一、并行执行规模
CUDA关于并行执行具有分层结构。每次内核启动时可以被切分成多个并行执行的块,而每个块又可以进一步地被切分成多个线程。这种并行执行的副本可以通过两种方式完成:一种是启动多个并行的块,每个块具有1个线程;另一种是启动1个块,每个块里具有多个线程。
通过共享内存1个块中的线程可以相互通信。所以启动1个具有多个线程的块让里面的线程能够相互通信是一个优势。更加理想的则是,我们并不单独启动1个块,里面多个线程;也不启动多个块,每个里面1个线程。我们一次并行启动多个块,每个块里面多个线程(最多可以是maxThread-PerBlock的数量)。
所以,假设上一章的那个向量加法例子你需要启动N=50000这么多的线程,我们可以这样调用内核:
gpuAdd << <((N+511)/512), 512 >> > (d_a, d_b, d_c);这个N最大可以是多少? 从计算能力3.0(目前CUDA能支持的最低计算能力)开始该x方向上的块数量就已经被放开了。因为考虑N过大而不能直接计算块数量的做法已经不需要考虑了。因为当前的限制是如此巨大,在2的31次方减1的块数量和每个块中1024的线程数量,只有非常巨大的N才能超出限制,大约在万亿级别的a,b,c中的元素数量才有可能,所以一般情况下这不会构成任何限制了。
二、大量线程并行示例
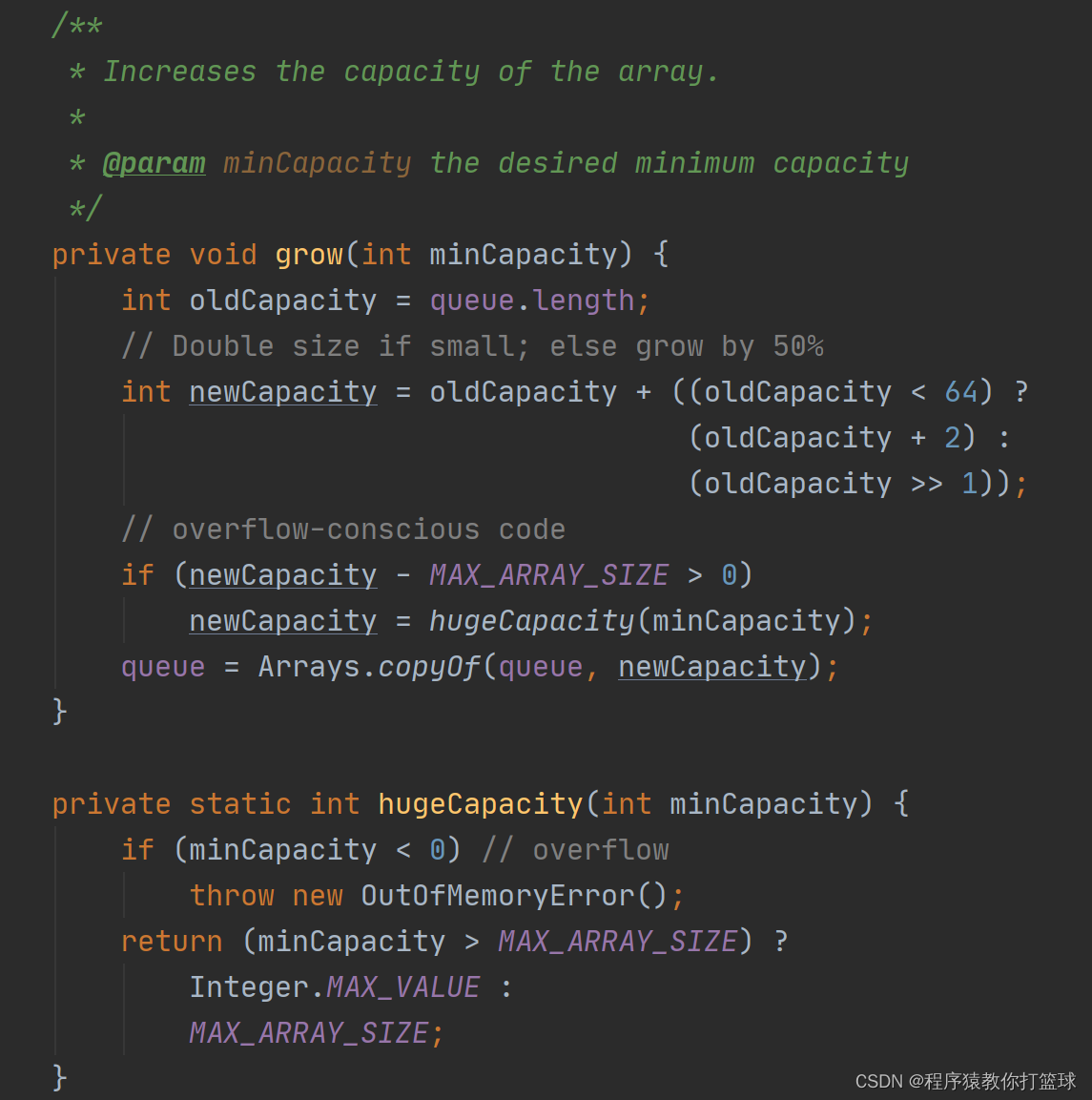
这里的内核的代码值得注意的是:一处是计算初始的tid的时候,另一处则是while循环部分。计算初始的tid的变化,是因为我们现在是启动多个块,每个里面有多个线程,直接看成ID的结构,多个块横排排列,每个块里面有N个线程,那么自然计算tid的时候是用当前块的ID*当前块里面的线程数量+当前线程在块中的ID,即tid=blockIdx.x(当前块的ID)*blockDim.x(当前块里面的线程数量)+threadIdx.x(当前线程在块中的ID)。
而while部分每次增加现有的线程数量(因为你没有启动到N),直到达到N。这就如同你有一个卡,一次最多只能启动100个块,每个块里有7个线程,也就是一次最多能启动700个线程。但N的规模是8000,远远超过700怎么办?答案是直接启动K个(K≥700),这样就能安全启动。然后里面添加一个while循环,这700个线程第一次处理[0,699),第二次处理[700,1400),第三次处理[1400,2100)……直到这8000个元素都被处理完。
