前言
MyBatis 执行 SQL 的核心接口为 SqlSession 接口,该接口提供了一些 CURD 及控制事务的方法,另外还可以通过 SqlSession 先获取 Mapper 接口的实例,然后通过 Mapper 接口执行 SQL,Mapper 接口方法的执行最终还是委托到 SqlSession 中的方法。因此可以由 SqlSession 入手分析 SQL 执行流程。由于本篇文章内容较多,感兴趣的小伙伴可以先收藏,待空闲时间耐心阅读,或直接翻到最后查看总结。
SQL 执行流程分析
MyBatis 中的 SQL 都是由 SqlSession 进行执行,由于日常工作中使用的 SQL 类型多为查询,并且 MyBatis 中的查询也最为复杂,因此本篇以 SqlSession#selectList(String, Object, RowBounds) 作为入口进行分析,中间穿插 SqlSession 的其他 API 介绍,重要的组件将在后面的章节中单独列出。
public interface SqlSession extends Closeable {
<E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds);
}
#selectList 的方法定义如上所示,该方法查询数据库然后将结果转换为用户需要的类型。各参数的具体含义如下。
statement:表示 SQL 语句的标识,Mapper 接口中的方法调用时会使用 接口全限定名. 方法名,对应 Mapper xml 配置中 mapper 节点 namespace.select 节点 id。
parameter:MyBatis SQL 语句中的参数,可以是原生类型或原生类型的 包装类,可以是 Map ,也可以是其他的 Object,如果 Mapper 接口方法中包含多个参数将转换为 Map,MyBatis 取 Map 或 Object 中的字段值替换 Mapper xml 文件中的 ${paramName} 或将 #{paramName} 指定的 SQL 参数设置为对应的字段值。
rowBounds:分页信息,包含 offset 和 limit ,MyBatis 在内存中对返回的结果进行分页。
了解方法的功能后,我们再看方法的实现,MyBatis 中 SqlSession 默认的实现为 DefaultSqlSession,跟踪源码。
public class DefaultSqlSession implements SqlSession {
// Mybatis 配置
private final Configuration configuration;
// 执行器
private final Executor executor;
@Override
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
}
SqlSession 进行数据库查询时先从配置中获取表示 SQL 语句的 MappedStatement,然后使用执行器 Executor 进行执行。调用的 Executor#query 方法定义如下。
public interface Executor {
<E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException;
}
Executor 执行查询时多了一个新的参数 ResultHandler,它用于处理每一行数据库记录对应的 Java 对象,例如可以将结果保存到 List 或者 Map 中。Executor 作为接口具有多个实现,CachingExecutor 和其他 Executor 相比仅多了 Statement 级别缓存的支持,因此我们跟踪 BaseExecutor#query 方法的实现。
public abstract class BaseExecutor implements Executor {
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameter);
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
}
BaseExecutor 先使用 MappedStatement 获取到 BoundSql 的实例,然后创建了表示当前查询的 CacheKey,最后调用了另一个 #query 方法。
BoundSql:MappedStatement 包含 MyBatis 执行 SQL 需要的完整元数据,如结果映射、参数映射、动态 SQL 等,MappedStatement 将动态 SQL 解析后生成 BoundSql,BoundSql 仅包含最终执行的 SQL 及参数信息。
CacheKey:MyBatis 可以将每个 SQL 的查询结果缓存下来,CacheKey 就是用来表示缓存的 key 值,它由 SQL、参数、分页等构成,当下次使用相同的条件查询数据库时可以优先从缓存获取到查询结果。
了解完这些参数后再看调用的 #query 方法。
public abstract class BaseExecutor implements Executor {
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
... 省略校验及缓存处理代码
List<E> list;
try {
queryStack++;
// 优先从缓存获取
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
// 处理存储过程 OUT 参数
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 缓存中没有数据,从数据库中查询
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
... 省略缓存处理相关代码
return list;
}
}
为了将重点放在主要流程,上面的代码省略了部分缓存处理的方法,关于缓存处理将在后面单独分析。#query 方法优先从缓存中获取查询结果,如果没有获取到则会从数据库进行查询,再看数据库查询的代码。
public abstract class BaseExecutor implements Executor {
