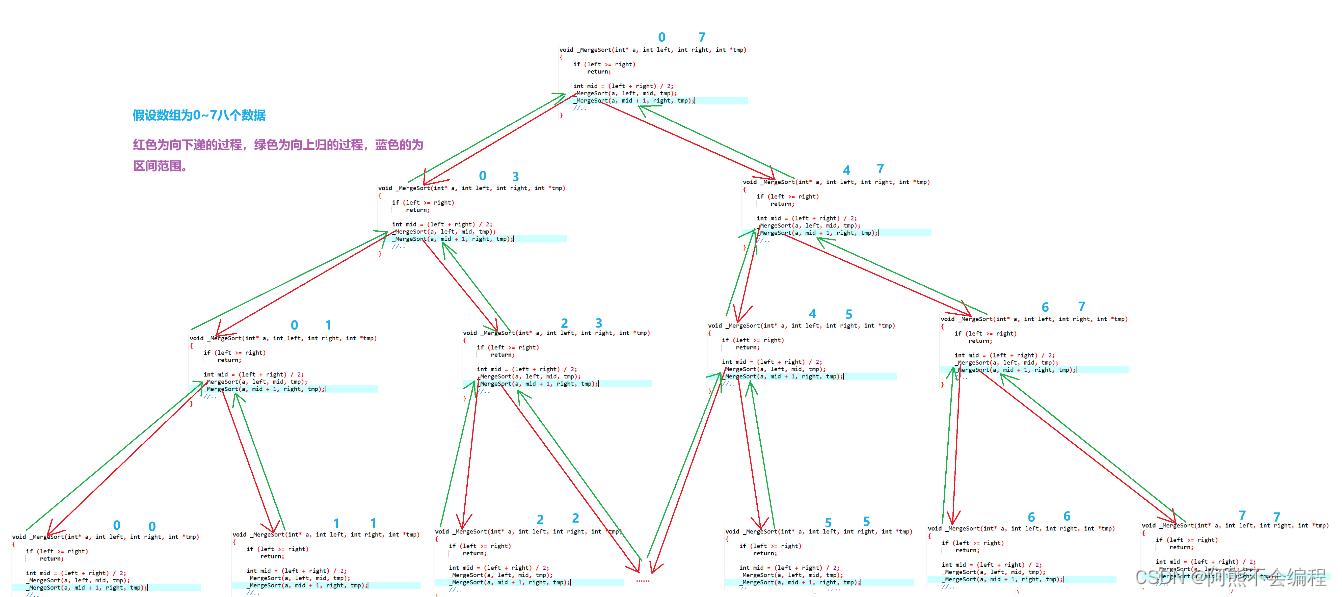
接下来就是向上归的过程,在向上归的过程中,首先要控制好区间,我们前面将数组分成两份,一份从begin到mid,一份从mid+1到end。那么该如何确定哪个元素大哪个元素小呢?其实很简单:
1、创建五个变量,分别记录两个区间的起始和结束(begin1, end1 begin2, end2),最后一个记录tmp数组的下标(index)。
2、需要一个while循环,首先循环的条件肯定是两个区间的起始位置都要小于等于终止位置(可能存在其中一个区间没有进入到tmp数组里面,这是不确定的)。
3、,在循环里比较两个区间的起始位置,哪个值较小就将值赋给tmp数组,tmp数组下标index自增,此元素下标也自增,否则另一个区间的元素进行赋值给tmp,下标同样都自增。
4、最后,可能会存在左区间或者右区间的值是没有进入到tmp数组的,所以我们直接在来两个while循环对两个区间分别赋值给tmp,保证最后两个区间都进入到tmp数组。
5、这些完成之后,将这两个区间的值拷贝回原数组,这里我们使用C语言中的memcpy函数进行拷贝,在拷贝回原数组时要拷对位置,从左区间第一个元素开始拷,tmp数组也要对应,拷贝字节大小为右区间减去左区间加一乘上整形字节数。
void _MergeSort(int* a, int left, int right, int *tmp)//归并排序
{
if (left >= right)
return;
int mid = (left + right) / 2;
_MergeSort(a, left, mid, tmp);
_MergeSort(a, mid + 1, right, tmp);
int begin1 = left, begin2 = mid + 1;//两个区间的左区间
int end1 = mid, end2 = right;//两个区间的右区间
int index = left;//tmp数组的下标,记录tmp中已存在元素个数
while (begin1 <= end1 && begin2 <= end2)//两个区间都不越界就继续比较赋值
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while (begin1 <= end1)//第一个区间元素没入完就直接将剩下元素赋值到tmp
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)//右区间同样如此
{
tmp[index++] = a[begin2++];
}
memcpy(a + left, tmp + left, (right - left + 1) * sizeof(int));//最后拷贝回原数组
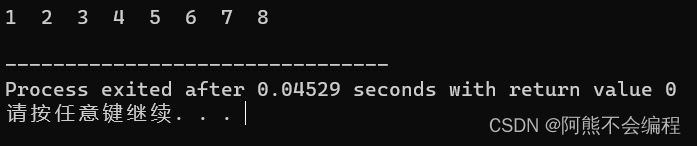
}这样,归并排序就完成了,下面是完整的代码以及测试结果:
#include<iostream>
using std::cout;
using std::cin;
