目录
一、Nokogiri库
二、OpenURI库
三、结合Nokogiri和OpenURI进行爬虫编程
四、高级爬虫编程
1、并发爬取
2、错误处理和异常处理
3、深度爬取
总结
在当今的数字化时代,网络爬虫已经成为收集和处理大量信息的重要工具。其中,Nokogiri和OpenURI是两个非常有用的Ruby库,可以帮助我们轻松地实现HTTP爬虫。在这篇文章中,我们将介绍如何使用这两个库进行网络爬虫编程。

一、Nokogiri库
Nokogiri是一个功能强大的HTML和XML解析器,可以方便地解析网页内容。它提供了许多便捷的方法来获取网页中的数据,如获取特定标签、属性等。
下面是一个简单的示例,演示如何使用Nokogiri获取HTML页面中的标题:
require 'nokogiri'
url = 'http://example.com'
doc = Nokogiri::HTML(open(url))
title = doc.title.text
puts title在这个例子中,我们首先使用require 'nokogiri'导入Nokogiri库。然后,我们定义了一个URL变量,将其设置为需要爬取的网页URL。接下来,我们使用Nokogiri::HTML(open(url))来解析网页内容,并将其存储在变量doc中。最后,我们使用doc.title.text获取网页的标题,并将其存储在变量title中。
二、OpenURI库
OpenURI是一个方便的库,可以让我们轻松地使用Ruby进行HTTP请求。它提供了许多选项来设置HTTP请求的参数,如请求方法、请求头等。
下面是一个示例,演示如何使用OpenURI发送GET请求并获取响应内容:
require 'open-uri'
url = 'http://example.com'
content = open(url) { |f| f.read }
puts content在这个例子中,我们首先使用require 'open-uri'导入OpenURI库。然后,我们定义了一个URL变量,将其设置为需要请求的网页URL。接下来,我们使用open(url) { |f| f.read }发送GET请求并获取响应内容,并将其存储在变量content中。最后,我们使用puts content将响应内容输出到控制台。
三、结合Nokogiri和OpenURI进行爬虫编程
现在我们已经介绍了Nokogiri和OpenURI的基本用法,下面我们将介绍如何将它们结合起来进行爬虫编程。以下是一个示例代码,演示如何使用Nokogiri和OpenURI获取一个网页的标题和链接:
require 'nokogiri'
require 'open-uri'
url = 'http://example.com'
doc = Nokogiri::HTML(open(url))
title = doc.title.text
puts title
links = doc.css('a').collect { |a| a['href'] }
puts links.join('\n')在这个例子中,我们首先使用require 'nokogiri'和require 'open-uri'导入Nokogiri和OpenURI库。然后,我们定义了一个URL变量,将其设置为需要爬取的网页URL。接下来,我们使用OpenURI发送GET请求并获取响应内容,然后使用Nokogiri解析响应内容并获取网页标题。最后,我们使用Nokogiri选择所有链接元素并获取它们的href属性,然后将它们存储在一个数组中。最后,我们将数组中的所有链接打印到控制台。
四、高级爬虫编程
1、并发爬取
在处理大量网页时,可以使用Ruby的并发特性来提高爬取速度。我们可以使用Ruby的Concurrent库来创建多个线程或进程来并发地发送HTTP请求。例如,以下代码演示了如何使用线程池并发地爬取多个网页:
require 'concurrent'
require 'nokogiri'
require 'open-uri'
url_pool = [
'http://example.com',
'http://example.com/page2',
'http://example.com/page3',
# ...
]
pool = Concurrent::ThreadPool.new(max_size: 10) # 创建大小为10的线程池
results = []
url_pool.each do |url|
pool.post {
doc = Nokogiri::HTML(open(url))
title = doc.title.text
links = doc.css('a').collect { |a| a['href'] }
results << [url, title, links]
}
end
pool.shutdown # 关闭线程池,等待所有任务完成在这个例子中,我们首先定义了一个URL池,其中包含了需要爬取的多个网页URL。然后,我们创建了一个大小为10的线程池,并使用pool.post方法将每个URL分配给一个线程并发地处理。每个线程会发送HTTP请求并解析响应内容,提取标题和链接,并将它们存储在一个数组中。最后,我们使用pool.shutdown方法关闭线程池,并等待所有任务完成。
2、错误处理和异常处理
在爬虫编程中,错误处理和异常处理非常重要。例如,如果目标网站做出了防爬虫措施,可能会导致爬虫失败。因此,我们需要添加错误处理和异常处理的代码来确保爬虫的稳健性。以下是一个示例代码,演示了如何处理异常:
require 'nokogiri'
require 'open-uri'
begin
url = 'http://example.com'
doc = Nokogiri::HTML(open(url))
title = doc.title.text
puts title
rescue OpenURI::HTTPError => e
puts "HTTP Error occurred: #{e.message}"
rescue Nokogiri::XML::SyntaxError => e
puts "XML Syntax Error occurred: #{e.message}"
rescue => e
puts "Unknown error occurred: #{e.message}"
end3、深度爬取
在处理大型网站时,我们可能需要爬取网页的子页面或特定链接。Nokogiri和OpenURI提供了方便的方法来进行深度爬取。
以下是一个示例代码,演示了如何使用Nokogiri和OpenURI进行深度爬取:
require 'nokogiri'
require 'open-uri'
url = 'http://example.com'
doc = Nokogiri::HTML(open(url))
# 爬取特定链接
特定链接 = doc.css('#特定链接').first.attribute('href').value
content = open(特定链接) { |f| f.read }
puts content
# 爬取子页面
子页面链接 = doc.css('.子页面链接').first.attribute('href').value
content = open(子页面链接) { |f| f.read }
puts content在这个例子中,我们首先解析了目标网页,并获取了特定链接和子页面链接的URL。然后,我们使用OpenURI发送HTTP请求并获取响应内容。请注意,在获取特定链接和子页面链接时,我们使用了CSS选择器和属性方法来定位和提取链接URL。
总结
Nokogiri和OpenURI是两个非常有用的Ruby库,可以帮助我们轻松地进行HTTP爬虫编程。通过结合这两个库,我们可以快速、高效地爬取网页内容,提取所需信息。在进行爬虫编程时,我们需要注意错误处理和异常处理,以确保爬虫的稳健性。同时,还可以使用并发编程来提高爬取速度。最后,通过深度爬取方法来获取网页的子页面或特定链接。
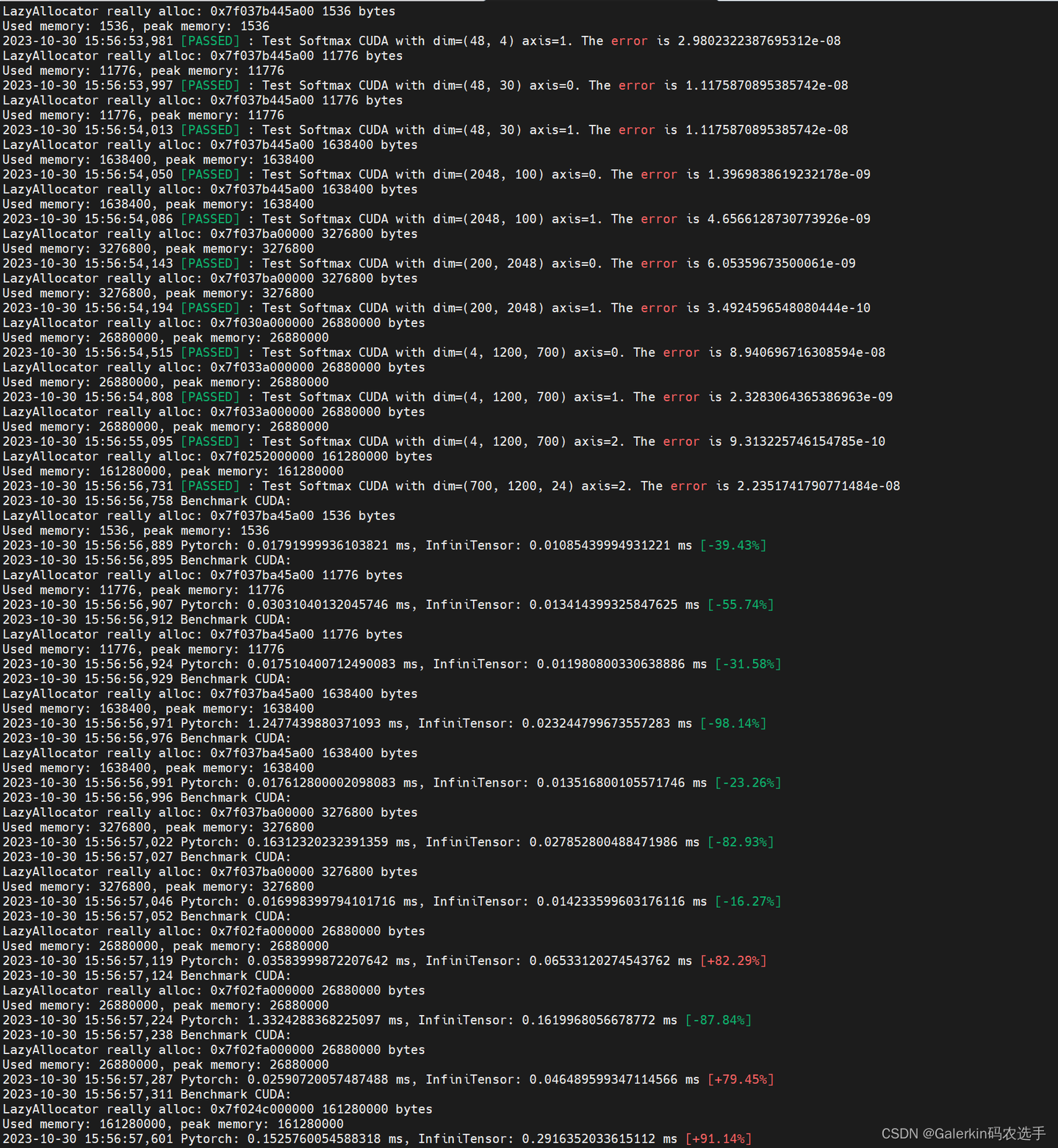







![js 异常数组 [空白,Array(10),空白,Array(10),空白]](https://img-blog.csdnimg.cn/cf9592a178694837b4c40003032b6b38.png#pic_center)