收藏和点赞,您的关注是我创作的动力
文章目录
- 概要
- 一、预测模型的实现
- 3.1数据的获取和预处理
- 3.2划分数据集
- 3.3构建神经网络
- 二、PyTorch框架
- 三 原理
- 2.1前馈神经网络
- 2.1.1 BP神经网络
- 四 预测效果验证
- 4.1小批量梯度下降
- 4.2批量梯度下降
- 4.3随机梯度下降
- 五 结 论
- 目录
概要
本文响应国家号召,利用近期发展迅猛的Python编程语言和PyTorch机器学习库,用天气和气候等信息作为特征变量构建一个基于BP神经网络的单车数量预测器,用于预测某一时刻、某一停放区域的单车数量。本文针对构建预测网络模型的过程和模型预测的效果,对Python编程语言和PyTorch机器学习库易用性和可移植性等特性作出评价,并讨论了将文章构建的BP神经网络迁移到教育领域以及其他领域的可能性。
【关键词】:共享单车;深度学习;数据预测
一、预测模型的实现
3.1数据的获取和预处理
本文所使用的数据来自加利福尼亚大学尔湾分校机器学习数据库[12]。它被世界各地的学生、教育工作者和研究人员广泛使用,是机器学习数据集的主要来源。本文使用了其中Seoul Bike Sharing Demand Data Set,该数据集包含了首尔单车([12])2017年12月到2018年12月期间每小时的租赁单车数量和日期信息以及对应的天气信息(温度、湿度、风速、能见度、露点温度、太阳辐射、降雪、降雨)等。选取数据集前两百条(即前两百小时)数据,将每小时单车被租赁的数量与时间的变化关系绘制图2。其中横坐标为数据的序号,即从数据记录开始后的小时数,纵坐标为对应小时共享单车租赁的数量。从图像上看,共享单车被租赁的数量随时间波动,并且呈现一定的规律性。对应到数据上,可以看出周末的共享单车使用量是低于工作日的。
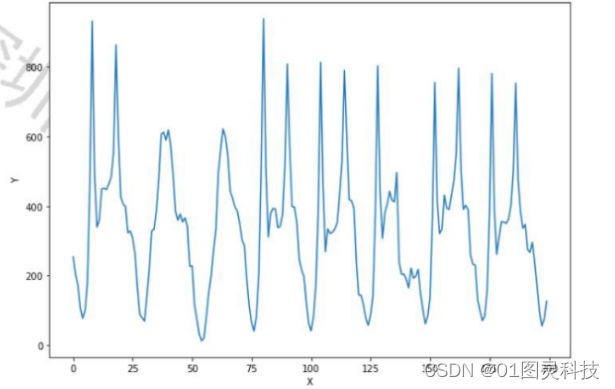
图2. 一段时间内每小时共享单车被租赁的数量与时间的变化关系图
由于数据集中各种信息数据多种多样,各个数据之间单位不同,变化的范围也不同,数量级的差异也比较大,如果直接使用数据输入构建的神经网络中,可能会让神经网络错误地理解数据数值的权重。而且在我们的数据源中,有些数据的值仅仅代表的是类型信息,这些数值并不是连续的值而是代表分类的值,数值的大小并没有意义。对数据源的数据,本研究分为数值变量和类型变量。并对这两种变量分别处理。数据的分类表格见表1。
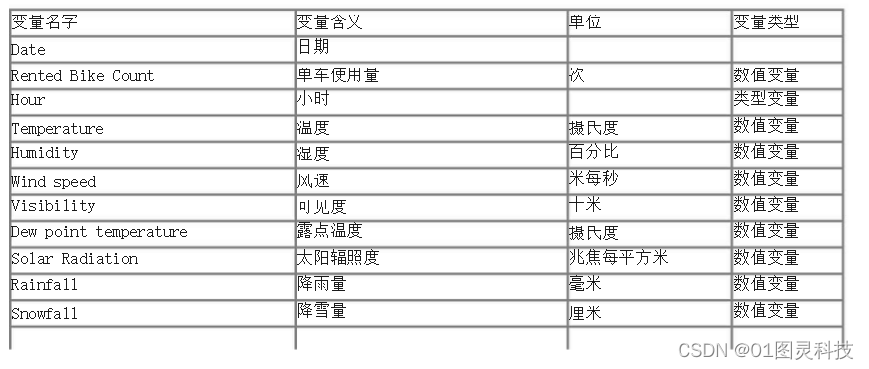 表1 变量类型
表1 变量类型
3.2划分数据集
数据集里包含首尔单车([13])2017年12月1日到2018年11月30日每小时的租赁单车数量和其它信息共8760条据。每条数据除了每小时的租赁单车数量和日期信息还包括对应的天气信息(温度、湿度、风速、能见度、露点温度、太阳辐射、降雪、降雨)。在对数据集中的数值变量和类型变量都进行预处理后,原来的13个变量转化成38个变量,原来的8760条数据筛选后剩余8465条数据。并且变量数值的范围被缩放到了一个较小的范围内。变量划分为特征变量和目的变量,特征变量为除了日期Data和Rented Bike Count的其他变量,目标变量为Rented BikeCount。使用特征变量来预测目的变量。本研究用留出法(Hold-out)划分数据集,将预处理后的数据集划分为两个互斥的集合。使用前8129条数据为训练集,用来训练神经网络;最后336条数据即最后两周的数据用来作为测试集,不参与神经网络的训练,检验模型的预测效果。训练集和测试集的比例大致为24.19:1。