using std::endl;
void _MergeSort(int* a, int left, int right, int *tmp)
{
if (left >= right)
return;
int mid = (left + right) / 2;
_MergeSort(a, left, mid, tmp);
_MergeSort(a, mid + 1, right, tmp);
int begin1 = left, begin2 = mid + 1;
int end1 = mid, end2 = right;
int index = left;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
memcpy(a + left, tmp + left, (right - left + 1) * sizeof(int));
}
void MergeSort(int* a, int len)
{
int* tmp = new int[len];
_MergeSort(a, 0, len - 1, tmp);
}
void output(int* a, int len)
{
int i = 0;
for (i = 0; i < len; i++)
{
cout << a[i] << " ";
}
cout << endl;
return;
}
void Test()
{
int a[] = { 6, 1, 4, 8, 2, 7, 3, 5 };
int len = sizeof(a) / sizeof(int);
MergeSort(a, len);
output(a, len);
return;
}
int main()
{
Test();
return 0;
}
总的来说,归并排序的递归写法还是很简单的。
三、归并排序非递归
归并排序说到底用的还是递归,用递归很容易就会造成 栈溢出,为了防止这种情况,我们有必要掌握归并排序的非递归编写方式。
值得注意的是,这里我们如果用栈或者队列来模拟实现归并排序的非递归其实是很困难的,我们这里用一种别的方法:
首先,我们先来对归并的过程详细的学习一下:
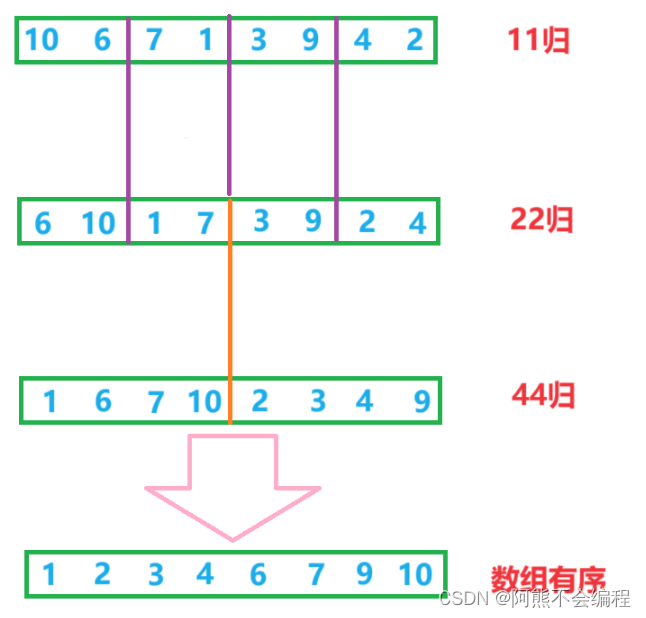
在归并的过程中首先进行11归,在进行22归,44归...直到把全部数据归并完毕,那么,我们该如何实现这种非递归模式呢?其实我让大家看归并的过程是有用的,我们可以像希尔排序那样设置gap间隔来分组(这里是分区间),比如gap == 1就代表11归,gap == 2就是22归,同时gap也是元素的个数。
1、在最外层用while循环控制gap的值。
2、在循环内,用for循环来对每个归并的过程进行gap gap归,在for循环内每次循环跳2倍的gap,这样正好跳过这个已排序的区间,跳向下一个区间。
3、for循环内的内容就和递归一样了,while循环对分成的两个区间进行排序,最后拷贝回原数组,值得注意的是,这里的memcpy拷贝位置是要+i的(对应区间位置),大小是右区间的end减去左区间的begin在乘上sizeof(int)。