初始化时候的tid=threadIdx.x+blockDim.x*blockIdx.x,每次while循环的时候tid+=blockDim.x*gridDim.x(注意一个是=,一个是+=,后者是增加的由来)。
这里的main函数,唯一的不同点在于内核的启动方式。现在我们用512个块,每个块里面有512个线程启动该内核。这样N非常大的问题就得到了解决。
#include "stdio.h"
#include<iostream>
#include <cuda.h>
#include <cuda_runtime.h>
//定义数组中的元素数
#define N 50000
//定义向量加法的核函数
__global__ void gpuAdd(int *d_a, int *d_b, int *d_c) {
//获取当前内核的块索引
int tid = threadIdx.x + blockIdx.x * blockDim.x;
while (tid < N)
{
d_c[tid] = d_a[tid] + d_b[tid];
tid += blockDim.x * gridDim.x;
}
}
int main(void) {
//定义主机的数组
int h_a[N], h_b[N], h_c[N];
//定义设备指针
int *d_a, *d_b, *d_c;
// 申请内存
cudaMalloc((void**)&d_a, N * sizeof(int));
cudaMalloc((void**)&d_b, N * sizeof(int));
cudaMalloc((void**)&d_c, N * sizeof(int));
//初始化数组
for (int i = 0; i < N; i++) {
h_a[i] = 2 * i*i;
h_b[i] = i;
}
// 将输入数组从主机复制到设备内存
cudaMemcpy(d_a, h_a, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, N * sizeof(int), cudaMemcpyHostToDevice);
//用512个块,每个块里面有512个线程启动该内核
gpuAdd << <512, 512 >> >(d_a, d_b, d_c);
//将结果从设备内存复制回主机内存
cudaMemcpy(h_c, d_c, N * sizeof(int), cudaMemcpyDeviceToHost);
cudaDeviceSynchronize();
int Correct = 1;
printf("Vector addition on GPU \n");
//Printing result on console
for (int i = 0; i < N; i++) {
if ((h_a[i] + h_b[i] != h_c[i]))
{
Correct = 0;
}
}
if (Correct == 1)
{
printf("GPU has computed Sum Correctly\n");
}
else
{
printf("There is an Error in GPU Computation\n");
}
//Free up memory
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
return 0;
}三、存储器架构
在GPU上的代码执行被划分为流多处理器、块和线程。GPU有几个不同的存储器空间,每个存储器空间都有特定的特征和用途以及不同的速度和范围。这个存储空间按层次结构划分为不同的组块,比如全局内存、共享内存、本地内存、常量内存和纹理内存,每个组块都可以从程序中的不同点访问。

如图所示,每个线程都有自己的本地存储器和寄存器堆。与处理器不同的是,GPU核心有很多寄存器来存储本地数据。当线程使用的数据不适合存储在寄存器堆中或者寄存器堆中装不下的时候,将会使用本地内存。寄存器堆和本地内存对每个线程都是唯一的。寄存器堆是最快的一种存储器。同一个块中的线程具有可由该块中的所有线程访问的共享内存。全局内存可被所有的块和其中的所有线程访问。它具有相当大的访问延迟,但存在缓存这种东西来给它提速。
GPU有一级和二级缓存(即L1缓存和L2缓存)。常量内存则是用于存储常量和内核参数之类的只读数据。最后,存在纹理内存,这种内存可以利用各种2D和3D的访问模式。
所有存储器特征总结如下
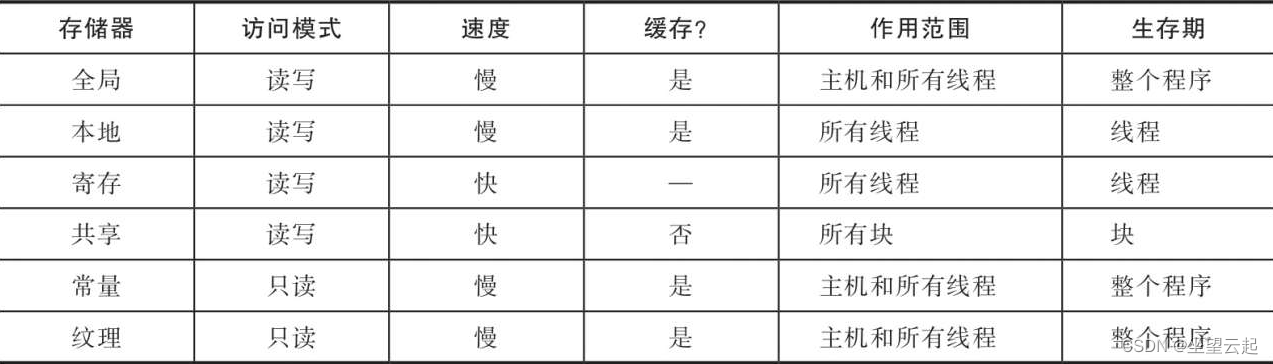
上表表述了各种存储器的各种特性。作用范围栏定义了程序的哪个部分能使用该存储器。而生存期定义了该存储器中的数据对程序可见的时间。除此之外,L1和L2缓存也可以用于GPU程序以便更快地访问存储器。
总之,所有线程都有一个寄存器堆,它是最快的。共享内存只能被块中的线程访问,但比全局内存块。全局内存是最慢的,但可以被所有的块访问。常量和纹理内存用于特殊用途。