毕业论文选题结束后,需要根据不同的研究主题以及研究目的确定相应的分析方法。同类型的研究方法有很多种,今天梳理了毕业论文写作的常用分析方法,分模块进行汇总整理,方便大家对照查找。
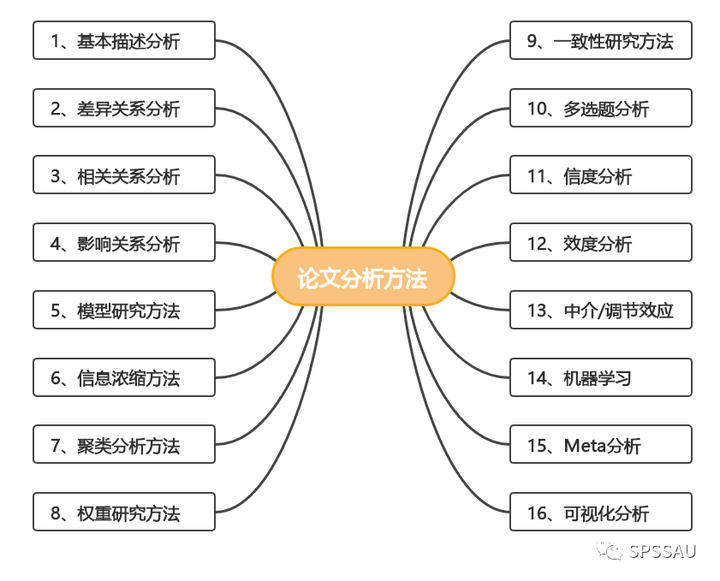
一、基本描述分析
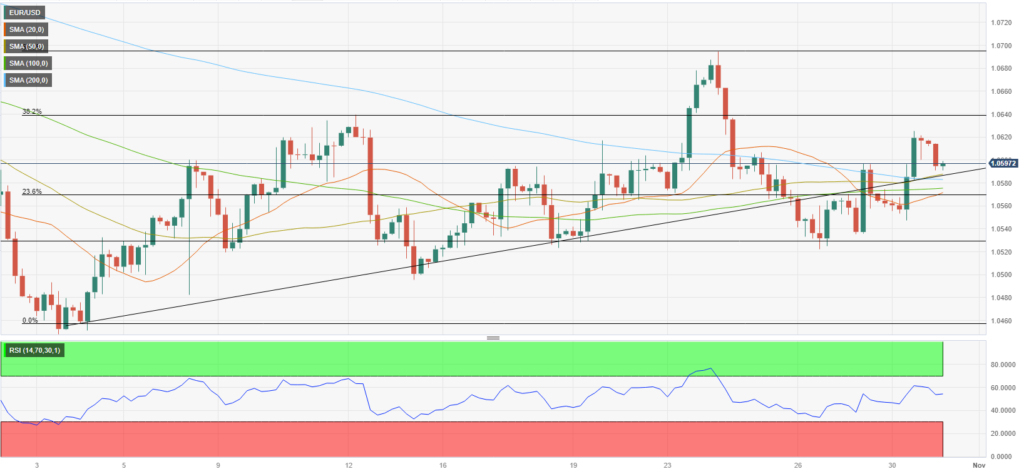
基本描述统计分析包括频数分析、描述分析、分类汇总;用于对收集的数据进行基本的说明:

- 频数分析:针对定类数据进行分析,一般使用频数、百分比、饼图等形式进行描述。
- 描述分析:针对定量数据进行分析,常见的指标有平均值、标准差、最大值、最小值、中位数等;更深入的描述指标包括百分位数、峰度、偏度、变异系数等。
- 分类汇总:用于研究不同分类时的汇总情况,输出的指标为汇总结果。比如不同区域分类项,销售额(汇总项)的差异情况。
二、差异关系分析
差异关系分析指对两个或多个事物之间的差异进行研究和分析的过程。这种分析可以帮助我们了解不同事物之间的差异,以及这些差异如何影响它们各自的表现和性能。论文写作中常用的差异关系分析方法有方差分析、t检验、卡方检验、非参数检验。
1、方差分析
方差分析用于进行X定类数据(2类及以上)与Y定量数据之间的差异关系研究;按照研究内容和数据类型等不同,可分为以下6类:

为方便大家理解,分别举一个例子进行说明:
- 单因素方差:研究不同学历(本科、研究生、博士)工资水平的差异。
- 双因素方差:研究不同性别、不同学历工资水平的差异。
- 多因素方差:研究不同性别、不同学历、不同岗位工资水平的差异。
- 协方差分析:研究减肥方式对于减肥效果的影响,同时将年龄设为干扰项。
- 事后多重比较:例如在单因素方差分析中,具体对比本科与研究生、本科与博士、研究生与博士两两之间的工资差异。
- 重复测量方差:研究抑郁症,共有12名患者,分别6名患者使用新药或者旧药;并且分别测试12名患者用药后分别第1周,第4周和第8周时的抑郁程度。
2、t检验
t检验用于分析X定类数据(仅2类)与Y定量数据之间的差异情况,按照研究内容和数据类型等不同,可分为以下3类:

举例说明:
- 独立样本t检验:分析班级不同性别(男女仅2类)数学成绩的差异。
- 配对样本t检验:分析两种方法测量同一批人的血压结果是否有差异。
- 单样本t检验:分析某班数学成绩与80分之间的差异。
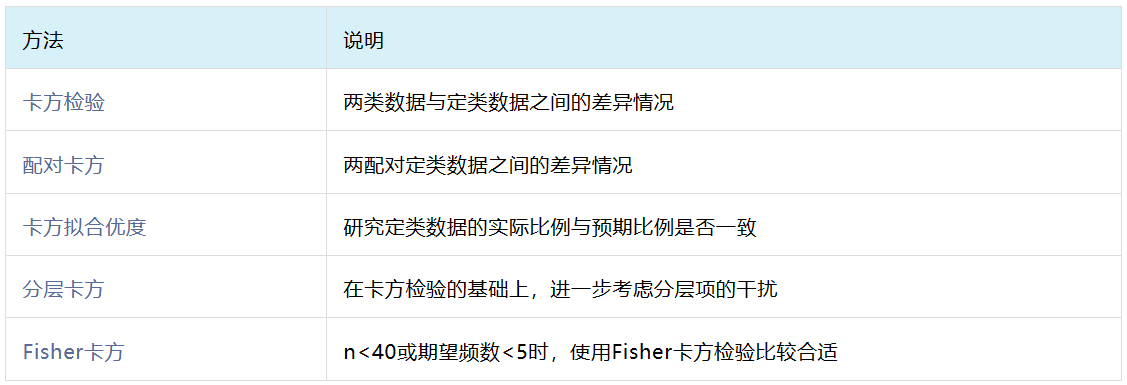
3、卡方检验
卡方检验用于分析定类数据与定类数据之间的差异情况,按照研究内容和数据类型等不同,可分为以下5类:
举例说明:
- 卡方检验:研究不同性别是否吸烟的差异情况。
- 配对卡方:研究两种方法检验结果(阳性&阴性)是否有差异。
- 卡方拟合优度:某研究收集的样本男女比例是否为6:4。
- 分层卡方:研究是否吸烟与是否生病的关系时,将性别纳入考虑范畴。
- Fisher卡方:在分析样本量较少(比如小于40),也或者期望频数出现小于5时,此时使用fisher卡方检验较为适合。
4、非参数检验
方差分析与t检验均属于参数检验的范围,通常需要数据满足正态性和方差齐性才能够使用,当数据不满足正态性或方差齐性时,研究定类数据与定量数据之间的差异性可以使用非参数检验进行分析。
常用的非参数检验如下:
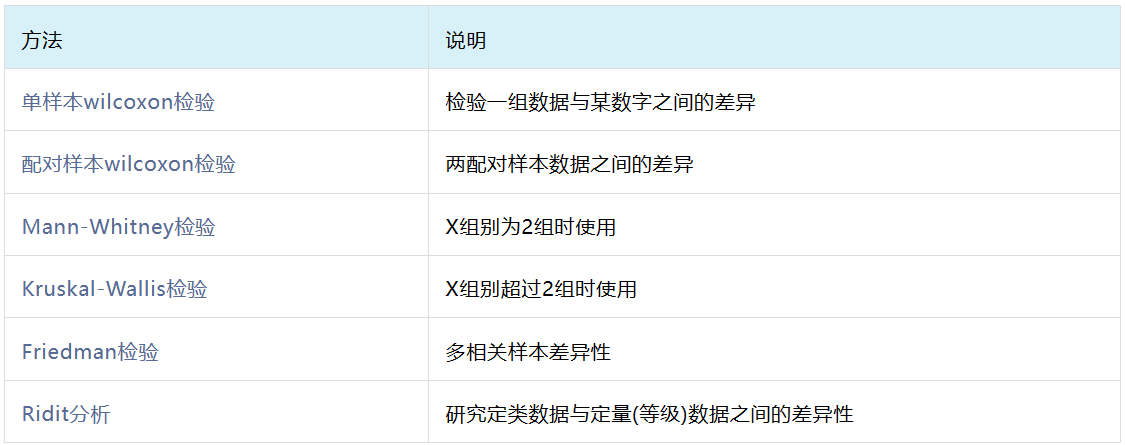
三、相关关系分析
相关分析用于分析变量之间的相关关系,相关分析具体可分为以下3种:

四、影响关系分析
影响关系分析是指对不同因素和变量之间的相互关系进行分析和研究。这种分析可以帮助我们了解事物之间的相互作用和影响,从而更好地预测和控制事物的发展趋势。
1、线性回归分析
通常先有相关关系再有回归影响关系,相关分析后再进行回归分析。根据因变量Y的数据类型不同,常用的回归模型可分为线性回归(Y为定量数据)和logistic回归(Y为定类数据)两大类。
下面介绍几种常用的线性回归模型:
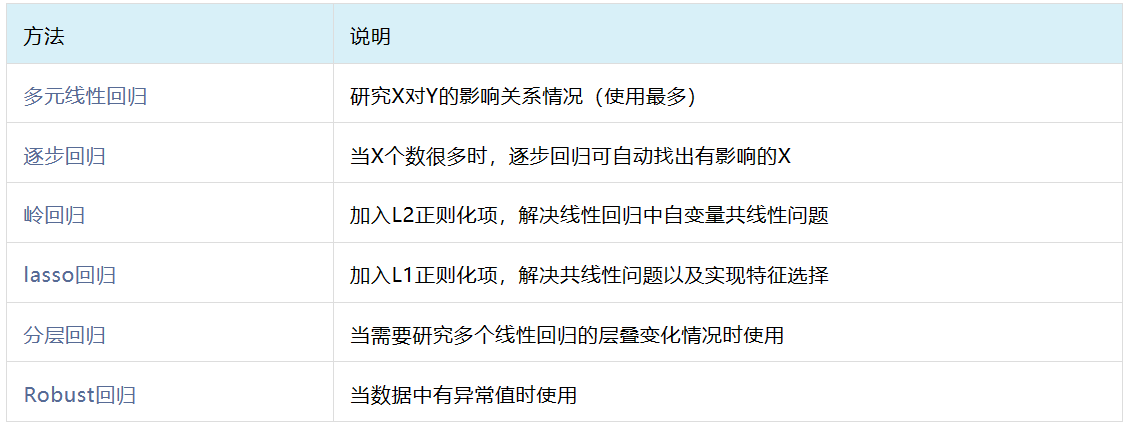
2、logistic回归分析
因变量Y为定类数据时,使用logistic回归分析进行影响关系分析:

五、模型研究方法
当需要研究多个变量之间的关系情况时,通常可构建统计模型用于分析及预测,分析方法说明见下表:
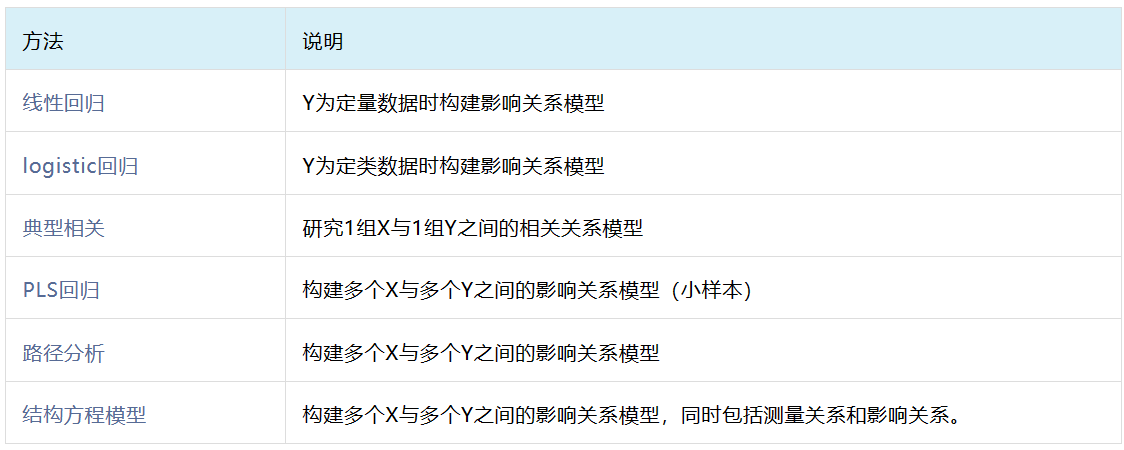
六、信息浓缩方法
信息浓缩方法可以帮助人们在不损失太多信息的情况下,将数据和信息进行简化和压缩,从而提高处理效率。常用方法包括主成分分析和因子分析两类。
- 主成分分析:是一种线性变换方法,它通过将原始变量转换为新的变量(主成分),使得这些新的变量在保留原始变量最大方差的基础上,彼此之间不相关。PCA的主要目标是减少数据集的维度,同时保留最重要的信息。这种方法常用于高维数据的降维分析。
- 因子分析:通过寻找隐藏在数据中的潜在因素或模式,将众多原始变量浓缩成少数几个因子变量。与主成分分析不同,因子分析更注重于寻找变量之间的关系,而不是直接将它们转换为主成分。因子分析试图用少数几个不可观测的因子来解释原始变量之间的关系,这些因子可以通过原始变量的方差和协方差来估计。
七、聚类分析方法
聚类分析是通过数据建模简化数据的一种方法,“物以类聚,人以群分”正是对聚类分析最好的诠释。它用于将抽象对象的集合,分组为由类似的对象组成的多个类。这种分析的目标是在相似的基础上收集数据来分类。
聚类分析常分为以下4类:

八、权重研究方法
权重研究是用于分析各因素或指标在综合体系中的重要程度,最终构建出指标评价体系。评价体系构建涉及的权重计算与优劣评价方法主要有以下几种:

九、一致性研究方法
一致性检验的目的在于比较不同方法得到的结果是否具有一致性。检验一致性的方法常用的有:Kappa检验、ICC组内相关系数、Kendall协调系数:

十、多选题分析
多选题分析是针对问卷多选题&单选题进行分析的方法,具体可分为四种类型包括:多选题、单选-多选、多选-单选、多选-多选。

十一、信度分析
信度分析用于测量样本回答结果是否可靠,即样本有没有真实作答量表类题项。信度分析仅针对量表题进行分析。
常用的信度指标有克隆巴赫α信度系数、折半信度、McDonald's ω信度系数、theta信度系数、重测信度5类:
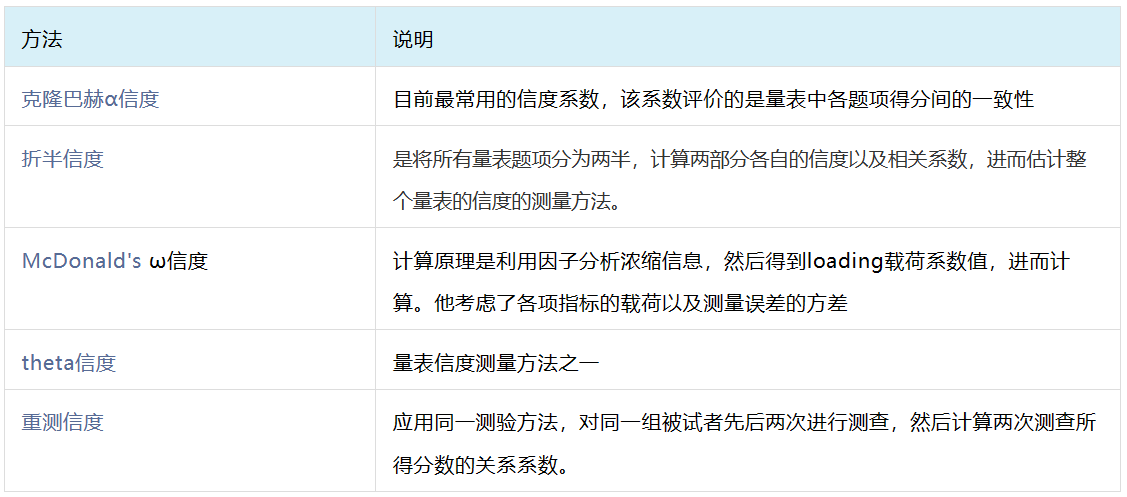
十二、效度分析
效度用于测量题项设计是否合理,即量表是否真正反映了我们希望测量的东西。效度用于反映实际测量结果与预想结果的符合程度,仅针对量表题进行分析。
一般来讲,有4种类型的效度内容效度、结构效度、区分效度、聚合效度,说明如下:

有关量表信度和效度的更多内容可参考往期文章:
量表信度与效度 | 测量方法及其评价指标汇总整理
十三、中介/调节效应
中介效应和调节效应虽然不是回归模型,但它们通常是在回归分析的基础上进行检验的。中介效应可以用来解释一个变量如何通过中介变量影响另一个变量。调节效应可以用来解释一个变量如何通过调节另一个变量与第三个变量的关系来影响第三个变量。