#include<iostream>
using std::cout;
using std::cin;
using std::endl;
void MergeSortNonR(int *a, int len)
{
int *tmp = new int[len];//tmp数组
int gap = 1;
while(gap < len)//while循环控制gap gap 归
{
int i = 0;
for(i = 0 ; i < len ; i += 2 * gap)//每次循环跳2倍gap就会跳过gapgap归的一个区间
{
int begin1 = i, end1 = i + gap - 1;//这里是下标,所以end最后要-1
int begin2 = i + gap, end2 = i + 2 * gap - 1;//2倍的gap相当于跳两个区间
int index = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
memcpy(a + i, tmp + i, (end2 - i + 1) * sizeof(int));//拷贝回原数组
}
gap *= 2;
}
}
void output(int* a, int len)
{
int i = 0;
for (i = 0; i < len; i++)
{
cout << a[i] << " ";
}
cout << endl;
return;
}
void Test()
{
int a[] = { 6, 1, 4, 8, 2, 7, 3, 5 };
int len = sizeof(a) / sizeof(int);
MergeSortNonR(a, len);
output(a, len);
return;
}
int main()
{
Test();
return 0;
}
可以看到,这样写似乎并没有什么问题,依旧能够排序,但是如果我的数据量为9个,10个,11个呢?这种写法能保证一定能完成排序吗,就按照gap gap归,while循环gap每次都乘2,当gap == 16的时候,这个时候在进行88分?这样一定是会越界访问的。
我们不妨做一下测试:


我们在这里加上printf函数以便于更加直观的测试哪里出了问题,首先是原始八个数据:
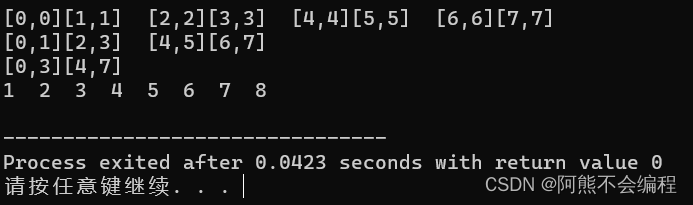
可以发现,8个数据是没任何问题的,区间是在0-7范围的,不会产生越界问题,但是我们将数据增加到9个呢?

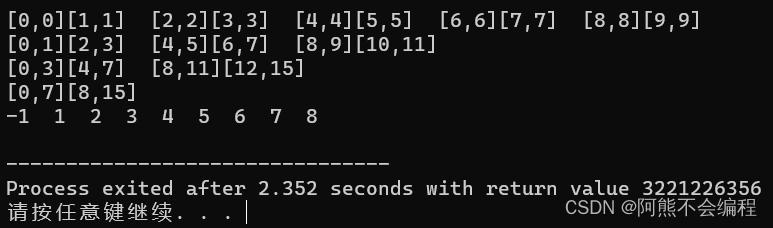
我们就会发现这里程序直接挂了,我们前面也说了,这一定是越界问题,那么究竟是哪里越界了呢?
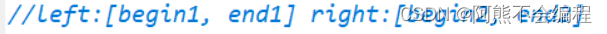

我们增加了一个元素,所以数组的下标就为0-8九个元素,那么超过8的就都为越界,这里你可以先不往下看,思考思考,这里的越界分为几种情况?谁有可能要越界,我们该对谁管理?