3.3构建神经网络
本文构建人工神经网络为BP(Backpropagation)神经网络,是一种按误差反向传播算法训练的多层前馈网络,包含输入层、隐含层和输出层。该方法对网络中所有权重计算损失函数的梯度。这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。其中输入层包含日期信息和天气信息等38个神经元,中间的隐含层包括两层每层6个神经元,输出层包含1个神经元,负责输出预测的单车租赁数量。构建的神经网络模型结构如图3,由于图片大小限制部分神经元以省略号表示。
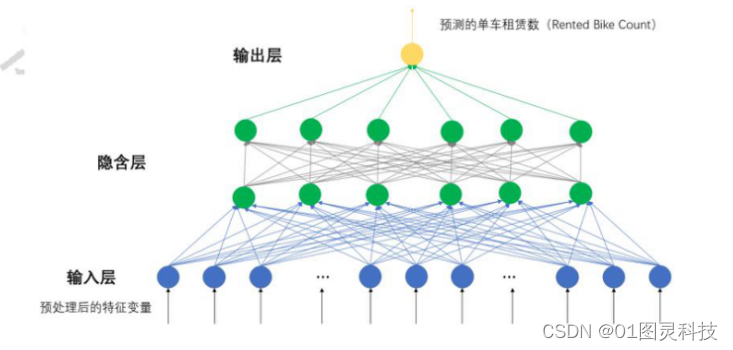 图3 单车租赁数量预测神经网络模型结构
图3 单车租赁数量预测神经网络模型结构
二、PyTorch框架
PyTorch是一个与TensorFlow、MXNet、Caffe等平齐的深度学习开源框架。然而,PyTorch简单易用,适合新手快速掌握。PyTorch支持张量计算(Tensor computation)和动态计算图(dynamic computation graph)。而且,PyTorch是一个完全面向Python的机器学习框架,对比其他深度学习框架,PyTorch对Python的支持非常完备,对于Python语言的使用者也是十分友好。PyTorch借助自动微分变量(autograd variable)来实现动态计算图,无论一个计算过程多么复杂,系统都会自动构造一张计算图来记录所有的运算过程。这样PyTorch使用者不需要为每一种架构的网络定制不同的反向传播算法,可以很轻松地利用PyTorch的函数,自动进行反向传播算法,从而计算每一个自动微分变量的梯度信息,很大程度减少了编程的工作量和学习深度学习的难度。
Python编程语言和PyTorch深度学习框架语法简洁易用,社区活跃,非常适合快速掌握。而且目前国际上排名前100的高校中80%都在开设Python程序设计课程,国内众多高校正在构建基于Python的程序设计教学体系, Python逐渐成为学习程序设计的第一选择[8]。本研究将使用基于Python编程语言的PyTorch深度学习框架,并使用天气和气候数据作为重要预测参数训练预测模型,以完成对同一地区范围内共享单车每小时的租赁数量的预测,帮助单车共享系统持续地运营下去。
三 原理
2.1前馈神经网络