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 执行数据库查询
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
// 将查询结果缓存
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
protected abstract <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql)
throws SQLException;
}
#queryFromDatabase 调用 #doQuery 方法进行数据库查询,然后将查询结果缓存下来。#doQuery 是一个抽象方法,我们看其在默认使用的 SimpleExecutor 中的实现。
public class SimpleExecutor extends BaseExecutor {
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 创建 Statement,设置 SQL 参数
stmt = prepareStatement(handler, ms.getStatementLog());
// 使用 StatementHandler 执行查询
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
// 准备好 Statement
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
// 创建 Statement
stmt = handler.prepare(connection, transaction.getTimeout());
// 设置 SQL 参数
handler.parameterize(stmt);
return stmt;
}
}
到了这里,终于看到了熟悉的 JDBC API。#doQuery 方法先使用配置创建了一个 StatementHandler,使用 StatementHandler 创建 Statement 并设置了 SQL 的参数后就开始调用 #StatementHandler#query 执行数据库查询。StatementHandler 用于创建 StatementHandler、设置参数、执行 SQL,如果没有指定则使用
PreparedStatementHandler。
先看 StatementHandler 创建 Statement 的方法 #prepared。
public abstract class BaseStatementHandler implements StatementHandler {
@Override
public Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException {
ErrorContext.instance().sql(boundSql.getSql());
Statement statement = null;
try {
// 实例化 Statement
statement = instantiateStatement(connection);
// 设置 Statement 的数据库参数
setStatementTimeout(statement, transactionTimeout);
setFetchSize(statement);
return statement;
} catch (SQLException e) {
closeStatement(statement);
throw e;
} catch (Exception e) {
closeStatement(statement);
throw new ExecutorException("Error preparing statement. Cause: " + e, e);
}
}
// 实例化 Statement
protected abstract Statement instantiateStatement(Connection connection) throws SQLException;
}
StatementHandler#prepared 方法由基类 BaseStatementHandler 实现,先调用了模板方法 #instantiateStatement 实例化 Statement,然后设置 Statement,模板方法由具体的子类实现,如 PreparedStatementHandler 会实例化出 PreparedStatement。
再跟踪 StatementHandler 的实现 PreparedStatementHandler 设置参数的 #parameterize 方法。
public class PreparedStatementHandler extends BaseStatementHandler {
@Override
public void parameterize(Statement statement) throws SQLException {
parameterHandler.setParameters((PreparedStatement) statement);
}
}
由于 PreparedStatement 需要设置参数,因此这里 PreparedStatementHandler 将设置参数的动作委托给 ParameterHandler 进行处理。
再看 StatementHandler 查询数据的方法 StatementHandler#query 的实现。
public class PreparedStatementHandler extends BaseStatementHandler {
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
return resultSetHandler.handleResultSets(ps);
}
}
PreparedStatementHandler 先调用 PreparedStatement#execute 方法执行 SQL,然后使用 ResultSetHandler 将查询结果转换为需要的类型。ResultSetHandler 会根据 resultMap 将数据库记录转换为 Mapper 接口方法返回的对象,由于其内部实现比较复杂,这里暂不进行分析。