经过上面的越界信息我们可以得到以下三种情况:
1、[begin1, end1] [begin2, end2]中,begin2没越界,end2越界。
2、[begin1, end1] [begin2, end2]中,begin2与end2都越界。
3、[begin1, end1] [begin2, end2]中,end1与begin2,end2都越界。
无论怎么越界,只要是发生了越界,end2就必定在其中,那么我们在归并的时候比如22归的时候,一定要两组数据都拥有两个数吗?不一定吧,我在递归里面也说了,分组没有那么严格,就算两组的元素个数不一样也是能归并的,甚至就算只有一组也是可以归并的。
那么有什么好的办法来防止越界的发生呢?其实这里只需要加上两条if语句就行了: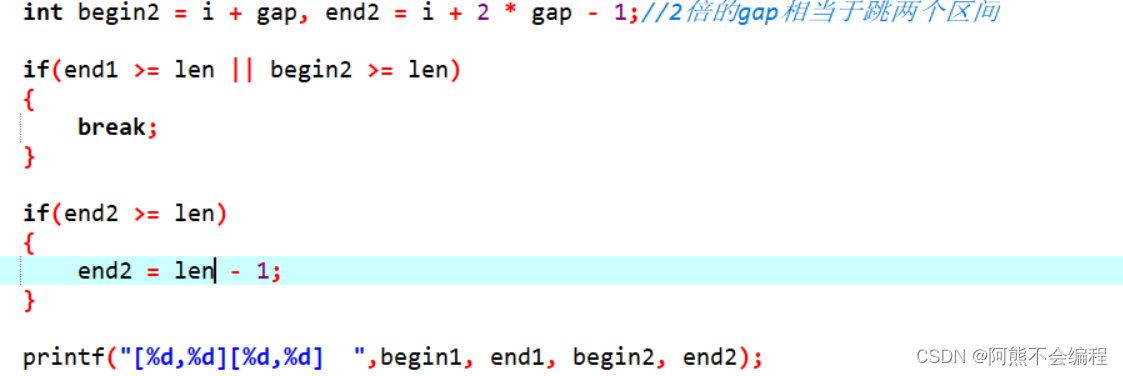
我们如何理解这几行代码呢?
1、当我们的end1越界了其实就可以直接break了,因为end1越界那么后边一定越界,end1也越界了,那么整个数组就剩下begin1一个元素所以就不用排序直接break,同样当begin2越界的话,右区间全部越界,左区间是已排好序的区间,那么直接break了对左区间也没有影响。
2、随后在检测end2 如果end2越界了,该怎么办?其实很简单,因为end2已经是最后一个元素了,如果他越界了就表示右数组没有end2这个数据,那么我们就可以直接修正下标,使下标指向数组最后一个元素就不会发生越界了。
这个时候在运行就不会有任何越界的问题发生了: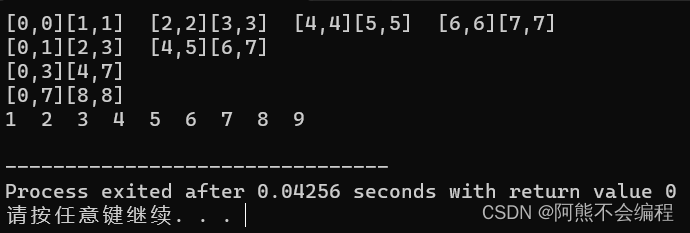
其实在第一个if这里还有优化的方案:
其实这里理解起来也很简单,begin2越界的时候第二组就全越界了,直接break掉,可能你会说:哦,确实有道理,但是吧,如果end1越界了的情况没有说明啊?
其实啊,我们在对这两组数进行归并的时候,这两组数每组里面已经是有序的了,那么我直接不管end1越没越界,如果第二组全都越界了,我也就break了,如果此时我end1越界了,那我还有左半区间是有序的,不用归,如果end1没越界,我第一组本来就是有序的,我也不用归啊,这在一定程度上还减少了消耗。
归并排序非递归完整代码如下:
#include<iostream>
using std::cout;
using std::cin;
using std::endl;
void MergeSortNonR(int *a, int len)
{
int *tmp = new int[len];
int gap = 1;
while(gap < len)
{
int i = 0;
for(i = 0 ; i < len ; i += 2 * gap)
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
if(begin2 >= len)
{
break;
}
if(end2 >= len)
{
end2 = len - 1;
}
int index = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
memcpy(a + i, tmp + i, (end2 - i + 1) * sizeof(int));
}
gap *= 2;
}
}
void output(int* a, int len)
{
int i = 0;
for (i = 0; i < len; i++)
{
cout << a[i] << " ";
}
cout << endl;
return;
}
void Test()
{
int a[] = { 6, 1, 4, 8, 2, 7, 3, 5, 11, 9, 10 };
int len = sizeof(a) / sizeof(int);
MergeSortNonR(a, len);
output(a, len);
return;
}
int main()
{
Test();
return 0;
}测试结果:
 如果各位看官老爷还满意的话,不如留下小小的三连支持一下博主吧~~
如果各位看官老爷还满意的话,不如留下小小的三连支持一下博主吧~~



![[架构之路-250/创业之路-81]:目标系统 - 纵向分层 - 企业信息化的呈现形态:常见企业信息化软件系统 - 企业内的数据与数据库](https://img-blog.csdnimg.cn/2eff2a6b8ce844f8babd97e7a77785f2.png)