MR的Uber模式
目标:了解MR的Uber模式的配置及应用
实施
- Spark为什么要比MR要快
- MR慢
- 只有Map和Reduce阶段,每个阶段的结果都必须写入磁盘
- 如果要实现Map1 -> Map2 -> Reduce1 -> Reduce2
- Mapreduce1:Map1
- MapReduce2:Map2 -> Reduce1
- Mapreduce3:Reduce2
- MapReduce程序处理是进程级别:MapTask进程、ReduceTask进程
问题:MR程序运行在YARN上时,有一些轻量级的作业要频繁的申请资源再运行,性能比较差怎么办?
Uber模式
功能:Uber模式下,程序只申请一个AM Container:所有Map Task和Reduce Task,均在这个Container中顺序执行

默认不开启
配置:${HADOOP_HOME}/etc/hadoop/mapred-site.xml

特点
- Uber模式的进程为AM,所有资源的使用必须小于AM进程的资源
- Uber模式条件不满足,不执行Uber模式
- Uber模式,会禁用推测执行机制
Sqoop采集数据格式问题
目标:掌握Sqoop采集数据时的问题
路径
- step1:现象
- step2:问题
- step3:原因
- step4:解决
实施
现象
- step1:查看Oracle中CISS_SERVICE_WORKORDER表的数据条数
![]()
- step2:采集CISS_SERVICE_WORKORDER的数据到HDFS上
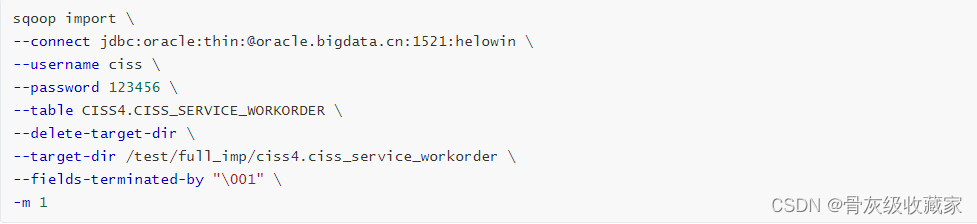
- step3:Hive中建表查看数据条数

问题:Sqoop采集完成后导致HDFS数据与Oracle数据量不符
原因
- sqoop以文本格式导入数据时,默认的换行符是特殊字符
- Oracle中的数据列中如果出现了\n、\r、\t等特殊字符,就会被划分为多行
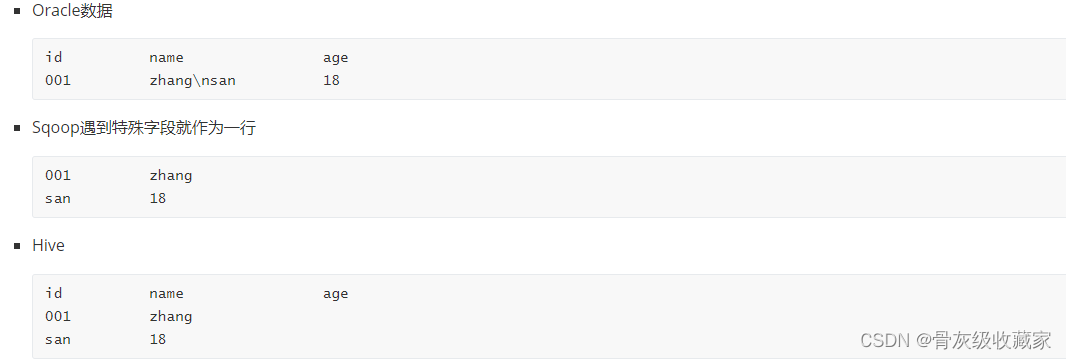
解决
- 方案一:删除或者替换数据中的换行符
- --hive-drop-import-delims:删除换行符
- --hive-delims-replacement char:替换换行符
- 不建议使用:侵入了原始数据
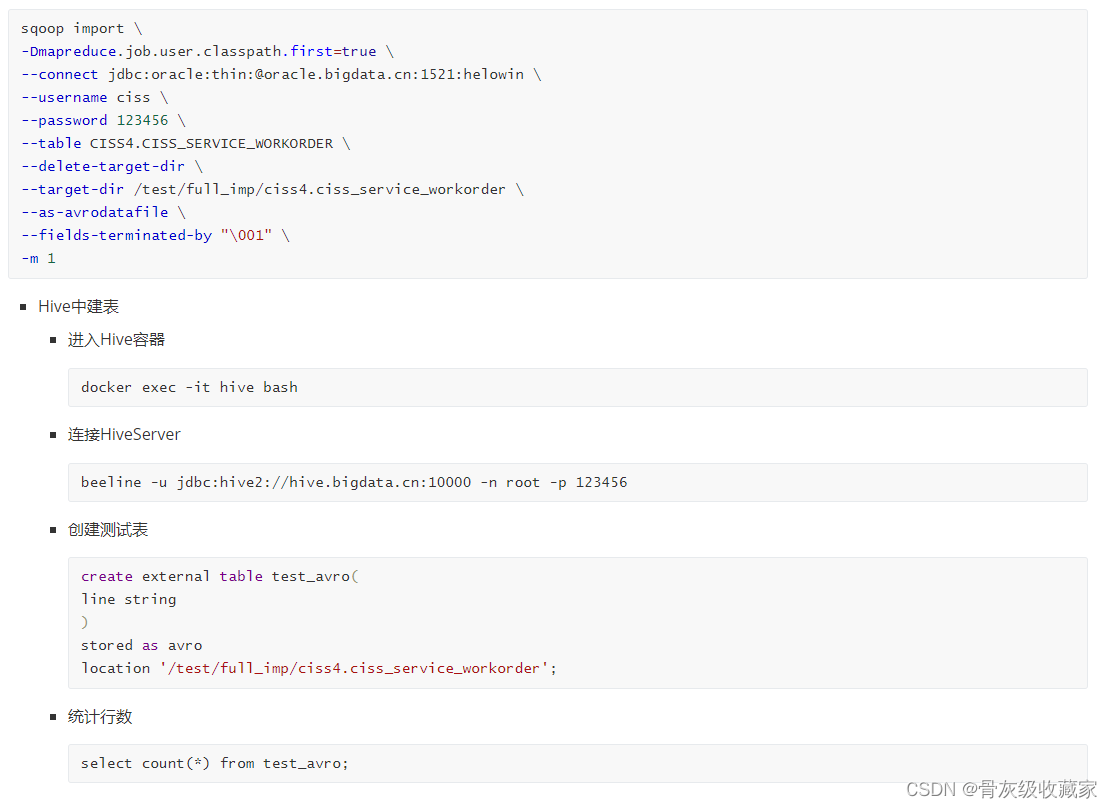
- 方案二:使用特殊文件格式:AVRO格式
