今天给大家带来CIKM2022应用研究方向最佳论文-来自于快手团队的《Real-time Short Video Recommendation on Mobile Devices》,主要研究在移动端如何做到更好的短视频实时推荐,是一篇不错的落地经验分享的论文,一起来看一下。
1、背景
近几年来短视频平台逐渐发展,像快手、抖音等平台吸引了大批用户的使用。下图为典型的短视频应用的页面截图。由于短视频时长较短,内容主题丰富多样,用户通常会在很短时间内观看许多不同主题的短视频,同时用户的实时兴趣可能会不断发生变化。因此,对于短视频应用来说,其推荐系统如何针对用户的实时反馈做出更敏感准确的推荐,是十分重要的。

传统的推荐系统通常部署在服务端,并包含多个阶段:召回,精排和重排阶段。客户端向推荐系统发送用户分页请求,然后推荐系统一次性返回一整个页面的内容,随后客户端将这些结果一个接一个展现给用户。对于这样的架构,主要存在两方面的问题:
1)敏感性:服务端只有在接收客户端发起的分页请求时才有机会调整推荐内容,无法基于用户的实时反馈作出实时的内容决策;
2)准确性:用户的实时反馈信息无法被及时利用。只有当这些用户反馈信息可用后,才会回传给服务端,这会花费数十秒甚至几分钟的时间,这对特征的实效性影响很大。同时,客户端特有的特征(用户的网络情况等),在服务端是无法获取到的,但对于实时用户兴趣预测来讲,这些特征也十分重要。
随着算力和存储能力发展,使得在一些移动端的的设备如手机、平板部署甚至训练简单的DNN模型变为可能。通过在移动端部署轻量级的模型,提供实时的推荐排序能力,来解决上述两方面的问题,为用户提供更为实时准确的推荐结果。
本文重点针对短视频场景下的端上实时推荐,重点分享两方面的经验:一方面如何有效利用端上的用户实时反馈特征进行模型预估;另一方面是如何通过自适应确定搜索步数的 beam search 来对短视频进行重排,生成整体效果更好的排序。接下来,对快手整个端上推荐系统的架构以及上述两方面的经验进行重点介绍。
2、系统架构概览
整个快手短视频推荐系统架构如下图所示,主要分为三个部分:服务端推荐系统;客户端推荐系统和模型训练系统。

2.1 服务端推荐系统
传统的推荐系统通常部署在服务端,包含召回、精排和重排多个阶段。当用户发起一次分页请求,服务器经过多个阶段将推荐结果返回给客户端。在快手的推荐系统中,服务端除返回重排后的m个候选结果外,还会额外n个视频,来扩展端上推荐系统的候选空间。
2.2 模型训练系统
第二个模块是模型训练系统,这部分首先从收集的数据中生产训练样本,然后通过分布式训练系统对排序模型进行增量更新。模型对应的checkpoint会定期导出,并以TFLite的形式进行部署。
2.3 客户端推荐系统
客户端推荐系统又可以进一步分为两部分:
1)特征收集:这部分收集来自服务端和客户端的特征,并将其发送给推荐模型。
2)上下文感知的重排模型:当用户滑动观看下一个视频或者点击喜欢/分享视频时,会触发端上模型对候选视频进行重排序,并按照重排序的结果填充下一个给用户展示的内容。
接下来,对端上推荐系统的内容进行重点介绍。
3、端上排序模型
3.1 设计理念
由于模型部署在移动端,出于存储能力、计算能力和电量消耗等方面的限制,模型必须极度轻量且高效。当设计模型结构时,有两种主要的选择:
1)一种是端云协作模式,模型中主要的embedding 参数保存在服务端,客户端只保留DNN部分的参数。当在线推理时,服务端查找对应的embedding并将其传输给客户端用于后续的计算。
2)另一种是为客户端设计轻量的小模型。这样的设计不仅可以减少计算延迟,同时无需考虑客户端和服务端之间模型的一致性问题
这里快手选择的是第二种方式,即为移动设备设计一个小型但独立的模型。该模型是服务端模型的补充,主要是利用客户端用户的实时反馈信息来提高预测精度。服务端的排序模型已经将大部分信息压缩为最终的预测分数,因此可以将其作为输入以避免冗余计算,并使模型足够小。离线实验也验证了将复杂的ID类特征作为输入,并没有比直接使用预测值作为输入带来明显的改进。
3.2 输入特征
这一部分主要介绍下端上模型的输入特征。主要包含三种类型的特征:
1)服务端模型的预测值:服务端模型无论是在模型结构还是输入特征上都十分复杂,其给出的预测值是对输入信息的高度压缩,能够很好的表示用户对于视频的喜好程度,同时可以利用客户端的实时特性作为补充,更好地预测用户的实时兴趣;
2)视频属性特征:视频属性特征如视频ID、类别、持续时长、标签、背景音乐等等,由于模型容量的限制,只能选择其中一小部分特征。这里,只选择了视频的类型以及持续时长特征;
3)客户端特征:客户端同样会收集许多重要的特征,如用户最近的观看列表,列表中的每个视频又包括用户的反馈信息,视频的观看时长,视频的观看时间戳等特征。除此之外,还会收集客户端相较服务端独有的特征,如候选视频将被展示的位置、用户的网络情况等等。不同的网络情况下为了保证用户体验,能够去展示的视频也是有所不同的。
模型所用到的输入特征汇总如下:

3.3 特征工程
为了进一步提升推荐效果,模型中进一步增加如下的交叉特征作为输入:
1)pXTR diff:候选视频精排 pXTR 和观看历史视频 pXTR 的差值,这里相较原文内容中的解释,文章https://m.thepaper.cn/baijiahao_20394383给出的解释更容易理解和接受:
不同用户天然存在的 bias 会导致用户间的 pXTR 并不直接可比,比如有些用户 pXTR 会整体偏高或偏低,由于端上重排模型中没有用到 uid 等特征,直接用 pXTR 的原始分值作为特征会干扰模型学习。通过 pXTR 之差可以消除这种 bias,并且以最近看过的视频 pXTR 为锚点,可以感知用户的实时兴趣偏好。
2)视频曝光时间之差:用户观看历史中每个视频曝光时间与上一次曝光时间的差值,通常来说离当前时间越近的视频影响越大。
3)视频曝光位置之差:用户观看历史中每个视频曝光位置与当前位置的位置间隔,如果用户观看视频的速度很快,那么曝光位置之差比曝光时间之差会更加稳定。
3.4 模型结构
介绍完了输入特征和特征工程,接下来看看模型的具体结构,如下图所示:

输入可以分为四部分:
1)实时观看历史:端上保存的用户实时观看历史
2)有序的候选视频列表:这里主要是为重排所考虑,建模已决策视频(即上文)对目标视频的影响。
3)目标视频
4)其他特征:主要包括一些上下文特征如当前的网络状况等。
具体的网络结构图上比较清晰,这里不再赘述。
3.5 模型训练和部署
整个模型需要考虑的建模目标有很多,这里主要选择了三个最为重要的目标:是否下刷、是否为有效观看(观看时长大于设定的阈值,如5s)、用户是否喜欢当前视频。三者均为二分类损失,通过MMoE结构得到三部分的预估值,并计算损失和模型训练:
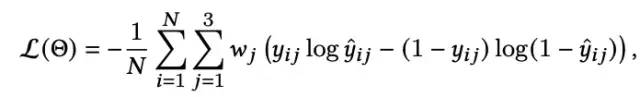
4、上下文感知的重排序
上一节中介绍了模型部分的主要内容,当模型对候选视频给出相应的预测得分之后,如何决定视频给用户展现的顺序呢?最常用的方法是point-wise的方法,即使用统一的排序公式对所有的视频进行单点排序,决定展现顺序。但单点排序的方法无法考虑候选视频之间的相互影响,非全局最优。
另一种方法是list-wise的方法,直接找到一个能够使得list-reward最大的排列。但直接寻找最优的排列所需要的计算量是巨大的,因此Beam-Search是一种常用的近似优化策略(但这种策略只能考虑上文对下文的影响,无法考虑下文对上文的影响,仍非全局最优策略)。

为了进一步减少寻找最优排列的耗时,论文对Beam-Search方法做出了一定的改进,提出了自适应步长的Beam-Search方法。在Beam-Search的每一步,计算reward最差的序列和最优的序列的奖励比值,如果该比值大于一定的阈值,则说明再往后的每一步,序列间的reward也不会相差太多,无需进一步的搜索。

那么List的Reward如何定义呢,公式如下:
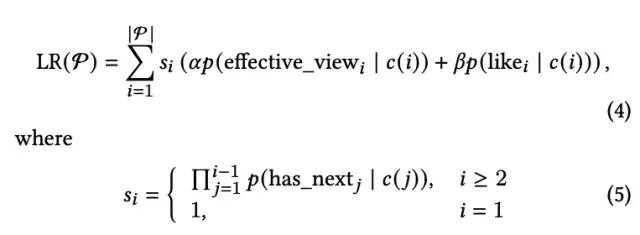
整体的奖励为单个视频奖励的求和。对每个视频来说,包含两部分:第一部分是视频曝光的概率(前面所有视频下刷的概率乘积),第二部分是对应每个视频有效观看以及被用户喜欢概率的加权求和。这两部分的乘积作为单个视频的奖励。
5、实验结果
最后来看一下实验结果部分:
5.1 离线实验

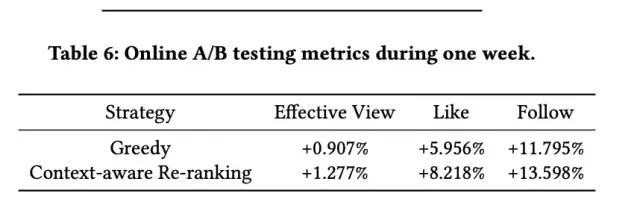
5.2 线上A/B测试
好了,论文就介绍到这里,从特征设计、特征工程、模型结构设计、重排方法设计,论文都有不错的借鉴意义,值得阅读~