前馈神经网络也叫全连接网络(fully connected neural network),是一种简单的神经网络。前馈神经网络各神经元分层排列,每个节点跟它的相邻层节点而且是全部节点相连。它一般包括三类人工神经单元,即输入层、隐含层和输出层。第零层称为输入层,最后一层称为输出层,其他中间层称为隐藏层。前馈神经网络的常见结构如图1,其中每个神经元只与前一层的神经元相连,接收前一层的输出,并输出给下一层。前馈神经网络是目前应用最广泛、发展最迅速的人工神经网络之一。关于前馈神经网络的研究从20世纪60年代开始,目前理论研究和实际应用达到了很高的水平。前馈神经网络具有很强的拟合能力,常见的连续非线性函数都可以用前馈神经网络来近似[10]。
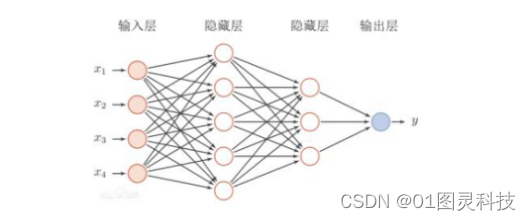
图1.前馈神经网络常见结构[9]
图中的每一个圆圈代表一个人工神经元,连线代表人工突触,它将两个神经元联系起来。每条连边上都包含一个数值,即权重,用w表示。
2.1.1 BP神经网络
BP神经网络(back propagation neural network),即反向传播神经网络。BP神经网络是指神经元连边权重调整采用了反向传播(Back Propagation)学习算法的前馈网络。BP神经网络使用梯度下降法,用一定数量的均方误差的负梯度方向对权重进行调节,其运行常包含前馈的预测过程(或称为决策过程)和反馈的学习过程。
在前馈即前向传播阶段的预测过程中,信号从输入单元输入,并沿着网络连边传输,每个信号在传输时与连边上的权重进行乘积,得到隐含层单元的输入;接下来,隐含层单元对所有连边输入的信号进行汇总(求和),然后经过激活函数处理进行输出;这些输出的信号再乘以从隐含层到输出层的连线上的权重,从而得到输入给输出单元的信号;最后,输出单元再对每一条输入连边的信号进行汇总,并进行加工处理再输出。最后的输出就是整个神经网络的输出。神经网络在训练阶段将会不断调节每条连边上的权重w数值[11]。
在反馈即反向传播阶段的学习过程中,每个输出神经元会首先计算出它的预测误差,然后将这个误差沿着网络的所有连边进行反向传播,将误差传递给隐含层神经元,然后调节隐含层到输出层的连接权重。最后,再调整输入层到隐含层的连接权值。在调整每条连边所连通的两个节点的误差更新连边上的权重的过程中,完成网络的学习与调整。
四 预测效果验证
使用训练好的神经网络对测试集进行预测,将预测结果与实际数据绘制在同一坐标系。由于在数据预处理的时候对每小时单车租赁数进行了标准化处理,要想观察真实的单车租赁数曲线需要将数据还原,还原公式如下( 为原始数, 为样本总体的平均值, 为总体的标准差)训练的神经网络预测数据与实际数据对比图见图8和图9。
4.1小批量梯度下降
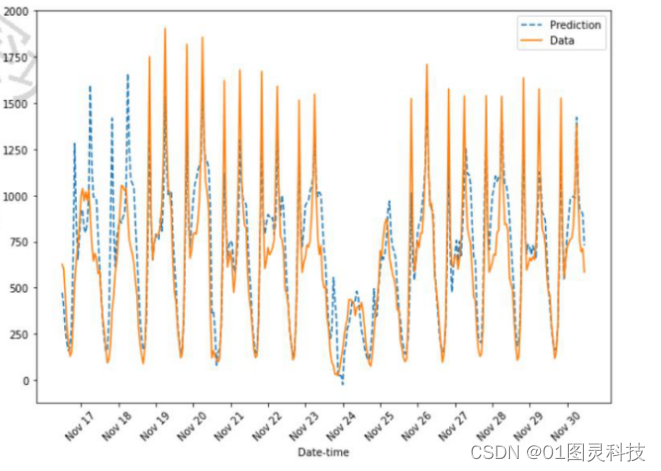
图8 使用MBGD训练的神经网络预测数据与实际数据对比图
4.2批量梯度下降
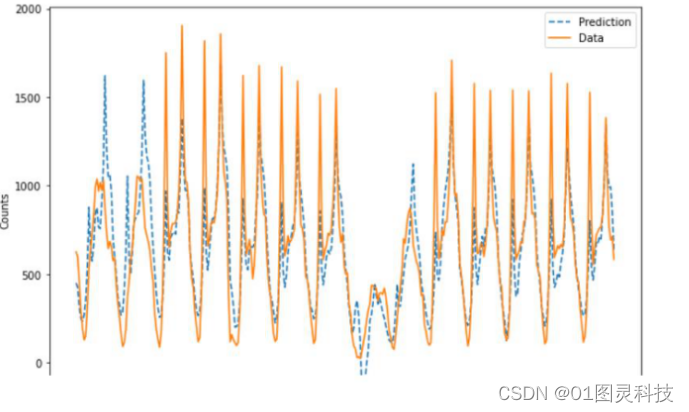
图9 使用BGD训练的神经网络预测数据与实际数据对比图
4.3随机梯度下降
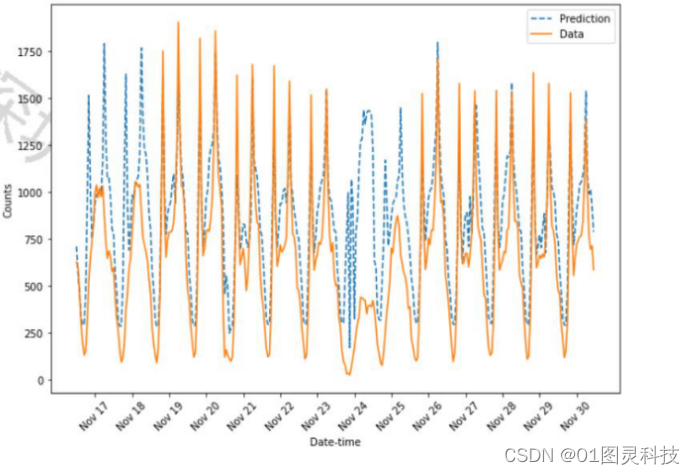
图10 使用SGD训练的神经网络预测数据与实际数据对比图
五 结 论
在构建本研究的共享单车使用量预测模型的过程中,Python编程语言和PyTorch学习框架的种种特性给研究带来了很大便利。Python编程语言语法简洁,抽象程度高,易于初学者入门。而且文档细致,社区活跃,在本研究编写和调试代码时,遇到问题基本都可以通过查看开发者文档或者去社区查找对应问题解决。而且Python语言的标准库和第三方库十分丰富,在本研究在处理数据和绘制图像时就大量使用了pandas库、Numpy库和Matplotlib库。最为关键的,也就是本研究核心的机器学习框架PyTorch也是属于Python的第三方库。在数据处理方面,PyTorch的tensor
和NumPy支持相互转换,这就意味着可以利用NumPy库进行数据处理再将它转换为PyTorch里的张量tensor,PyTorch可以和NumPy结合,充分发挥NumPy在科学计算和数据处理的优点。在构建深度学习网络方面,PyTorch借助自动微分变量(autograd variable)实现动态计算图,而且在PyTorch 1.5中,自动微分变量已经与张量完全合并了,任何一个张量都支持自动微分变量。当使用了自动微分变量后,无论计算过程有多复杂,系统都能自动生成计算图,记录下所有的运算过程。利用PyTorch的动态计算图,就能很方便地利用PyTorch里的函数,获得每一个自动微分变量的梯度信息,实现反向传播算法的自动化。PyTorch还自带针对不同算法的优化器,通过这些优化器,PyTorch能非常便捷地优化所有待优化的所有参数。此外,PyTorch中的张量还支持通过CUDA在GPU中计算,大大提高了运算速度。得益于Python编程语言和PyTorch深度学习框架的种种特性,使用PyTorch深度学习框架构建一个深度学习网络模型十分便捷,而且如果需要调整深度学习网络模型结构也十分方便。并且,PyTorch支持使用GPU进行运算,训练深度学习网络的速度也十分快捷。Python编程语言和PyTorch深度学习框架让构建一个深度学习网络变得十分简单,而且修改和迁移学习模型也变得前所未有的方便。对于深度学习初学者和机器学习爱好者来说,PyTorch深度学习框
架是一个非常好的选择。如果要学习人工智能,从利用PyTorch构建一个深度学习网络,将会是一个不错的入门项目。
目录
目录
基于PyTorch的共享单车使用数量预测2
1前言2
2原理4
2.1前馈神经网络4
2.2激活函数5
2.3损失函数6
2.4梯度下降法6
3预测模型的实现7
3.1数据的获取和预处理7
3.2划分数据集10
3.3构建神经网络10
4预测效果验证14
4.1小批量梯度下降14
4.2批量梯度下降15
4.3随机梯度下降16
4.4预测结果总结16
5结论与展望18
5.1关于Python编程语言与PyTorch学习框架18
5.2 预测模型的推广19
参考文献:20
致谢21
![[H5动画制作系列]随机抽取数字](https://img-blog.csdnimg.cn/08c235f265d7454d8a6d075b0d740a85.png)

![[架构之路-248/创业之路-79]:目标系统 - 纵向分层 - 企业信息化的呈现形态:常见企业信息化软件系统 - 供应链管理](https://img-blog.csdnimg.cn/6a164a416a1a4a92827fc514f4b69b2c.png)