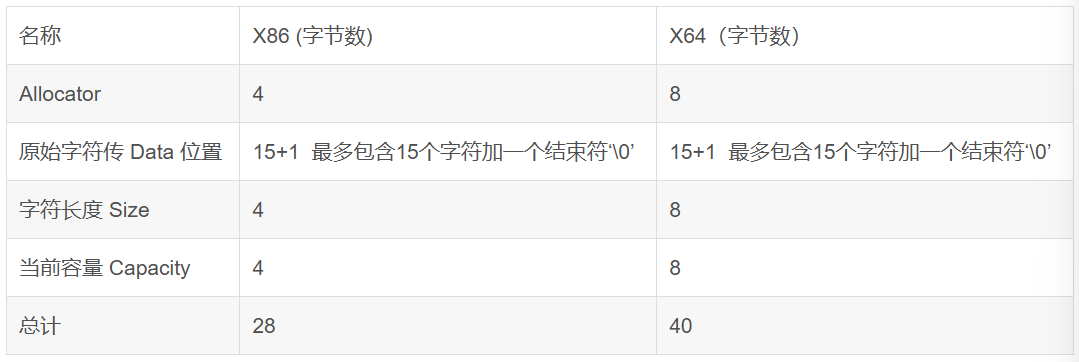
文章目录
- 自监督视觉`transformer`模型DINO
-
- 总体介绍
- DINO中使用的SSL和KD方法
- multicrop strategy
- 损失函数定义
- `teacher`输出的中心化与锐化
- 模型总体结构及应用
-
- reference
欢迎访问个人网络日志🌹🌹知行空间🌹🌹
自监督视觉transformer模型DINO
总体介绍
论文:1.Emerging Properties in Self-Supervised Vision Transformers
这篇文章旨在探索自监督训练有没有给视觉transformer带来相对于CNN没有的新特性。
除了观测到自监督训练ViT工作特别好外,作者还有两个新发现,一个是自监督训练得到的特征图包含明显的语义信息,有可能将自监督的结果直接拿来做语义分割和目标检测,另外一个是直接拿自监督得到的特征向量应用KNN分类,得到了非常好的效果。ps:本人在工程数据(20W张)上验证的直接使用KNN分类的效果比efficient-net还好。
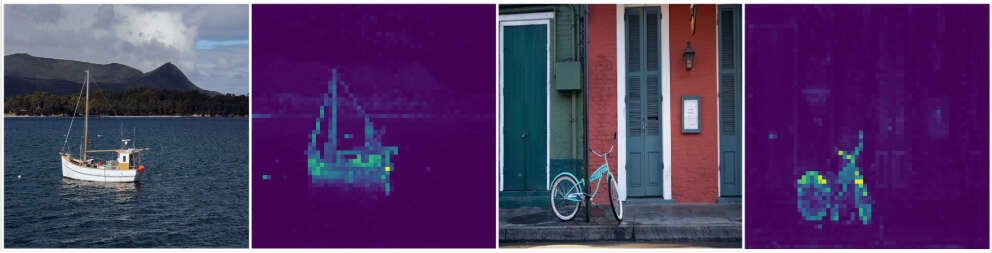
正如DINO的名字缩写,这整个算法使用了知识蒸馏的架构,通过一个teacher网络引导student的学习,使用损失值计算的梯度更新student模型的参数,而teacher模型的参数使用的是student模型参数的指数移动平均值,和BYOL的方法有些相似。除了知识蒸馏,作者还强调了对输入进行RandomResizeCrop和transformer使用小patch_size的重要性。同时,DINO需要对teacher的输出进行中心化和锐化centering and sharpening,否则模型训练会不稳定,甚至崩溃(collapse)。DINO使用的student和teacher且训练过程中相互促进学习,也属于共蒸馏codistillation模型。
知识蒸馏的概念是一个学生网络student表示为 g θ s g\theta_s gθs学习匹配一个教师网络teacher表示为 g θ t g\theta_t gθt的输出,通过teacher引导student的训练。
假如给定一个输入图像 x x x,网络对应的输出是 K K K维的概率分布 P P P(类似于有K个类别的分类),student和teacher对应的输出概率分别为P_s和P_t。
在计算student输出概率的时候使用的是带 τ s \tau_s τs温度系数的softmax方法,在DINO中默认的 τ s = 0.1 \tau_s=0.1 τs=0.1,目的在于增大输出的相对熵,促进类别之间相似度的区分,在计算teacher输出的概率时同样使用了 τ t = 0.9 \tau_t=0.9 τt=0.9。
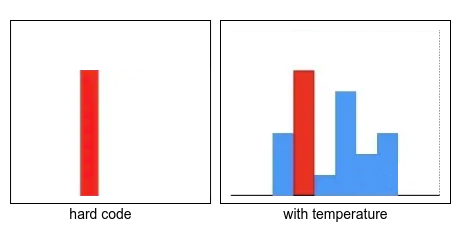
P s ( x ) ( i ) = e x p ( g θ s ( x ) ( i ) / τ s ) ∑ k = 1 K e x p ( g θ s ( x ) ( k ) / τ s ) P_s(x)^(i)=\frac{exp(g\theta_s(x)^{(i)}/\tau_s)}{\sum\limits_{k=1}^{K}exp(g\theta_s(x)^{(k)}/\tau_s)} Ps(x)(i)=k=1∑Kexp(g