MappedStatement
概念理解:根据 CURD 四种 SQL 类型,Mapper xml 文件中操作数据库的节点分为 insert、update、select、delete 四种,对应到 Mapper 接口方法上可以使用的注解则为 @Insert、@Update、@Select、@Delete,MappedStatement 表示这四种语句的元数据,MyBatis 将其保存在 Configuration 中。
解析存储:MyBatis 解析 Mapper xml 文件时会使用 xml 节点中的元数据构建 MappedStatement 实例然后添加到 Configuration,也可以直接将 Mapper 接口直接添加到 Configuration,此时会使用 Mapper 接口中的注解信息构建 MappedStatement 然后添加到 Configuration。
源码位置:参见 XMLMapperBuilder#buildStatementFromContext(List)、MapperAnnotationBuilder#parseStatement
Executor
概念理解:Executor 接口是 SQL 的执行器,它根据 SQL 语句的抽象 MappedStatement 及参数操作数据库,返回操作结果,如果进行数据库查询还可以将结果转换为用户期望的类型。
配置 Executor:通常情况下在 MyBatis 中不需要显式指定具体 Executor,如果需要指定则有以下两种方式。
xml 配置文件中 /configuration/settings 节点下指定 defaultExecutorType 的值来配置默认的 Executor。
通过 Configuration#newExecutor(Transaction, ExecutorType) 方法创建 Executor 的实例。
Executor 接口定义:Executor 接口定义如下。
public interface Executor {
// 数据库新增、修改、或删除
int update(MappedStatement ms, Object parameter) throws SQLException;
// 数据库查询
<E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey cacheKey, BoundSql boundSql) throws SQLException;
<E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException;
<E> Cursor<E> queryCursor(MappedStatement ms, Object parameter, RowBounds rowBounds) throws SQLException;
// 支持批处理的 Executor 批量执行 SQL
List<BatchResult> flushStatements() throws SQLException;
// 事务管理
void commit(boolean required) throws SQLException;
void rollback(boolean required) throws SQLException;
Transaction getTransaction();
// 从缓存中加载对象的属性值,或记录要从缓存中获取的属性
void deferLoad(MappedStatement ms, MetaObject resultObject, String property, CacheKey key, Class<?> targetType);
// 连接管理
void close(boolean forceRollback);
boolean isClosed();
// 设置当前 Executor 的包装器
void setExecutorWrapper(Executor executor);
}
Executor 实现:Executor 作为一个接口在 MyBatis 中有多种实现,类图如下。
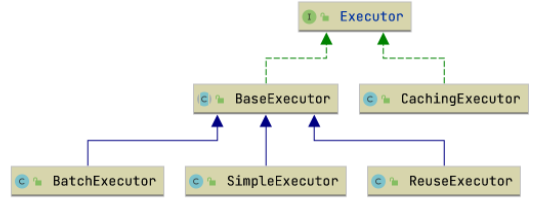
BaseExecutor:Executor 的基类。
SimpleExecutor:MyBatis 中默认的 Executor。
ReuseExecutor:复用 Statement 的 Executor,对于相同的 SQL,使用的是同一个 Statement。
BatchExecutor:支持批处理的 Executor,每次执行 #update 方法时会将 SQL 添加到 Statement 中,直到调用 #flushStatements 方法开始提交到数据库执行。
CachingExecutor:作为其他 Executor 的包装器,支持 Statement 级别的缓存,其他 Executor 仅支持 Session 级别的缓存。
ResultHandler
ResultHandler 用于处理 MyBatis 将某一条数据库记录转换成的 Java 对象,通常会将转换结果保存到其内部,待使用时再获取。其接口定义如下。
public interface ResultHandler<T> {
// 处理每一行对应的值
void handleResult(ResultContext<? extends T> resultContext);
}
接口中只有一个方法,根据结果 (即数据库单行记录对应的 Java 对象) 的上下文处理结果。ResultHandler 在 MyBatis 中的实现有两个,具体如下。
DefaultResultHandler:将结果存储至内部的 List,Mapper 接口方法返回类型为 List 时使用。
DefaultMapResultHandler:将结果存储至内部的 Map 中,Mapper 接口方法返回类型为 Map 时使用,此时需要在 Mapper 方法上使用 @MapKey 注解指定 key 使用结果的哪个属性。
StatementHandler
StatementHandler 表示 JDBC 中 Statement 的处理器,用于创建 Statement、设置 Statement 中的 SQL 参数、执行 SQL,接口定义如下。