有关调节效应和中介效应的更多内容可参考往期文章:
论文写作问卷研究必备→调节作用&中介作用
十四、机器学习
主要可用于分类任务或回归任务。常用方法包括决策树、随机森林、KNN、朴素贝叶斯、支持向量机、神经网络,说明如下:
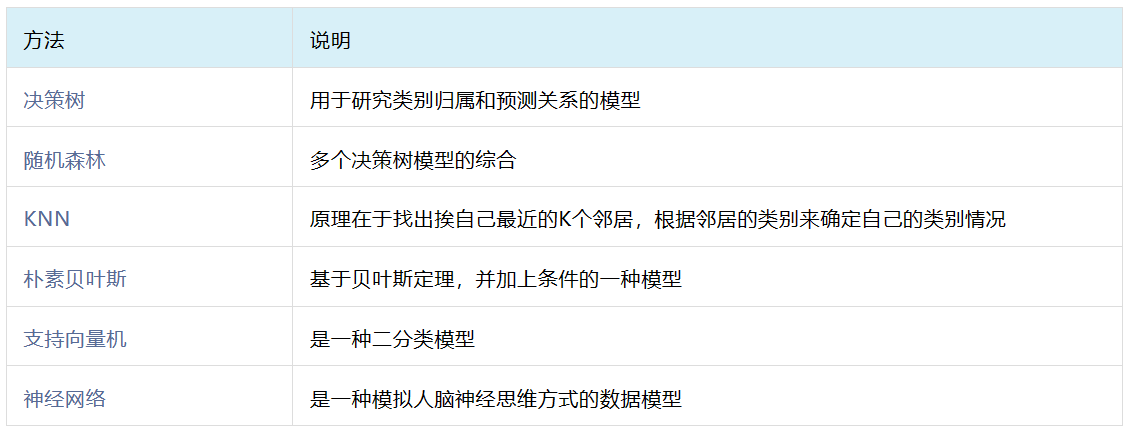
有关机器学习的更多内容可参考往期文章:六种机器学习算法大揭秘:从决策树到神经网络,小白也能轻松掌握!
十五、Meta分析
Meta荟萃分析是一种综合各种文献结论,进而汇总综合评价的方法,通俗地看,Meta分析是将多篇类似研究的文献进行汇总,将多个文献的研究结论进行总结,并且通过一系列科学分析,从而得到科学结论的方法。
SPSSAU的Meta分析模块,根据不同的数据类型,细分为以下8个算法:
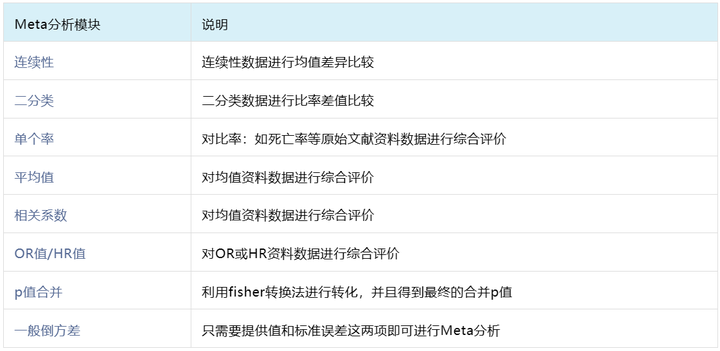
有关Meta分析的更多内容可参考往期文章:
初学Meta分析 | 基本流程与方法介绍
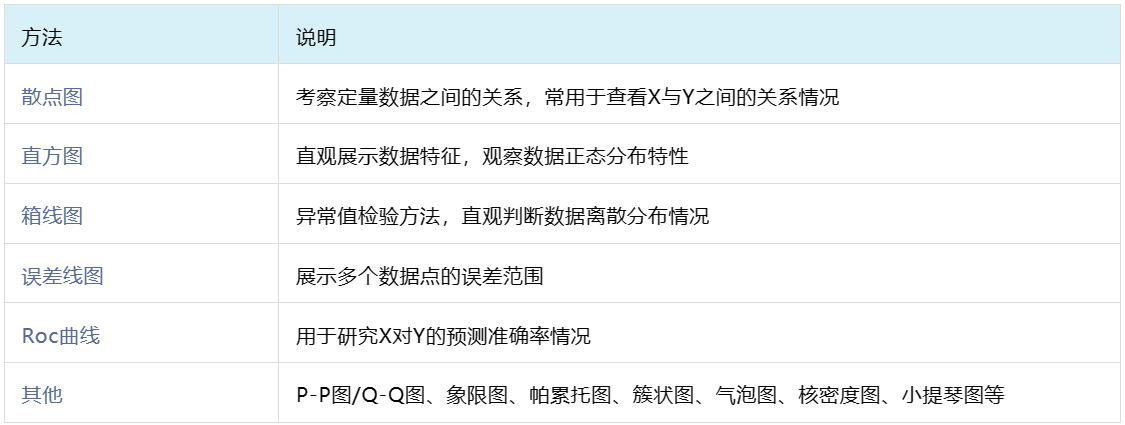
十六、可视化分析
统计图是将数据以图形化的方式展示出来的工具,他可以帮助人们更好的理解和分析数据。使用合适的统计图可以直观展示数据分布情况、比较数据差异、预测数据未来趋势等。常用方法说明如下: