精华置顶
墙裂推荐!小白如何1个月系统学习CV核心知识:链接
今天跟大家分享一个可视化CNN/ViT中间特征的库:pytorch-grad-cam
下载地址:https://github.com/jacobgil/pytorch-grad-cam
pytorch-grad-cam支持多种可视化方法,如下表所示:

一些可视化示例


5分钟实现网络特征可视化
(1)安装pytorch-grad-cam
在安装完pytorch和torchvision库后,使用命令pip install grad-cam安装pytorch-grad-cam。
(2)导入所需的库,定义model
这里直接使用torchvision中带有预训练权重的resnet18,可视化resnet18某一层的输出feature map。
import numpy as np
import cv2
import torchvision.models as models
import torchvision.transforms as transforms
import pytorch_grad_cam
from pytorch_grad_cam.utils.image import show_cam_on_image
# 从torchvision中导入resnet16
resnet18 = models.resnet18(pretrained=True)
resnet18.eval()
(3)设置可视化哪个层的输出feature map
打印上面定义的resnet18,查看层的名字。下图为部分打印结果
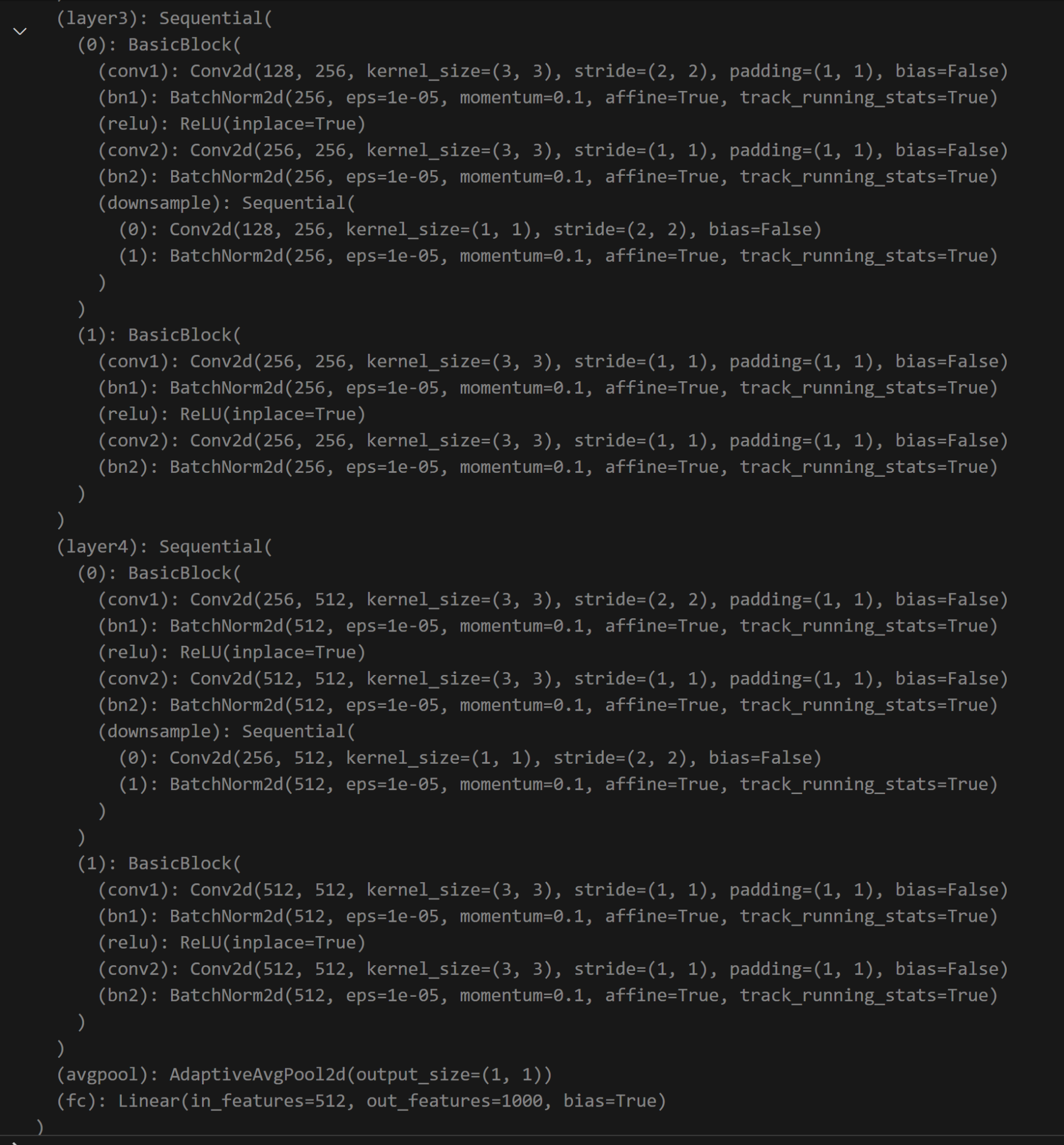
可以可视化resnet18.layer4[0].conv1、resnet18.layer4[1].bn2等你感兴趣的层的输出feature map。
比如想可视化resnet18.layer4[1].bn2的输出feature map,则:
traget_layers = [resnet18.layer4[0].conv1]
(4)读取输入图片,进行图片预处理,得到网络输入tensor以及用于可视化时的原始图像
# 读取图片,将图片转为RGB
origin_img = cv2.imread('./bird.jpg')
rgb_img = cv2.cvtColor(origin_img, cv2.COLOR_BGR2RGB)
# 图片预处理:resize、裁剪、归一化
trans = transforms.Compose([
transforms.ToTensor(),
transforms.Resize(224),
transforms.CenterCrop(224)
])
crop_img = trans(rgb_img)
net_input = transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))(crop_img).unsqueeze(0)
# 将裁剪后的Tensor格式的图像转为numpy格式,便于可视化
canvas_img = (crop_img*255).byte().numpy().transpose(1, 2, 0)
canvas_img = cv2.cvtColor(canvas_img, cv2.COLOR_RGB2BGR)
(5)得到可视化结果
这里使用GradCAM++方法进行可视化。注意pytorch_grad_cam.GradCAMPlusPlus中要输入步骤(3)中定义的traget_layers,用于指定要可视化的feature map。
# 实例化cam,得到指定feature map的可视化数据
cam = pytorch_grad_cam.GradCAMPlusPlus(model=resnet18, target_layers=traget_layers, use_cuda=False)
grayscale_cam = cam(net_input)
grayscale_cam = grayscale_cam[0, :]
# 将feature map与原图叠加并可视化
src_img = np.float32(canvas_img) / 255
visualization_img = show_cam_on_image(src_img, grayscale_cam, use_rgb=False)
cv2.imshow('feature map', visualization_img)
cv2.waitKey(0)
可视化结果如下:

完整代码如下:
import numpy as np
import cv2
import torchvision.models as models
import torchvision.transforms as transforms
import pytorch_grad_cam
from pytorch_grad_cam.utils.image import show_cam_on_image
# 1.定义模型结构,选取要可视化的层
resnet18 = models.resnet18(pretrained=True)
resnet18.eval()
traget_layers = [resnet18.layer4[1].bn2]
# 2.读取图片,将图片转为RGB
origin_img = cv2.imread('./bird.jpg')
rgb_img = cv2.cvtColor(origin_img, cv2.COLOR_BGR2RGB)
# 3.图片预处理:resize、裁剪、归一化
trans = transforms.Compose([
transforms.ToTensor(),
transforms.Resize(224),
transforms.CenterCrop(224)
])
crop_img = trans(rgb_img)
net_input = transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))(crop_img).unsqueeze(0)
# 4.将裁剪后的Tensor格式的图像转为numpy格式,便于可视化
canvas_img = (crop_img*255).byte().numpy().transpose(1, 2, 0)
canvas_img = cv2.cvtColor(canvas_img, cv2.COLOR_RGB2BGR)
# 5.实例化cam
cam = pytorch_grad_cam.GradCAMPlusPlus(model=resnet18, target_layers=traget_layers, use_cuda=False)
grayscale_cam = cam(net_input)
grayscale_cam = grayscale_cam[0, :]
# 6.将feature map与原图叠加并可视化
src_img = np.float32(canvas_img) / 255
visualization_img = show_cam_on_image(src_img, grayscale_cam, use_rgb=False)
cv2.imshow('feature map', visualization_img)
cv2.waitKey(0)
推荐阅读:
图像分类任务ViT与CNN谁更胜一筹?DeepMind用实验证明
如何优雅地读取网络的中间特征?
港科大提出适用于夜间场景语义分割的无监督域自适应新方法
EViT:借鉴鹰眼视觉结构,南开大学等提出ViT新骨干架构,在多个任务上涨点
HSN:微调预训练ViT用于目标检测和语义分割,华南理工和阿里巴巴联合提出
使用目标之间的先验关系提升目标检测器性能
CV计算机视觉每日开源代码Paper with code速览-2023.10.27
CV计算机视觉每日开源代码Paper with code速览-2023.10.26