public interface StatementHandler {
// 创建 Statement,并设置数据库相关参数
Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException;
// 设置 Statement 中的 SQL 参数
void parameterize(Statement statement) throws SQLException;
// 将 SQL 添加到批量执行列表中
void batch(Statement statement) throws SQLException;
// 执行 添加、更新、删除 SQL
int update(Statement statement) throws SQLException;
// 执行查询
<E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException;
<E> Cursor<E> queryCursor(Statement statement) throws SQLException;
// 获取 SQL 信息
BoundSql getBoundSql();
// 获取参数处理器
ParameterHandler getParameterHandler();
}
根据不同的 Statement 类型,StatementHandler 具有不同的实现,其设计和 Executor 很类似,具体如下。
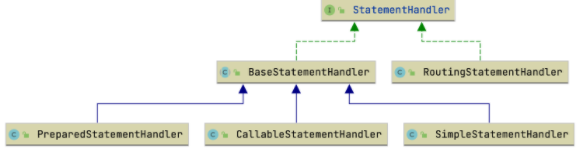
BaseStatementHandler:抽象的 StatementHandler 基类,提供子类的通用实现。
SimpleStatementHandler:简单 StatementHandler,处理普通的 Statement。
PreparedStatementHandler:支持预处理的 StatementHandler,处理 PreparedStatement。
CalableStatementHandler:支持存储过程的 StatementHandler,处理 CallableStatement。
RoutingStatementHandler:其他 StatementHandler 的装饰器,根据 Statement 的类型委托给其他 StatementHandler 做具体的处理。
ParameterHandler
ParameterHandler 是 SQL 参数的处理器,用于设置 SQL 中的参数。其定义比较简单,具体如下,它只有一个默认的实现 DefaultParameterHandler。
public interface ParameterHandler {
// 获取参数对象,该对象包含 SQL 中可用的参数
Object getParameterObject();
// 设置 SQL 参数
void setParameters(PreparedStatement ps) throws SQLException;
}
ResultSetHandler
ResultSetHandler 是 ResultSet 的处理器,当 Statement 执行 SQL 之后,就会使用 ResultSetHandler 处理产生的 ResultSet,ResultHandler 会根据 Mapper xml 文件中定义的 resultMap 或 resultType 将数据库记录转换为 Mapper 接口方法的返回值类型。对于每一行转换为的 Java 对象,使用 ResultHandler 进行处理。该接口默认的实现是 DefaultResultSetHandler ,该接口定义如下。
public interface ResultSetHandler {
// 处理 ResultSet 为 List
<E> List<E> handleResultSets(Statement stmt) throws SQLException;
// 处理 ResultSet 为 Cursor
<E> Cursor<E> handleCursorResultSets(Statement stmt) throws SQLException;
// 处理存储过程 OUT 参数
void handleOutputParameters(CallableStatement cs) throws SQLException;
}
总结
前面以 SqlSession 的方法为入口,分析了 SQL 在 MyBatis 内部执行的代码,并对重要的 API 进行了介绍,这里使用文字的方式进行总结整个过程。
首先我们会使用 SqlSessionFactoryBuilder 构建 SqlSessionFactory。期间 MyBatis 会解析 Mapper xml 文件或注解,生成 SQL 语句元数据 MappedStatement,并保存到 Configuration 中。
使用 SqlSessionFactory 获取 SqlSession,默认的 SqlSession 是 DefaultSqlSession。
使用 SqlSession 获取 Mapper 接口实现,或直接执行 SqlSession 其他方法操作数据库。
SqlSession 根据语句的标识从 Configuration 中获取 MappedStatement,然后委托 Executor 操作数据库。
Executor 优先从缓存中获取数据,如果缓存中没有则执行数据库查询,对于 update 操作会先刷新缓存。
Executor 使用 Configuration 创建出 Statement 的处理器 StatementHandler,委托 StatementHandler 执行数据库操作。
StatementHandler 先实例化出 Statement,然后使用 ParameterHandler 设置 SQL 的参数,最后执行 Statement。
StatementHandler 委托 ResultSetHandler 处理结果集。
ResultSetHandler 处理结果集,根据 resultMap 或 resultType 将每一行数据库的记录转换为 Java 对象,然后将 Java 对象交由 ResultHandler 处理,最后转换为 Mapper 接口方法的返回类型。