问题解决:Avro格式
目标:掌握使用Avro格式解决采集换行问题
路径
- step1:常见格式介绍
- step2:Avro格式特点
- step3:Sqoop使用Avro格式
- step4:使用测试
实施
常见格式介绍

- SparkCore缺点:RDD【数据】:没有Schema
- SparkSQL优点:DataFrame【数据 + Schema】
- Schema:列的信息【名称、类型】
Avro格式特点
- 优点
- 二进制数据存储,性能好、效率高
- 使用JSON描述模式,支持场景更丰富
- Schema和数据统一存储,消息自描述
- 模式定义允许定义数据的排序
- 缺点
- 只支持Avro自己的序列化格式
- 少量列的读取性能比较差,压缩比较低
- 场景:基于行的大规模结构化数据写入、列的读取非常多或者Schema变更操作比较频繁的场景
Sqoop使用Avro格式

使用测试
Sqoop增量采集方案回顾
目标:回顾Sqoop增量采集方案
路径
- step1:Append
- step2:Lastmodified
- step3:特殊方式
实施
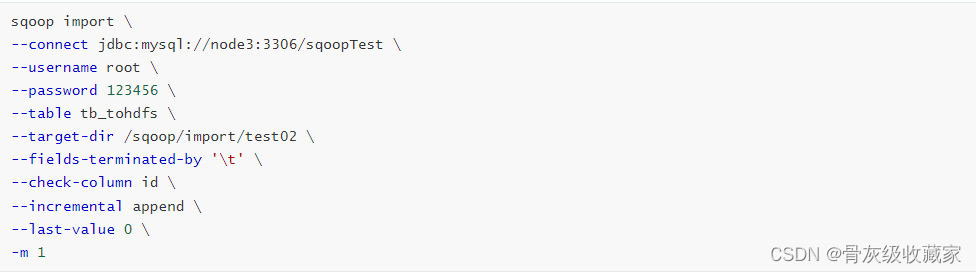
Append
- 要求:必须有一列自增的值,按照自增的int值进行判断
- 特点:只能导入增加的数据,无法导入更新的数据
- 场景:数据只会发生新增,不会发生更新的场景
- 代码
Lastmodified
- 要求:必须包含动态时间变化这一列,按照数据变化的时间进行判断
- 特点:既导入新增的数据也导入更新的数据
- 场景:一般无法满足要求,所以不用

特殊方式
- 要求:每次运行的输出目录不能相同
- 特点:自己实现增量的数据过滤,可以实现新增和更新数据的采集
- 场景:一般用于自定义增量采集每天的分区数据到Hive
- 代码

脚本开发思路
目标:实现自动化脚本开发的设计思路分析
路径
- step1:脚本目标
- step2:实现流程
- step3:脚本选型
- step4:单个测试
实施
脚本目标:实现自动化将多张Oracle中的数据表全量或者增量采集同步到HDFS中
实现流程
- a. 获取表名
- b.构建Sqoop命令
- c.执行Sqoop命令
- d.验证结果
脚本选型
- Shell:Linux原生Shell脚本,命令功能全面丰富,主要用于实现自动化Linux指令,适合于Linux中简单的自动化任务开发
- Python:多平台可移植兼容脚本,自身库功能强大,主要用于爬虫、数据科学分析计算等,适合于复杂逻辑的处理计算场景
- 场景:一般100行以内的代码建议用Shell,超过100行的代码建议用Python
- 采集脚本选用:Shell
单个测试
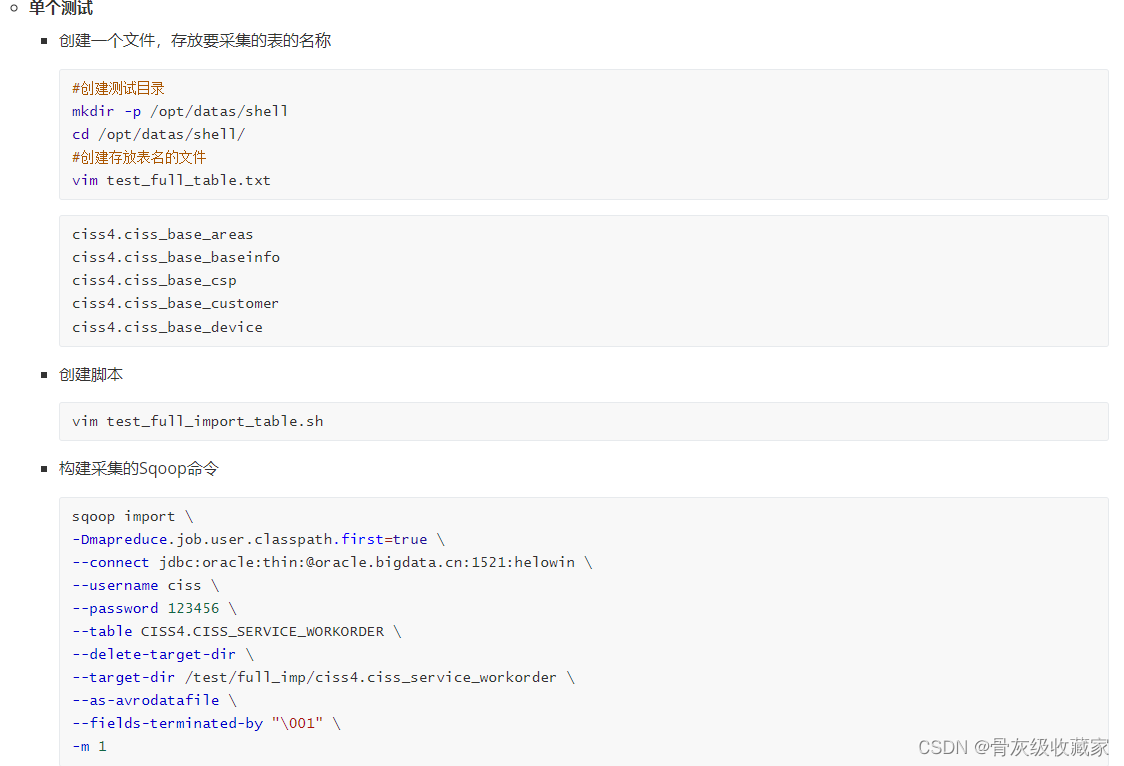
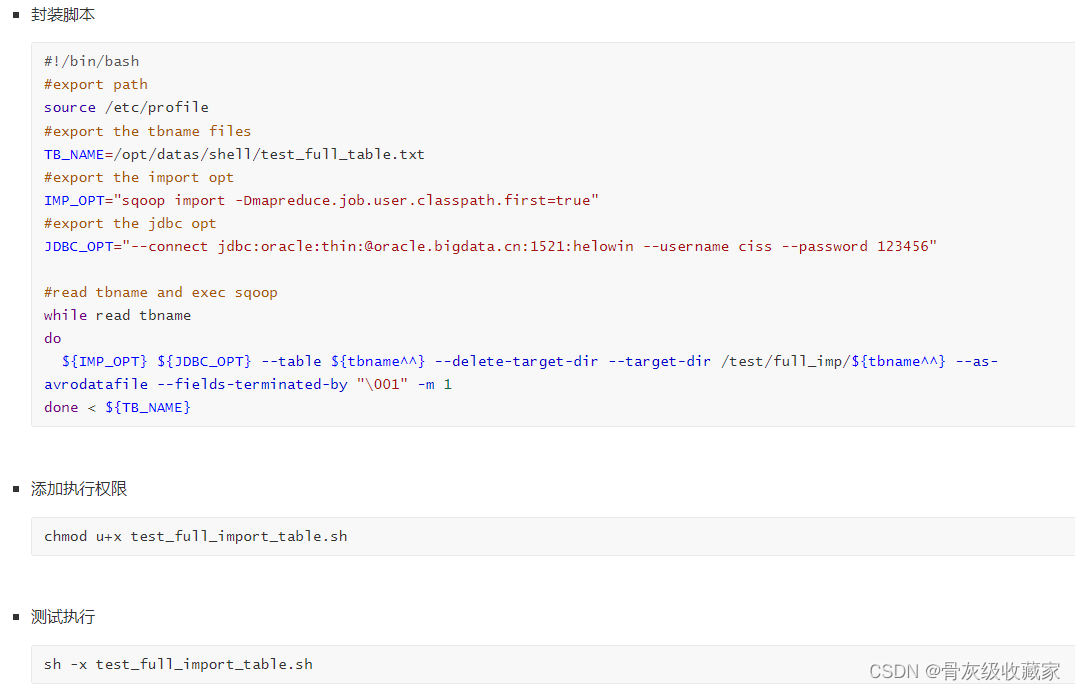
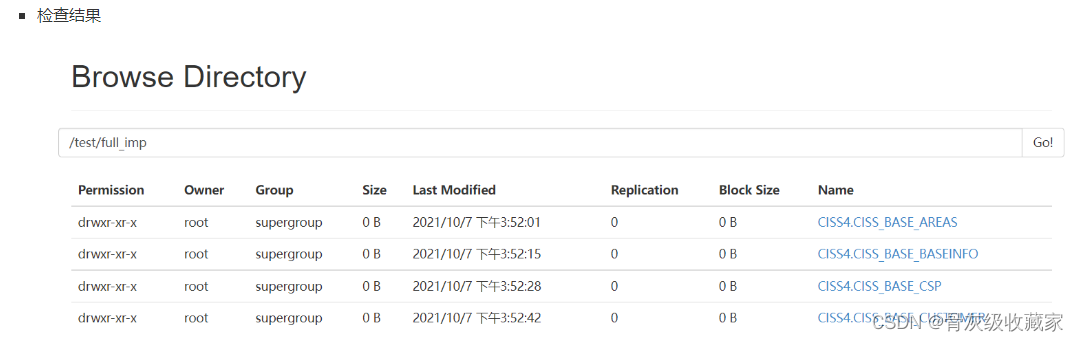
全量及增量采集脚本运行
目标:实现全量采集脚本的运行
实施
全量目标:将所有需要将实现全量采集的表进行全量采集存储到HDFS上
- Oracle表:组织机构信息、地区信息、服务商信息、数据字典等
- HDFS路径

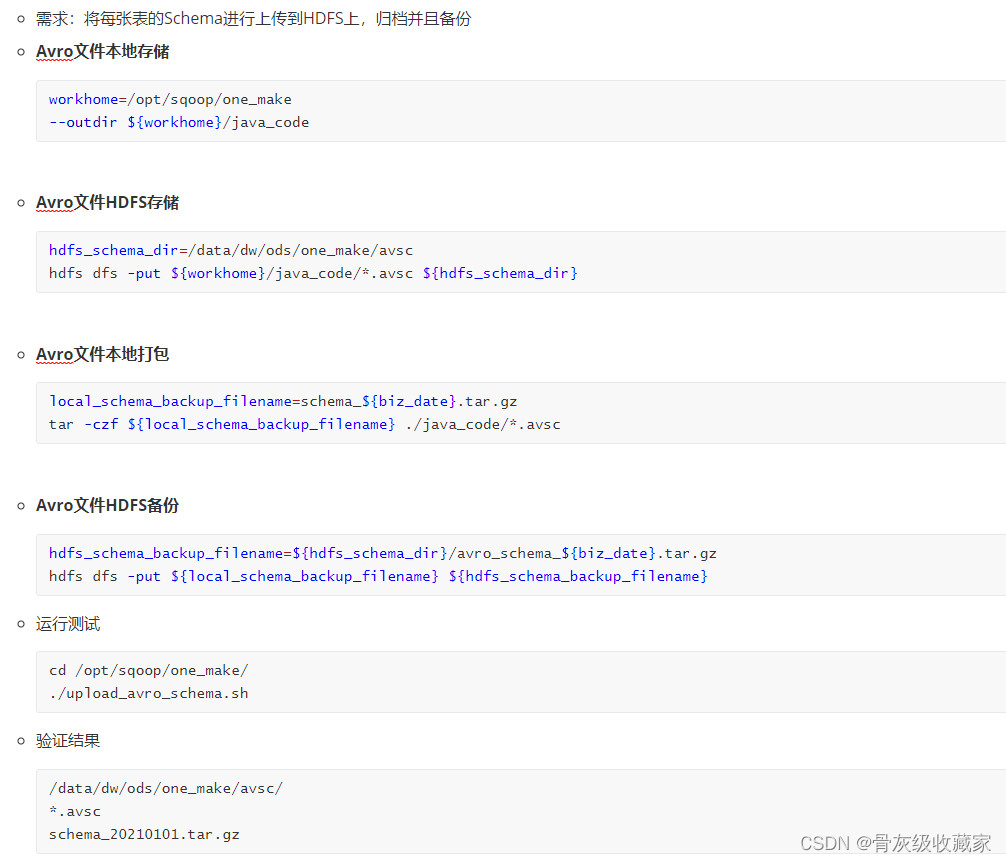
Schema备份及上传
目标:了解如何实现采集数据备份
实施
Python脚本
目标:了解如果使用Python脚本如何实现
实施
原理本质
- 问题:所有的操作是Sqoop、HDFS等命令操作,如何能通过Python代码控制?
- 解决:本质上是使用Python执行了Linux的Shell命令来实现的
- 导包